our site, or use our apps and select from 22 meals each week. • They pick the meals they want to cook and say how many people they’re cooking for. • We deliver all the ingredients they need in exact propor@ons with step-by-step recipe cards in 2-3 days. • No planning, no supermarkets and no food waste – you just cook (and eat). • We’re a rapidly growing business. About Gousto
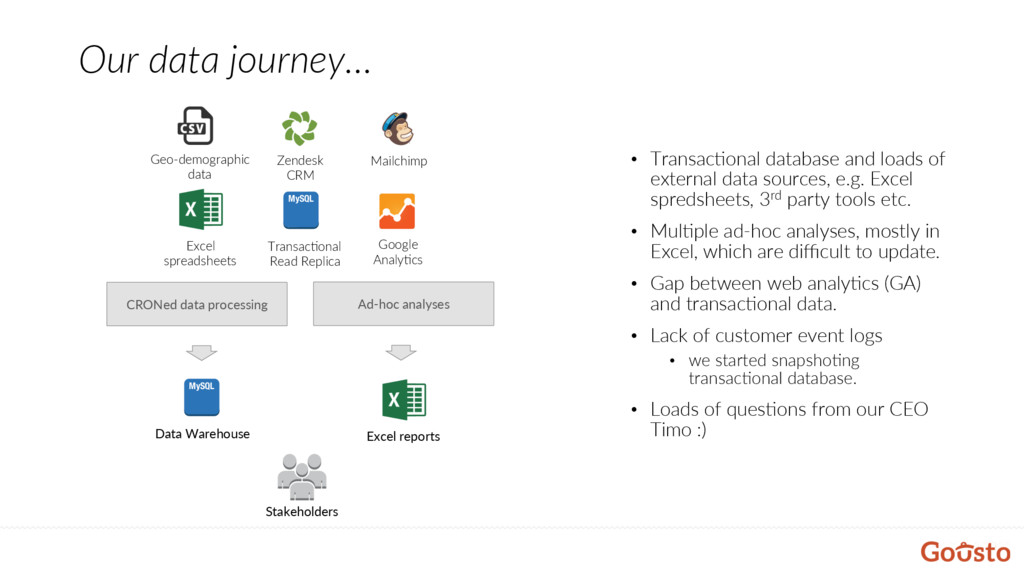
Excel spredsheets, 3rd party tools etc. • Mul@ple ad-hoc analyses, mostly in Excel, which are difficult to update. • Gap between web analy@cs (GA) and transac@onal data. • Lack of customer event logs • we started snapsho@ng transac@onal database. • Loads of ques@ons from our CEO Timo :) Our data journey… MySQL Transac@onal Read Replica Mailchimp Excel spreadsheets Google Analy@cs Zendesk CRM Geo-demographic data CRONed data processing Ad-hoc analyses MySQL Data Warehouse Excel reports Stakeholders
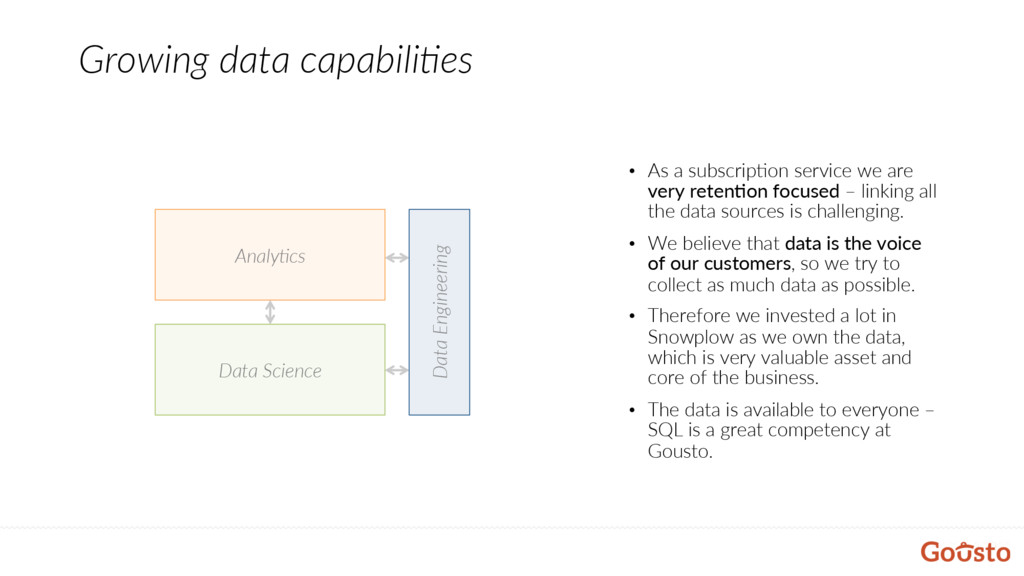
a subscrip@on service we are very retenDon focused – linking all the data sources is challenging. • We believe that data is the voice of our customers, so we try to collect as much data as possible. • Therefore we invested a lot in Snowplow as we own the data, which is very valuable asset and core of the business. • The data is available to everyone – SQL is a great competency at Gousto.
