shared ownership, understanding, and responsibility shipping is just the beginning product development requires continuously asking questions and iterating
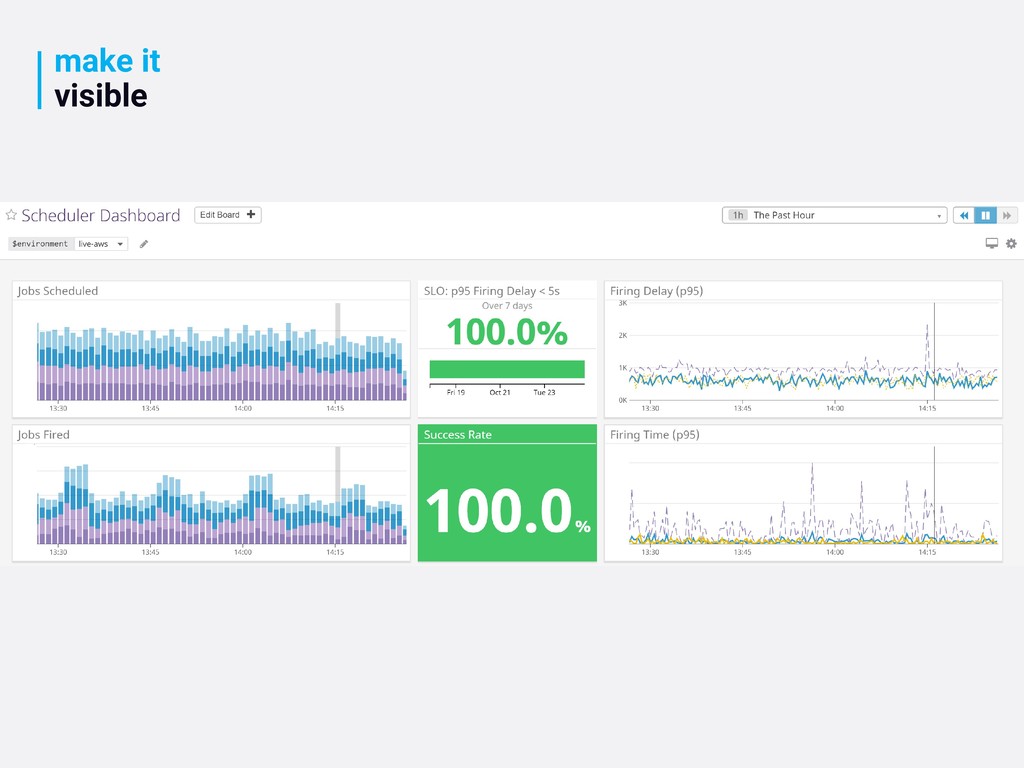
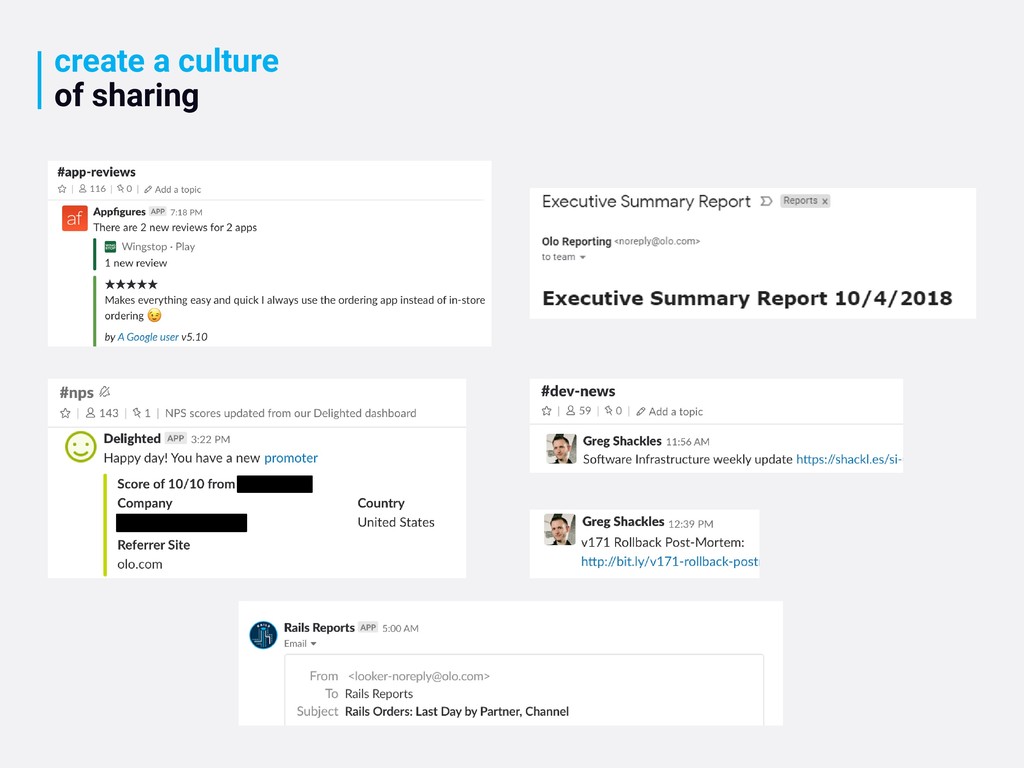
measure if you’re not measuring, you’re effectively flying blind level up your skills and your value this mindset will make you a better engineer and more valuable to your company observability is about asking questions it’s a cultural trait that drives how you build systems and products break down silos, share knowledge build a shared understanding and insight into your systems
