Upgrade to Pro
— share decks privately, control downloads, hide ads and more …
Speaker Deck
Features
Speaker Deck
PRO
Sign in
Sign up for free
Search
Search
REALITY低遅延モード配信を支えるリアルタイムサーバとデータパイプライン
Search
gree_tech
PRO
September 18, 2020
Technology
4.4k
1
Share
Embed
Copy iframe code
Copy JS code
Copy link
Start on current slide
REALITY低遅延モード配信を支えるリアルタイムサーバとデータパイプライン
GREE Tech Conference 2020 で発表された資料です。
https://techcon.gree.jp/2020/session/Session-11
gree_tech
PRO
September 18, 2020
More Decks by gree_tech
See All by gree_tech
変わるもの、変わらないもの :OSSアーキテクチャで実現する持続可能なシステム
gree_tech
PRO
0
4.9k
マネジメントに役立つ Google Cloud
gree_tech
PRO
0
71
今この時代に技術とどう向き合うべきか
gree_tech
PRO
3
2.8k
生成AIを開発組織にインストールするために: REALITYにおけるガバナンス・技術・文化へのアプローチ
gree_tech
PRO
0
460
安く・手軽に・現場発 既存資産を生かすSlack×AI検索Botの作り方
gree_tech
PRO
0
460
生成AIを安心して活用するために──「情報セキュリティガイドライン」策定とポイント
gree_tech
PRO
1
2.4k
あうもんと学ぶGenAIOps
gree_tech
PRO
0
580
MVP開発における生成AIの活用と導入事例
gree_tech
PRO
0
610
機械学習・生成AIが拓く事業価値創出の最前線
gree_tech
PRO
0
500
Other Decks in Technology
See All in Technology
Gen3R: 3D Scene Generation Meets Feed-Forward Reconstruction
