Upgrade to Pro
— share decks privately, control downloads, hide ads and more …
Speaker Deck
Features
Speaker Deck
PRO
Sign in
Sign up for free
Search
Search
Claude Codeを使って3カ月の分析プロジェクトが 60時間で終わった話
Search
Sponsored
·
Your Podcast. Everywhere. Effortlessly.
Share. Educate. Inspire. Entertain. You do you. We'll handle the rest.
→
TomoyukiMurakami
March 19, 2026
15
0
Share
Embed
Copy iframe code
Copy JS code
Copy link
Start on current slide
Claude Codeを使って3カ月の分析プロジェクトが 60時間で終わった話
TomoyukiMurakami
March 19, 2026
More Decks by TomoyukiMurakami
See All by TomoyukiMurakami
データサイエンスはオワコンなのか?
greenmidori
0
360
生成AIで変わるAI開発の現場とジュニアのキャリアデザイン
greenmidori
0
280
10分で分かるデータ民主化
greenmidori
0
850
AI民主化時代のツール活用
greenmidori
0
740
データを資産にする取り組み
greenmidori
1
840
DLG Cross 第1回オープニングトーク
greenmidori
0
93
データマネジメントを個人が気軽に学べる機会を
greenmidori
1
890
スポンサードセッション_今後の流れ.pdf
greenmidori
0
100
データラーニングアカデミー_データサイエンティストを目指す人のためのキャリア戦略
greenmidori
1
160
Featured
See All Featured
Easily Structure & Communicate Ideas using Wireframe
afnizarnur
194
17k
What does AI have to do with Human Rights?
axbom
PRO
1
2.2k
Building a Scalable Design System with Sketch
