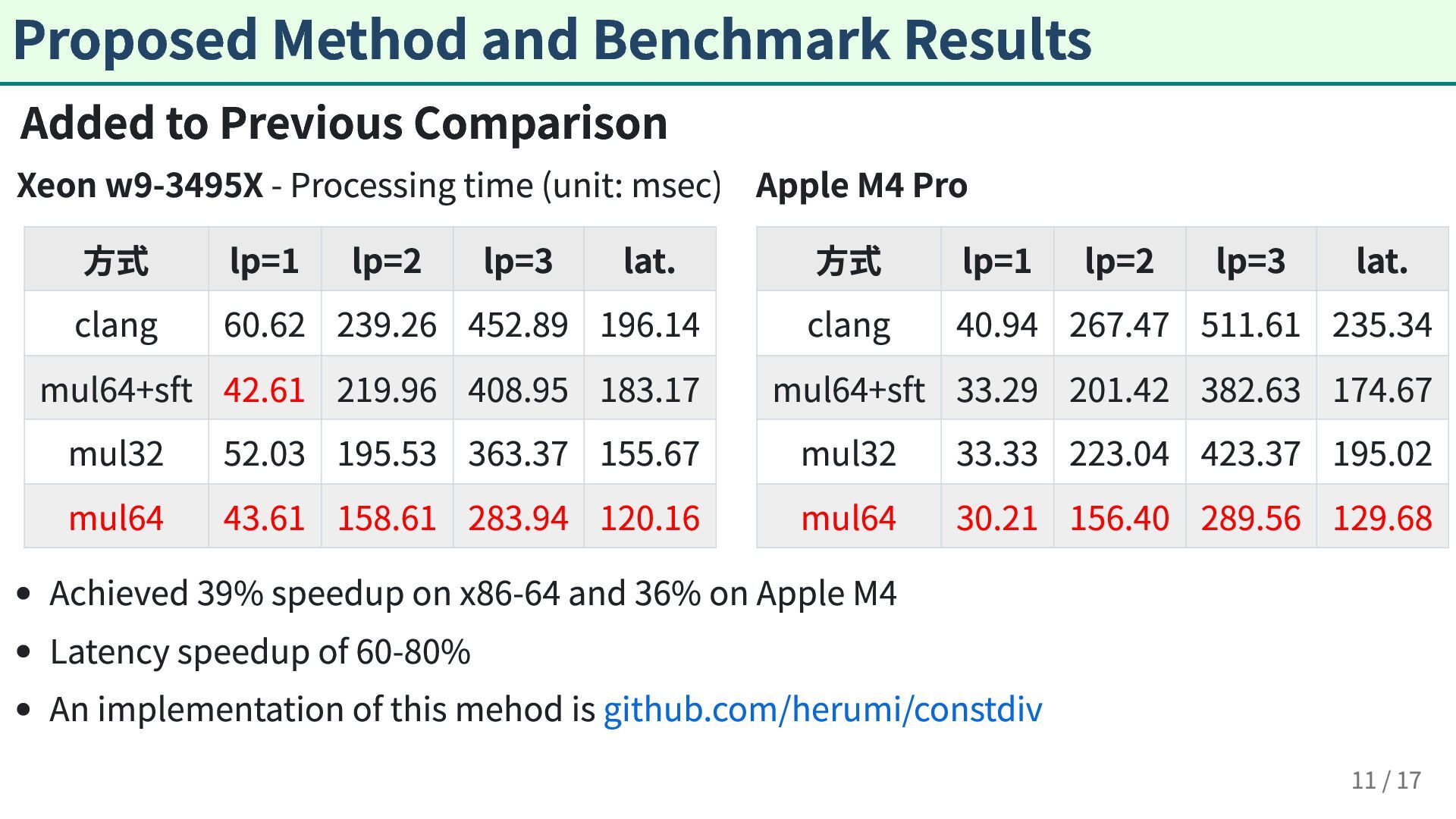
code such as uint32_t divd(uint32_t x) { return x / 7; } , we propose a new method that is 36-39% faster than code generated by GCC, Clang, and MSVC for x86-64 and Apple M4, which method we call the GM (Granlund-Montgomery) method. Uses only one 64-bit integer multiplication instruction Avoids 128-bit integer shifts Smaller Multipliers for Constant Modulus Choose for used in MLKEM, etc., we propose a method using smaller multipliers than existing Barrett Reduction for modulus operations Requires additional select instruction 2 / 17
: dividend Quotient: , Remainder: When , : largest integer not exceeding whose remainder when divided by is : function that returns x if condition cond is true, otherwise y u32 , u64 , etc.: unsigned 32/64-bit integers Case Classification for When is a power of 2, , then and When , then Otherwise → The main topic of this presentation 3 / 17
, if then for any , holds A different but equivalent formulation to the original GM for Theorem 2 below Case of There exists such that When Both and are u32 variables and multiplication result fits in u64 , so is sufficient When GM method proposes a way to keep intermediate variable values within 32 bits (next slide) 4 / 17
fit in u64 Decompose into 3 stages of shifts: Let (where ), then Calculate using 32-bit×32-bit→64-bit (mul32) Let , then Computing does not fit in u32 Using , c L 1 1-bit x 32-bit x c L x x 2 32 + (x c L ) × + c 6 / 17
Variables into 32 Bits 1. Use 64-bit×64-bit MUL (mul64) and u128 shift (mul64+sft) Directly compute x64 can obtain 128 bits with a single imul instruction M4 (AArch64) obtains upper/lower 64 bits with two instructions umulh / mul u32 udivd1(u32 x) { return (x * u128(c)) >> a; } 2. Calculate using the mul32, then compute with u64 u32 udivd2(u32 x) { u64 cL = c & 0xffffffff; u64 y = (x * cL) >> 32; return (x + y) >> (a - 32); // Simpler since there's no 32-bit overflow handling } 7 / 17
due to small target size Process multiple times and evaluate differences lp=1, 2, 3 represent the number of times processed within a processing unit (see proceedings for details) The difference lat. when lp increases roughly corresponds to the latency of proc. time u32 loop(FuncType f) { u32 sum = 0; // This loop is not unrolled for (u32 x = 0; x < N; x++) { u32 t = x; // Embed code for f(t) = t//d lp times for (int i = 0; i < lp; i++) { sum += f(t); t += sum; } ... } return sum; } 8 / 17
