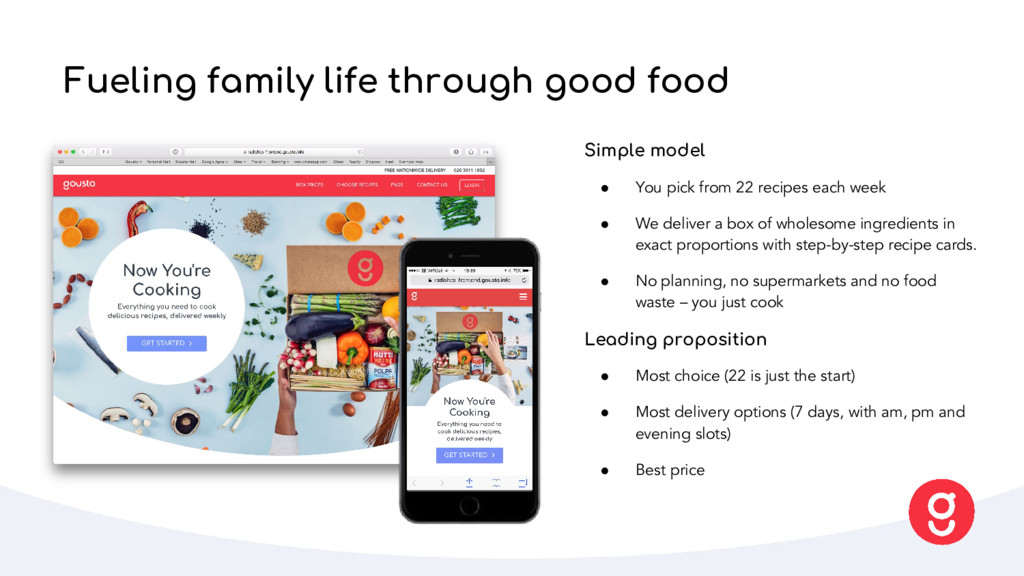
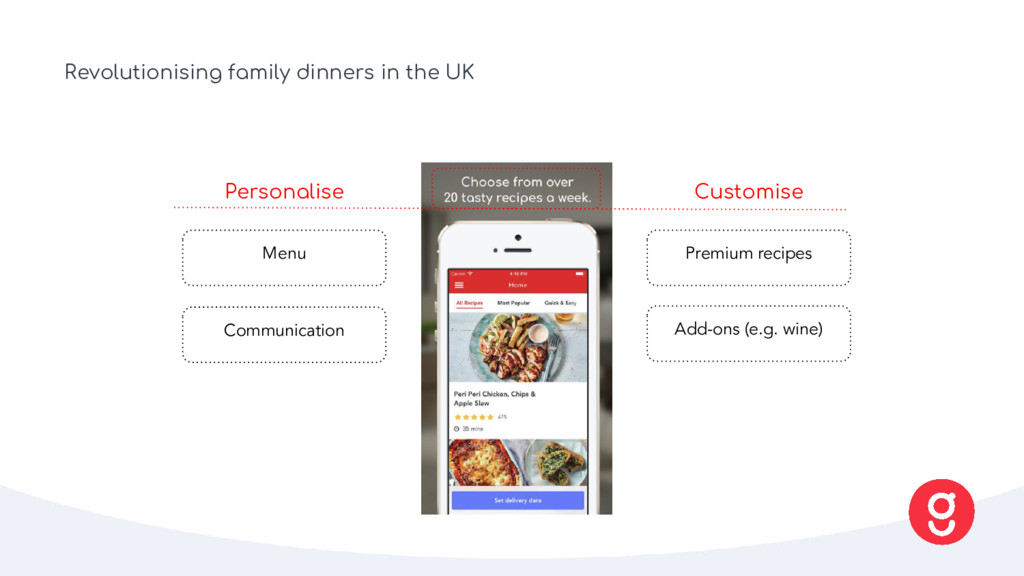
pick from 22 recipes each week • We deliver a box of wholesome ingredients in exact proportions with step-by-step recipe cards. • No planning, no supermarkets and no food waste – you just cook Leading proposition • Most choice (22 is just the start) • Most delivery options (7 days, with am, pm and evening slots) • Best price
capability from the beginning Build what the business needs Use agile product management and scrum to deliver value early Build production ready products We practice devops at Gousto - “You build it, you run it” Create focus Create a separate, dedicated data analytics function, all data insight queries go there Measure success through data Make it accountable to the investment being made 1 2 3 4 5