lauravandoore
463
34k
Paper Plane (Part 1)
katiecoart
PRO
0
9.6k
Reflections from 52 weeks, 52 projects
jeffersonlam
356
21k
Why Mistakes Are the Best Teachers: Turning Failure into a Pathway for Growth
auna
0
180
How To Stay Up To Date on Web Technology
chriscoyier
790
250k
For a Future-Friendly Web
brad_frost
183
10k
Organizational Design Perspectives: An Ontology of Organizational Design Elements
kimpetersen
PRO
1
760
Making Projects Easy
brettharned
120
6.7k
Information Architects: The Missing Link in Design Systems
soysaucechin
0
1k
Darren the Foodie - Storyboard
khoart
PRO
3
3.4k
Transcript
Claude Codeを使って 3カ月の分析プロジェクトが 60時間で終わった話 480時間 → 60時間 | 87%の工数削減 株式会社データラーニング
村上智之
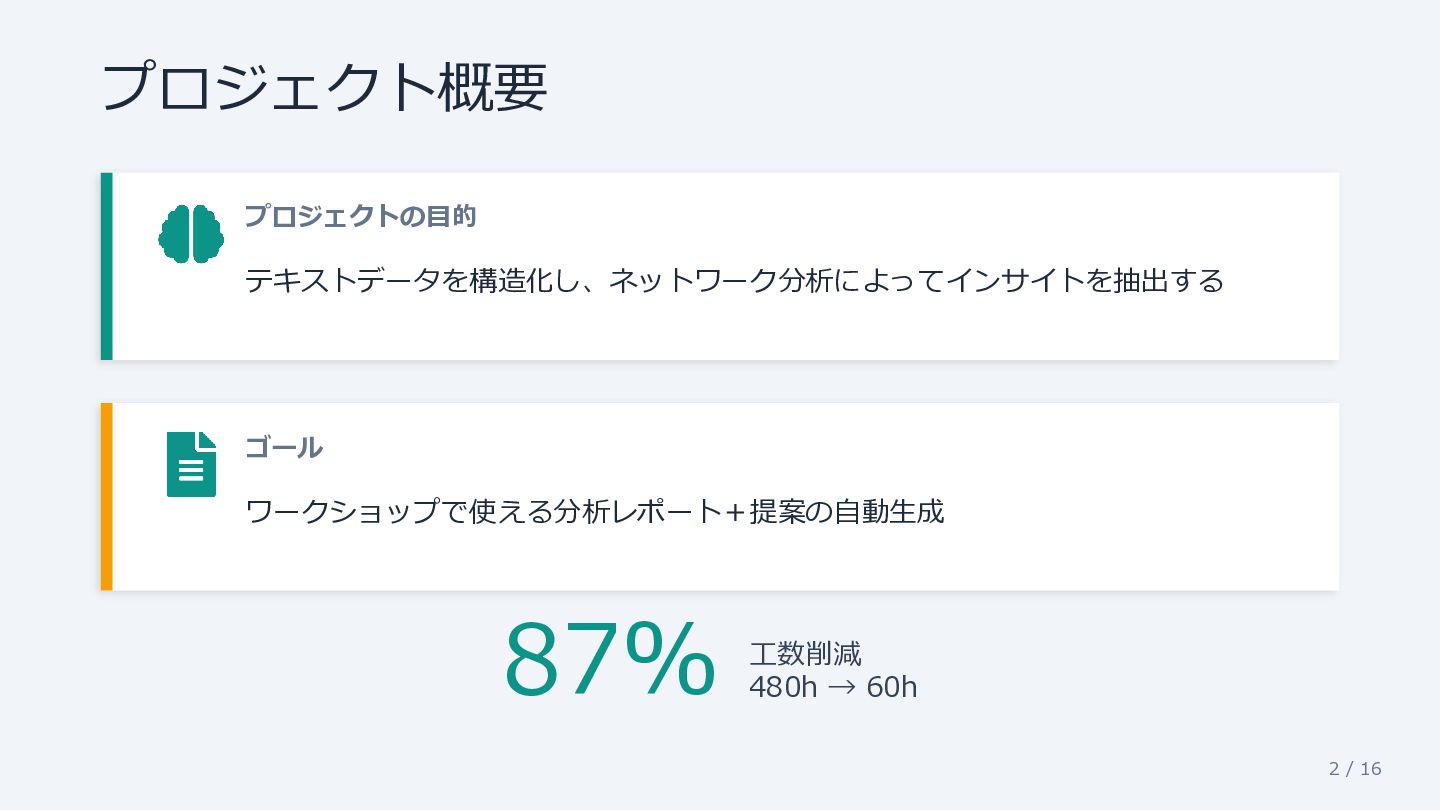
2 / 16 プロジェクト概要 プロジェクトの目的 テキストデータを構造化し、ネットワーク分析によってインサイトを抽出する ゴール ワークショップで使える分析レポート+提案の自動生成 87% 工数削減
480h → 60h
13 / 16 成果物の全体像 ネットワークモデル ノード+エッジで構成された 構造化データ テキスト分類結果 大量テキスト →
ノードへのマッピング 分析レポート 基礎・ネットワーク・切り口別 チャート多数 インタラクティブ可視化 D3.jsネットワークビューア アクション提案 分析結果に基づく提案 +実行ロードマップ Pythonスクリプト 全てAI生成、再実行可能な パイプライン
3 / 16 分析の全体像 — 8ステップ 1 分類体系の構築 テキストからラベル抽出 2
