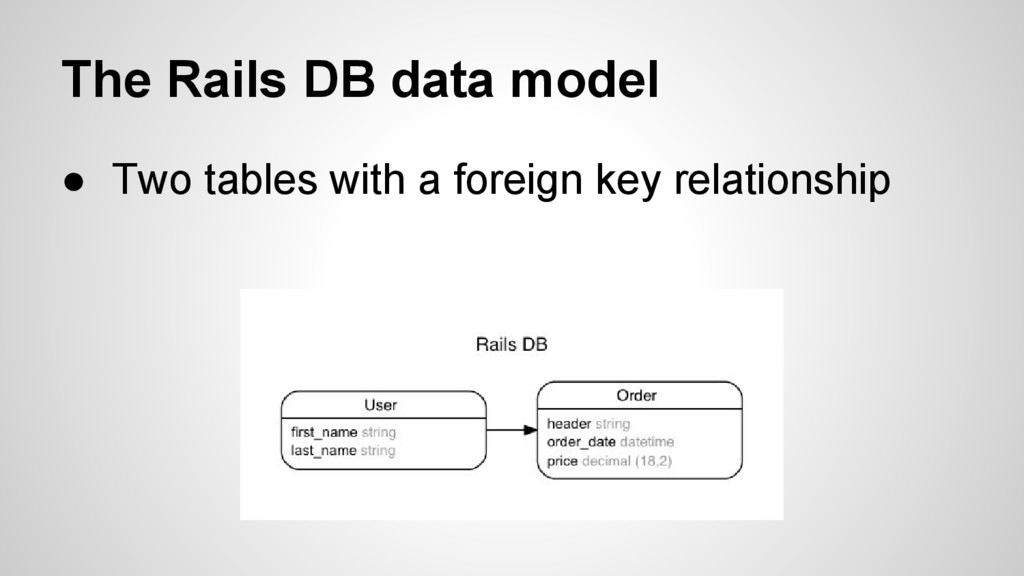
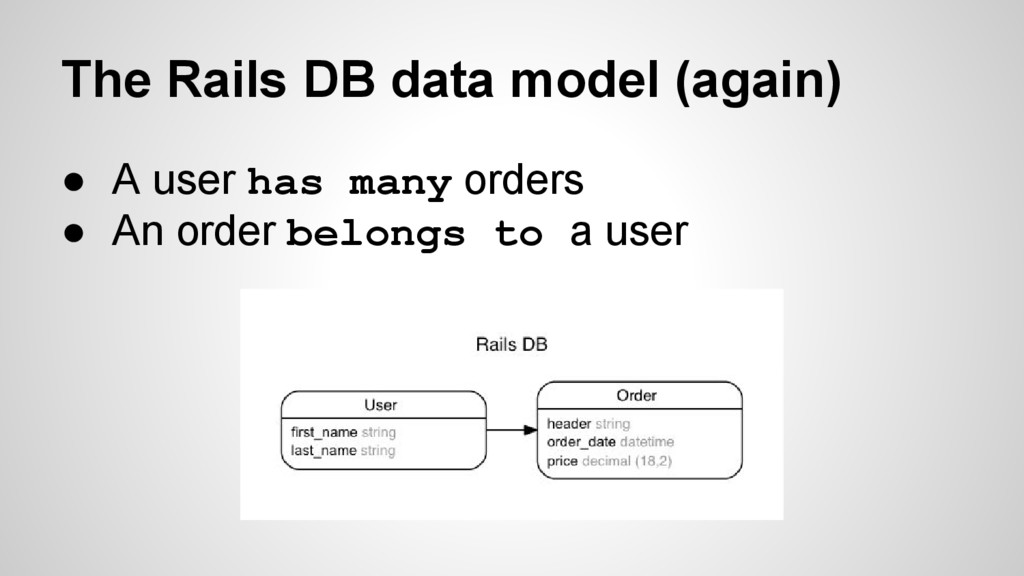
objects in memory • Need to persist them in an effective way ◦ Effective to write and read(find) • This is where ORM’s enter the picture ◦ ActiveRecords (Rails/Ruby) ◦ SQLAlchemy (Python) ◦ Hibernate/NHibernate (Java and .Net)
of developers • Supposed to fix the “Impedance mismatch” between an Object model and a Relational