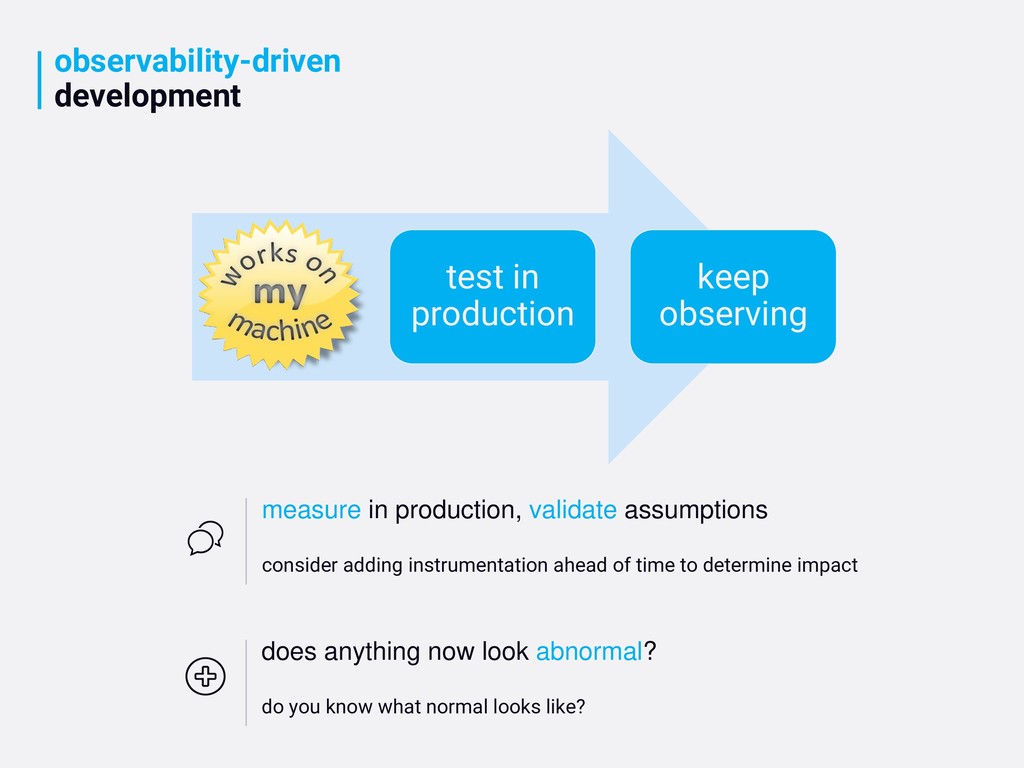
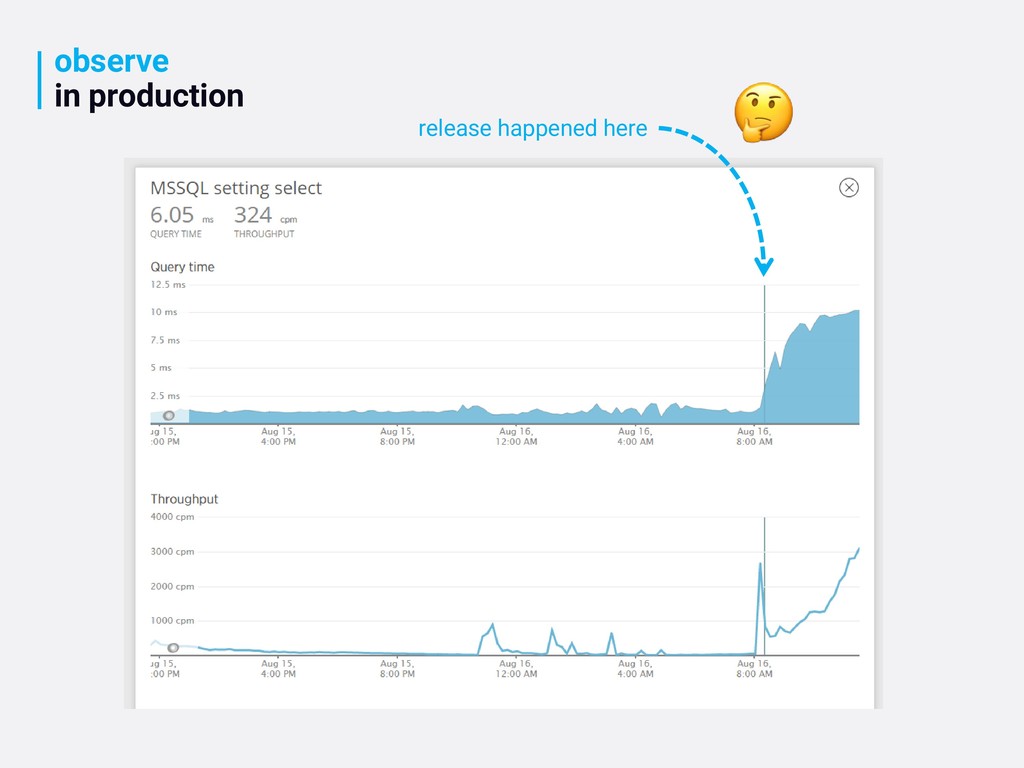
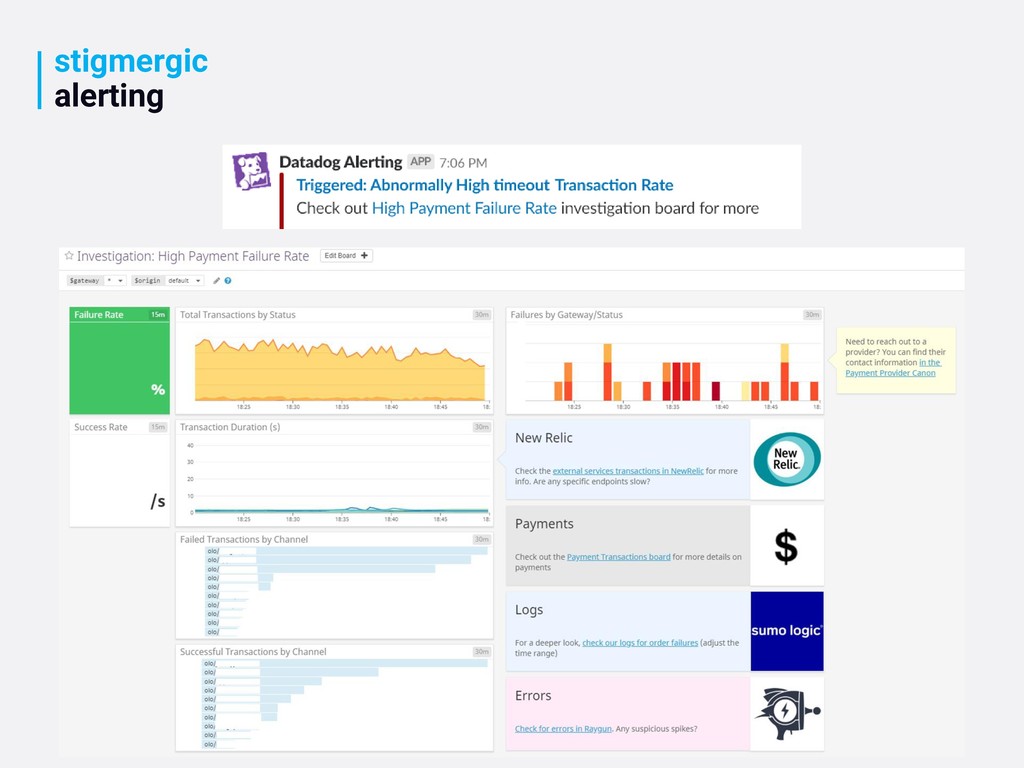
validate assumptions consider adding instrumentation ahead of time to determine impact does anything now look abnormal? do you know what normal looks like?
quantitative measure of some aspect of a service Service Level Objective (SLO) target value or range for a service, measured by an SLI Service Level Agreement (SLA) contract with your users that includes consequences of meeting or missing the SLOs landing.google.com/sre/book/chapters/service-level-objectives.html request latency, error rate, availability 99th percentile for request latency of 100ms or less public service: 10% discount for every hour below SLO, internal service: team gets paged
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![questions? Greg Shackles Principal Engineer, Olo @gshackles [email protected]](https://files.speakerdeck.com/presentations/c5de995453f6458b9aaa443f7b105275/slide_33.jpg){kind=link}