関係性の構築 ノード間エッジを定義 3 テキスト分類 大量テキストをマッピング 4 基礎統計分析 頻度・Lift値・分布 5 ネットワーク分析 共起・中心性・クラスタ D3.jsによる可視化 6 切り口別分析 多角的に比較 7 提案策定 アクション提案 8 エグゼクティブ サマリー 意思決定者向け要約 最大のボトルネック:Step 3 テキスト分類 学習データ作成 → 人手ラベリング → 一致率検証 → ルール修正…の反復
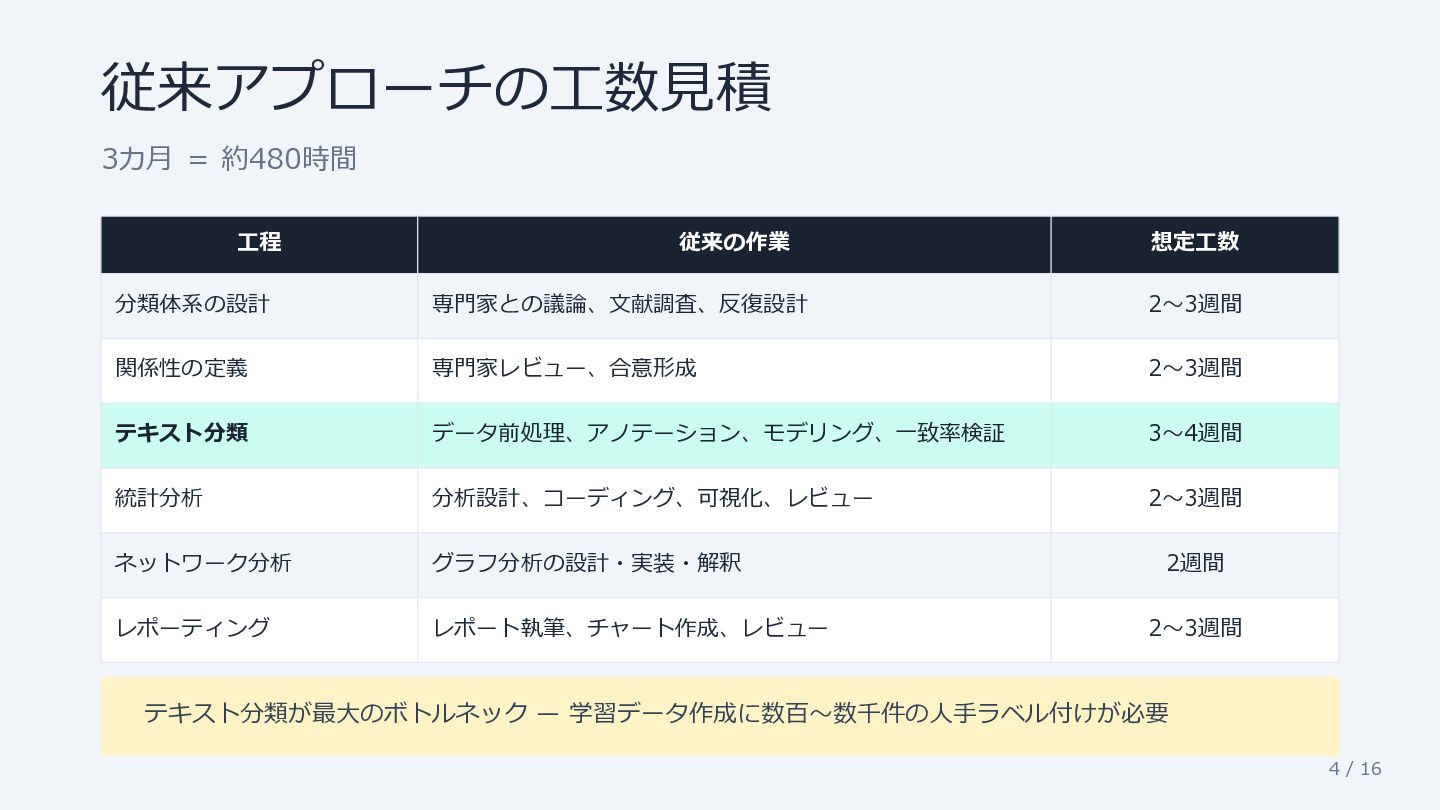
4 / 16 従来アプローチの工数見積 3カ月 = 約480時間 工程 従来の作業 想定工数
分類体系の設計 専門家との議論、文献調査、反復設計 2〜3週間 関係性の定義 専門家レビュー、合意形成 2〜3週間 テキスト分類 データ前処理、アノテーション、モデリング、一致率検証 3〜4週間 統計分析 分析設計、コーディング、可視化、レビュー 2〜3週間 ネットワーク分析 グラフ分析の設計・実装・解釈 2週間 レポーティング レポート執筆、チャート作成、レビュー 2〜3週間 テキスト分類が最大のボトルネック — 学習データ作成に数百〜数千件の人手ラベル付けが必要
5 / 16 テキスト分類の革新 従来の機械学習 × 学習データの作成が必要(数百〜数千件) × 人手でのラベル付け →
致率検証 × ラベル体系変更 → 学習データから作り直し × 数百クラスだと精度が出にくい LLMゼロショット分類 ✓ 学習データ一切不要 ✓ プロンプト書き換えで即座に再実行 ✓ 数百クラスのマルチラベルも実用精度 ✓ Confidence scoreで品質管理
生成AIで何を変えたか アーキテクチャと技術スタック
7 / 16 技術スタック 役割 技術 コード生成・設計 Claude Code テキスト分類・関係推論
Gemini API(構造化出力 + Pydantic) 統計分析 Python(scipy, networkx) 可視化 matplotlib / D3.js Claude Code(開発パートナー) 設計書作成 / 全Pythonスクリプト生成 分析方針の議論 / レポート自動生成 Gemini API(分析エンジン) テキスト→ノード分類(バッチ処理) ノード間の関係推論 / テーマクラスタリング
8 / 16 Claude Codeが担った範囲 設計 フェーズ設計書、Pydanticスキーマ定義、プロンプト設計 実装 全Pythonスクリプト(一行も手書きしていない) 分析
結果の解釈、方針転換の判断支援 レポート Markdownレポートの自動生成(チャート埋め込み) 可視化 D3.jsネットワークビューア(自己完結型HTML)
