N πijt − J ∑ ℓ=1 λijℓt ≥ 0, ∀ i = 1, · · · , N; j = 1, · · · , J; t = 1, · · · , T 0 ≤ pjt ⊥ − N ∑ i=1 ∑ j′∈Jf λij′jt ≥ 0, ∀ j = 1, · · · , J; t = 1, · · · , T 0 ≤ λijℓt ⊥ vijℓt + pℓt − xT ℓt βi − αi mcjt + ξℓt αi ≥ 0, ∀ i = 1, · · · , N; j = 1, · · · , J; ℓ = 1, · · · , J; t = 1, · · · , T 0 ≤ πijt ⊥ γit + αi pjt − (xT jt βi − αi mcjt + ξjt ) ≥ 0, ∀ i = 1, · · · , N; j = 1, · · · , J; t = 1, · · · , T 0 ≤ γit ⊥ 1 − J ∑ j=1 πijt ≥ 0. ∀ i = 1, · · · , N; t = 1, · · · , T Return 47 / 47
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
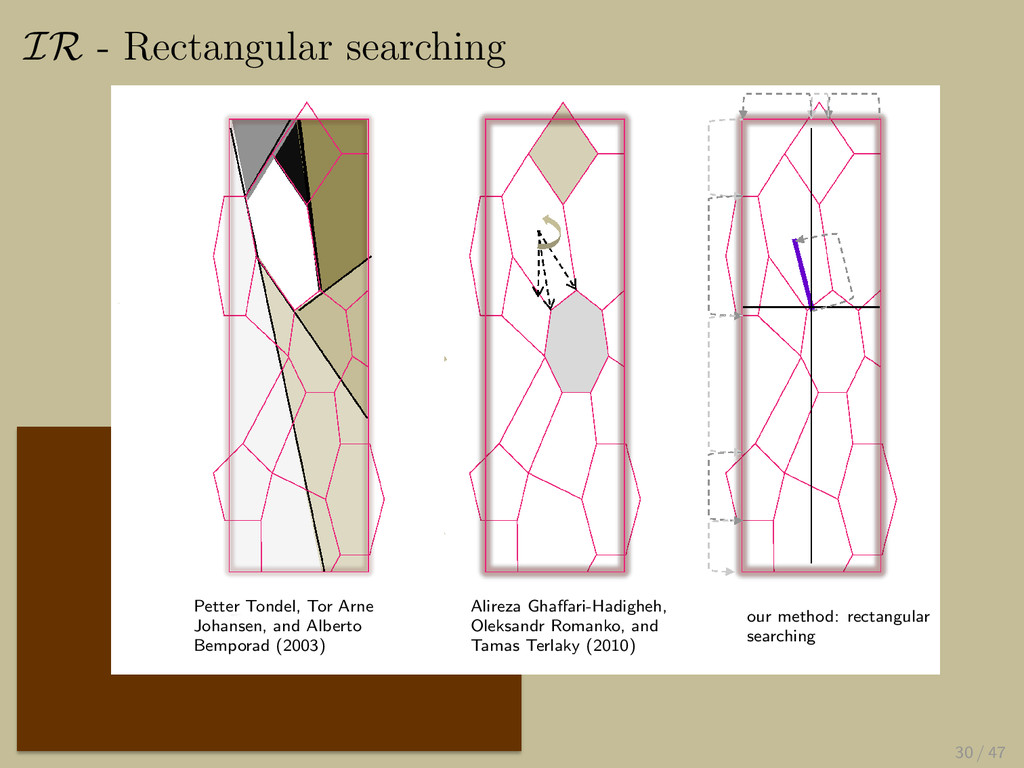{kind=link}
{kind=link}
{kind=link}
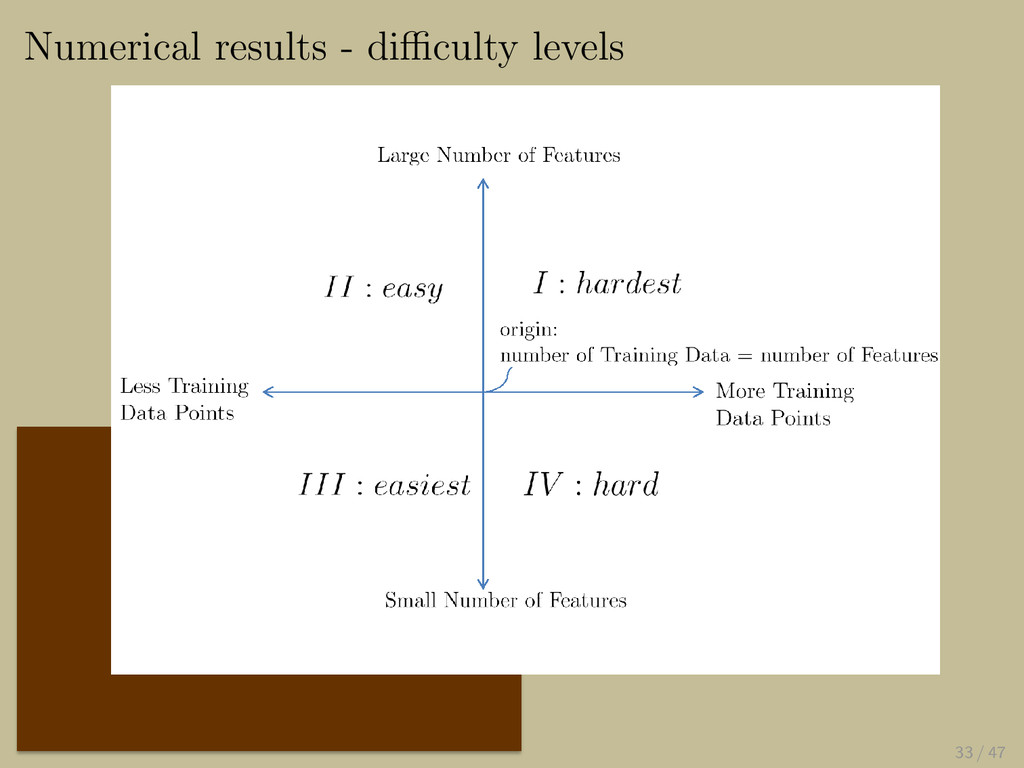{kind=link}
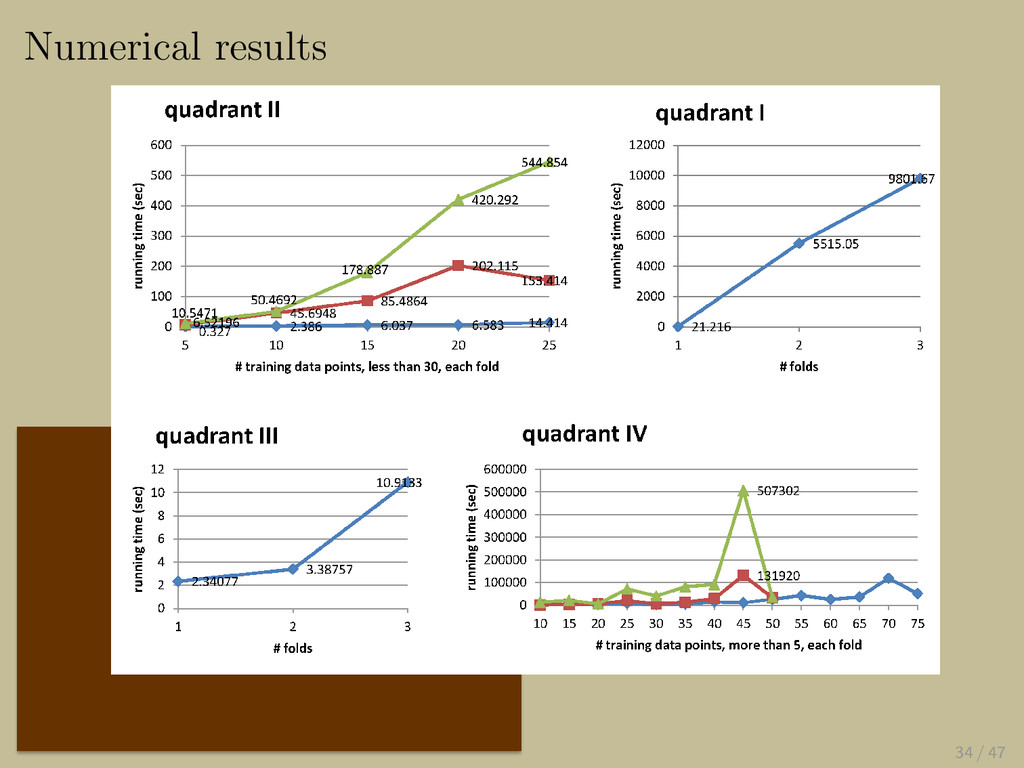{kind=link}
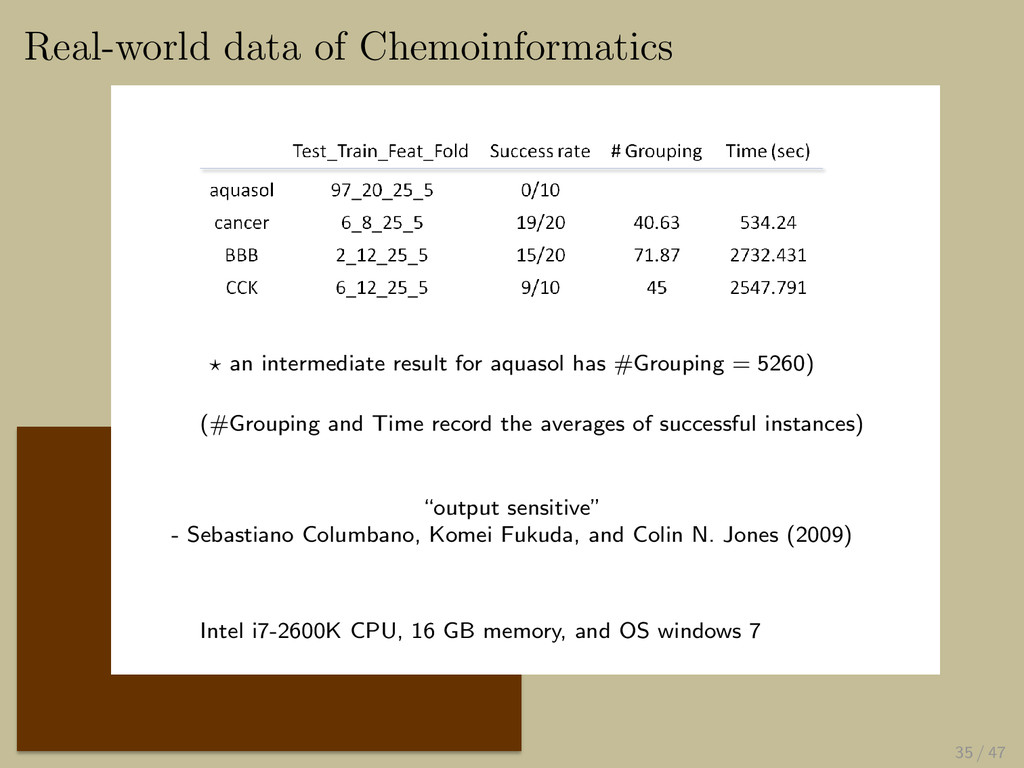{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}