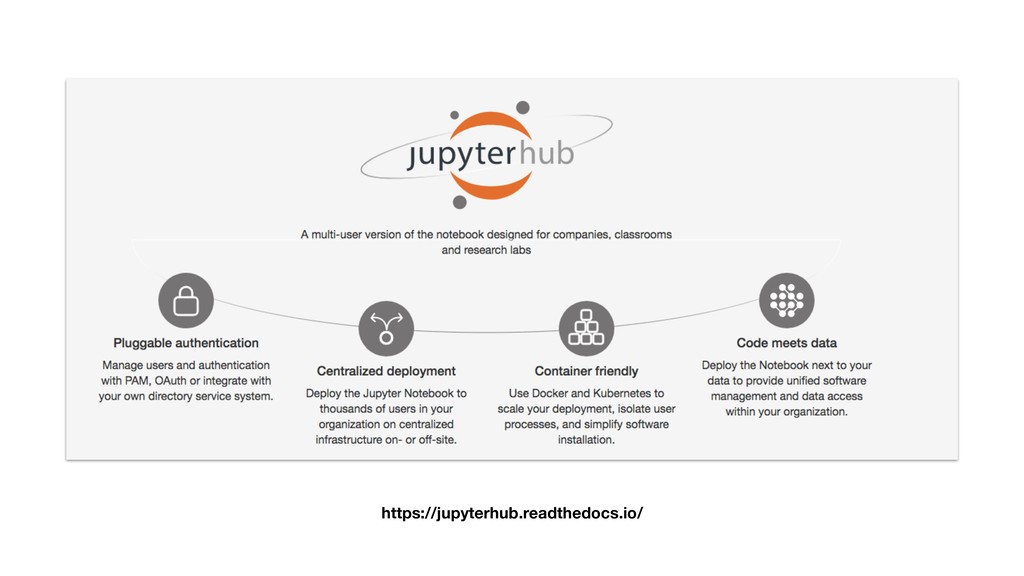
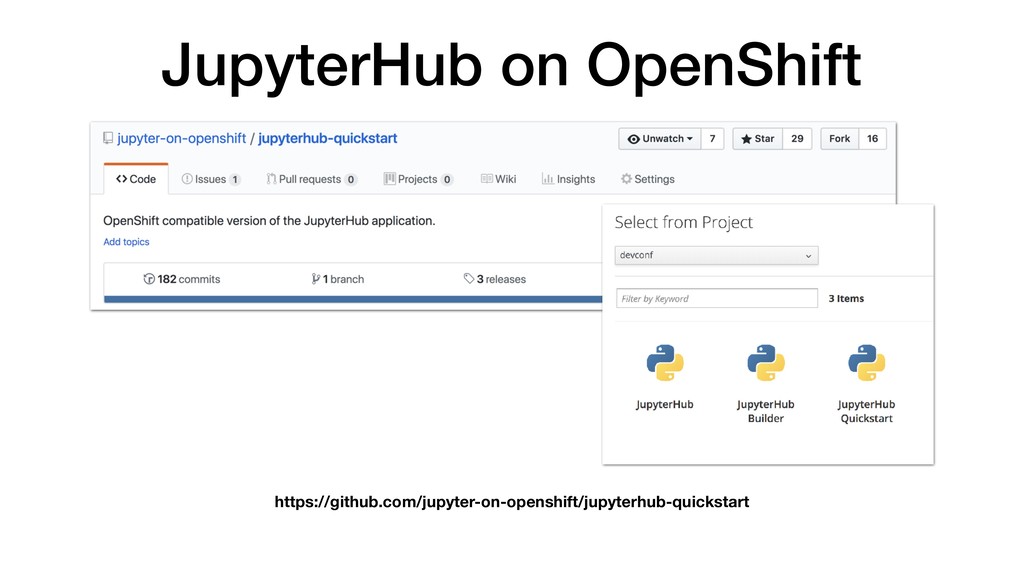
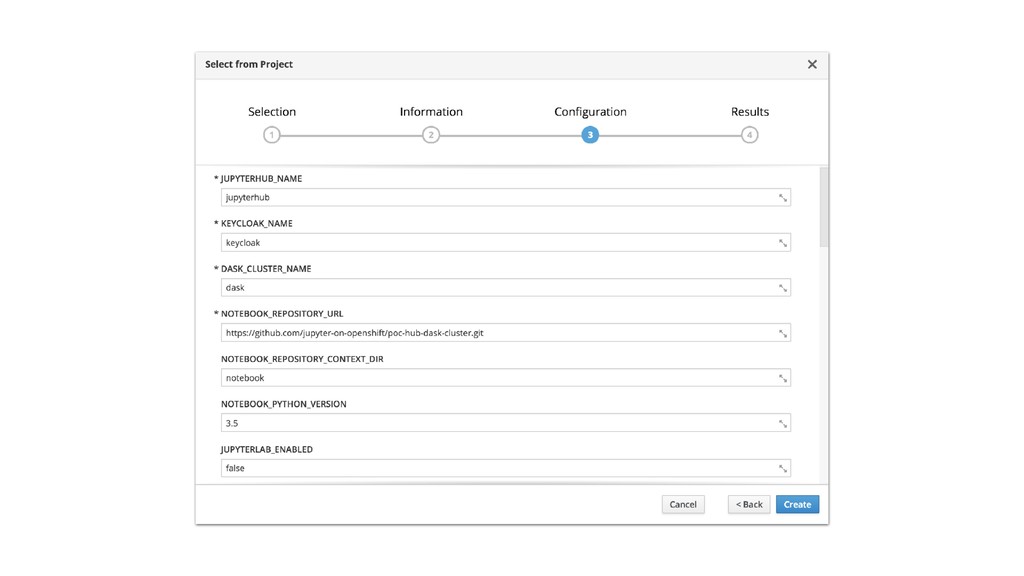
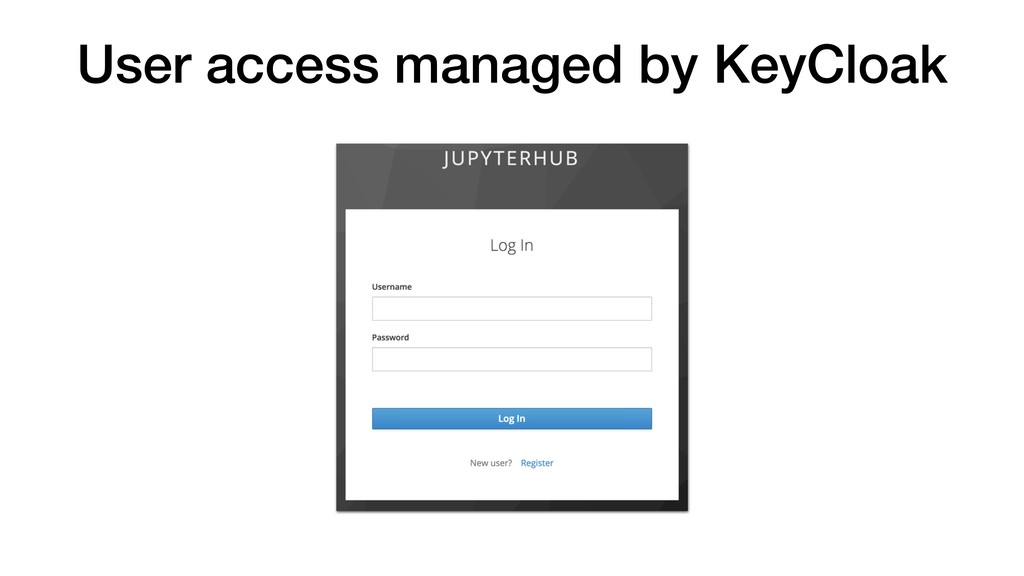