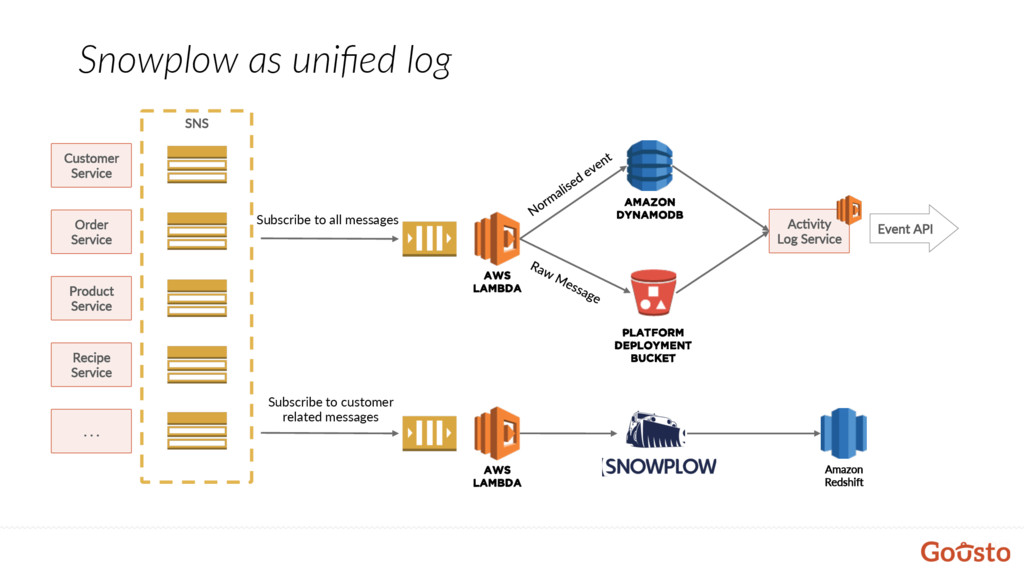
Service Product Service Recipe Service . . . AWS Lambda Amazon DynamoDB Platform Deployment Bucket SNS Subscribe to all messages Event API Amazon RedshiK AWS Lambda Subscribe to customer related messages
what happened to my events?! • No page loads – no automa@c page views. • We developed our custom framework for triggering events. • We use structured events for that purpose, but store (unstructured) JSON objects in them. • Such approach allows us to be flexible and quickly introduce new events. • But, no data valida@on can lead to garbage leaking. • Data modelling in Redshi[. Client Server App API
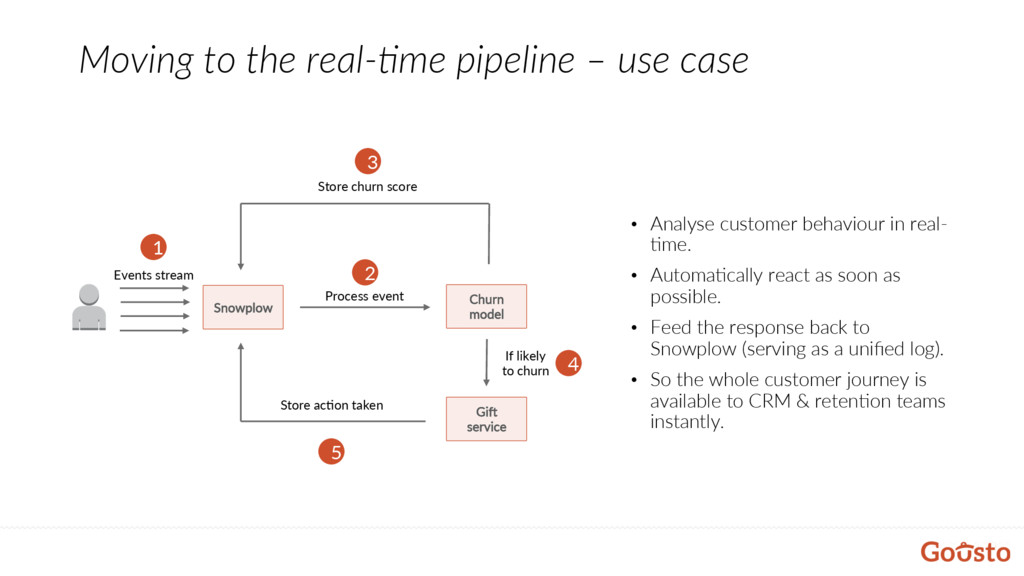
5 Store acDon taken Churn model GiK service Process event 2 Events stream 4 If likely to churn 3 Store churn score • Analyse customer behaviour in real- @me. • Automa@cally react as soon as possible. • Feed the response back to Snowplow (serving as a unified log). • So the whole customer journey is available to CRM & reten@on teams instantly.
