Large Language Models (LLMs) have demonstrated impressive capabilities in tasks such as code generation, completion, and repair. A recent trend involves designing agentic systems, where multiple LLM-powered agents collaborate to accomplish software engineering goals. These multi-agent setups have achieved state-of-the-art performance in several tasks, but their practical adoption faces significant challenges. In this tutorial, we will begin by introducing the foundations of agentic systems and their applications in software engineering. We will then broaden the discussion to cover critical aspects of code intelligence using LLMs and agentic systems that must be addressed for real-world deployment, including code comprehension, effective communication, security concerns, explainability, reasoning capabilities, and computational efficiency. Through this lens, we will analyze the current limitations of LLMs and agent-LLMs, highlighting the gaps, and how to adapt the models to our requirements. We will conclude with several directions and considerations when using Agentic systems.
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
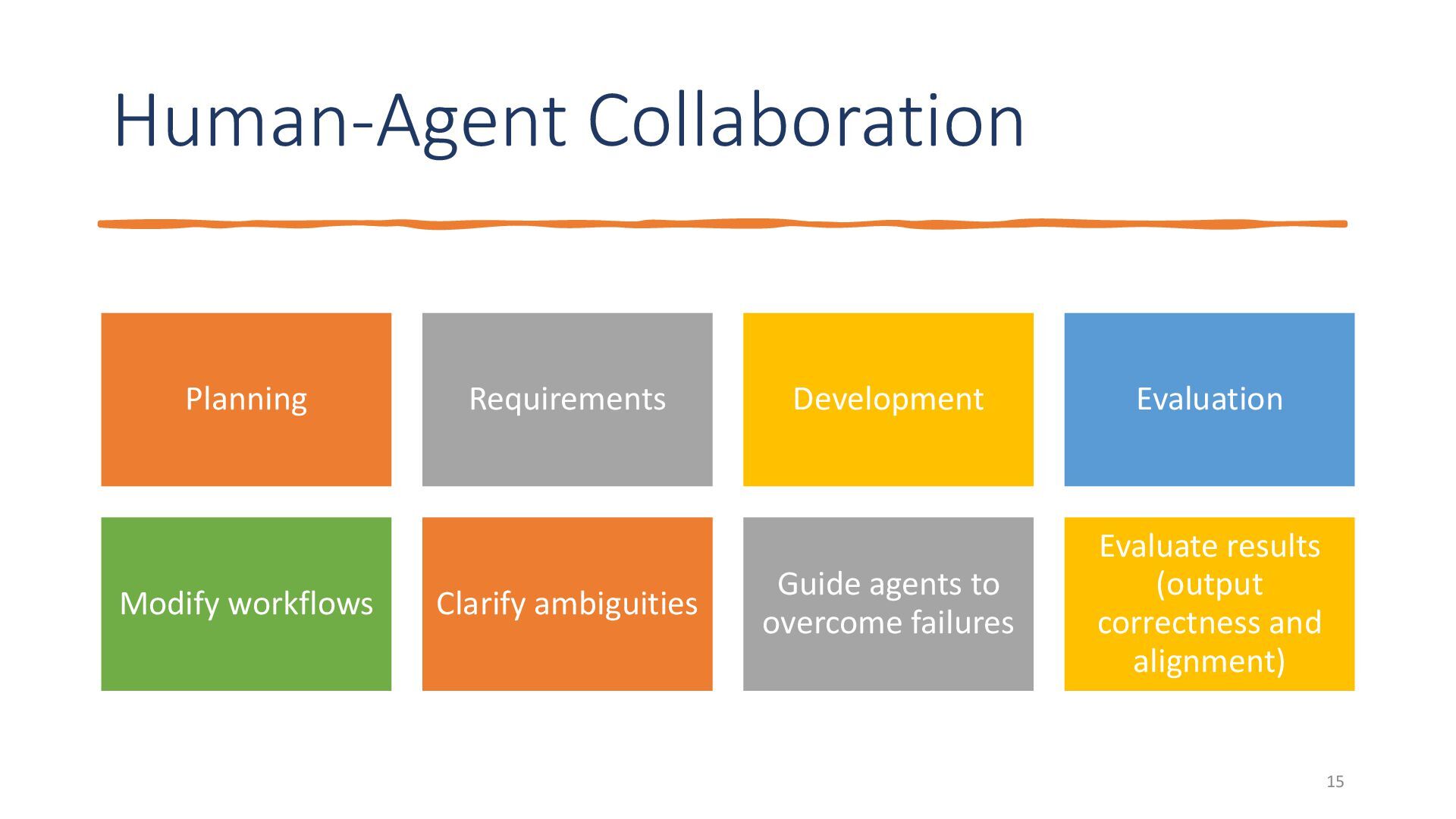{kind=link}
{kind=link}
{kind=link}
{kind=link}