Database • Usually simple to use for the common case • Can be really horrible to deal with more complex situations
with a Relational Database • One flavor per vendor with a growing common subset • Set language that is sometimes hard to grasp if you are used to procedural thinking • Well supported for development and end- user interaction
size blocks on disk (2k, 4k, 8k, 16k) • Some databases have one file per table/index other have the objects organized into table spaces and one or more file per table space
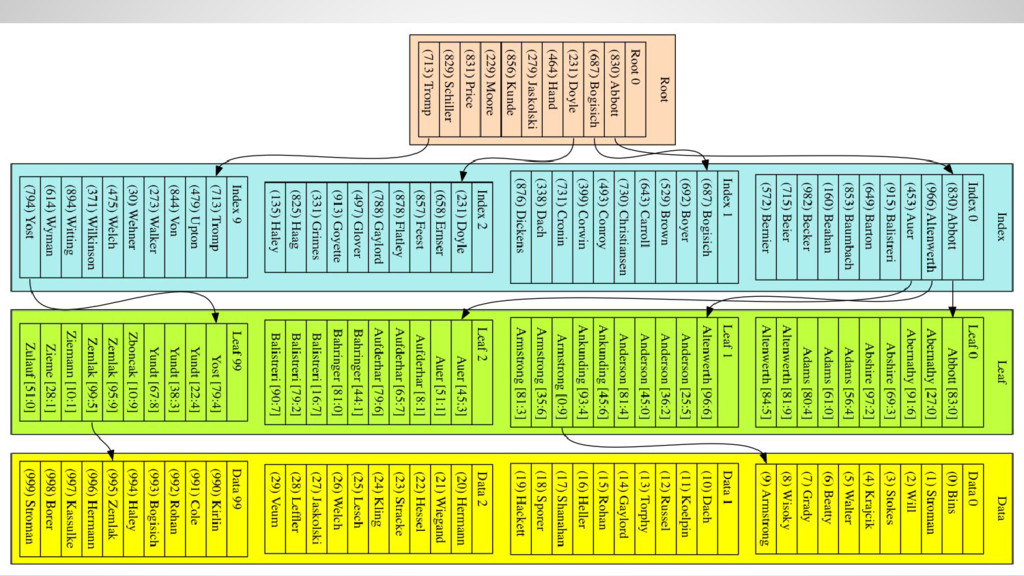
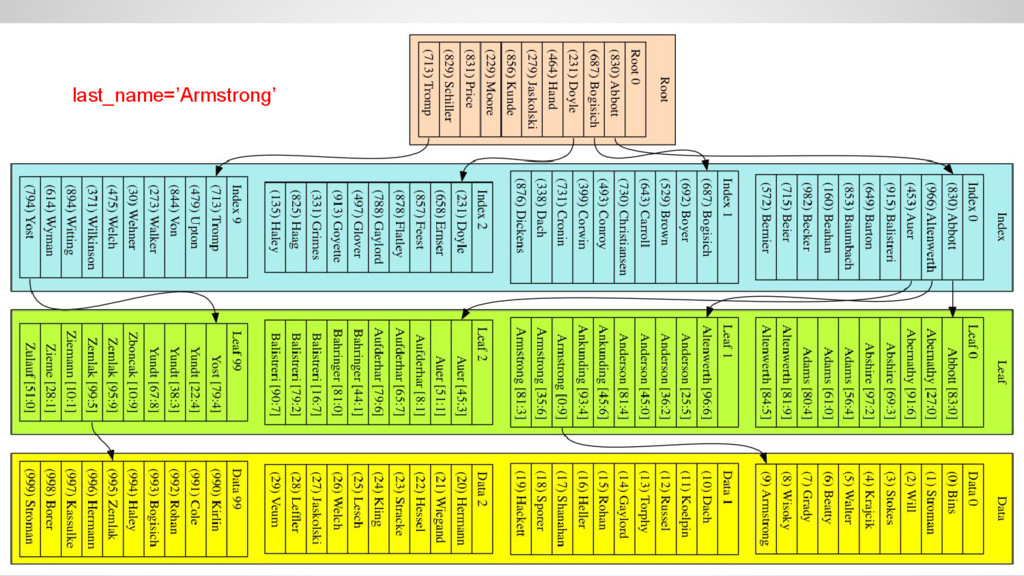
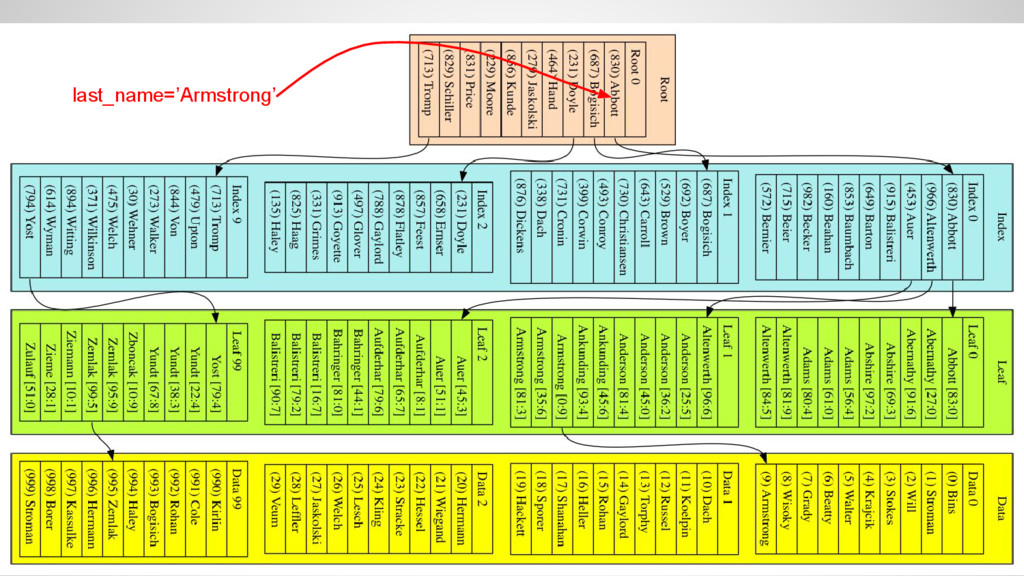
the data, as there is no guaranteed order by last_name • Access time grows as O(n) where n is the number of rows in the table • Fine for small tables, but very bad for big tables and selective queries