are very reten9on focused. • Some customers are immediately convinced and become very loyal customers, while some customers need a bit more effort to get hooked. • We use Snowplow events data to model customer behavior and find customers more likely to churn so we can focus on them. • Use personalised approach to retain customers.
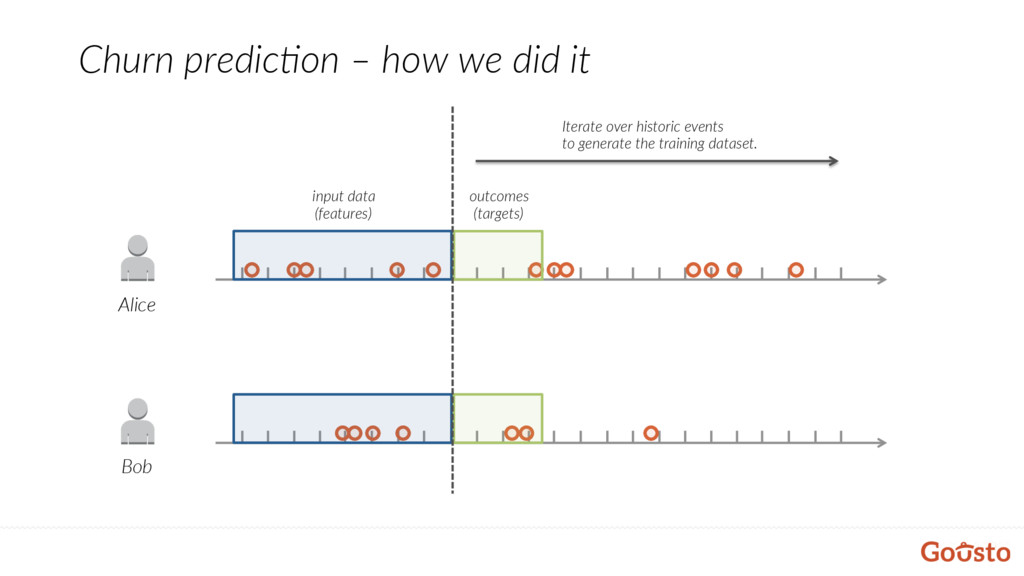
to define it? • It might be beaer trying to predict the likelihood of customer placing an order. • How big should be a horizon? Where should we draw a line? • Using events data, there is almost unlimited number of features – how to find really informa@ve ones? • How do we keep model up to date if we are affec@ng customer journeys? • How to measure success? • No maaer how accurate the model, the profit is what it counts at the end.