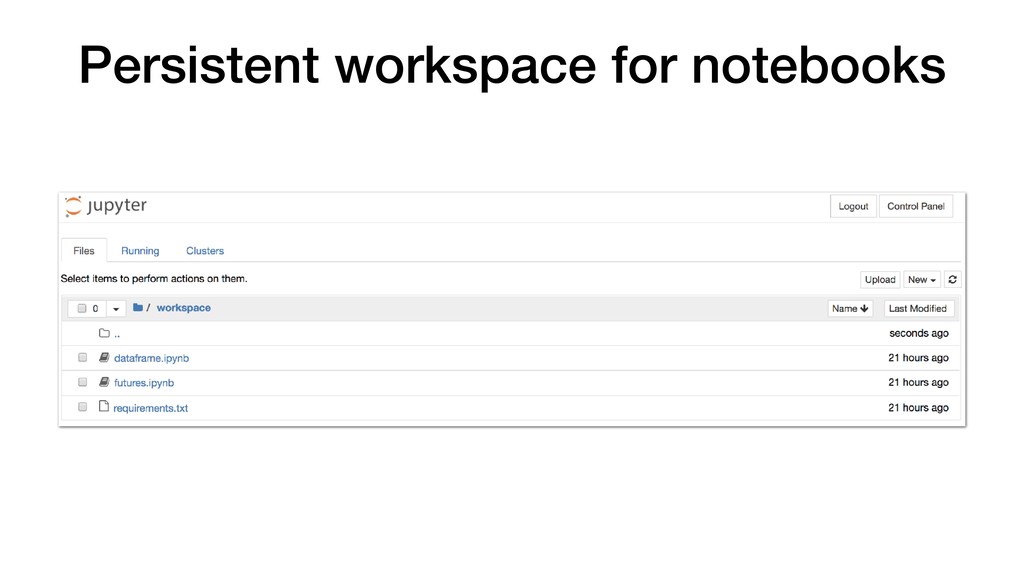
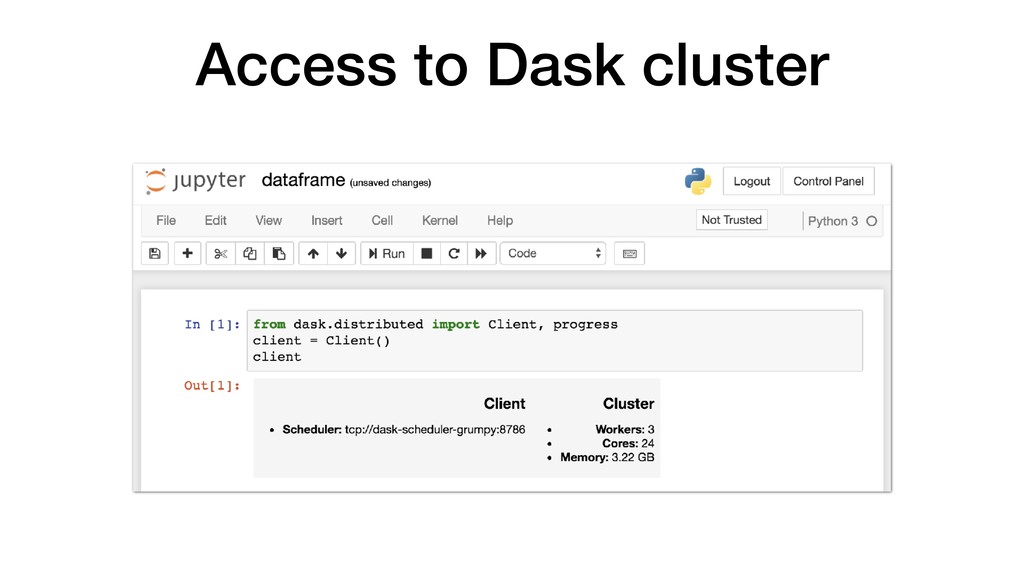
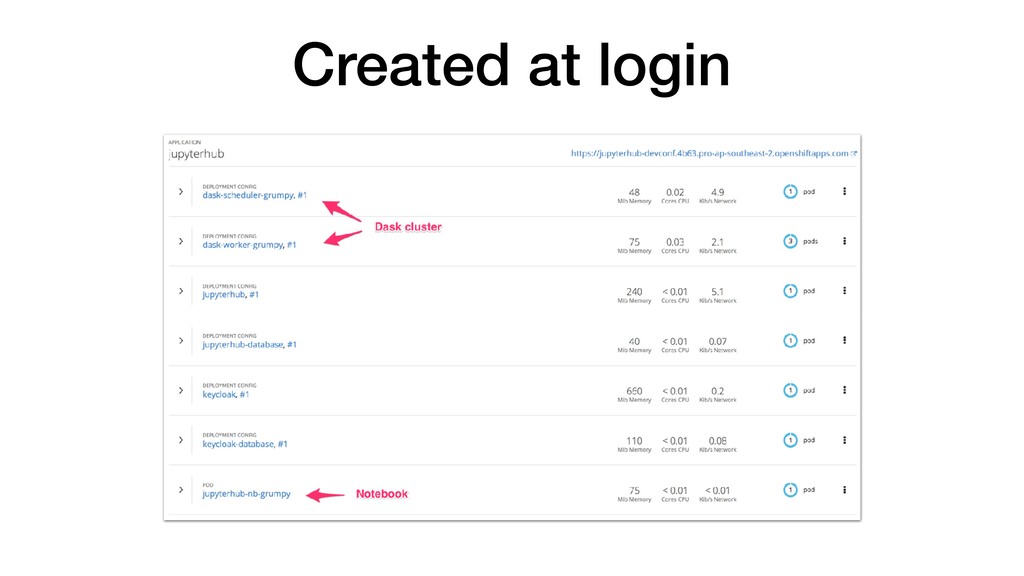
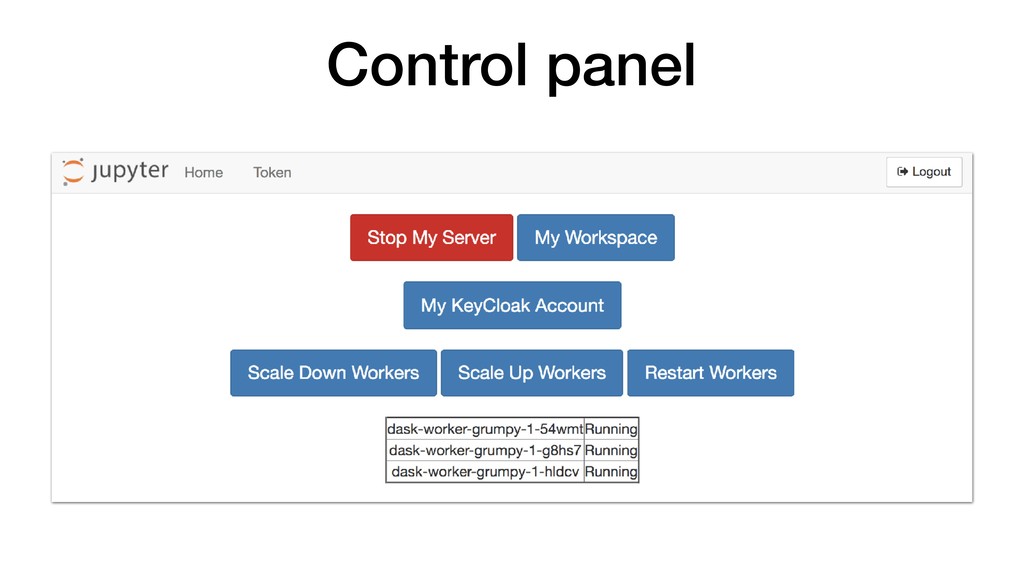