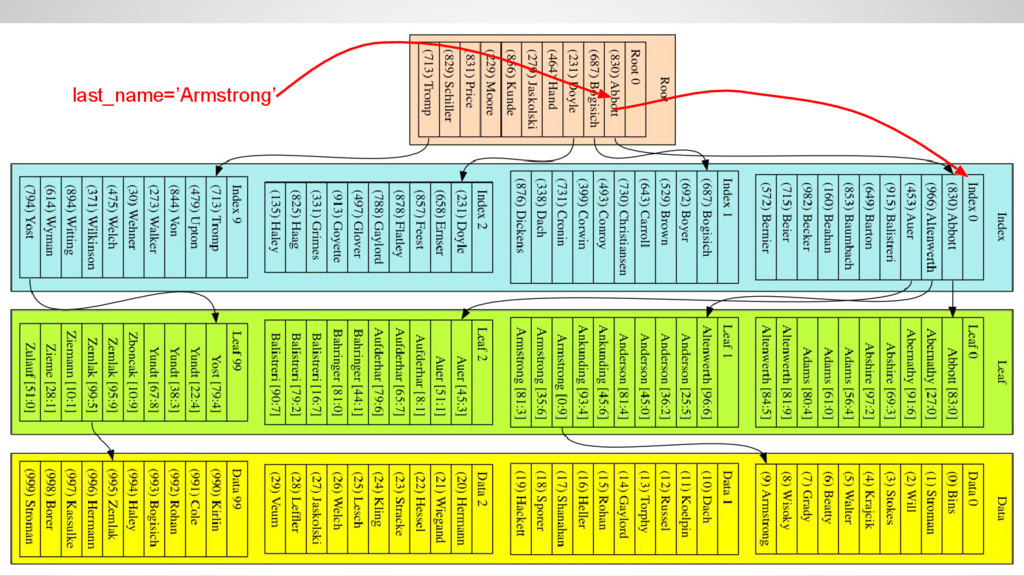
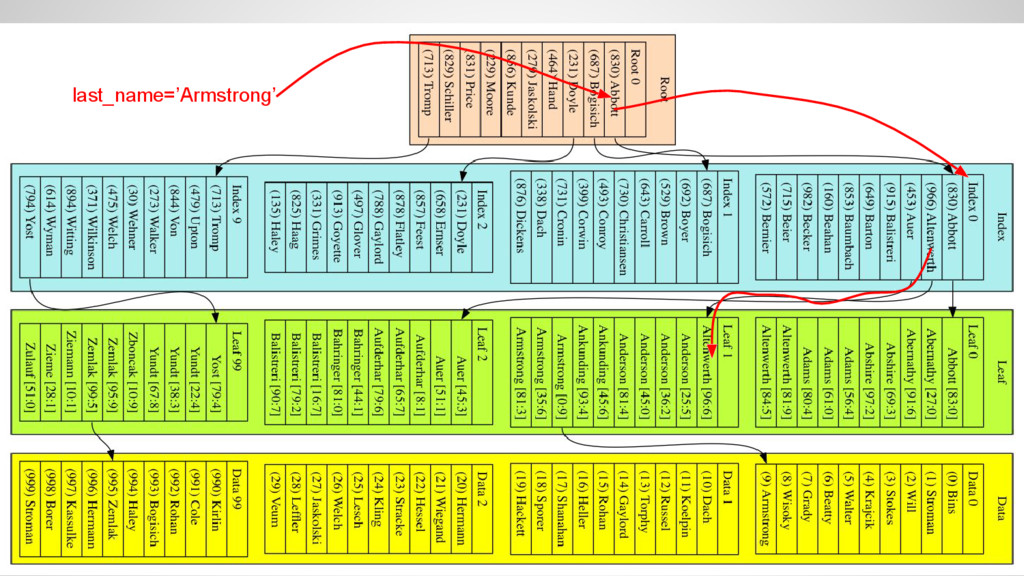
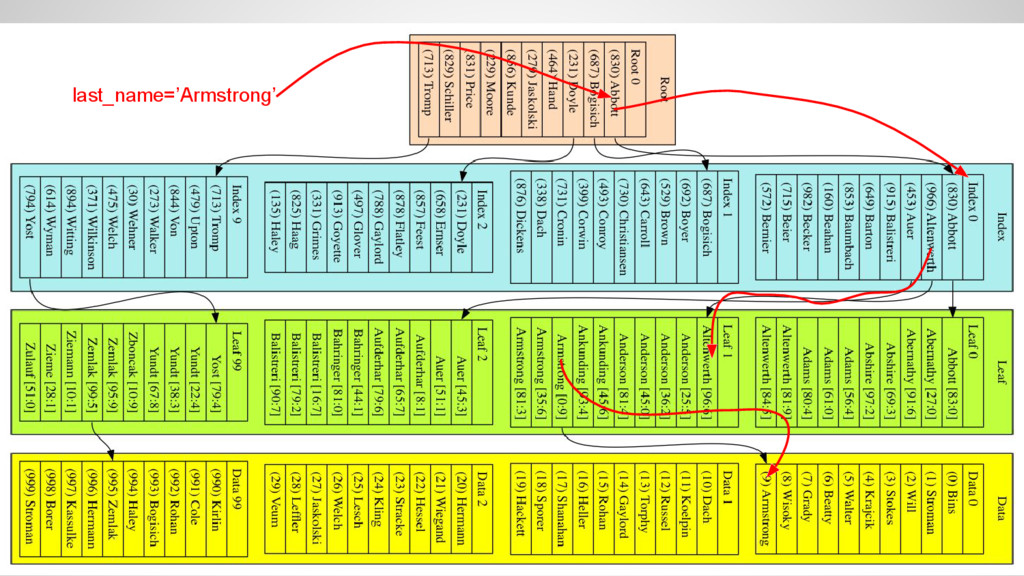
the index • The index is ordered by last_name • Navigate through the index down to a leaf block and finally read the data • Access time grows as O(log(n)) where n is the number of rows in the table • I.e. access time triples when data grows by three orders of magnitude!