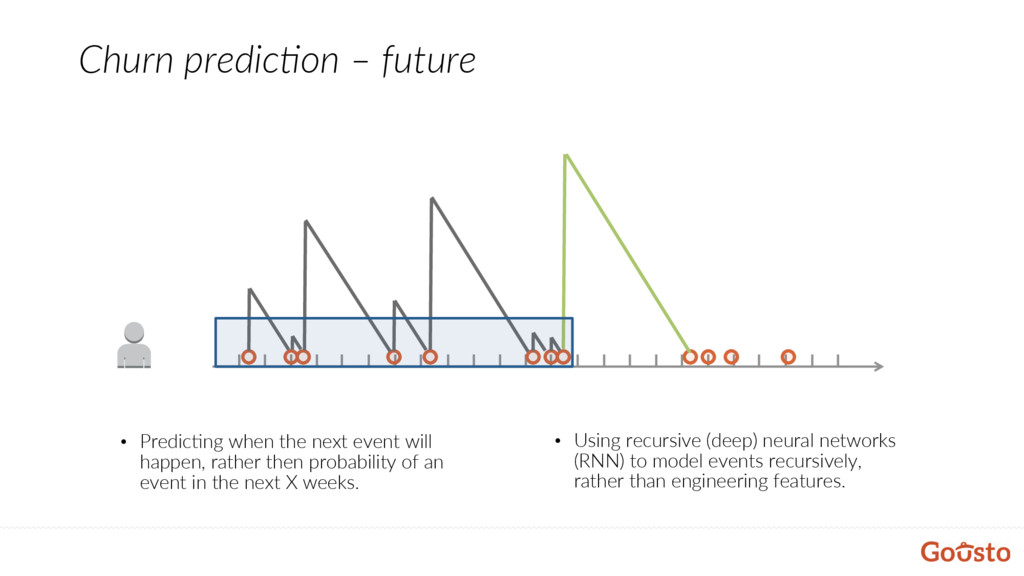
will happen, rather then probability of an event in the next X weeks. • Using recursive (deep) neural networks (RNN) to model events recursively, rather than engineering features.
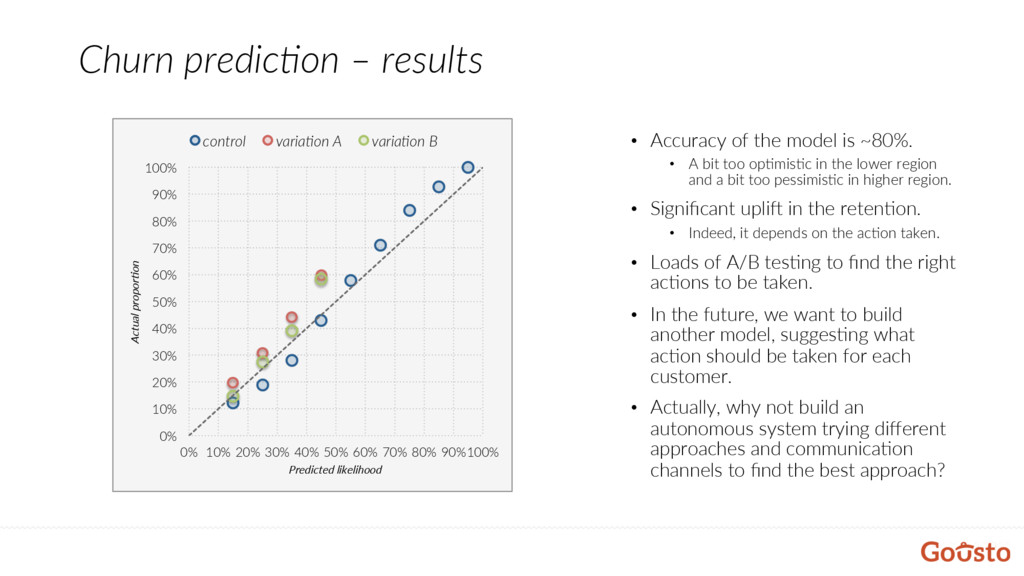
~80%. • A bit too op@mis@c in the lower region and a bit too pessimis@c in higher region. • Significant upli[ in the reten@on. • Indeed, it depends on the ac@on taken. • Loads of A/B tes@ng to find the right ac@ons to be taken. • In the future, we want to build another model, sugges@ng what ac@on should be taken for each customer. • Actually, why not build an autonomous system trying different approaches and communica@on channels to find the best approach? 0% 10% 20% 30% 40% 50% 60% 70% 80% 90% 100% 0% 10% 20% 30% 40% 50% 60% 70% 80% 90% 100% Actual propor+on Predicted likelihood control varia9on A varia9on B
