come to our site, or use our apps and select from 22 meals each week. • They pick the meals they want to cook and say how many people they’re cooking for. • We deliver all the ingredients they need in exact proportions with step-by-step recipe cards in 2-3 days. • No planning, no supermarkets and no food waste – you just cook (and eat). • We’re a rapidly growing business.
balanced menus • When planning menus, we have to take many constraints into account: • Variety: There needs to be a range of proteins and cuisines • Operational: There are certain operational restrictions like lack of availability of certain ingredients • Collections: Menu needs to fulfil certain collections such as family and low calories • Hard to do this by hand!
uses: • Genetic algorithms: algorithm used for multivariable optimisation, based on the process that drives biological evolution • Recipe graph DB: database connecting relations between recipes and ingredients • Genetic algorithm deals with fulfilling constraints and collections • Recipe ontology helps us understand recipes and our customers SIMILARITY CONSTRAINTS
to the similarity between two recipes • Part of the problem is that it is a very subjective issue • Using only ingredients in common does not accurately capture similarity A small example…
to the similarity between two recipes • Part of the problem is that it is a very subjective issue • Using only ingredients in common does not accurately capture similarity • We need to be able to look at similarity from different points of view: • Ingredients • Cuisines • Presentation • Collections • (Customers’ taste) • Etc.
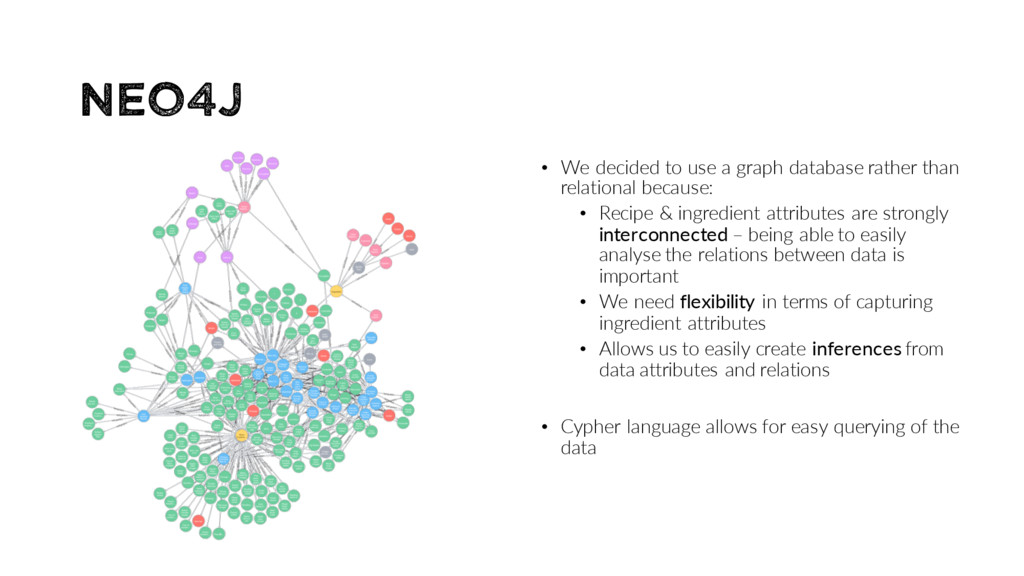
than relational because: • Recipe & ingredient attributes are strongly interconnected – being able to easily analyse the relations between data is important • We need flexibility in terms of capturing ingredient attributes • Allows us to easily create inferences from data attributes and relations • Cypher language allows for easy querying of the data
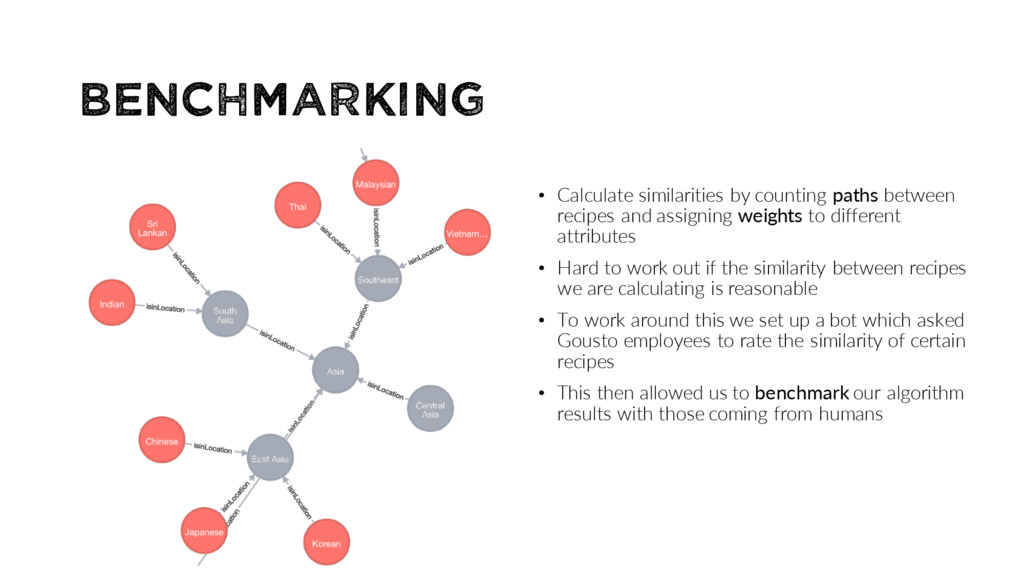
assigning weights to different attributes • Hard to work out if the similarity between recipes we are calculating is reasonable • To work around this we set up a bot which asked Gousto employees to rate the similarity of certain recipes • This then allowed us to benchmark our algorithm results with those coming from humans
fully implementing the menu planning algorithm • It is difficult to set up structure of graph database, as we needed to make sure we were capturing all the different recipe aspects • Currently investigating how to improve similarity estimations
towards a recommendation engine • This will require adding customer purchases, taste scores, reviews etc. • Allow customers to search exactly for what they want • Curate recipes for dietary requirements
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![@GoustoTech techbrunch.gousto.co.uk [email protected] Thank you for Listening!](https://files.speakerdeck.com/presentations/e853d3a016f445bcbe0336e676f94b3e/slide_13.jpg){kind=link}