9 / 16 60時間の内訳 Phase 1 〜10時間 Day 1-2 5h
分類体系の精製 Day 3 3h ノード間関係の試作 Day 4 2h D3.jsネットワーク可視化 Phase 2 〜50時間 Day 5-6 8h テキスト全量分類 Day 7-8 5h 全ノード関係構築 Day 9-12 12h 統計+ネットワーク分析 Day 13-15 10h 切り口別分析+サマリー Day 16-18 15h FB対応・修正・品質向上 Phase 1だけで従来3カ月分の分類体系+可視化が完成 従来 480h 60h
10 / 16 「対話しながら進める」ワークフロー 1 方針を自然言語で指示 「セグメント別のLift値を出して、ヒートマップで可視化して」 2 Claude Codeがスクリプト生成・実行
3 結果を確認、フィードバック 「サンプル数も表示して」「表示項目を増やして」 4 即座に修正・再実行 5 レポートに統合 方針転換もスムーズ:従来「数日〜1週間」→ Claude Codeなら「30分〜1時間」
12 / 16 人間がやったこと = AIに任せなかったこと 分析フレームワークの設計 何を明らかにしたいか、どう構造化するか ドメイン知識の注入 ノードの定義、関係性の妥当性判断
品質管理 分類結果のサンプルレビュー、閾値設定 方針判断 横断比較 → 特定セグメント深堀りへの転換 結果の解釈 統計的発見をビジネス上の示唆に翻訳 ステークホルダー対応 ワークショップ設計、報告 AIは「手を動かす」部分を引き受けた。 人間は「何をやるか」「なぜやるか」「結果をどう使うか」に集中した。
14 / 16 再現性 — 他のデータで使えるか パラメータ化済み データ差し替えで別案件にも適用可能 分類体系は汎用的 再利用可能な構造化フレームワーク
低コスト Gemini APIの全工程コスト 約$5〜10(Flashモデル) ミニマル体制 1人のアナリスト+Claude Code+Gemini API 従来チーム3人 × 3カ月(480時間) → 1人 × 60時間 = 87%削減
まとめ 1 コードは1行も手書きしていない 2 テキスト分類をLLMに委託し最大ボトルネックを解消 3 方針転換のコストがほぼゼロ 4 人間は判断に集中 5
再現可能なパイプライン — 横展開可能 生成AIは「分析を速くする」だけでなく、「分析の試行錯誤を安くする」
Q & A ご質問・ご相談お待ちしています 株式会社データラーニング 村上 智之
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}