spatial_ai_network
0
130
ZOZOTOWNの進化と信頼性を両立する負荷試験
zozotech
PRO
2
190
AI時代のYAGNI:「爆速で無駄になった機能」からの学び / 20260720 Naoki Takahashi
shift_evolve
PRO
2
290
AI時代のPlaywright活用(システムテストを自動化する ー 実行エンジンにPla ywrightを選んだ理由)
ynisqa1988
0
130
事業価値を⽣み出すSREへ SREが担うべき意思決定の5層
kenta_hi
2
3.9k
インフラと開発の垣根を超えていき!〜元AWSインフラエンジニアがAWS開発で奮闘している話〜
hatahata021
3
290
AIと共生する開発者プラットフォーム:バクラクのモノレポ×マイクロサービス基盤
sakajunquality
2
3.7k
SRE依存からの脱却 運用を開 発チームへ移す、 フルサイ クル開 発体制の実践
joooee0000
0
3.1k
ボーイスカウトルールでメモリやスキルを改善しよう
azukiazusa1
4
1.4k
“それは自分の仕事じゃない"を 越えて行け
yuukiyo
1
460
脱金融のフューチャー・デザイン / Future Design Beyond Finance
ks91
PRO
0
150
AmplifyHostingConstructからSSRフレームワークのためのホスティング設計を考察する/amplify-hosting-construct
fossamagna
1
210
Featured
See All Featured
Navigating Weather and Climate Data
rabernat
0
350
A brief & incomplete history of UX Design for the World Wide Web: 1989–2019
jct
2
420
Collaborative Software Design: How to facilitate domain modelling decisions
baasie
1
260
Cheating the UX When There Is Nothing More to Optimize - PixelPioneers
stephaniewalter
287
14k
Large-scale JavaScript Application Architecture