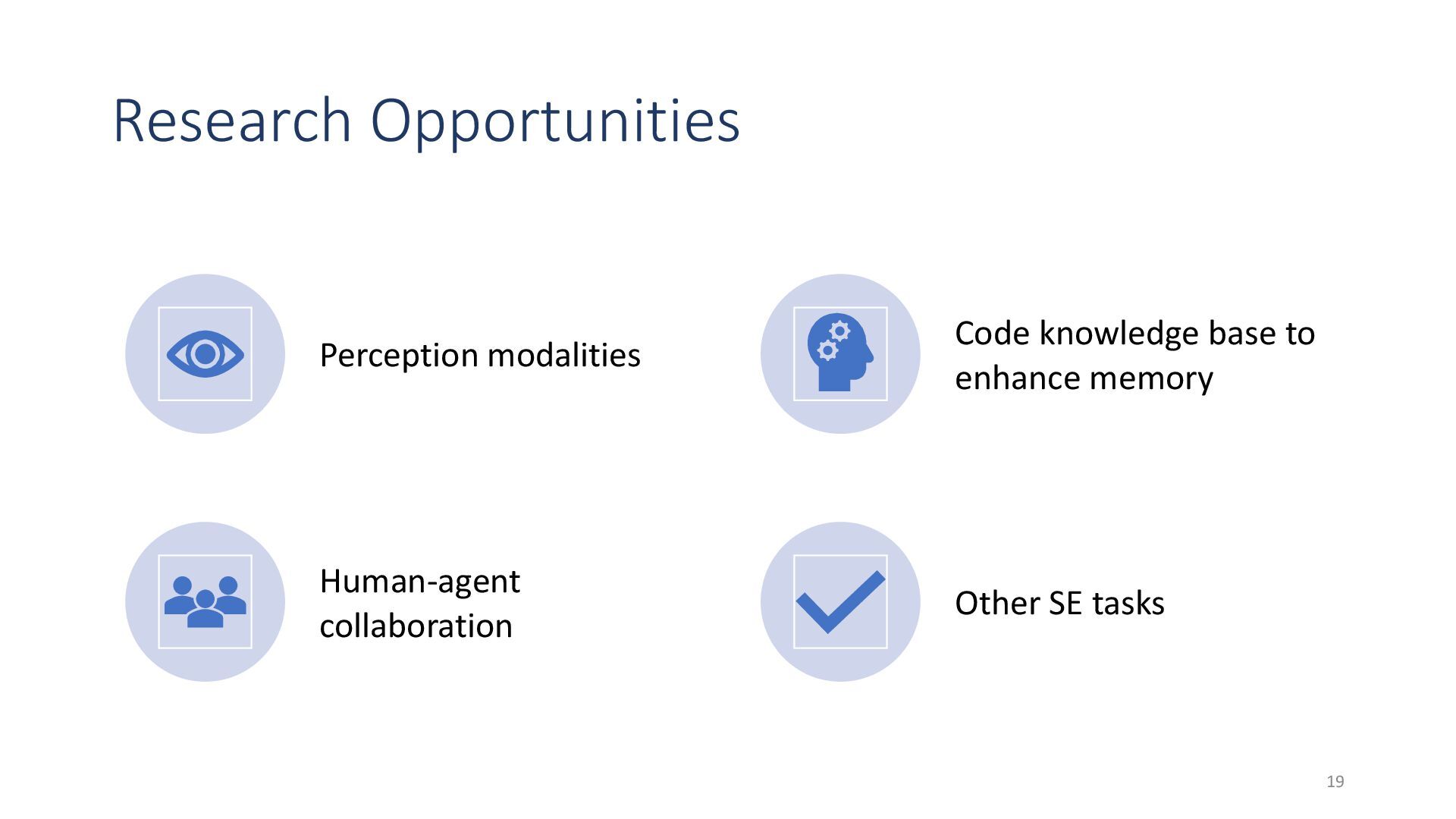{kind=link}
{kind=link}
{kind=link}
{kind=link}
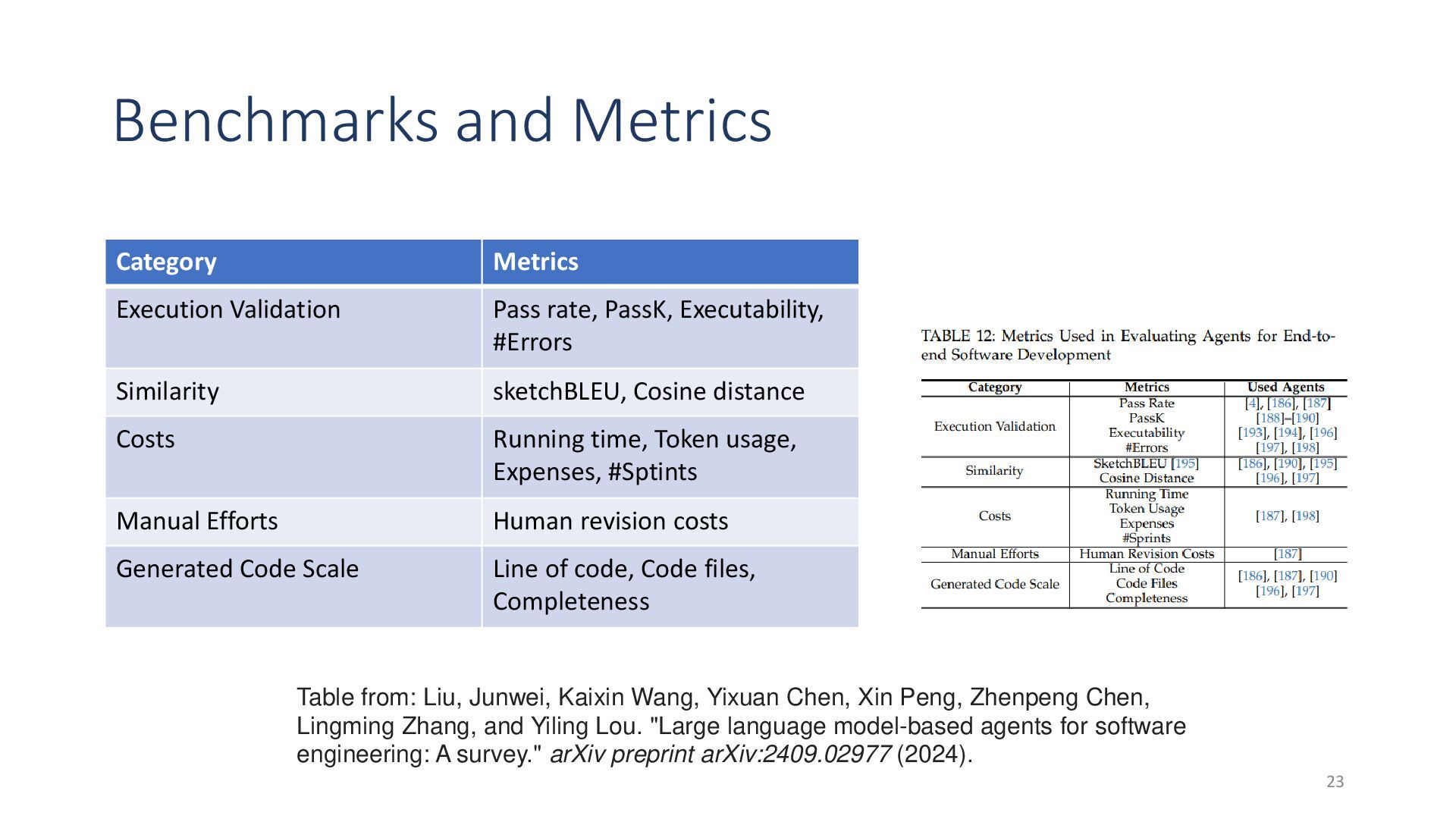{kind=link}
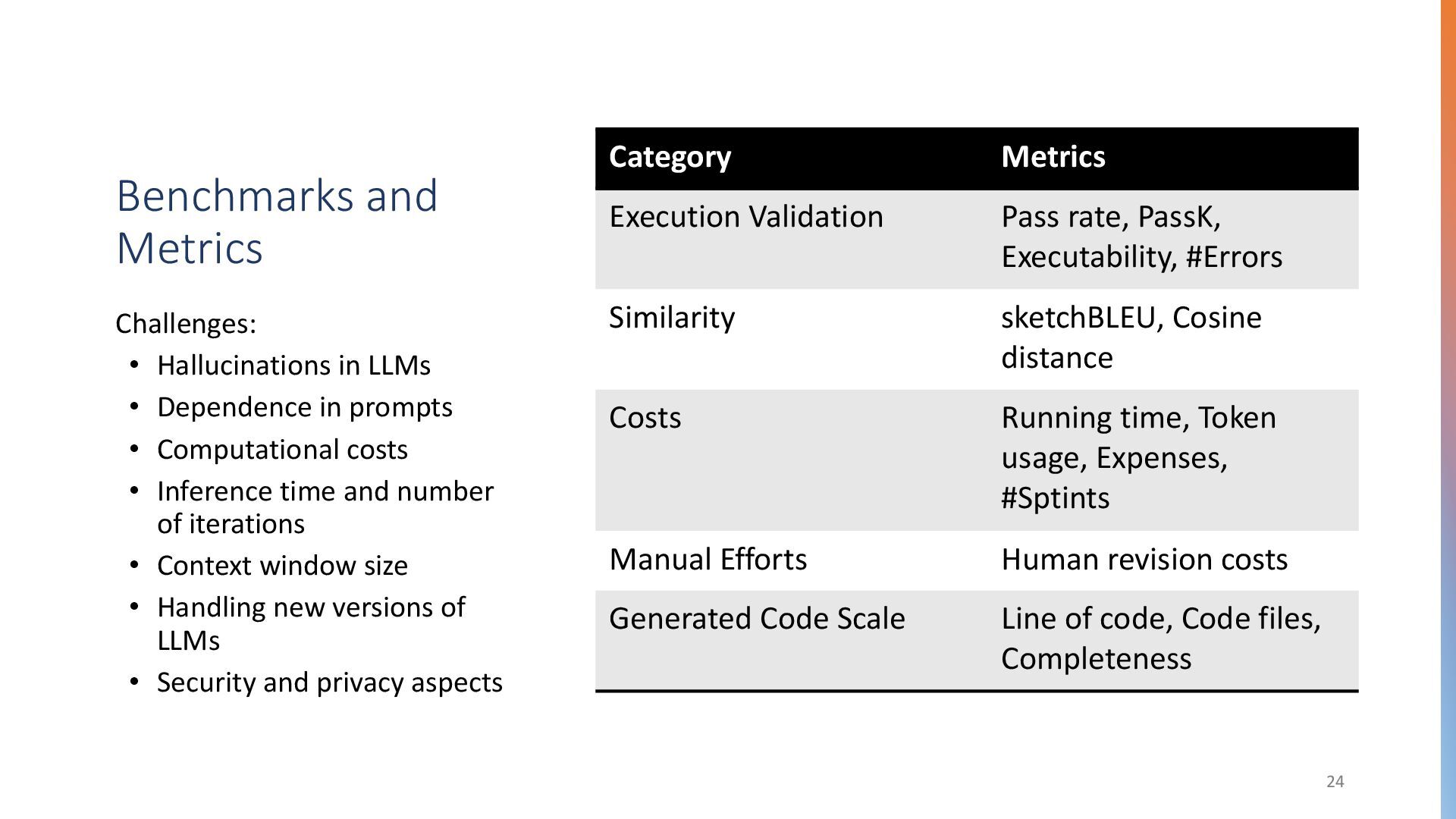{kind=link}
{kind=link}
{kind=link}
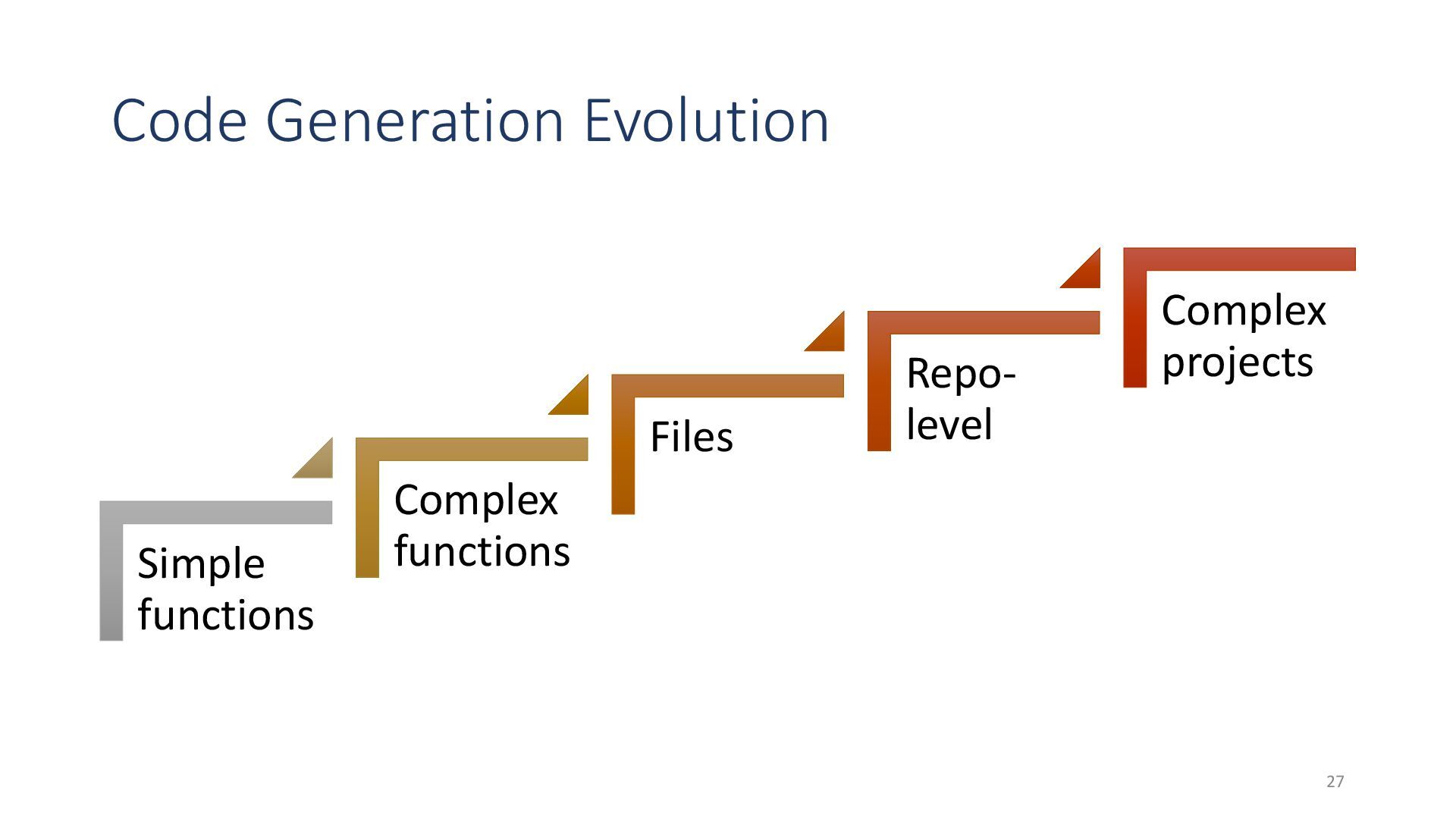{kind=link}
