Redis只做cache提⾼查询速度。 b. 调研使⽤⼀个⽀持多数据中⼼复制的Cache系统, 如Acrospike, 携程开源的x-pipe c. 程序⾃⼰处理多数据中⼼的Redis的同步。 • 写多份、删多份 • ⽤⼀个proxy来处理多个数据中⼼的Redis读写操作,⽐如改造 Codis d. 根据⽤户的地理位置,对⽤户进⾏分区。对某个⽤户 的连接、推送、上⾏都转到其归属idc处理。
rolled back的原因: 在db.BeginTx时,会启⼀个协程awaitDone: func (tx *Tx) awaitDone() { // Wait for either the transaction to be committed or rolled // back, or for the associated context to be closed. <-tx.ctx.Done() // Discard and close the connection used to ensure the // transaction is closed and the resources are released. This // rollback does nothing if the transaction has already been // committed or rolled back. tx.rollback(true) } 在context被cancel时,会进⾏rollback(),⽽rollback时,会操作原⼦变量。 之后,在另⼀个协程中tx.Commit()时,会判断原⼦变量,如果变了,会抛出此错误。 • 解决⽅法 这2个error都是由连接断开导致的,是正常的。将这2个错误转成user error。
the context in Tx is canceled and rolls back // the transaction if it's not already done. func (tx *Tx) awaitDone() { // Wait for either the transaction to be committed or rolled // back, or for the associated context to be closed. <-tx.ctx.Done() // Discard and close the connection used to ensure the // transaction is closed and the resources are released. This // rollback does nothing if the transaction has already been // committed or rolled back. tx.rollback(true) } 在rollback(true)中,会先判断原⼦变量tx.done是否为1,如果1, 则返回;如果是0,则加1,并进⾏rollback操作。 在提交事务Commit()时,会先操作原⼦变量 tx.done,然后判断context是否被cancel了,如 果被cancel,则返回;如果没有,则进⾏commit 操作。 // Commit commits the transaction. func (tx *Tx) Commit() error { if !atomic.CompareAndSwapInt32(&tx.do ne, 0, 1) { return ErrTxDone } select { default: case <-tx.ctx.Done(): return tx.ctx.Err() } var err error withLock(tx.dc, func() { err = tx.txi.Commit() }) if err != driver.ErrBadConn { tx.closePrepared() } tx.close(err) return err } 如果先进⾏commit()过程中,先操作原⼦变量,然 后context cancel,之后 另⼀个协程在进⾏ rollback()会因为原⼦变量置为1⽽返回。导致 commit()没有执⾏,rollback()也没有执⾏。
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
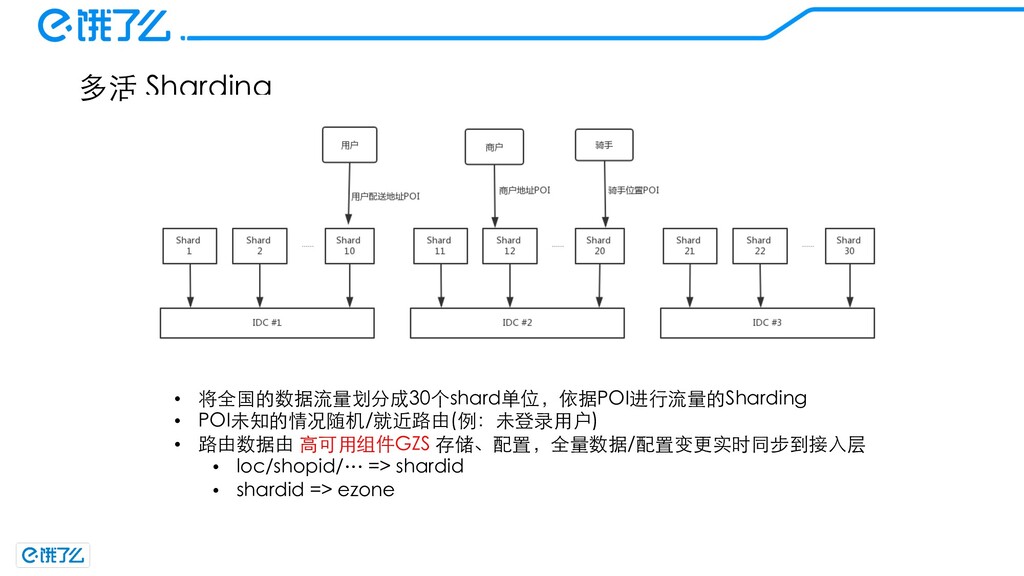{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}