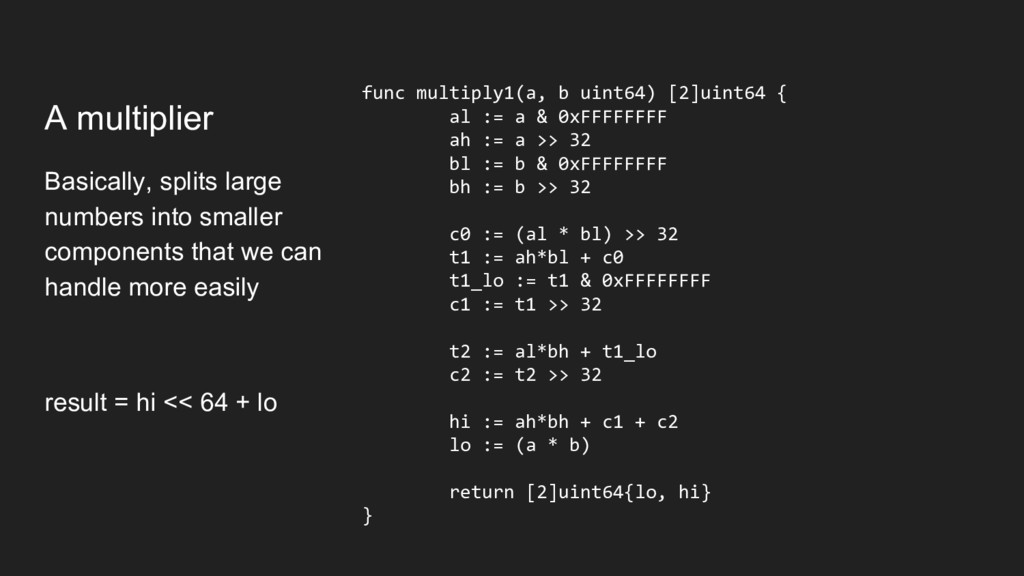
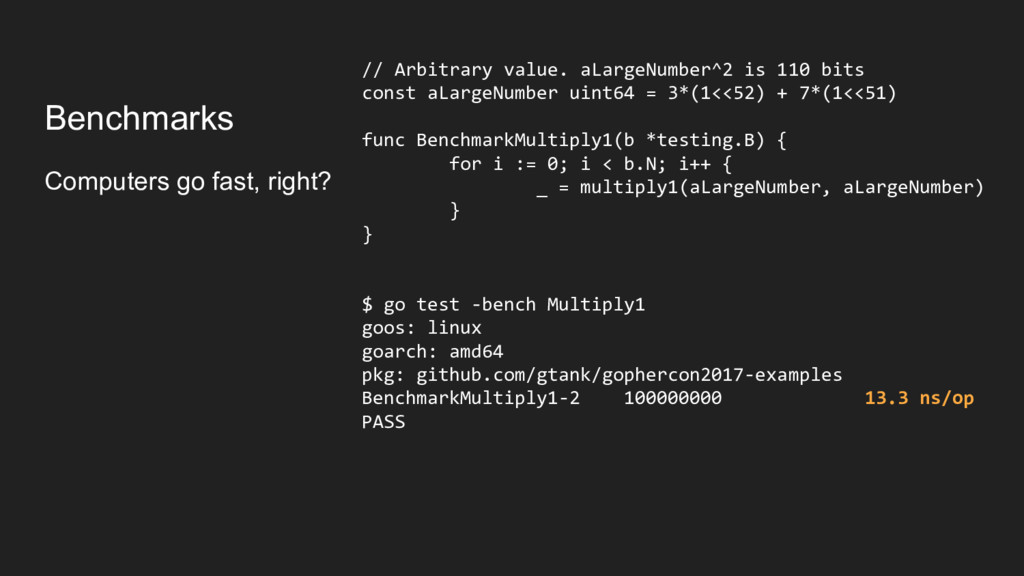
big numbers together” • 64 bits x 64 bits will produce 128-bit output • We don't have 128-bit registers on 64-bit machines • Results have to be stored in multiple registers (ignoring vector insns) • Processors provide "widening multiply" instructions that do this • Some languages provide uint128 and handle this for you • Go does not ◦ https://github.com/golang/go/issues/9455
we love Plan9? // +build amd64 // func mulq(x, y uint64) (lo uint64, hi uint64) TEXT ·mulq(SB),4,$0 MOVQ x+0(FP), AX MOVQ y+8(FP), CX MULQ CX MOVQ AX, ret+16(FP) // result low bits MOVQ DX, ret+24(FP) // result high bits RET
completely dominates the runtime of small arithmetic functions like this multiplier. pprof again! this mode is called “weblist” https://github.com/google/pprof