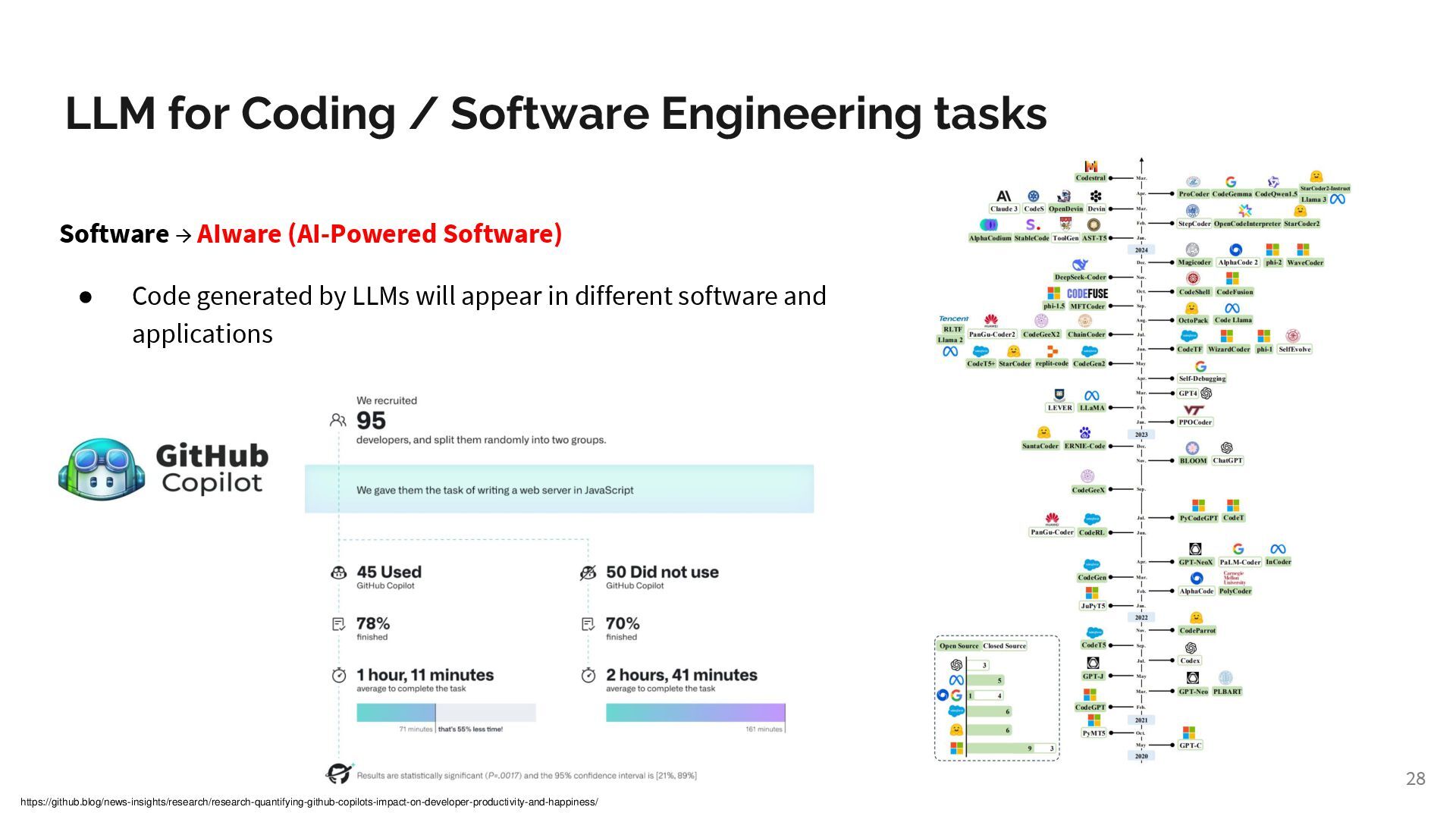{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
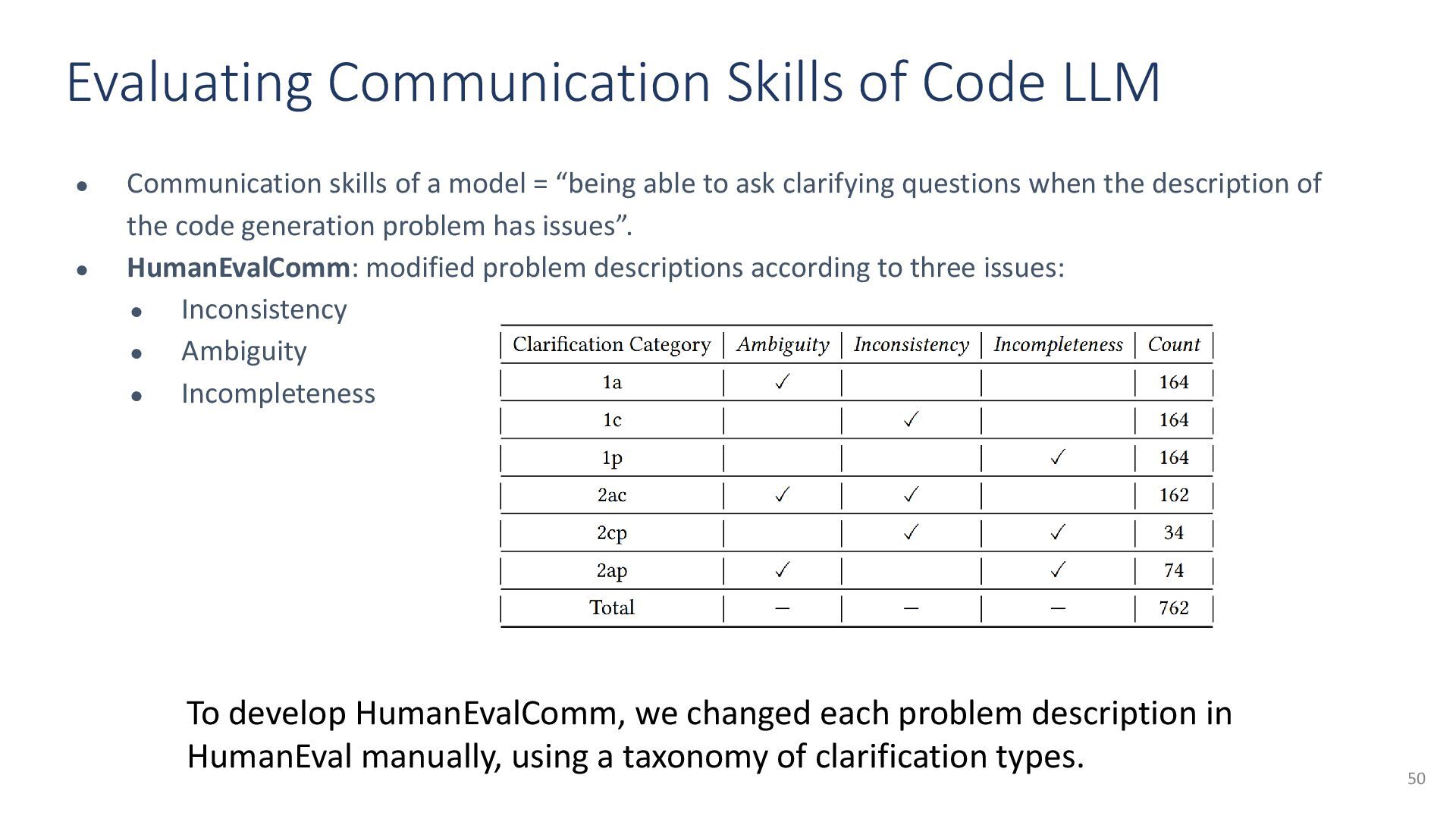{kind=link}
{kind=link}
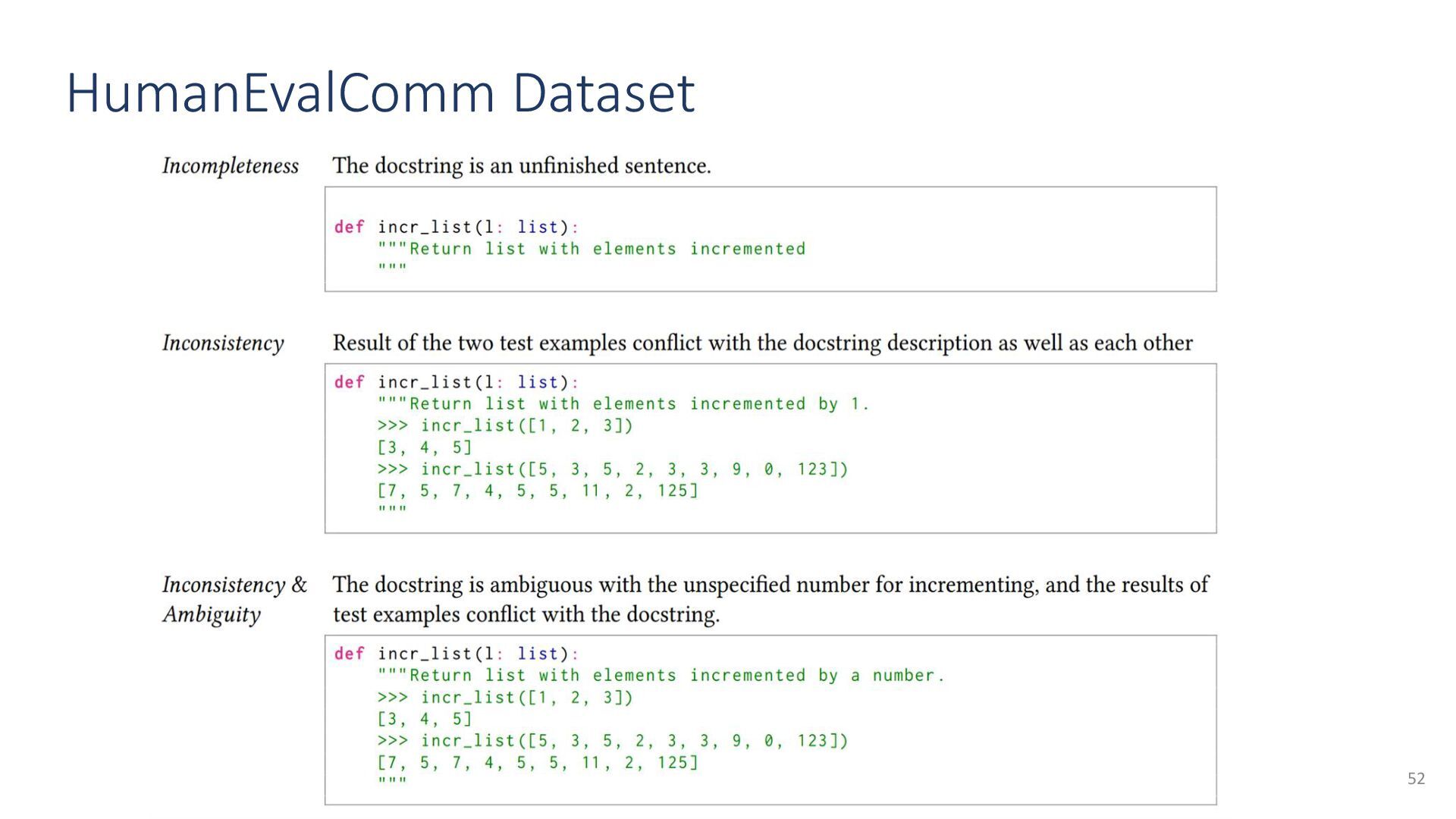{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
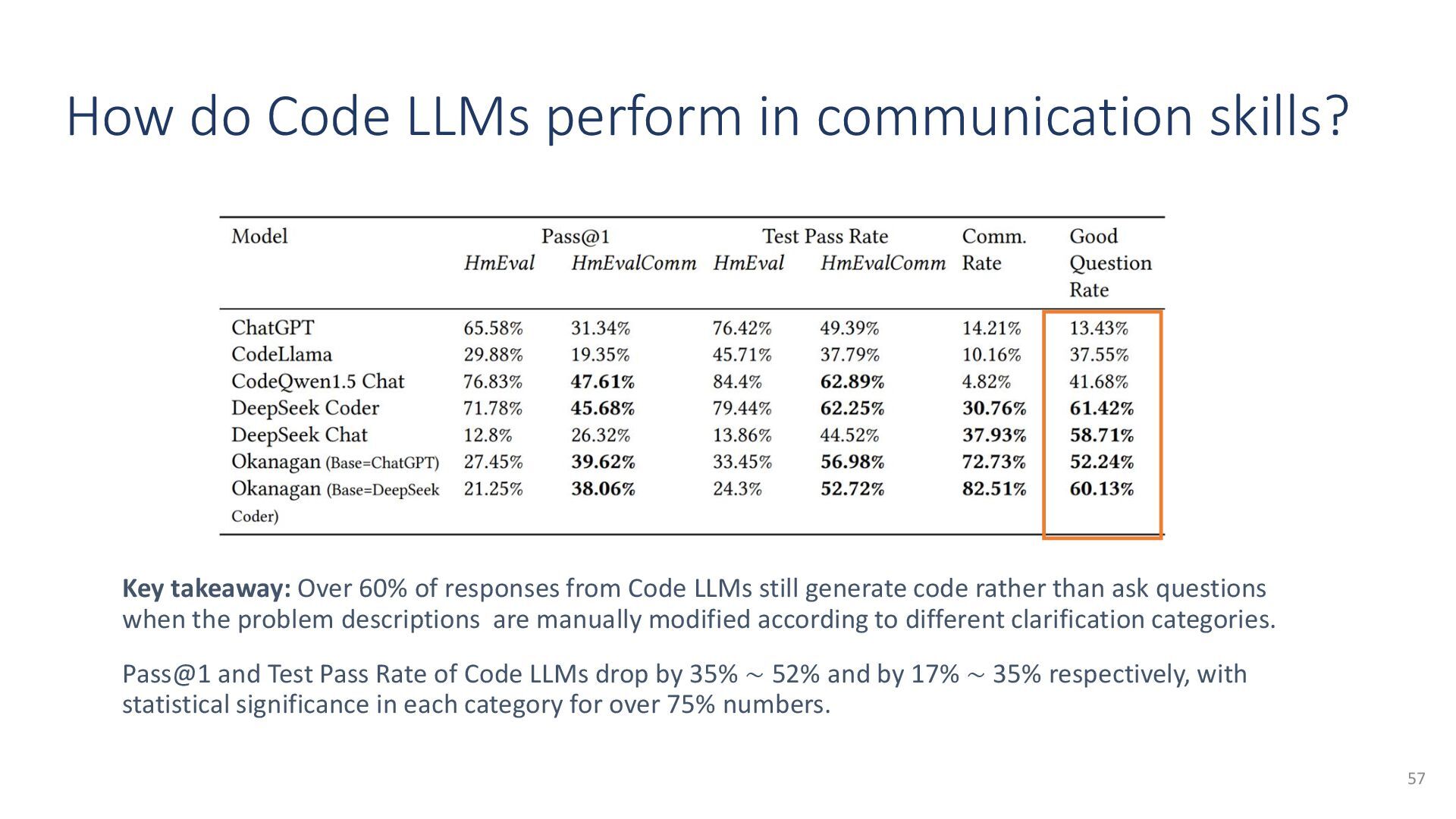{kind=link}
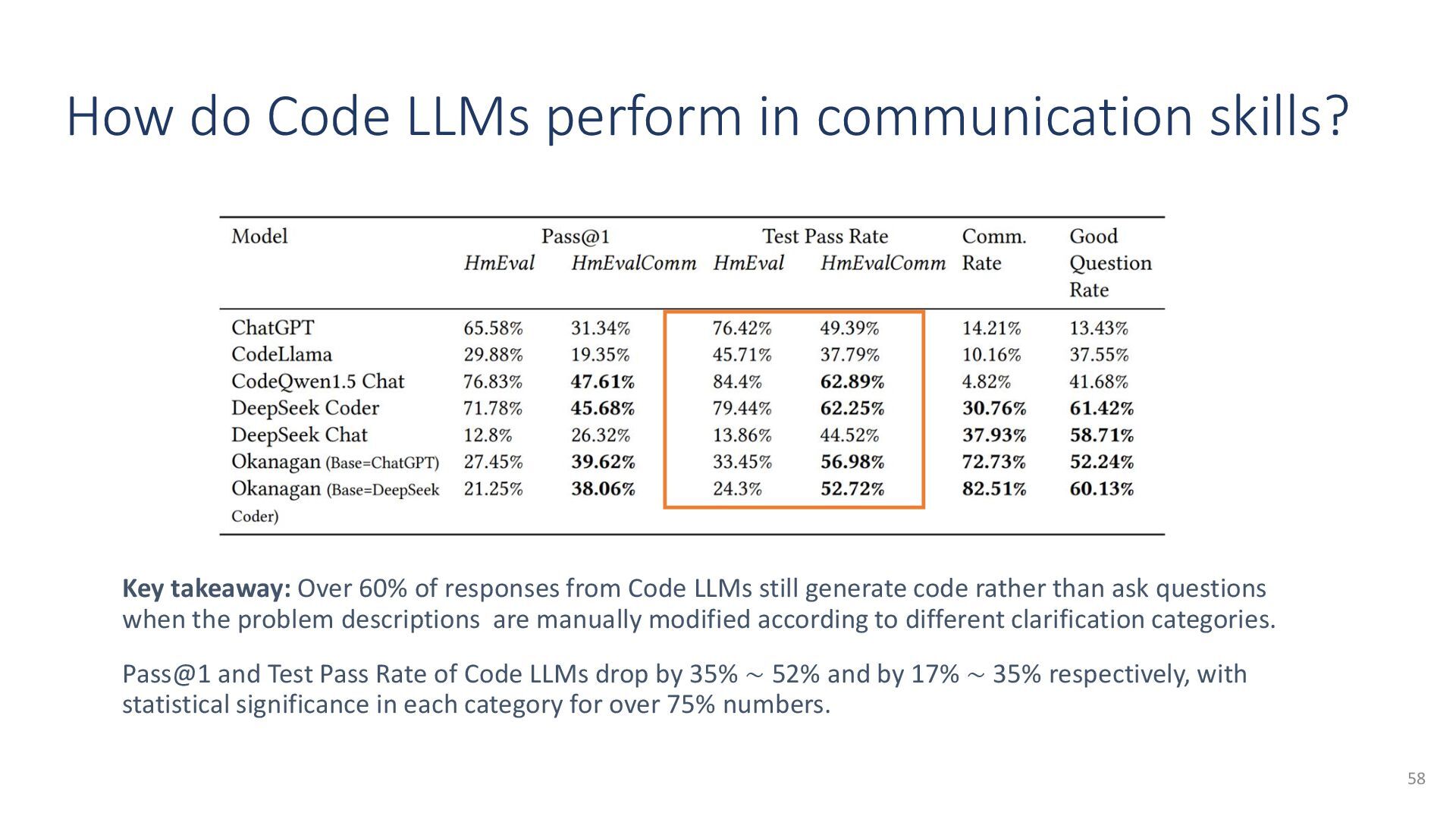{kind=link}