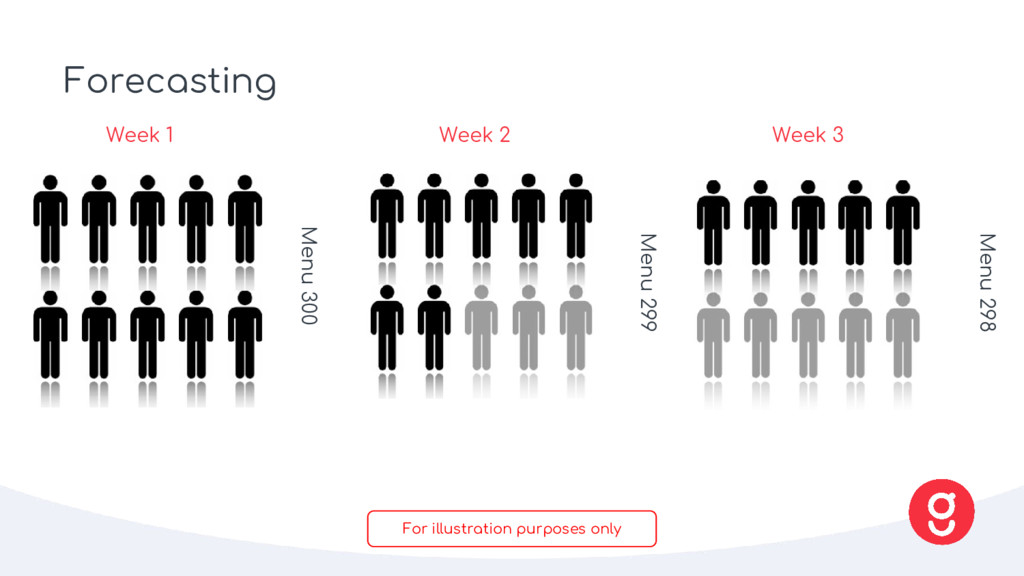
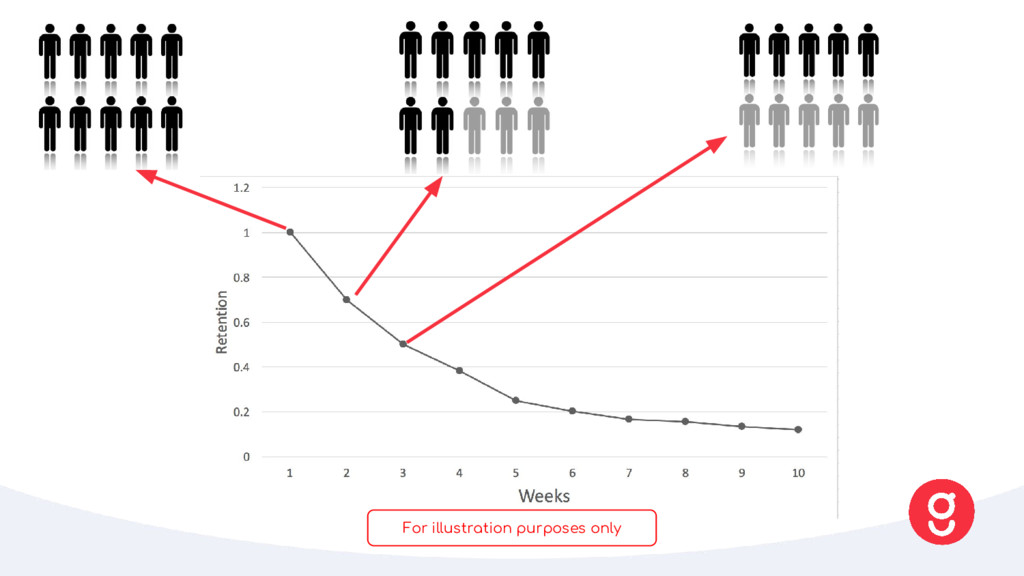
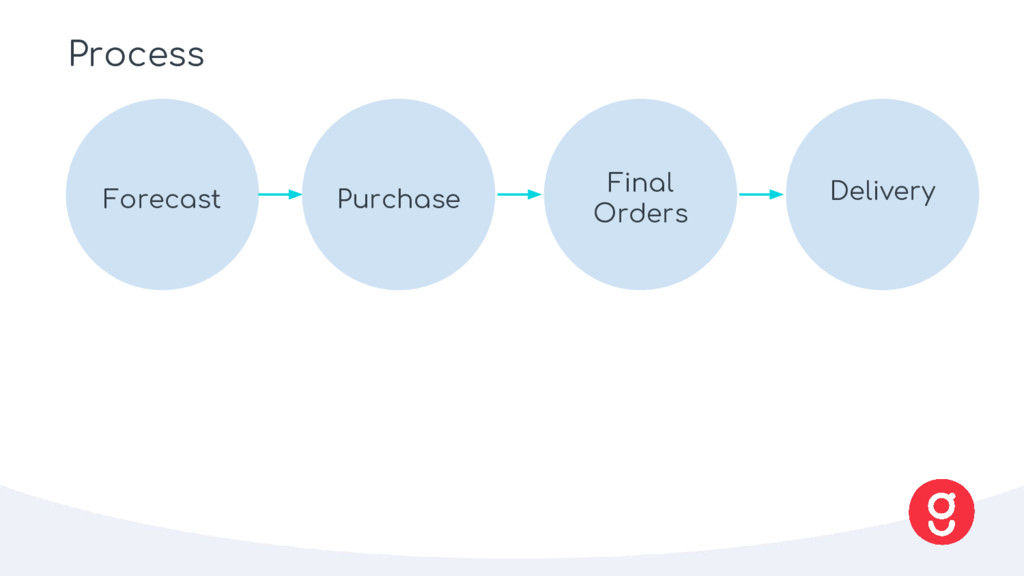
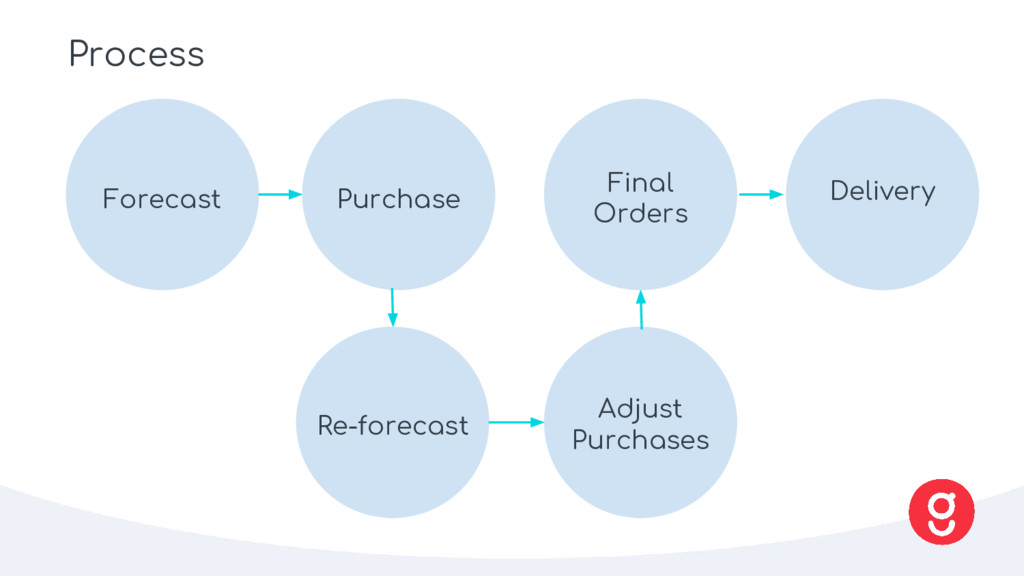
purchase our ingredients against actual orders • We need to forecast total number of boxes and how many ingredients we need to buy • There are a lot of perishables: forecasting is key to being a sustainable business What • Predicted acquisition strength • Live customer trends • Retention (cohort analysis) • Seasonality (Facebook prophet) How Forecast Waste Average
changing on a weekly basis • SKU quantities change on a weekly / daily basis • SKUs are placed on different locations every week • Optimise pickface AND finding shortest path to collect items Gousto • Mostly items with long shelf-life • SKUs are changing rarely (static) • SKU quantities are cyclical / seasonality • SKUs are placed on the same locations • Finding shortest path to collect items General e-commerce
week (requires a weekly redesign of our warehouse) • First we do forecast to predict total orders per recipe, per day • Orders forecast is consumed by genetic algorithms to calculate: ◦ Optimal pick-face layout from billions of combinations to balance load across our pick stations ◦ Optimal picking order and line routing to reduce congestion at these pick stations • Wondering about results?