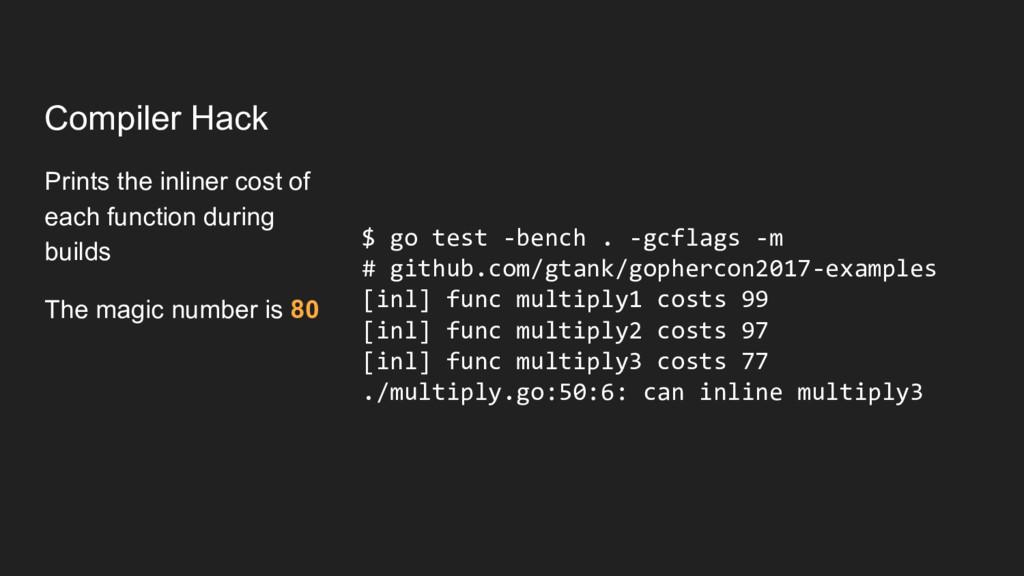
code of small/simple functions directly into the caller. This is called inlining. The Go inliner lives here: https://github.com/golang/go/blob/master/src/cmd/compile/internal/gc/inl.go It walks the instruction tree of each function calculating a “cost” that roughly reflects the complexity of the function. If the cost exceeds the hard-coded max budget, the function will not be inlined.
instruction tree Some instructions are more equal than others: • Slice ops are +2 • 3-arg slice ops are +3 • Direct function calls (OCALLFUNC/OCALLMETH) only OK if target is inlinable and we have budget for it Some things are hard stops: • Most other types