addyosmani
515
110k
Fashionably flexible responsive web design (full day workshop)
malarkey
408
67k
Intergalactic Javascript Robots from Outer Space
tanoku
273
27k
No one is an island. Learnings from fostering a developers community.
thoeni
21
3.8k
Responsive Adventures: Dirty Tricks From The Dark Corners of Front-End
smashingmag
254
22k
End of SEO as We Know It (SMX Advanced Version)
ipullrank
3
4.3k
エンジニアに許された特別な時間の終わり
watany
108
250k
Are puppies a ranking factor?
jonoalderson
1
3.7k
Transcript
REALITY低遅延モード配信を支える リアルタイムサーバと データパイプライン 株式会社 Wright Flyer Live Entertainment 増住 啓吾
2 自己紹介 増住 啓吾 株式会社Wright Flyer Live Entertainment - 2017年にGlossom株式会社に入社
- iOS/Android向けアプリの開発やデータ分析基盤 の構築、広告ログ集計システムの開発・運用などを 担当 - グループ内公募制度を利用し、2019年に株式会社 Wright Flyer Live Entertainmentにジョイン - Kubernates・Apache Beamなどを用いた REALITYプラットフォームのライブ配信基盤の開発 を担当
3 REALITYとは?
4 2020/01/08 REALITY低遅延モードリリース
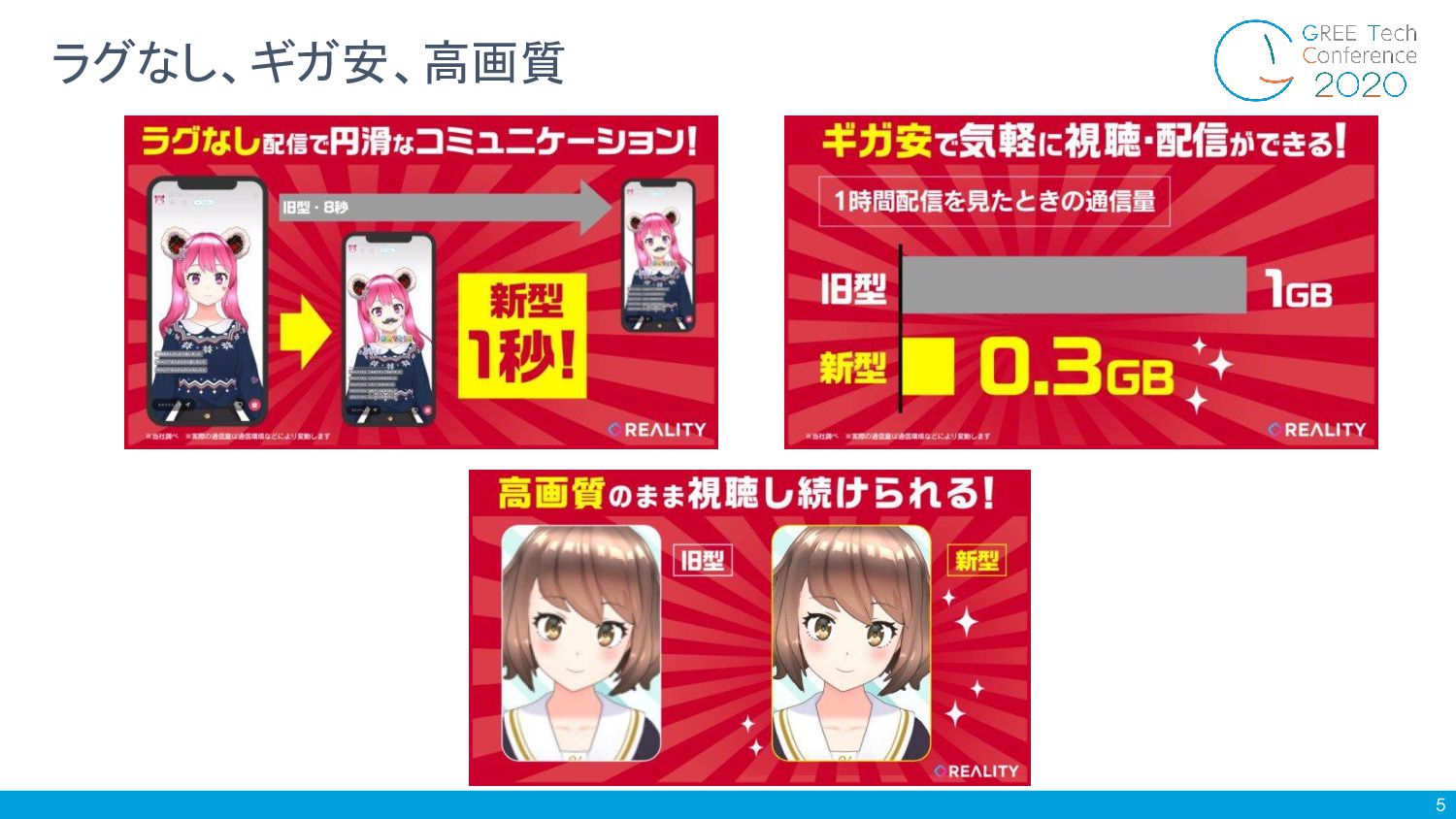
5 ラグなし、ギガ安、高画質
6 低遅延モード配信のフォーマット • REALITYの現行のメイン配信方式 • 配信・視聴ユーザーがそれぞれWebSocketサーバへ接続 • WebSocketサーバを通してデータを送受信する • 配信データの中身はモーション・音声などのデータをProtobuf形式