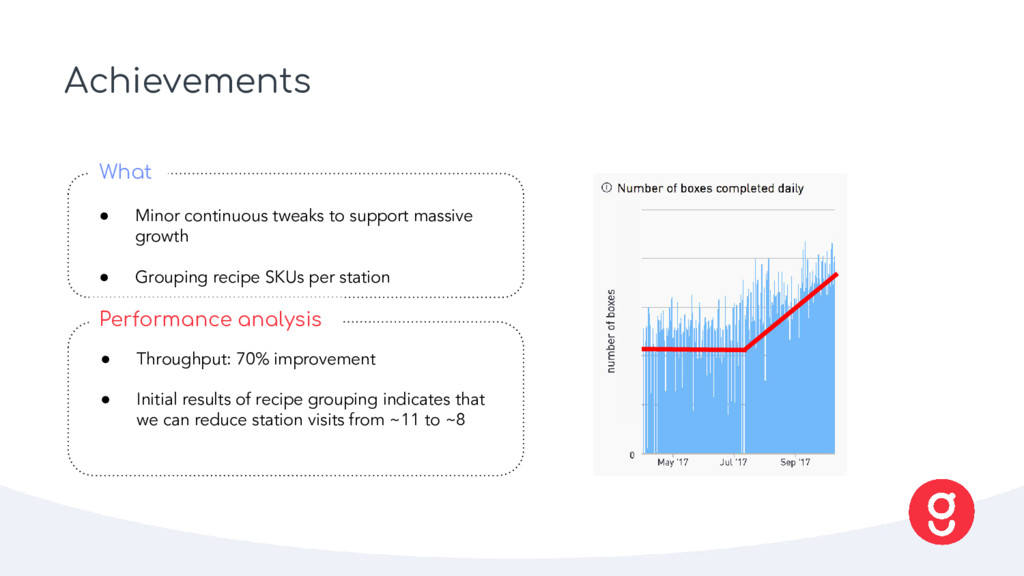
Grouping recipe SKUs per station What • Throughput: 70% improvement • Initial results of recipe grouping indicates that we can reduce station visits from ~11 to ~8 Performance analysis
item similarity) • Automate replenishment from a mezzanine floor • Image recognition for quality inspection What • Improving pick time and reduce picking errors • Improve the quality of work for pickers Expected outcome Plans
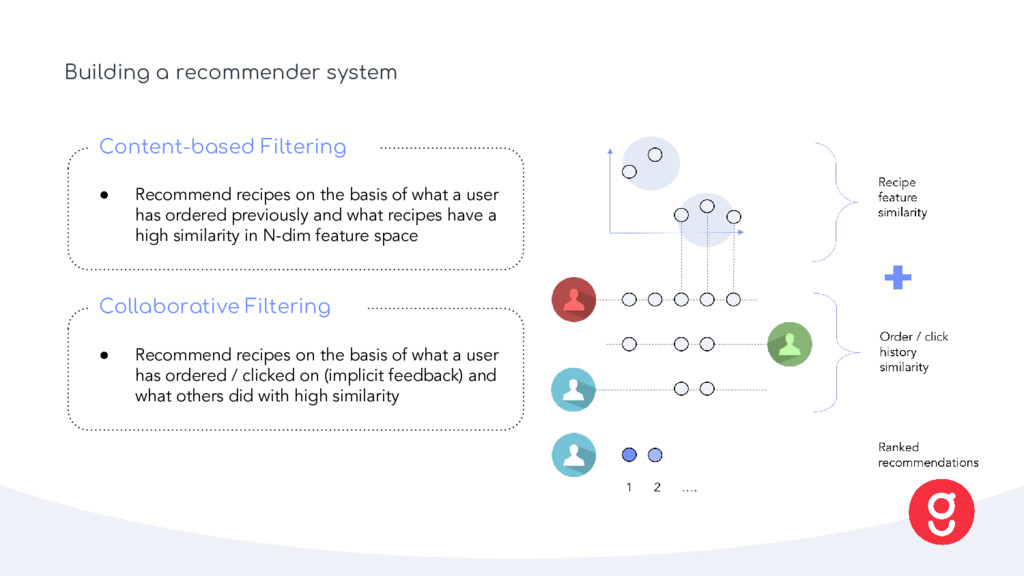
of what a user has ordered previously and what recipes have a high similarity in N-dim feature space Content-based Filtering • Recommend recipes on the basis of what a user has ordered / clicked on (implicit feedback) and what others did with high similarity Collaborative Filtering