of calls. Interface calls, type conversions • Panic/recover • Certain runtime funcs and all non-intrinsic assembly [#17373]
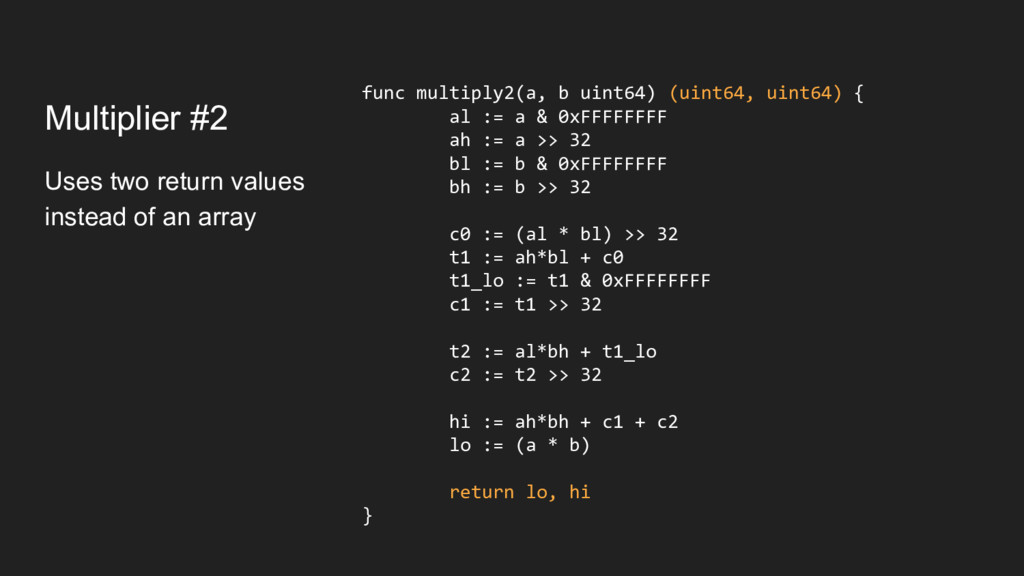
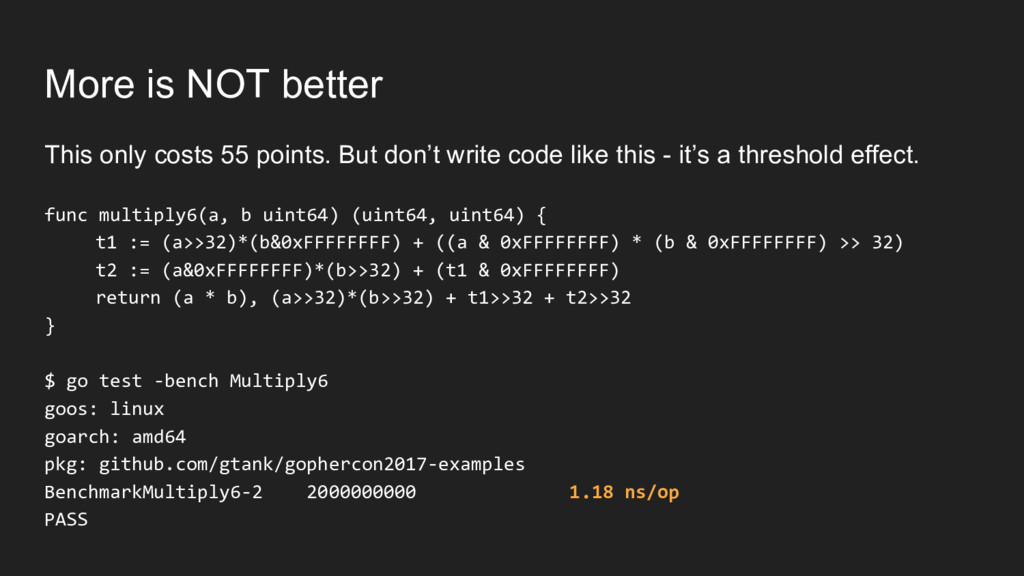
shift + assign if you only use them once But how do we know? func multiply3(a, b uint64) (uint64, uint64) { al := a & 0xFFFFFFFF ah := a >> 32 bl := b & 0xFFFFFFFF bh := b >> 32 t1 := ah*bl + ((al * bl) >> 32) t2 := al*bh + (t1 & 0xFFFFFFFF) hi := ah*bh + t1>>32 + t2>>32 lo := (a * b) return lo, hi }
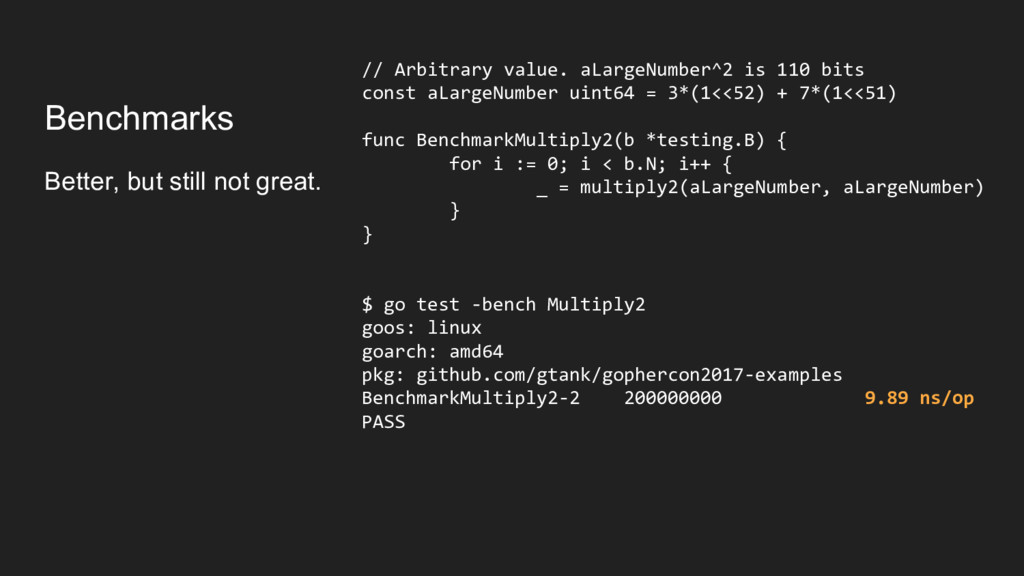
linux goarch: amd64 pkg: github.com/gtank/gophercon2017-examples BenchmarkMultiply3-2 2000000000 1.18 ns/op PASS That’s ⅕ of the time the assembly function took.
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}