to avoid 128-bit shifts Proposed Method Remove shift by increasing multiplier ・ ・ ・ Since a 128-bit integer is represented by two 64-bit integers, the cost of extracting the upper 64-bit integer is 0 Becomes one multiplication instruction in assembly language on x64/M4 excluding value setting 10 / 17 div7_optimized: mov edx, edi mov rax, 0x24924924a0000000 mulx rax, rax, rax ret
than , and if is greater than or equal to , subtract u32 barrett(u32 x) { u32 q = (x * c) >> a; u32 r = x - q * d; while (r >= d) r -= d; // Loop may execute at most 2 times depending on constant selection return r; } In the MLKEM768 implementation mlkem-native, for and s16 ref3329(s16 x) { const int d = 3329; int t = (x * 20159 + (1<<25)) >> 26; return x - t * d; } 12 / 17
if " and " then for all , holds. Condition "" is relaxed from " " in Theorem 1, making smaller and division error at most 1 Find at most 1 larger than , and if is negative, add Implementation For u32 , always fits in 32 bits (see below) u32 uremd_mywork(u32 x) { u32 q = (x * c) >> a; u32 r = x - q * d; if (r < 0) r += d; return r; } 13 / 17
and Montgomery Reduction const int q = 3329; s16 ref3329(s16 x) { // ((q-1)/2)^2 * c > 2^32 int t = (x * 20159 + (1<<25)) >> 26; return x - t * q; } int mont(int x, int y) { int t = x * y; int m = ((t & 0xffff) * 3327) & 0xffff; t = (t + m * q) >> 16; if (t >= q) t -= q; return t; } Proposed Method (Th. 2) Applying Th. 2 to gives , Using (x * (5<<2))>>16 enables SIMD (PMULHW) that returns upper u16 × u16 MUL Since , multiplication cost may be reduced in embedded systems s16 my3329(s16 x) { // Perfectly matches output of ref3329() int t = (x * 5) >> 14; // (x*20)>>16 also works t = x - t * q; if (t > q/2) t -= q; return t; // To fit within [-(q//2), q//2] } 15 / 17
, let and , then Therefore, if , then or holds are non-negative constants; consider when varies (and varies accordingly) Maximum is given by or From , we get From , we get Therefore, if condition "" holds, then , and holds M 0 x M d d-1 r (M,r 0 ) ... (M d ,d-1 ) 16 / 17
/ u32 division using only one u64 MUL, compared to traditional GM method Achieved 39% speedup on x86-64 and 36% on Apple M4 compared to existing compilers GCC, Clang, MSVC Improvement of Constant Integer Modulus Operations Proposed a variant of Barrett Reduction Proposed a method with smaller multipliers compared to existing methods Easier to apply in SIMD environments since 64-bit multiplication can be avoided Possibility of reduced modulus operations for primes used in MLKEM 17 / 17
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}