でシリアライズしたもの
7 解決すべき問題点 • 配信データのボリュームが大きい • チャット等に比べデータ量が非常に多い • 128〜256kbs程度 • パトロール・監査のため、配信データを参照可能な方式で保存して
おく必要がある • 配信音声やラベル付き配信データなどのフォーマット
8 ライブ配信・視聴サーバ
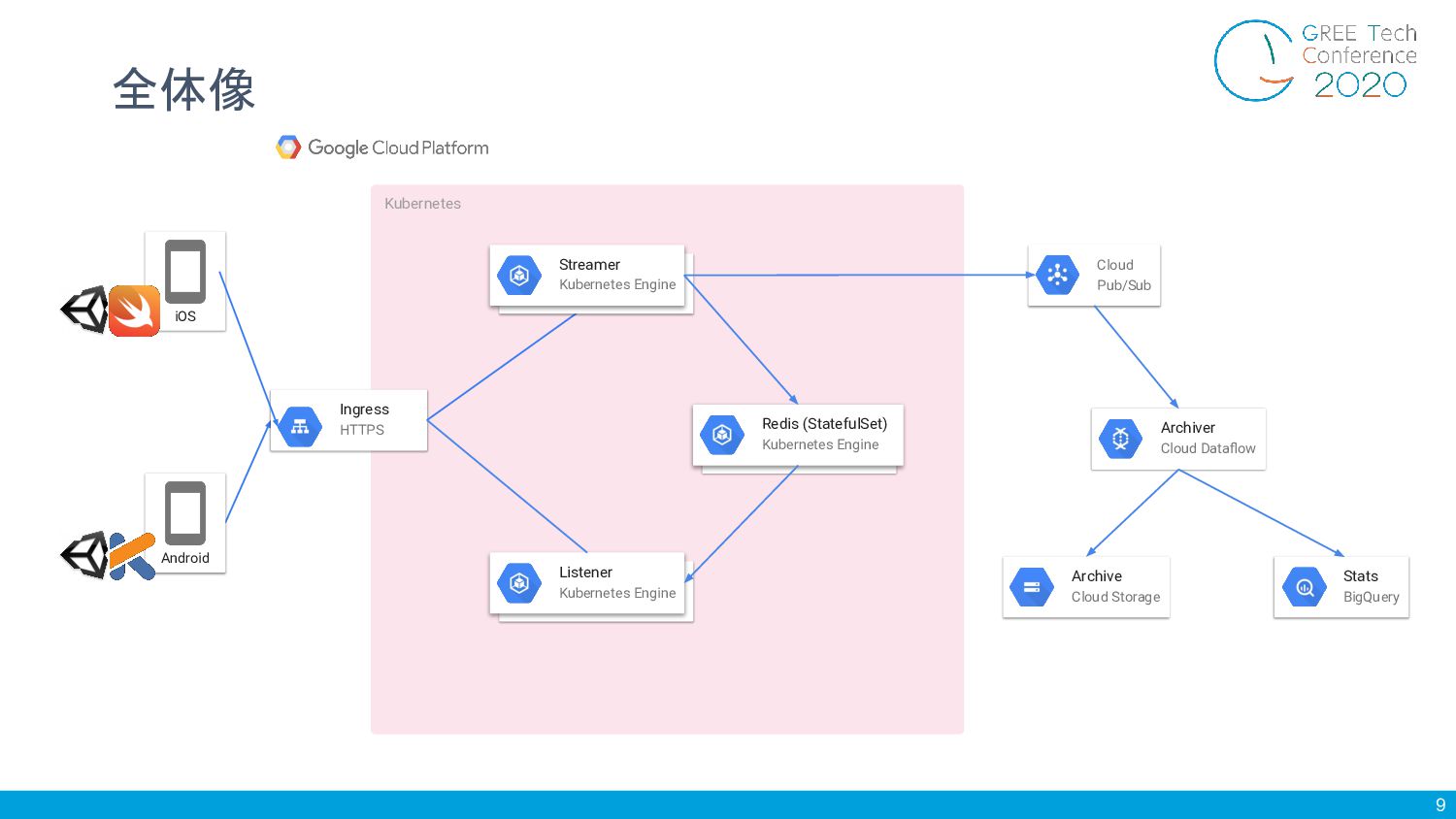
9 全体像 Kubernetes Android iOS Ingress HTTPS Streamer Kubernetes Engine
Redis (StatefulSet) Kubernetes Engine Listener Kubernetes Engine Cloud Pub/Sub Archiver Cloud Dataflow Archive Cloud Storage Stats BigQuery
10 解決すべき問題点 • 配信データのボリュームが大きい • チャット等に比べデータ量が非常に多い • 128〜256kbs程度 • パトロール・監査のため、配信データを参照可能な方式で保存して
おく必要がある • 配信音声やラベル付き配信データなどのフォーマット
11 ライブ配信 / 視聴サーバ - 課題 • WebSocketサーバ ( Node.js
) を通して配信データの送 受信を行う • WebSocketサーバの冗長化はRedis Pub/Subを用いる • ただし、一般的なWebSocket + Redis Pub/Subのパ ターンでは配信・視聴の負荷に耐えきれなくなる
12 WebSocketサーバの負荷分散方式 (1)
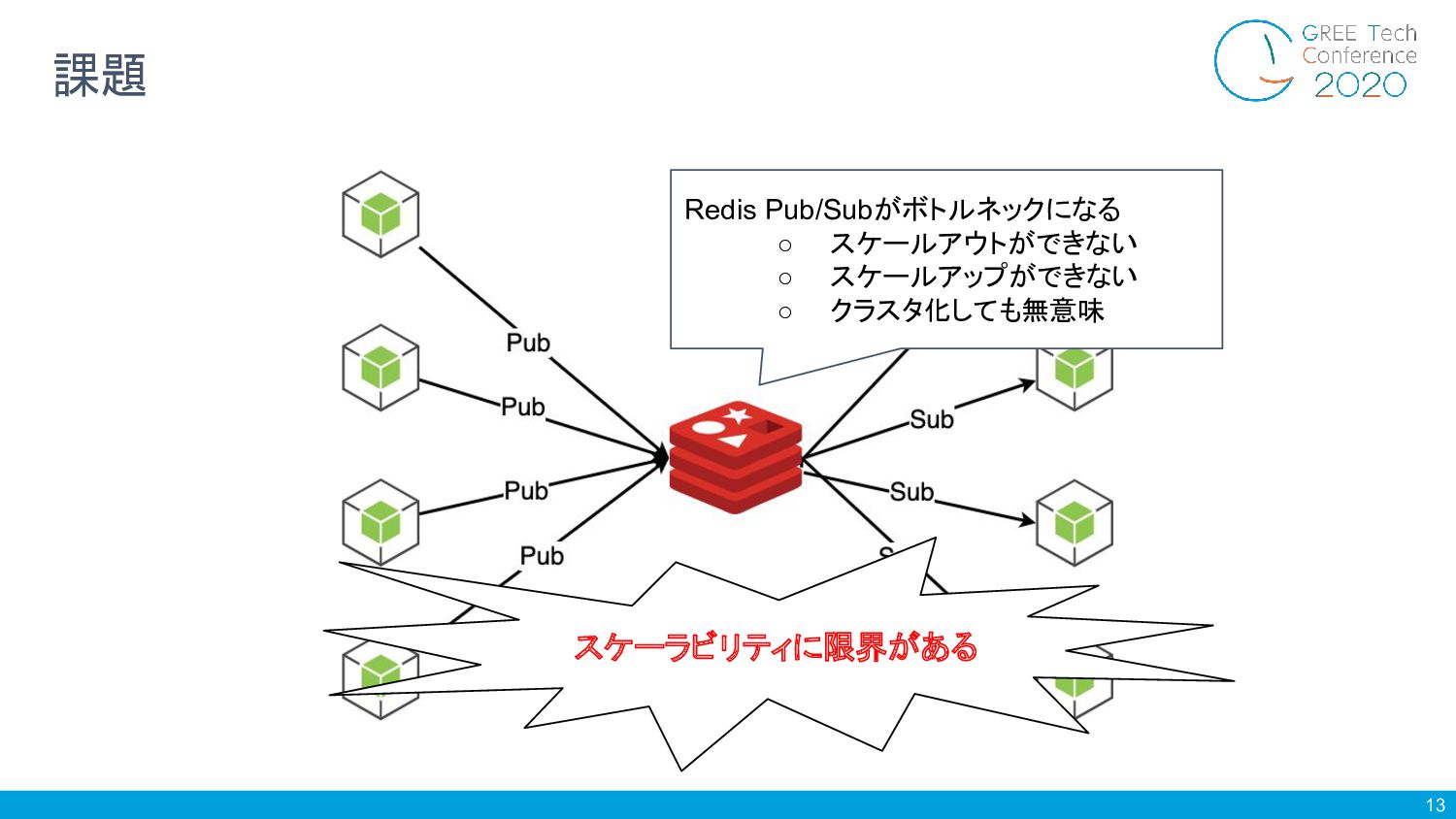
13 課題 Redis Pub/Subがボトルネックになる ◦ スケールアウトができない ◦ スケールアップができない ◦ クラスタ化しても無意味
スケーラビリティに限界がある
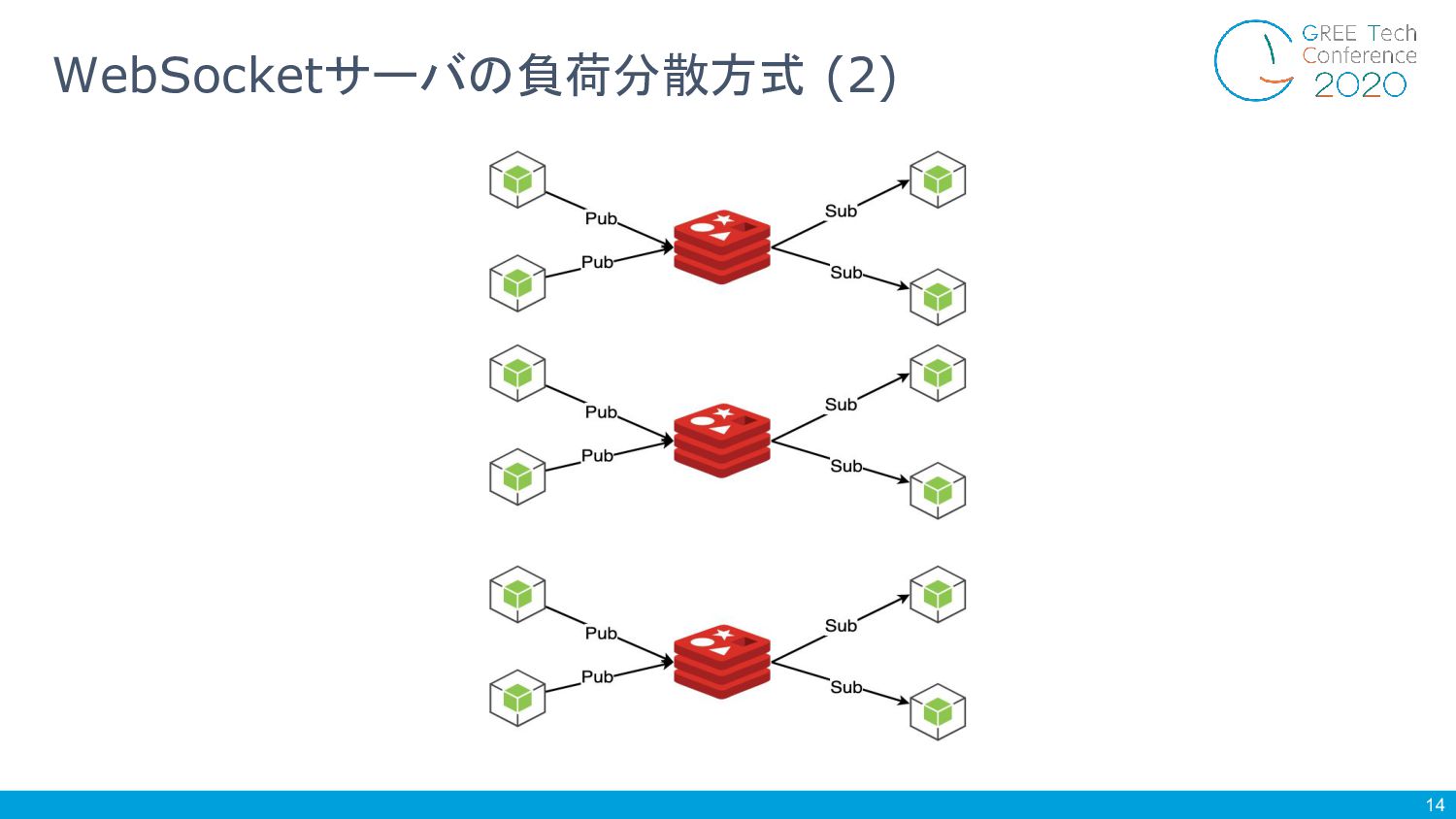
14 WebSocketサーバの負荷分散方式 (2)
15 課題 1.エンドポイントレベルのシャー ディング 2.WebSocketサーバ * N + Redis *
1 の単位でスケール 運用コストが高い
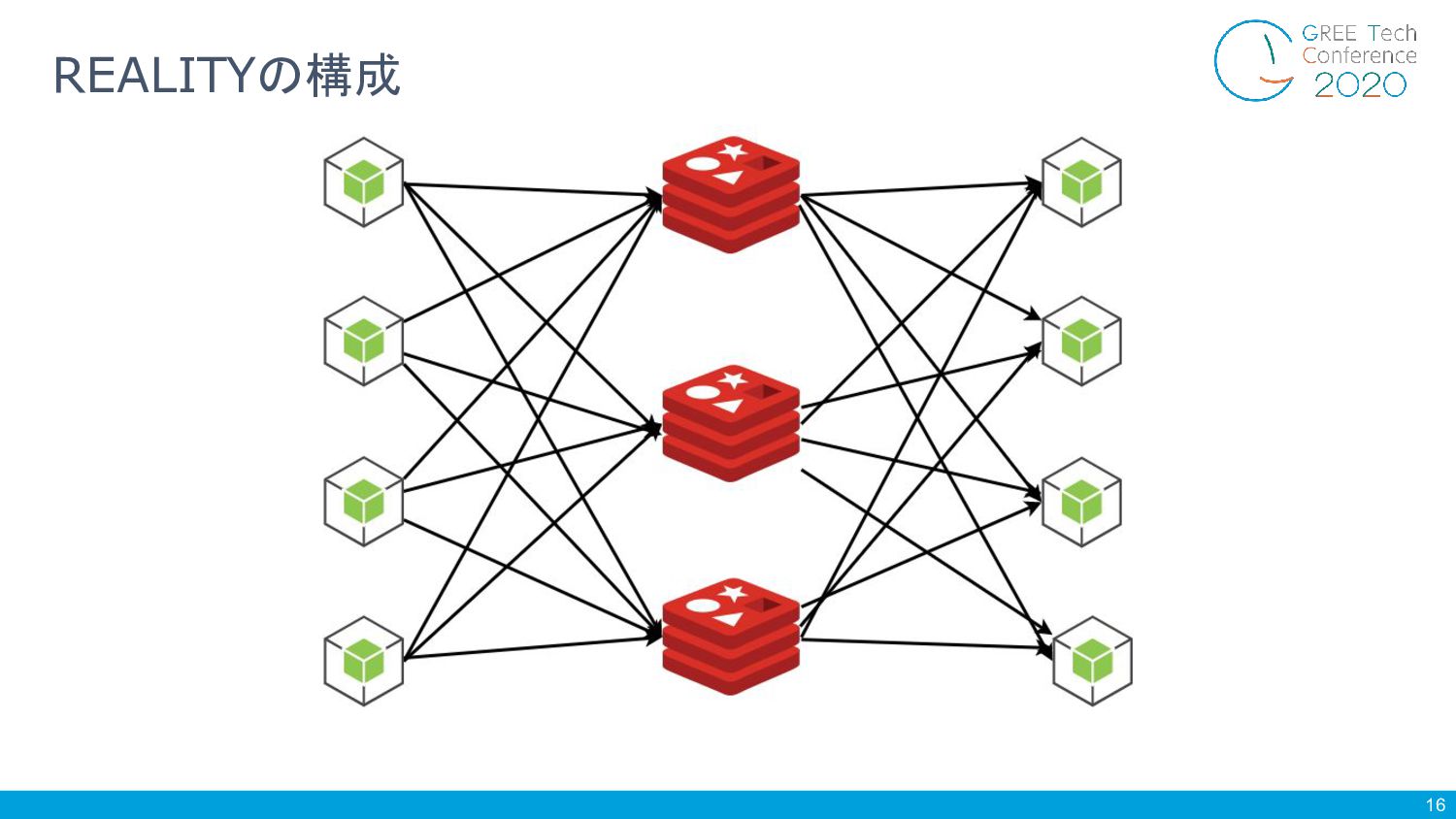
16 REALITYの構成
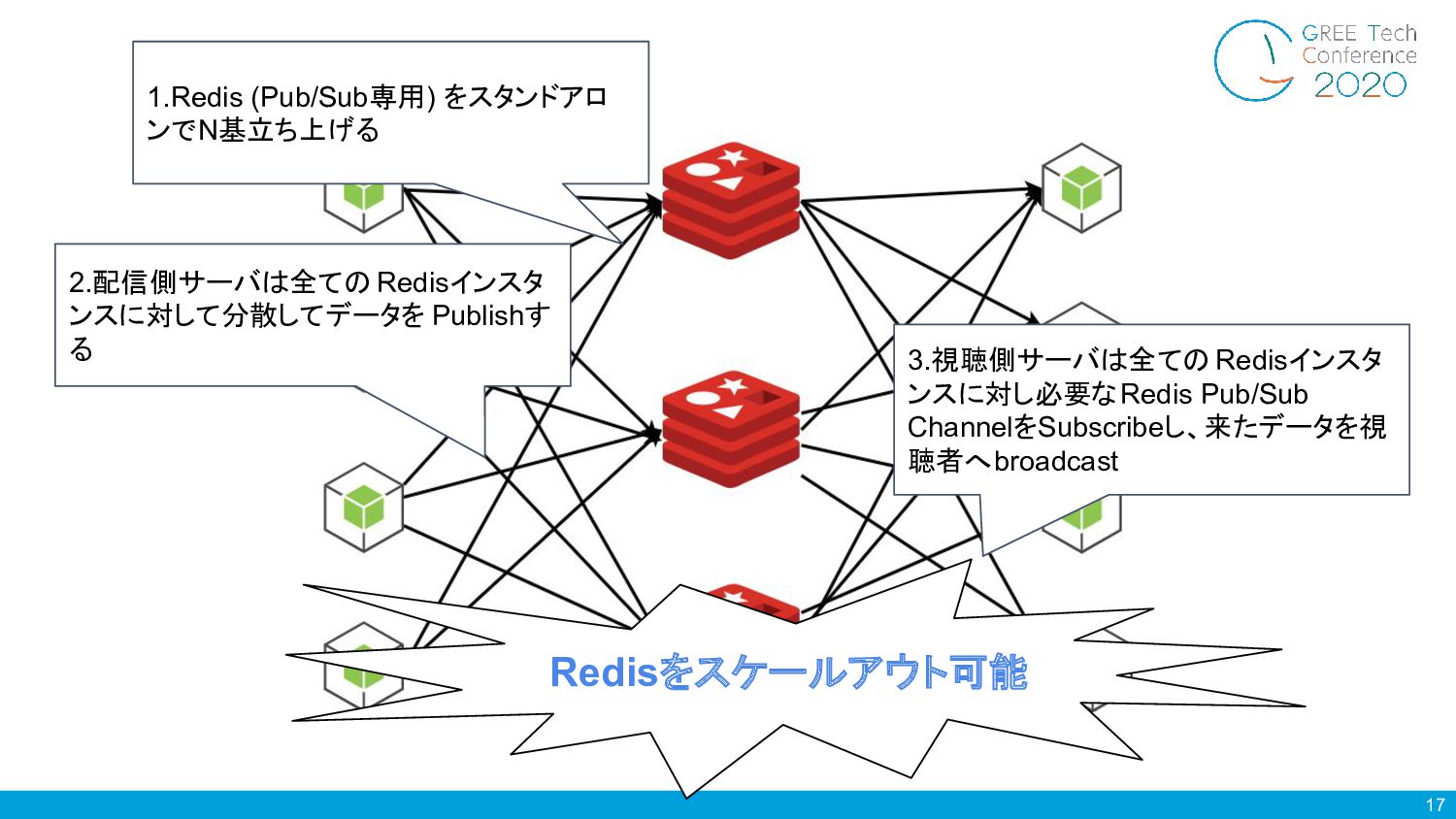