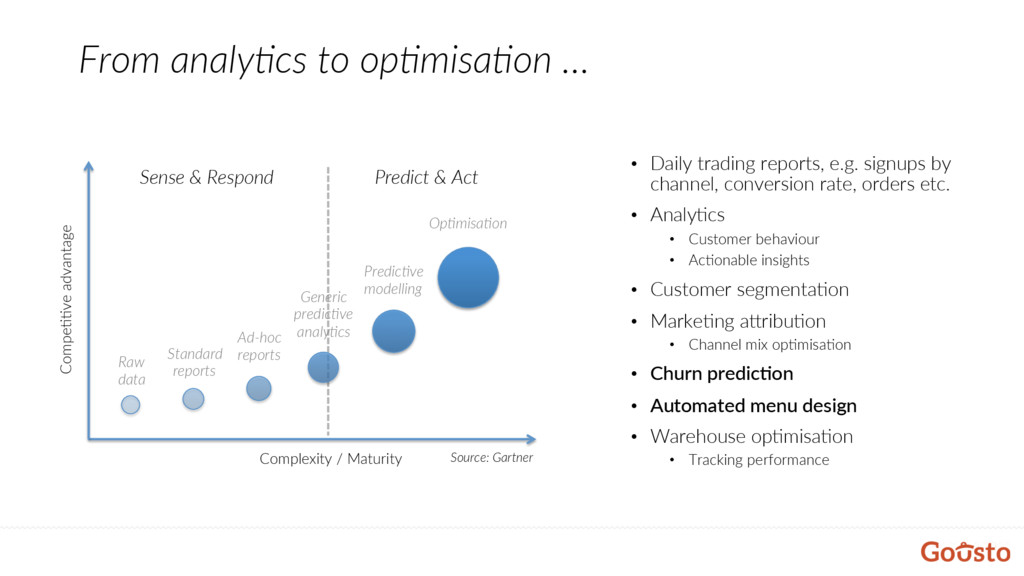
to manually design menus – every week. • With 22 recipes this task has become too demanding – diversity, mul@ple constraints, costs etc. • They should be focusing on recipe development to keep delivering delicious recipes. • Why not use machine learning to leverage the data to understand customers’ taste and design popular menus?
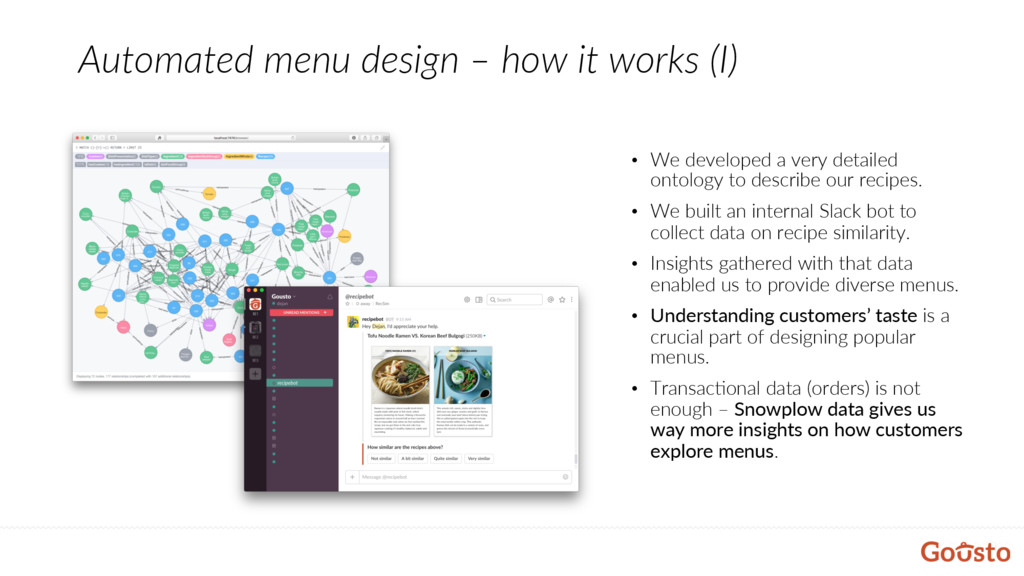
developed a very detailed ontology to describe our recipes. • We built an internal Slack bot to collect data on recipe similarity. • Insights gathered with that data enabled us to provide diverse menus. • Understanding customers’ taste is a crucial part of designing popular menus. • Transac@onal data (orders) is not enough – Snowplow data gives us way more insights on how customers explore menus.