Uses factorization to approximate pairwise (or higher order) interactions under data sparsity • Allows fitting on both interaction and item/user meta-data • Optimized with e.g. SGD Factorization Machines* Rendle, Steffen. “Factorization Machines with libFM.” ACM TIST 3 (2012) * Reference
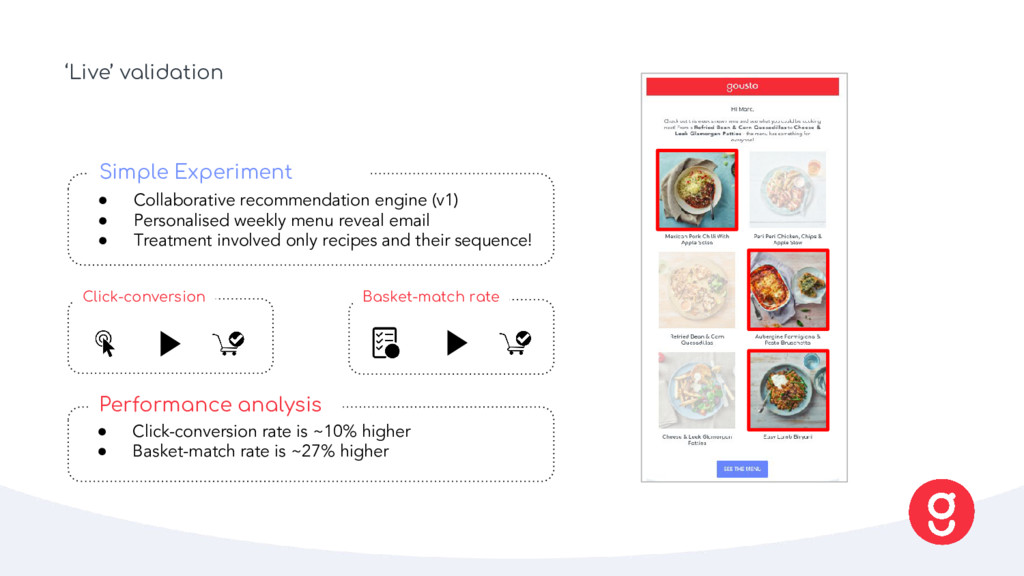
menu reveal email • Treatment involved only recipes and their sequence! Simple Experiment • Click-conversion rate is ~10% higher • Basket-match rate is ~27% higher Performance analysis Click-conversion Basket-match rate
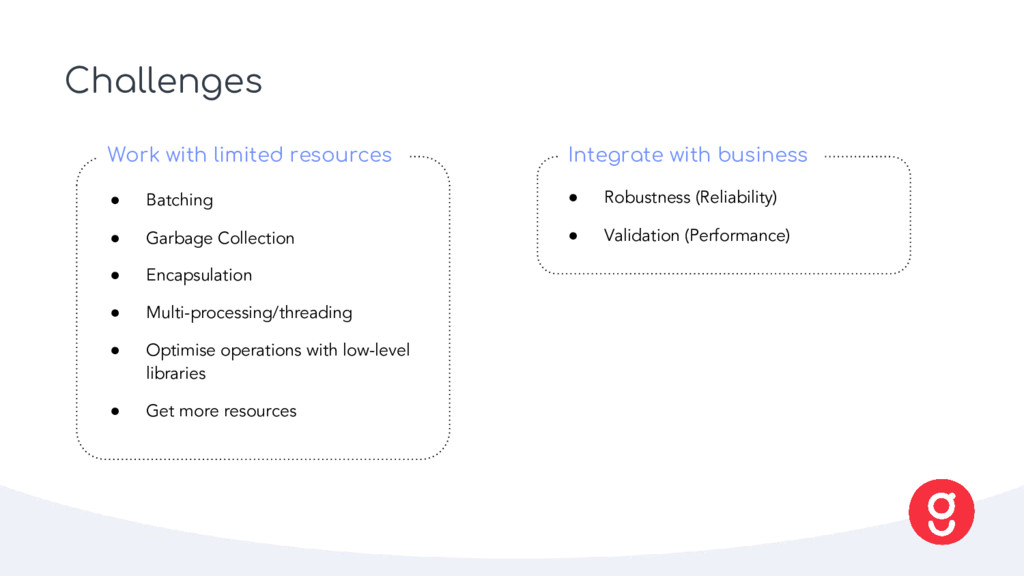
Encapsulation • Multi-processing/threading • Optimise operations with low-level libraries • Get more resources Work with limited resources • Robustness (Reliability) • Validation (Performance) Integrate with business
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}