17 2.配信側サーバは全ての Redisインスタ ンスに対して分散してデータを Publishす る 3.視聴側サーバは全ての Redisインスタ ンスに対し必要なRedis Pub/Sub
ChannelをSubscribeし、来たデータを視 聴者へbroadcast Redisをスケールアウト可能 1.Redis (Pub/Sub専用) をスタンドアロ ンでN基立ち上げる
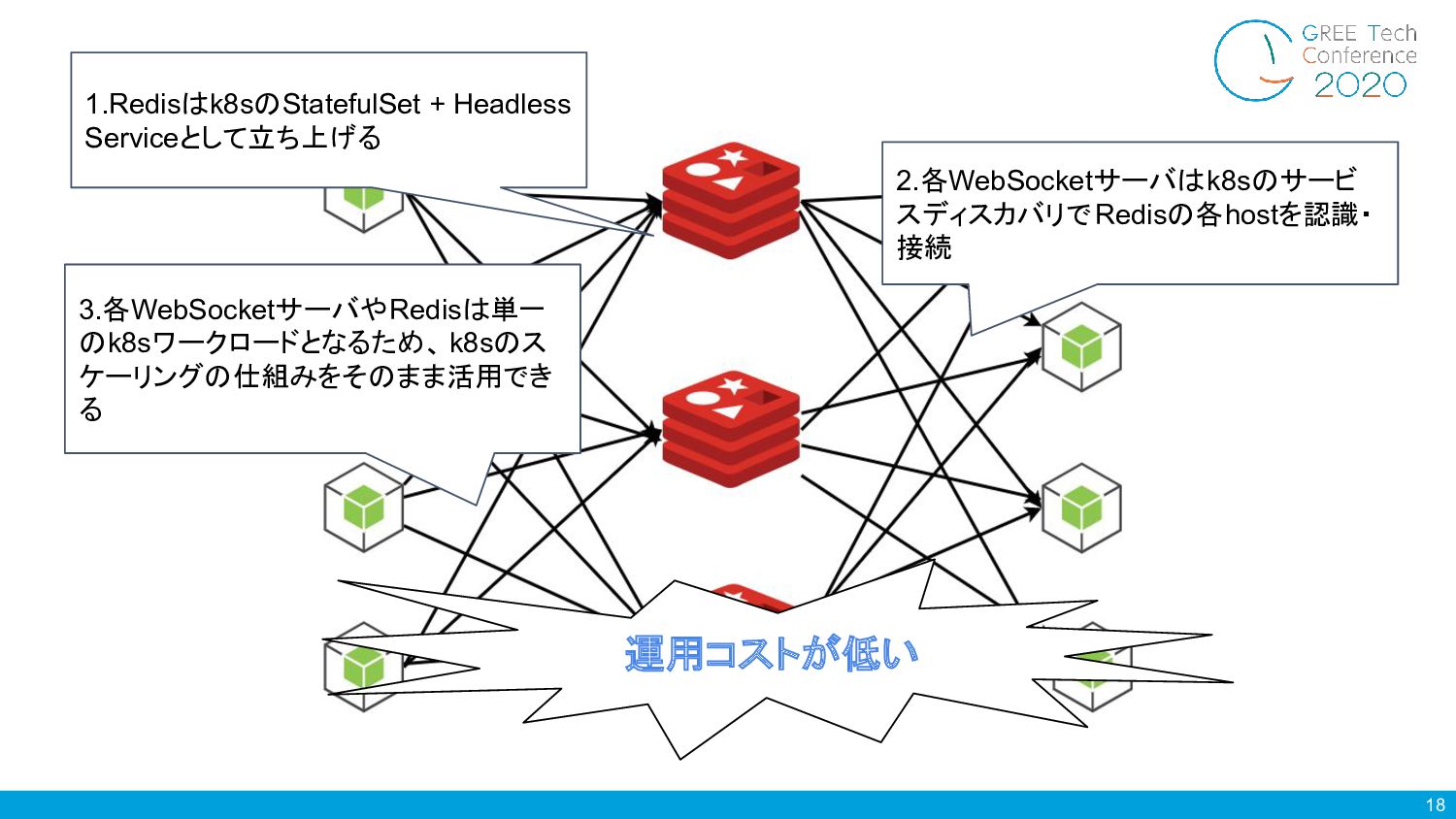
18 1.Redisはk8sのStatefulSet + Headless Serviceとして立ち上げる 2.各WebSocketサーバはk8sのサービ スディスカバリでRedisの各hostを認識・ 接続 運用コストが低い 3.各WebSocketサーバやRedisは単一
のk8sワークロードとなるため、 k8sのス ケーリングの仕組みをそのまま活用でき る
19 ライブ配信 / 視聴サーバ - 構成 • k8sのサービスディスカバリを利用したRedisのスケーリング • Redisはk8sのStatefulSet
+ Headless Serviceを利用 => kube-proxyを通らないのでパフォーマンスも落ちない • Redisのスケールアウトが可能なので、構成全体のスケーラ ビリティを担保できる • k8sのオートスケーリングの仕組みに乗ったスケーリングが 可能なので運用工数も低い
20 ライブ配信 / 視聴サーバ - まとめ • 当該方式の配信・視聴サーバのリリース後7ヶ月経過 • 同時配信数・視聴者数ともに右肩上がりだが、障害なしで安定して動
作 • 基本的にはk8sのオートスケーリングに任せられるので、運用コストも 非常に低い • Redis Pub/Subによる遅延は、アプリ - 配信・視聴サーバ間の通信 に比べて無視できる程度で安定
21 ライブ配信 / 視聴サーバ - その他 • シンプルな構成なので横展開が楽 • 事例1:
コラボ配信サーバ • 「アバタービデオチャット」的な機能を提供するコンポーネント • ボイスチャット用の音声のミキシングも行う • 事例2: ゲーム配信サーバ • ゲームサーバ + ゲーム配信の視聴サーバの機能を提供する
22 解決すべき問題点 (再掲) • 配信データのボリュームが大きい • チャット等に比べデータ量が非常に多い • 128〜256kbs程度 •