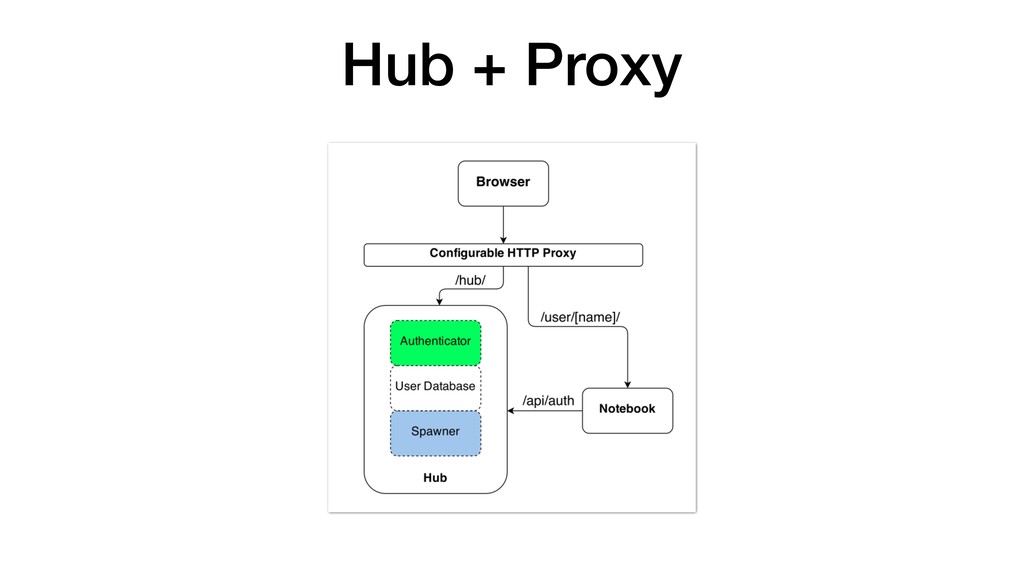
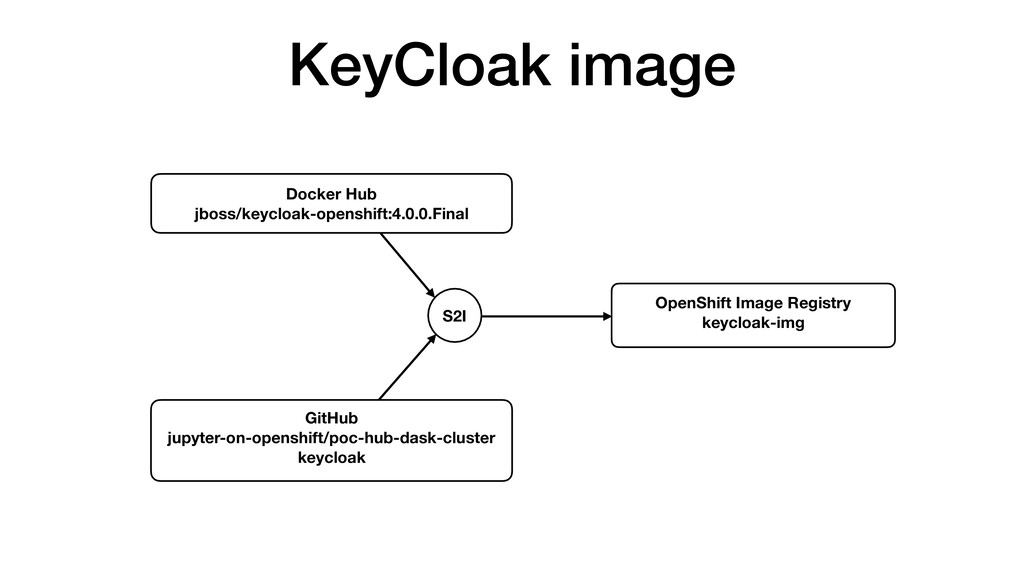
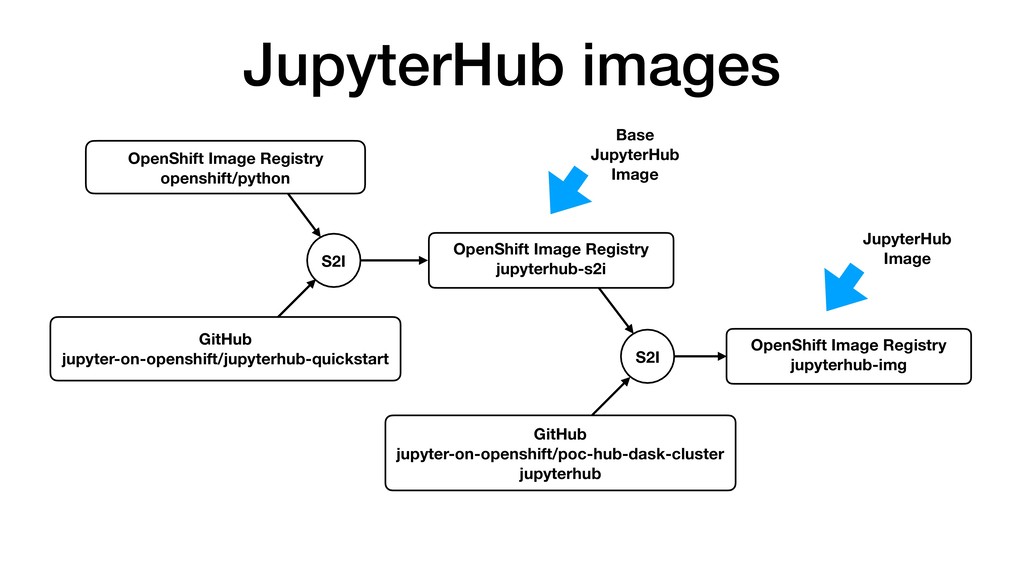
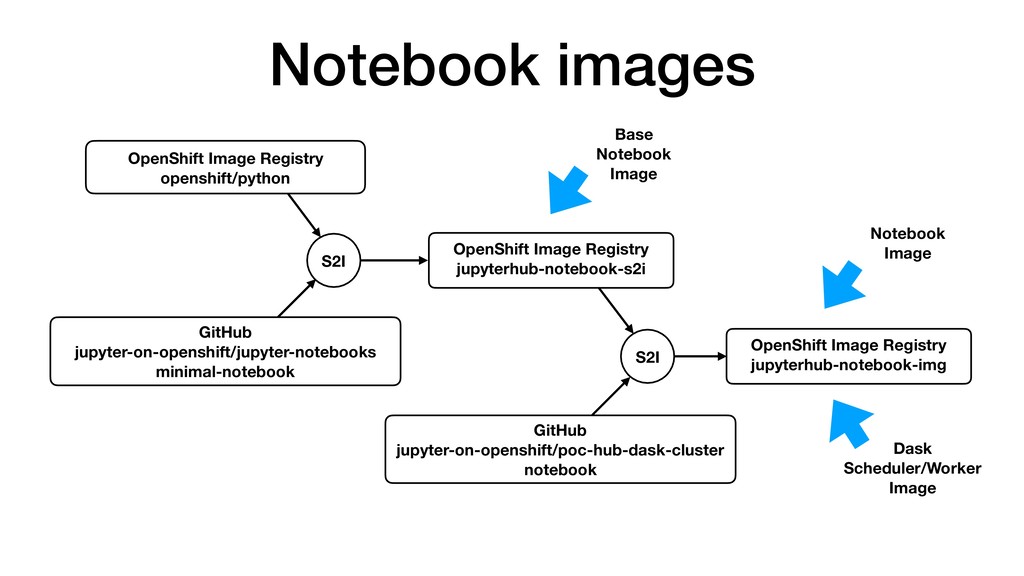
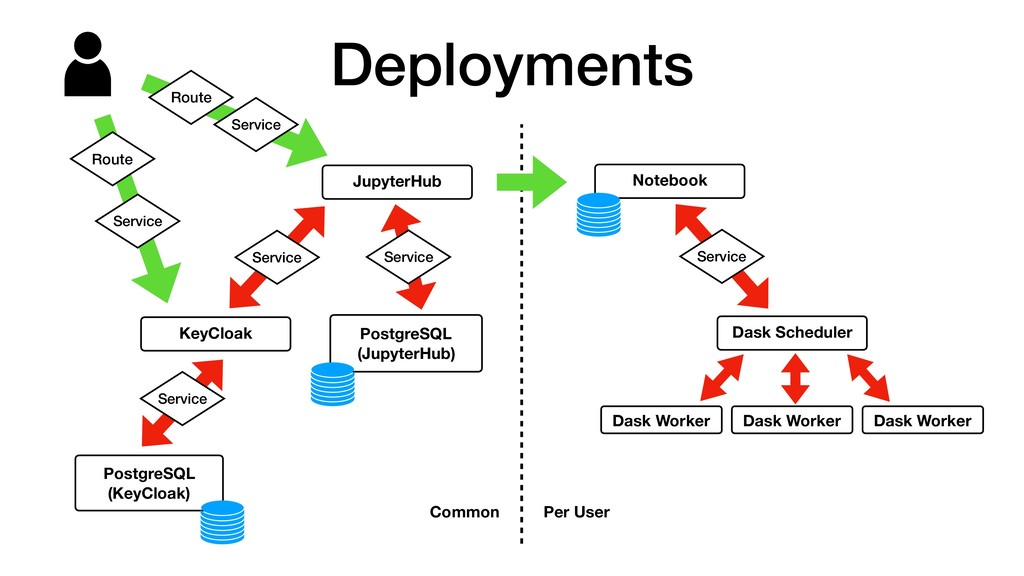
• JupyterHub customisable through use of Source-to-Image. • Can pre-build images with notebooks and required Python packages. • Can attach storage to notebooks for persistence. • Integrate with KeyCloak for user authentication. • Connect to backend cluster for distributed data analytics.
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![Contact me Graham Dumpleton @GrahamDumpleton [email protected]](https://files.speakerdeck.com/presentations/4912cc22f8a047aa80fdd17ed43277e5/slide_50.jpg){kind=link}