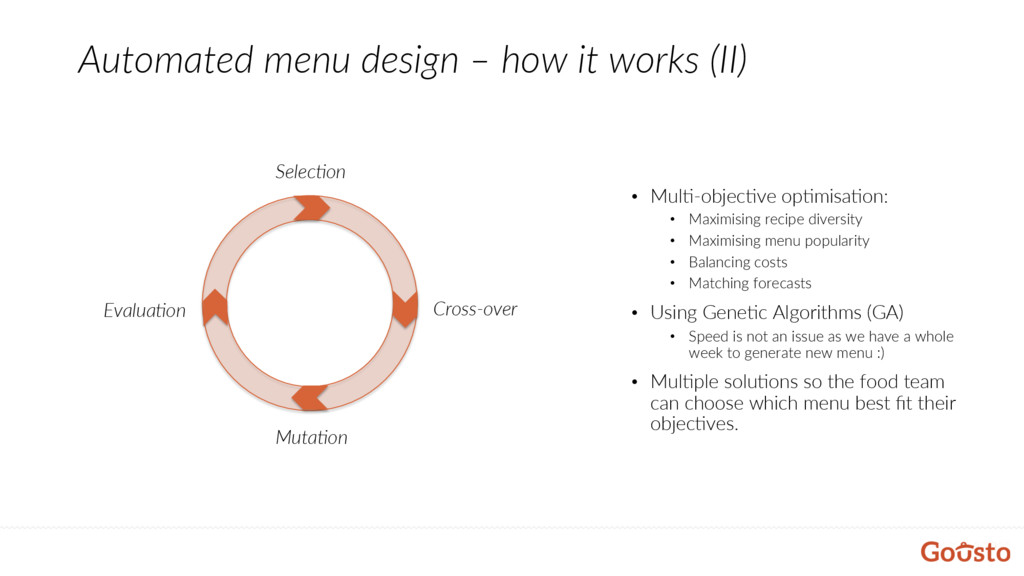
op@misa@on: • Maximising recipe diversity • Maximising menu popularity • Balancing costs • Matching forecasts • Using Gene@c Algorithms (GA) • Speed is not an issue as we have a whole week to generate new menu :) • Mul@ple solu@ons so the food team can choose which menu best fit their objec@ves. Selec9on Cross-over Muta9on Evalua9on
data capabili@es with limited data engineering resources. • TIP TO STARTUPS: start building data capabili9es as early as possible – data is a huge asset. • Snowplow also serves us as a unified log. • Not necessarily limited to customer focused data. • Snowplow enables us to ‘listen’ to our customers and provide them more personalised experience. • Moving to the real-Dme pipeline to realise just-in-@me personalisa@on, e.g. personalised recipe ordering, add-on recommenda@ons (upselling) etc.
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![@GoustoTech techbrunch.gousto.co.uk [email protected] Thank you Also… we’re recruiting](https://files.speakerdeck.com/presentations/f7cb60f1076142438a44109eb77067d8/slide_19.jpg){kind=link}