パトロール・監査のため、配信データを参照可能な方式で保 存しておく必要がある • 配信音声やラベル付き配信データなどのフォーマット
23 ライブ配信データパイプライン
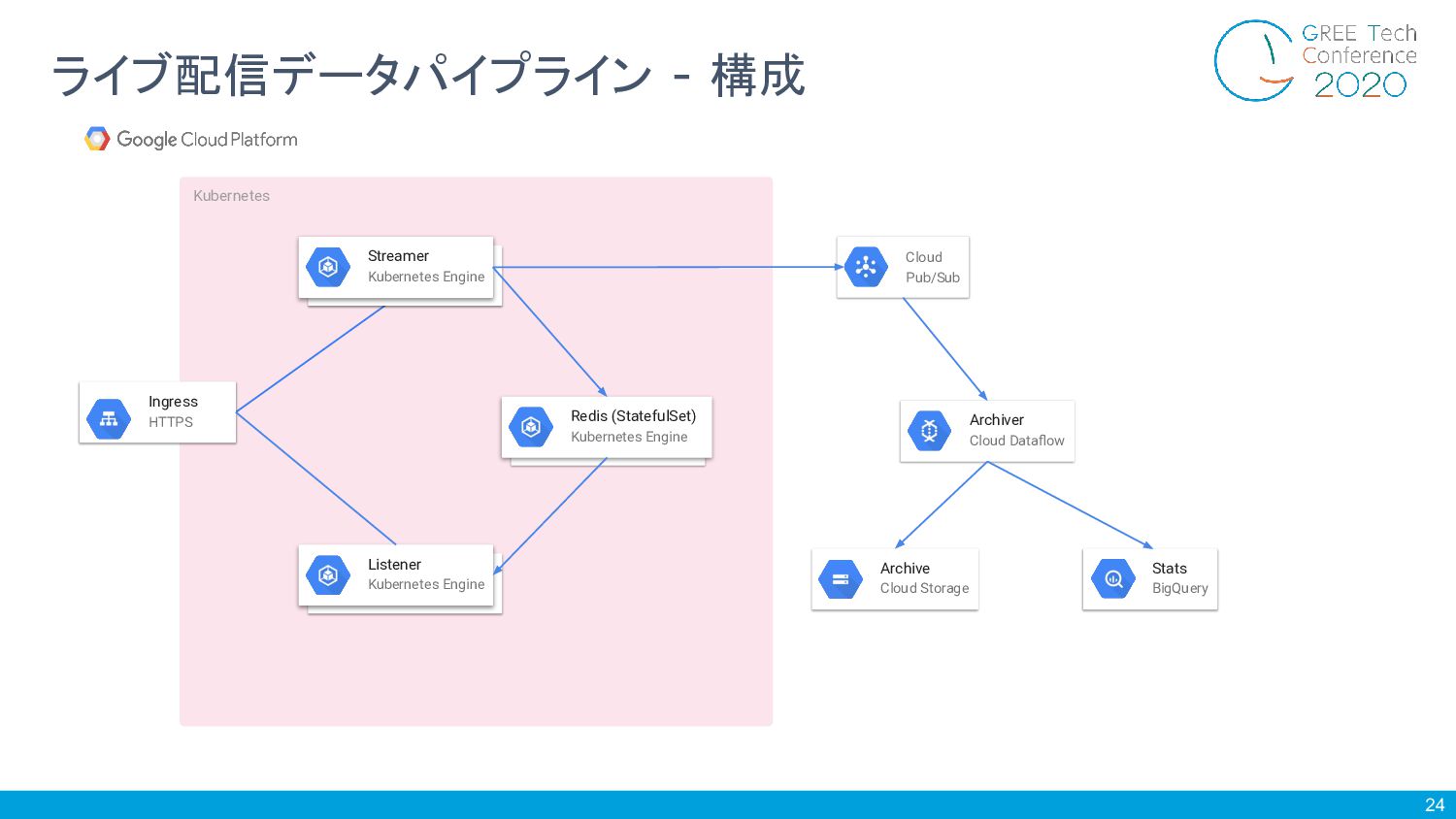
24 ライブ配信データパイプライン - 構成 Cloud Pub/Sub Archiver Cloud Dataflow Archive
Cloud Storage Stats BigQuery Kubernetes Streamer Kubernetes Engine Ingress HTTPS Redis (StatefulSet) Kubernetes Engine Listener Kubernetes Engine
25 ライブ配信データパイプライン - 構成 Cloud Pub/Sub Archiver Cloud Dataflow Archive
Cloud Storage Stats BigQuery Kubernetes Streamer Kubernetes Engine Ingress HTTPS Redis (StatefulSet) Kubernetes Engine Listener Kubernetes Engine 1.配信データをCloud Pub/Sub TopicへPublish 2.Cloud Dataflow Jobが Cloud Pub/Sub Subscription 経由で配信データを読み出す 3.配信データを Streaming処理で集計・ 加工して保存
26 ライブ配信データパイプライン - 概要 • 配信サーバはCloud Pub/Sub Topicへラベル付き配信データ をPublish •
Cloud DataFlow Job ( Apache Beam Java ) がCloud Pub/Sub Subscription経由でデータを読み出す • 読み出した配信データをApache Beam Pipelineで処理 • ラベル付き配信データ、監査用音声アーカイブファイル、分 析用統計情報などを生成 • 生成したデータをCloud Storageへ書き込む
27 ライブ配信データパイプライン - インフラ • Cloud DataFlow Streaming Engineを使用 •
Streaming処理とオートスケーリングを両立 • Worker Machineの分だけ自動でスケールしていく • キャパシティプランニングもほぼ不要 • deployもJavaのビルドだけで完結するので楽