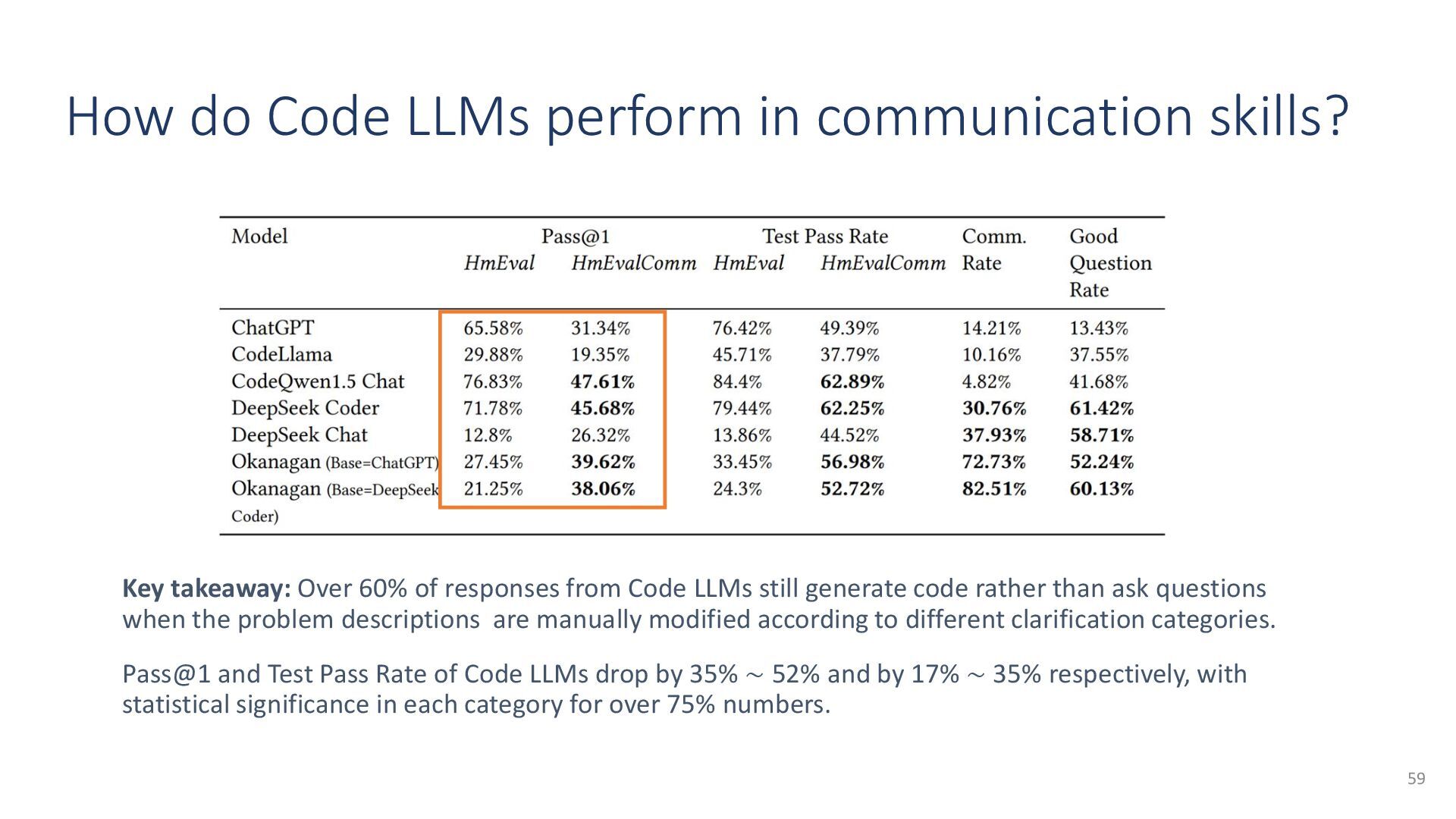{kind=link}
{kind=link}
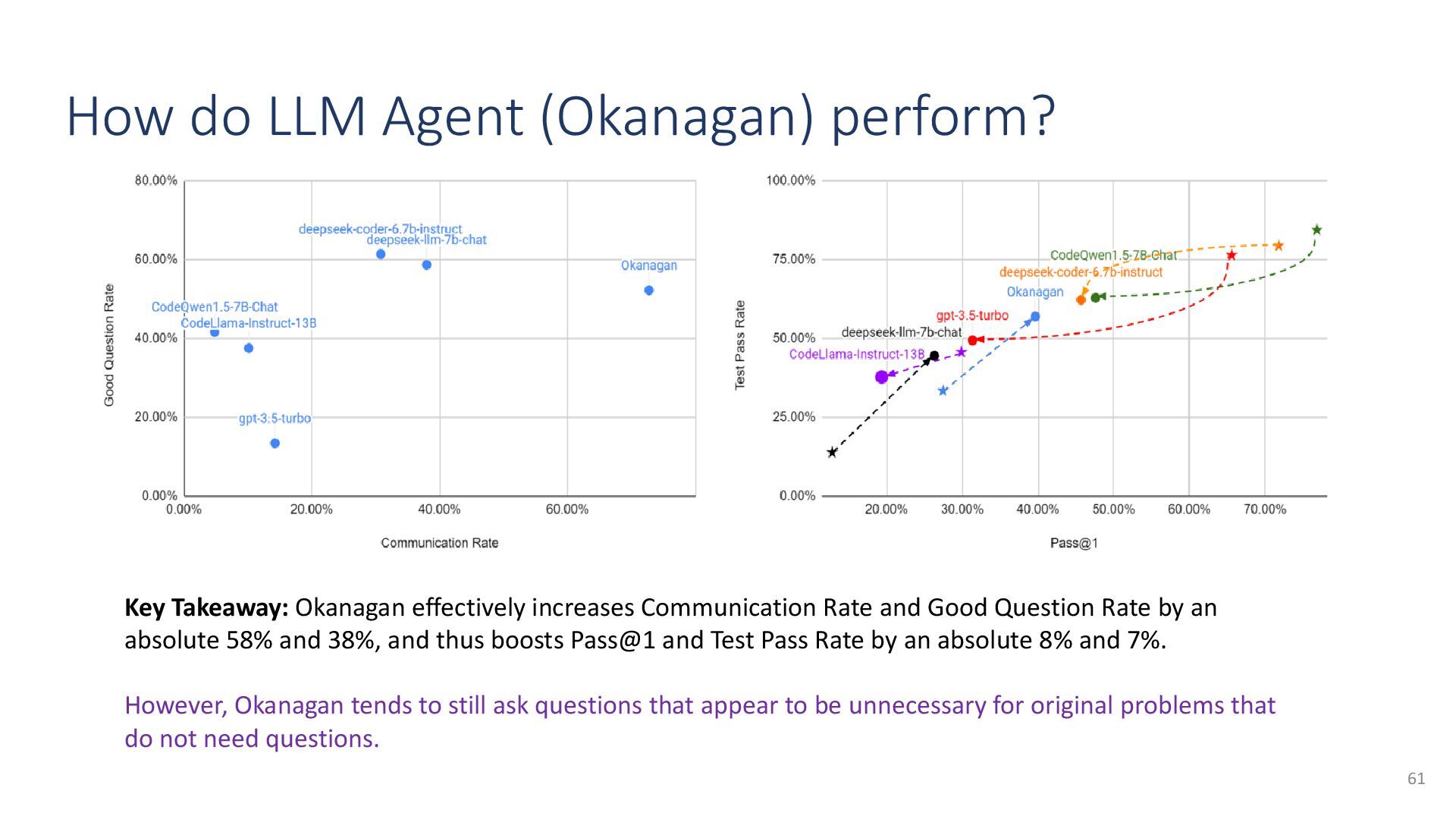{kind=link}
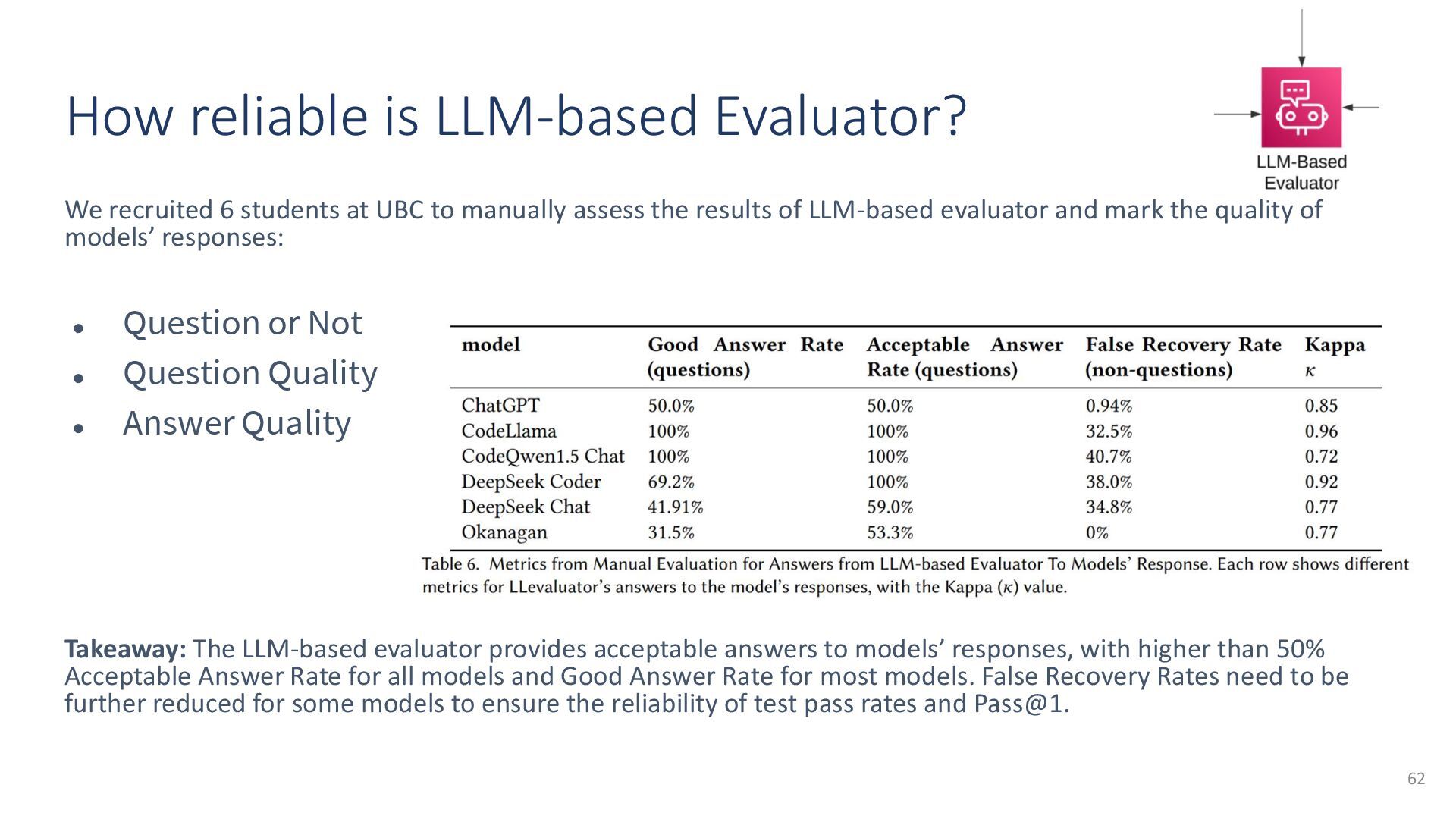{kind=link}
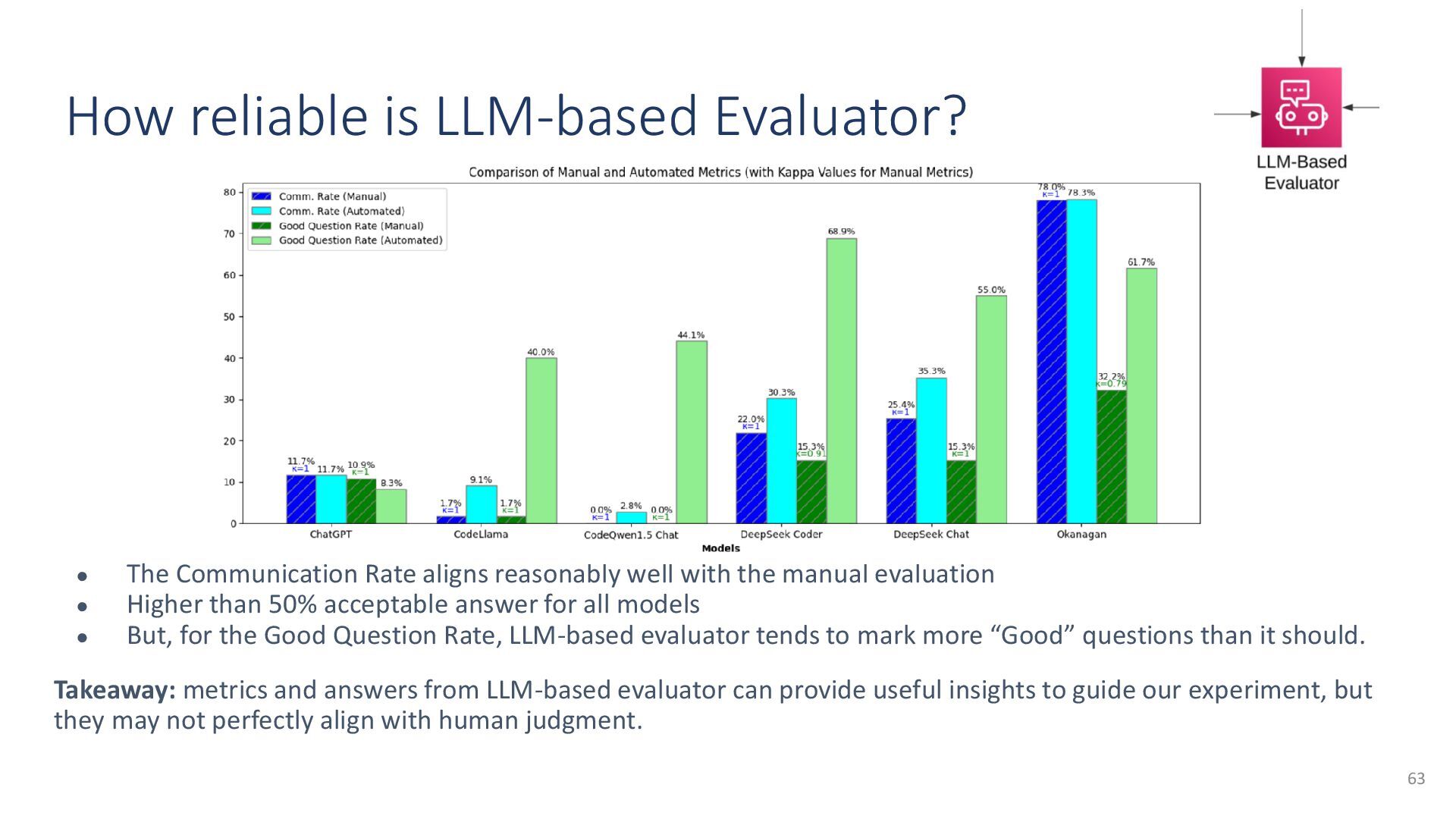{kind=link}
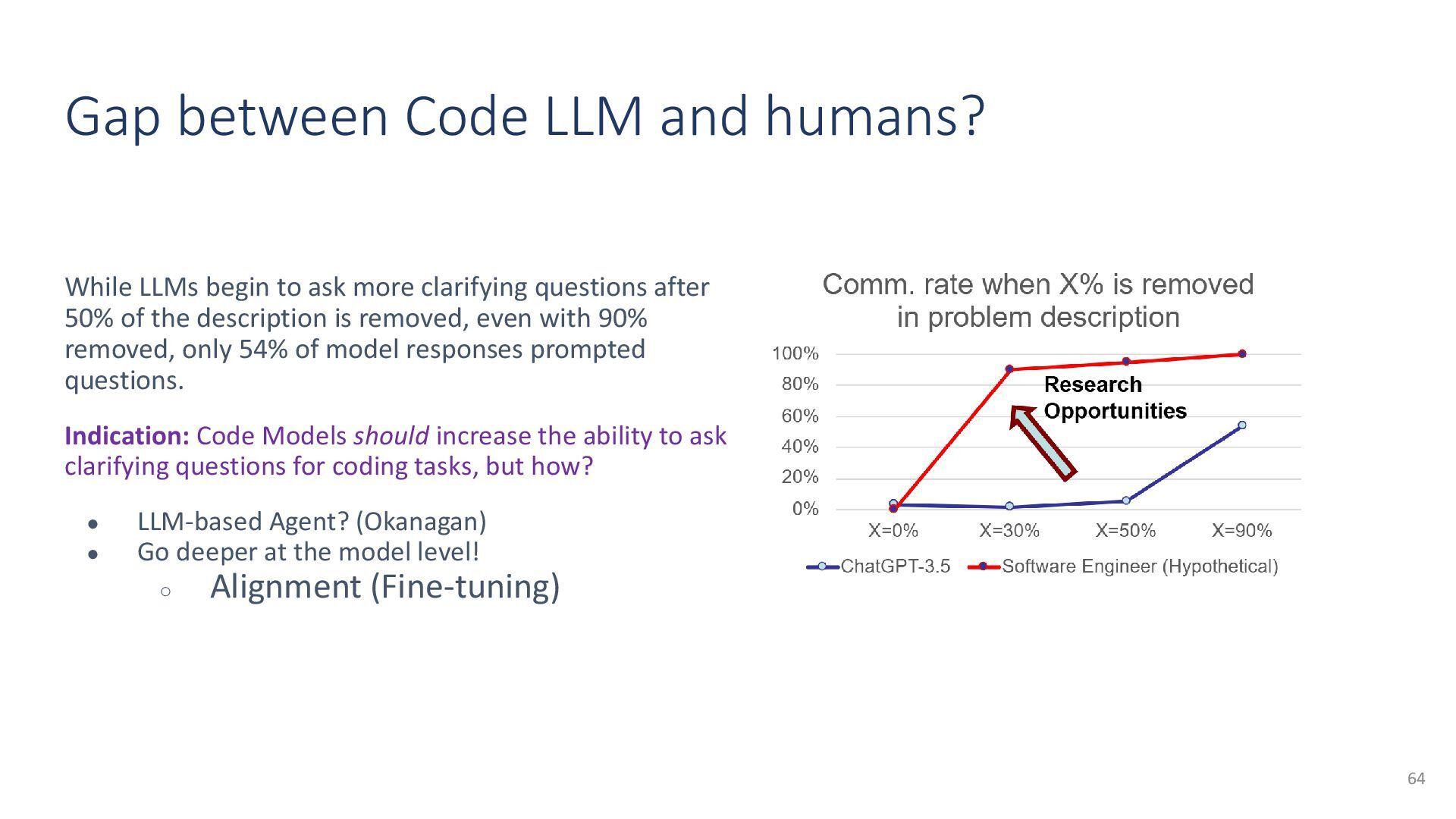{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