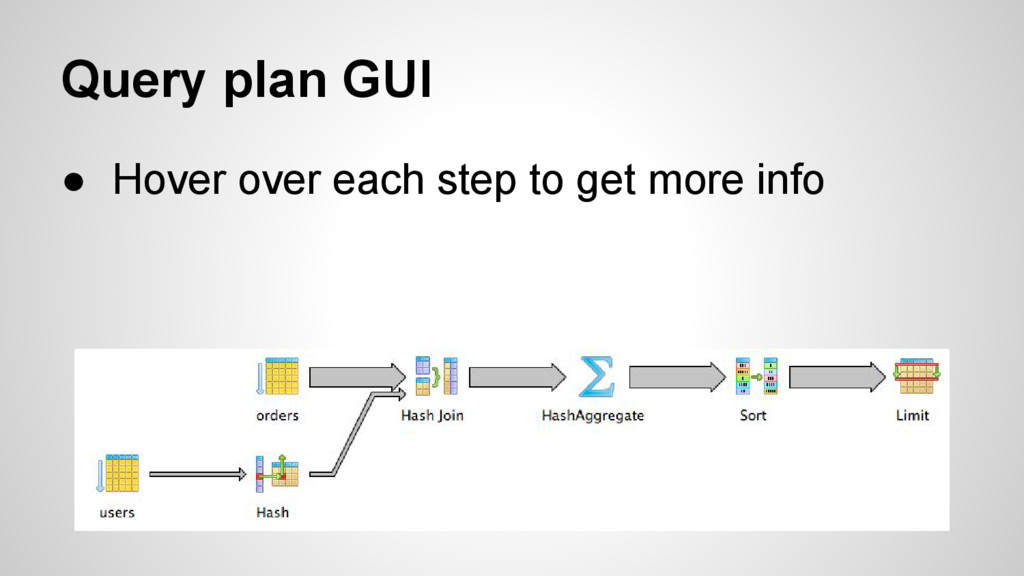
SELECT users.id,sum(price) as the_sum FROM "orders" INNER JOIN "users" ON "users"."id" = "orders"."user_id" WHERE (last_name='Haley') GROUP BY users.id
0.221640 user 0.021172 system CREATE INDEX index_users_on_last_name ON users(last_name); 0.243382 elapsed 0.221215 user 0.021065 system CREATE INDEX index_orders_on_user_id ON orders(user_id); 0.004092 elapsed 0.004052 user 0.000024 system 60-fold speedup!
statements • Deleting a row needs to also delete from each index on the the table • Inserting will have to also insert into each index (possibly causing a block split) • Update is the combination of Delete/Insert on the indices of the updated columns
for small tables • Index lookup - one row at a time ◦ Traverse the index from the root down to the leaf ◦ Equi-join • Index range-scan ◦ Find the first row with the index ◦ Scan the index for subsequent rows ◦ BETWEEN, greater-than, less-than Access paths
Preferably a meaningless integer called id • Should not depend on business rules or even be visible to end-users • Never create a composite primary key!
up with a good plan ◦ Is there an index on the join column or do we have to do a full scan ◦ In case of multiple indices, pick the best one to use • It also needs data statistics, row count and block count to adapt to changing data volume
tables (get rid of obsolete row versions) • Can be auto-configured with: ◦ autovacuum=on in postgresql.conf • Can also be done interactively with the ANALYZE or VACUUM ANALYZE commands
variable • If set (which is default), the statistics will be updated on: ◦ SHOW TABLE STATUS and SHOW INDEX ◦ Access to the INFORMATION_SCHEMA • Can also run ANALYZE TABLE command
chunk of standard SQL • Very lightweight and small footprint • No separate server process • Available on most all platforms, including cell phones and files are portable • Trivial to use with Rails
on standards • Not very active development since Oracle bought Sun that bought MySQL • Decent support for high-reliability and scaling • Excellent community support
for standard SQL (CTE and window functions supported) • Active development society • Some support for high-availability and scaling • Great community support
NT) • Maintained for Windows since then by MS • Runs only on MS Windows (Linux coming!) • Very standards compliant • Rather scalable, partitioning, parallel query • Somewhat HA (failover clustering) • Not free
Highly scalable, partitioning, parallel everything, real clustering • Multi-platform (written in C since version 3) • Highly available • Not inexpensive
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}