28 Apache Beam??
29 ライブ配信データパイプライン - Apache Beam • バッチ・ストリーミング処理を統合して実行できる分散処理 フレームワーク • REALITYではApache
Beam Javaを使用 • 基本的にはJavaアプリケーションなのでできることの範囲が 広い • 当然JNIも使えるのでネイティブコードも利用可能 • その上でさらに分散処理のメリットを享受できる • Apache Sparkなどと比較すると、Cloud DataFlowとの連携 のメリットが非常に大きい
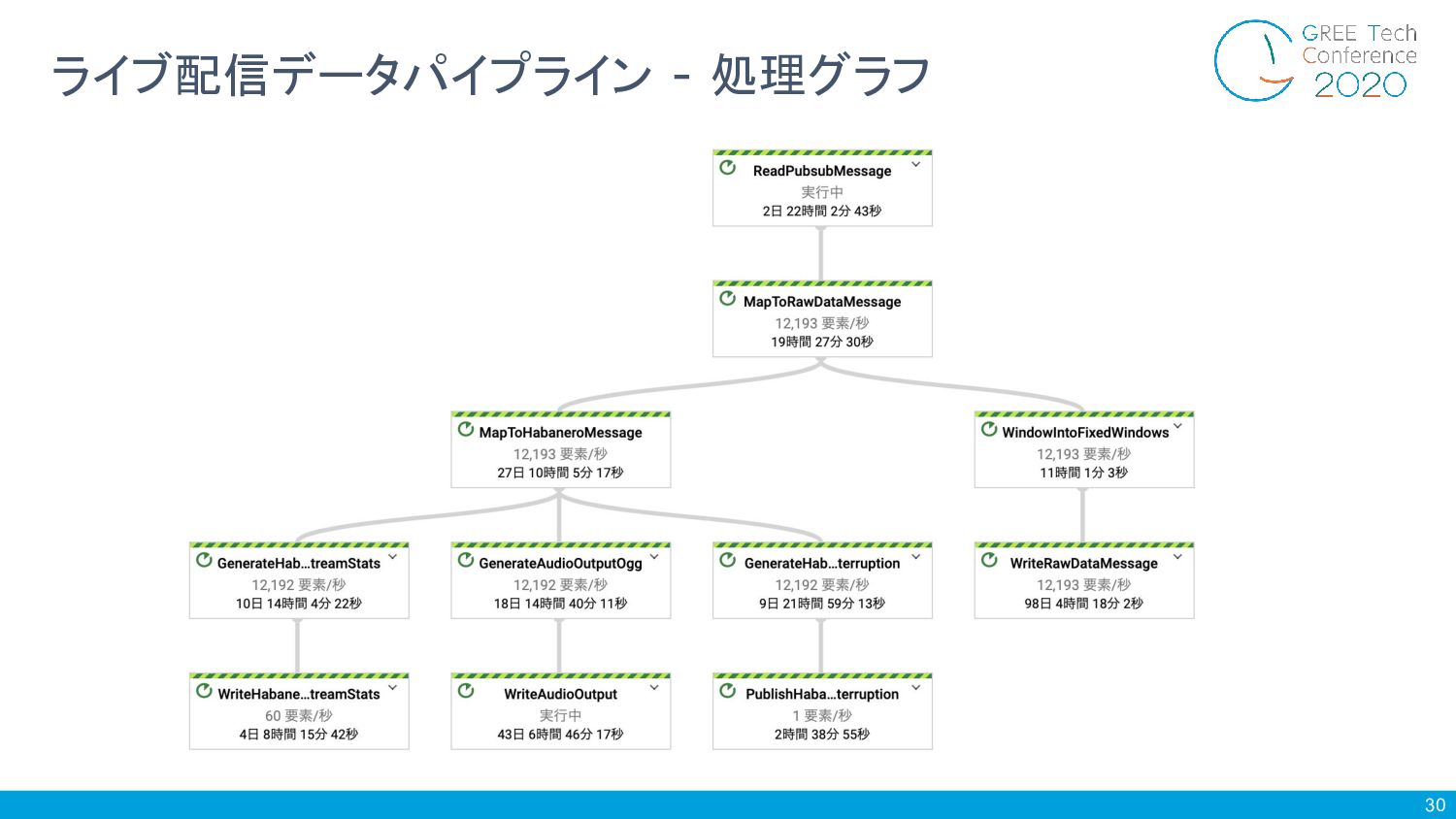
30 ライブ配信データパイプライン - 処理グラフ
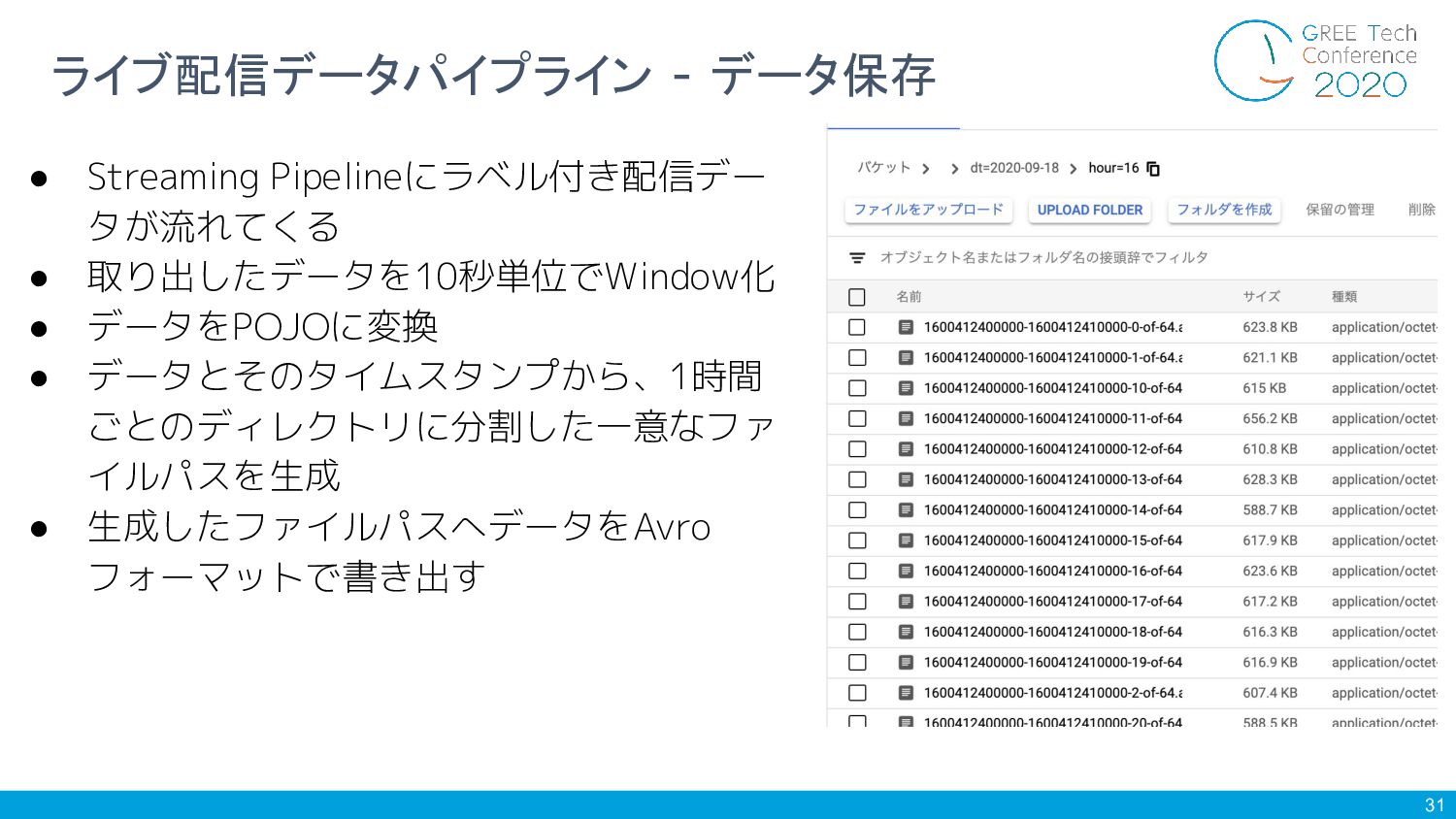
31 ライブ配信データパイプライン - データ保存 • Streaming Pipelineにラベル付き配信デー タが流れてくる • 取り出したデータを10秒単位でWindow化
• データをPOJOに変換 • データとそのタイムスタンプから、1時間 ごとのディレクトリに分割した一意なファ イルパスを生成 • 生成したファイルパスへデータをAvro フォーマットで書き出す
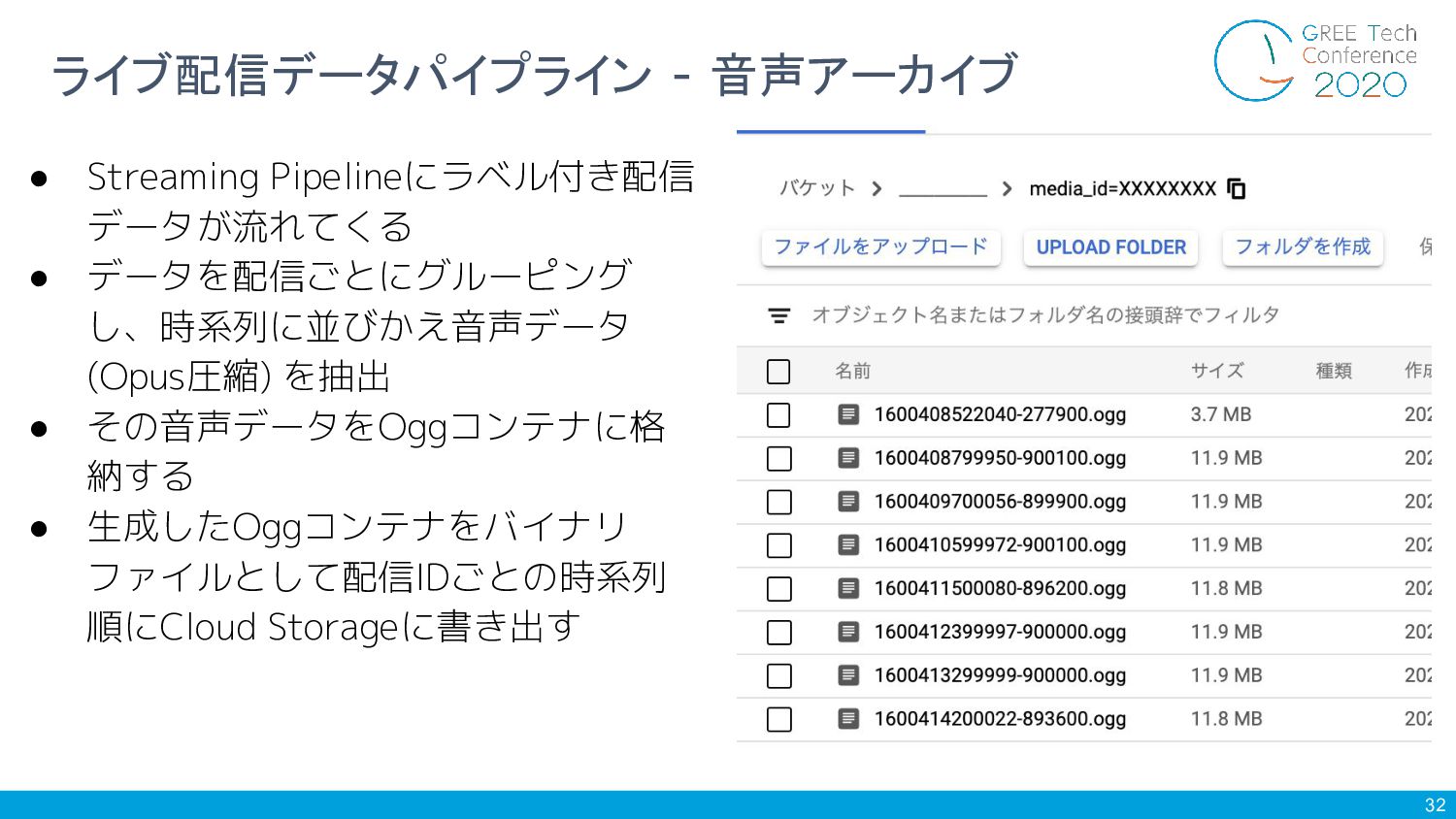
32 ライブ配信データパイプライン - 音声アーカイブ • Streaming Pipelineにラベル付き配信 データが流れてくる • データを配信ごとにグルーピング
し、時系列に並びかえ音声データ (Opus圧縮) を抽出 • その音声データをOggコンテナに格 納する • 生成したOggコンテナをバイナリ ファイルとして配信IDごとの時系列 順にCloud Storageに書き出す
33 ライブ配信データパイプライン - まとめ • 同時配信数の増加に伴い比例して処理データ量も増えていったが、全て Cloud Dataflow側で吸収してくれるので特に追加のオペレーションの必要 はなかった •
データロストの発生もなし • サーバ費用の面では当然それなりのコストは発生するものの、想定通りにお さまる
34 結果
35 解決された問題点 • 配信データのボリュームが大きい • チャット等に比べデータ量が非常に多い • 128〜256kbs程度 • パトロール・監査のため、配信データを参照可能な方式で保存して
おく必要がある • 配信音声やラベル付き配信データなどのフォーマット
36 おわりに
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}