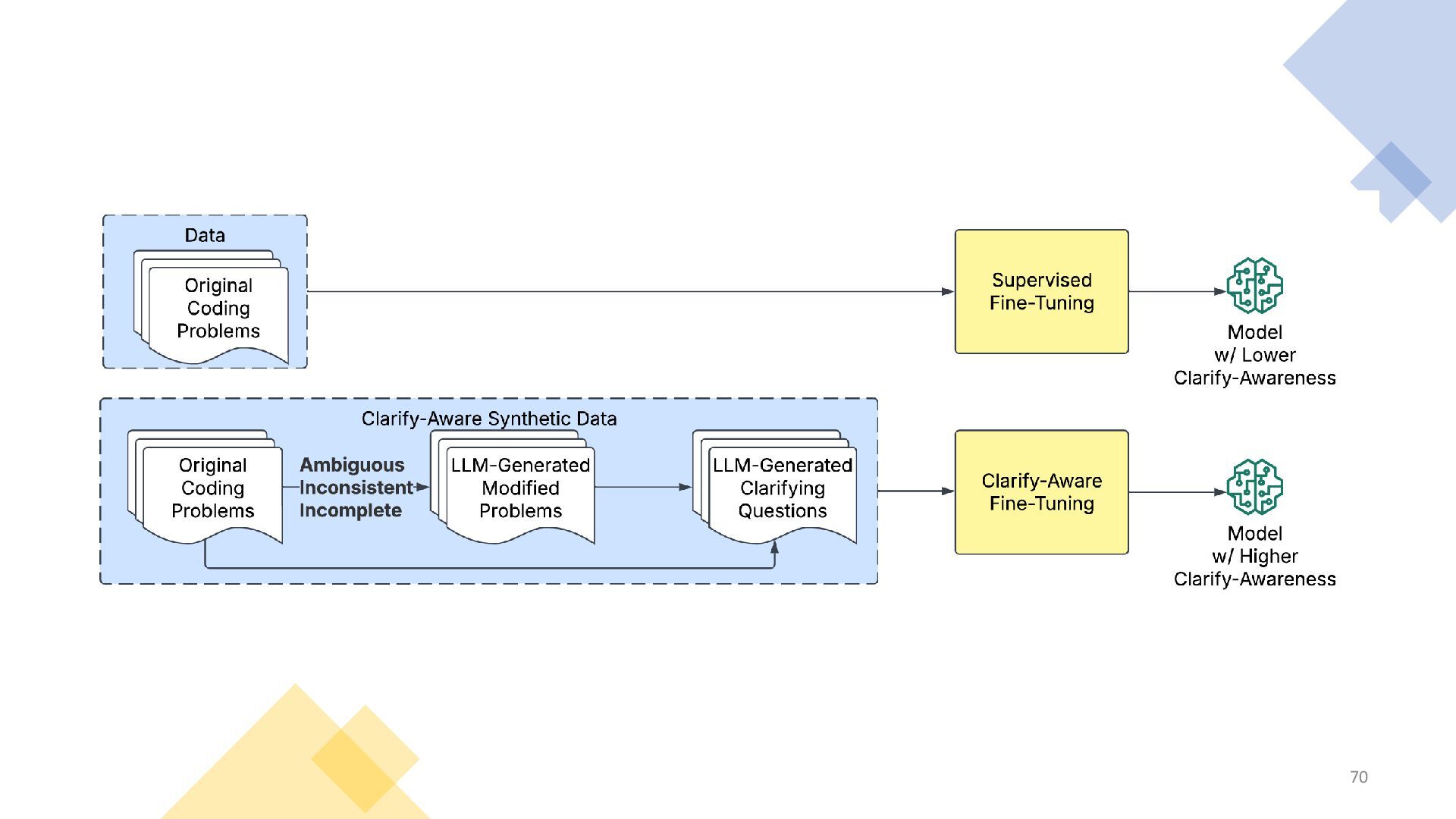{kind=link}
{kind=link}
{kind=link}
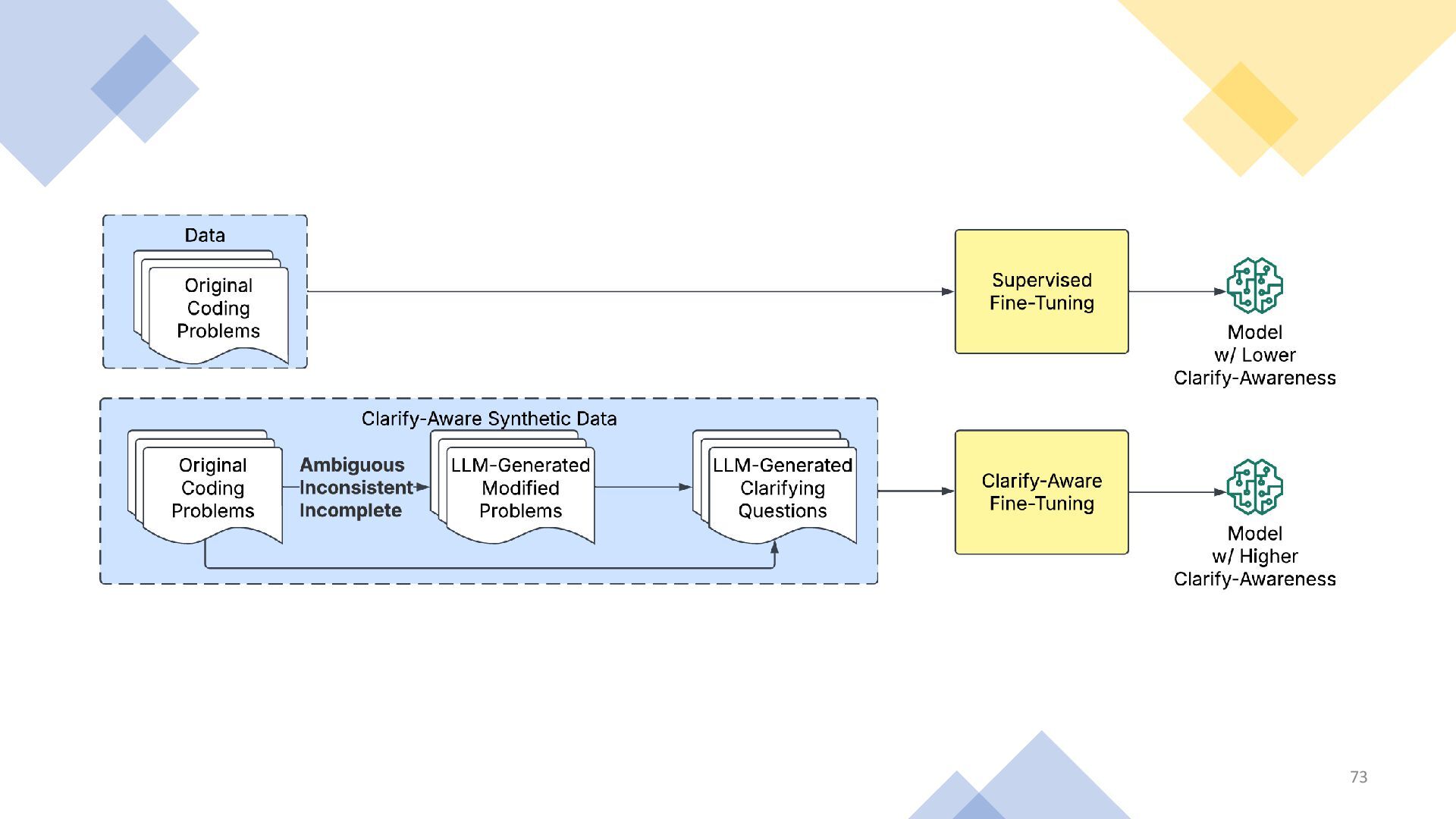{kind=link}
{kind=link}
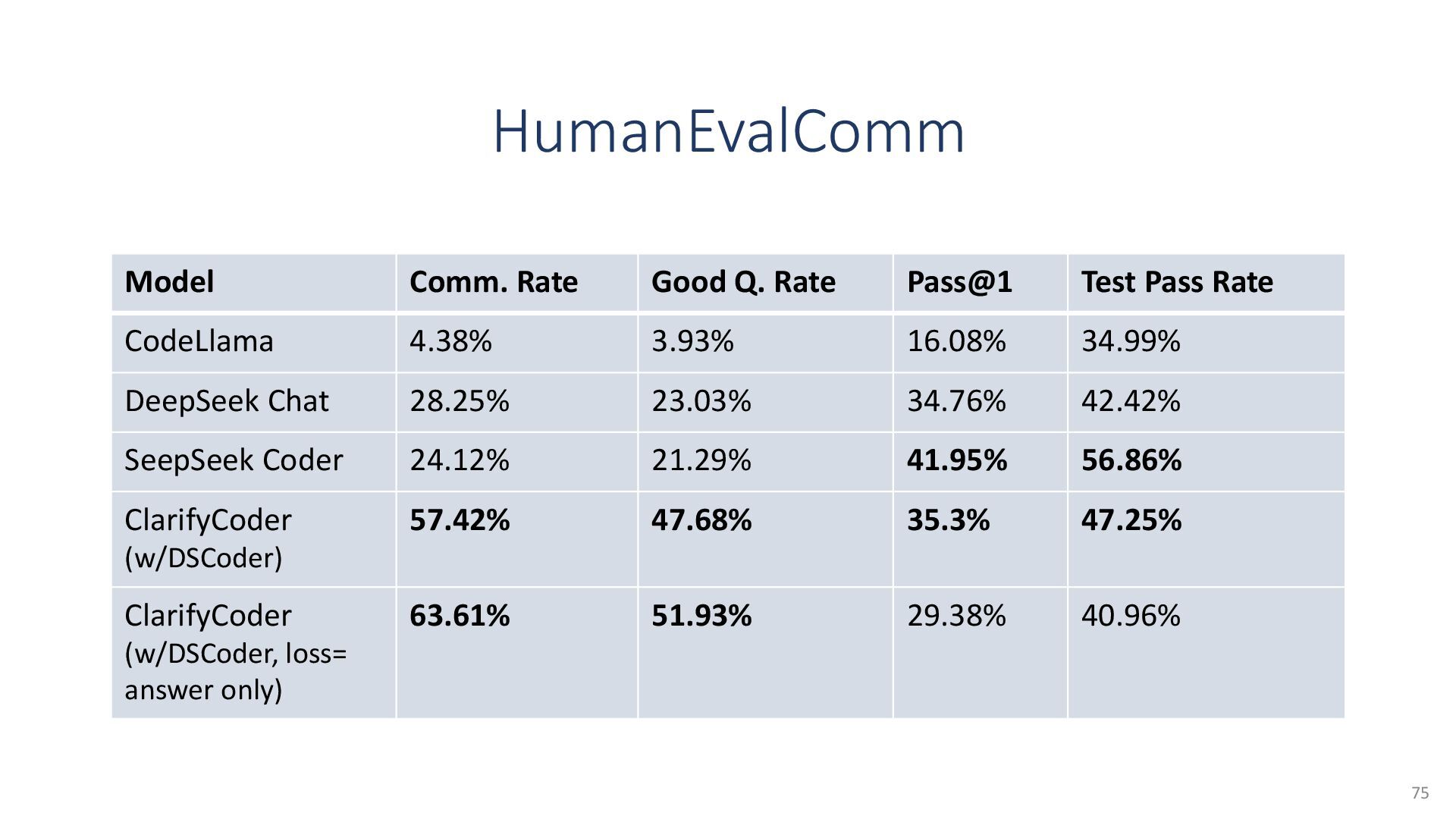{kind=link}
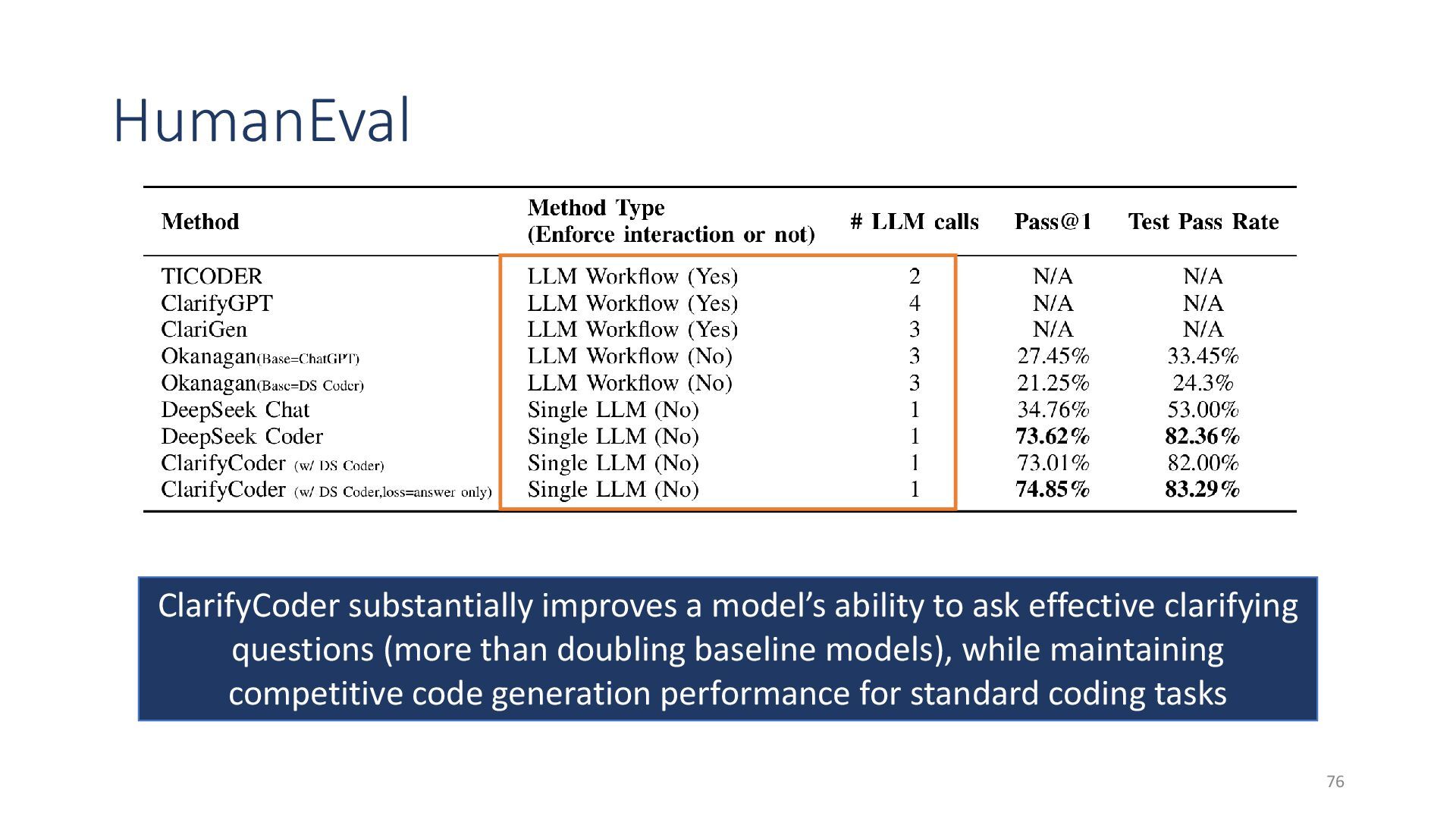{kind=link}
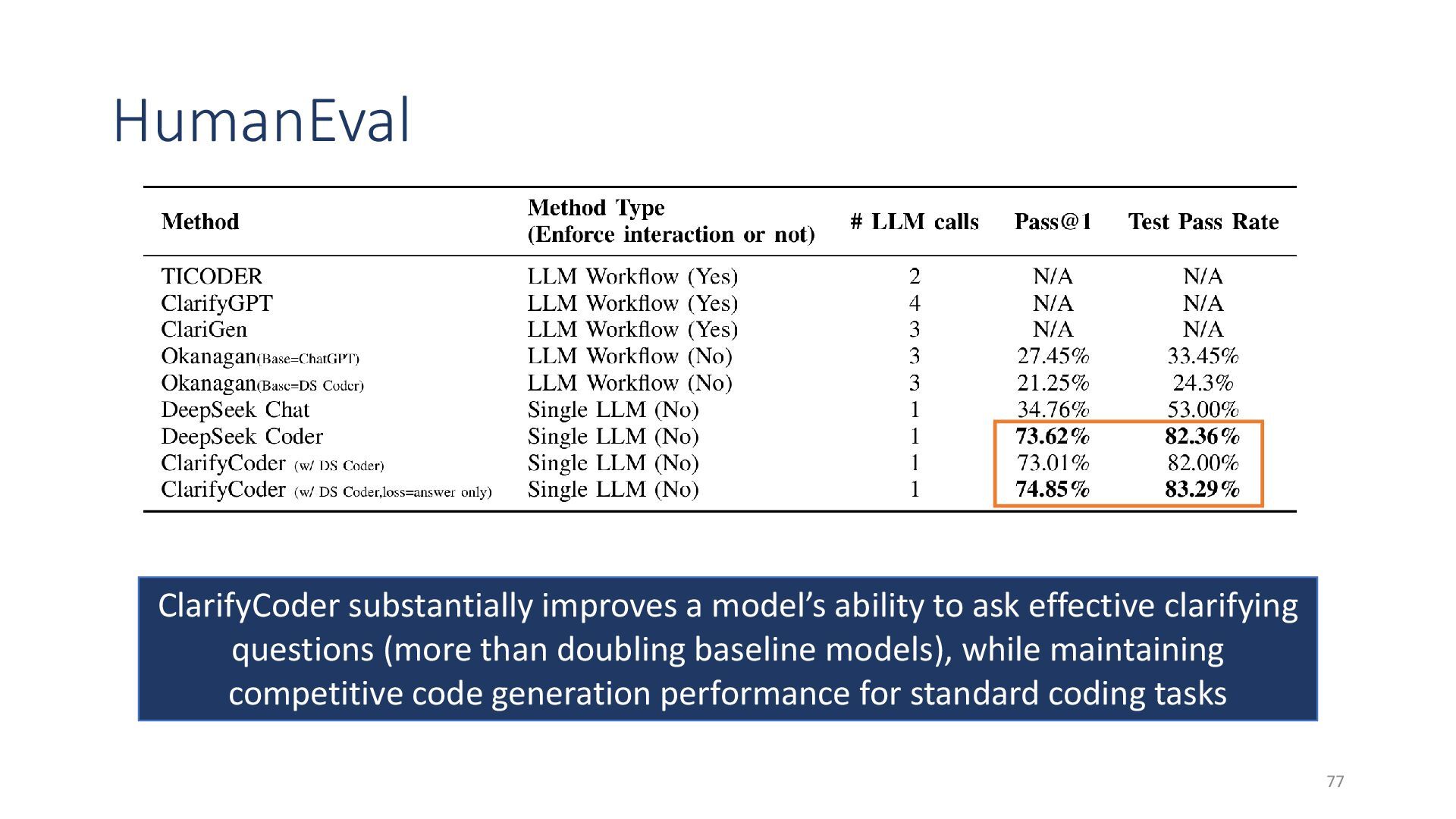{kind=link}
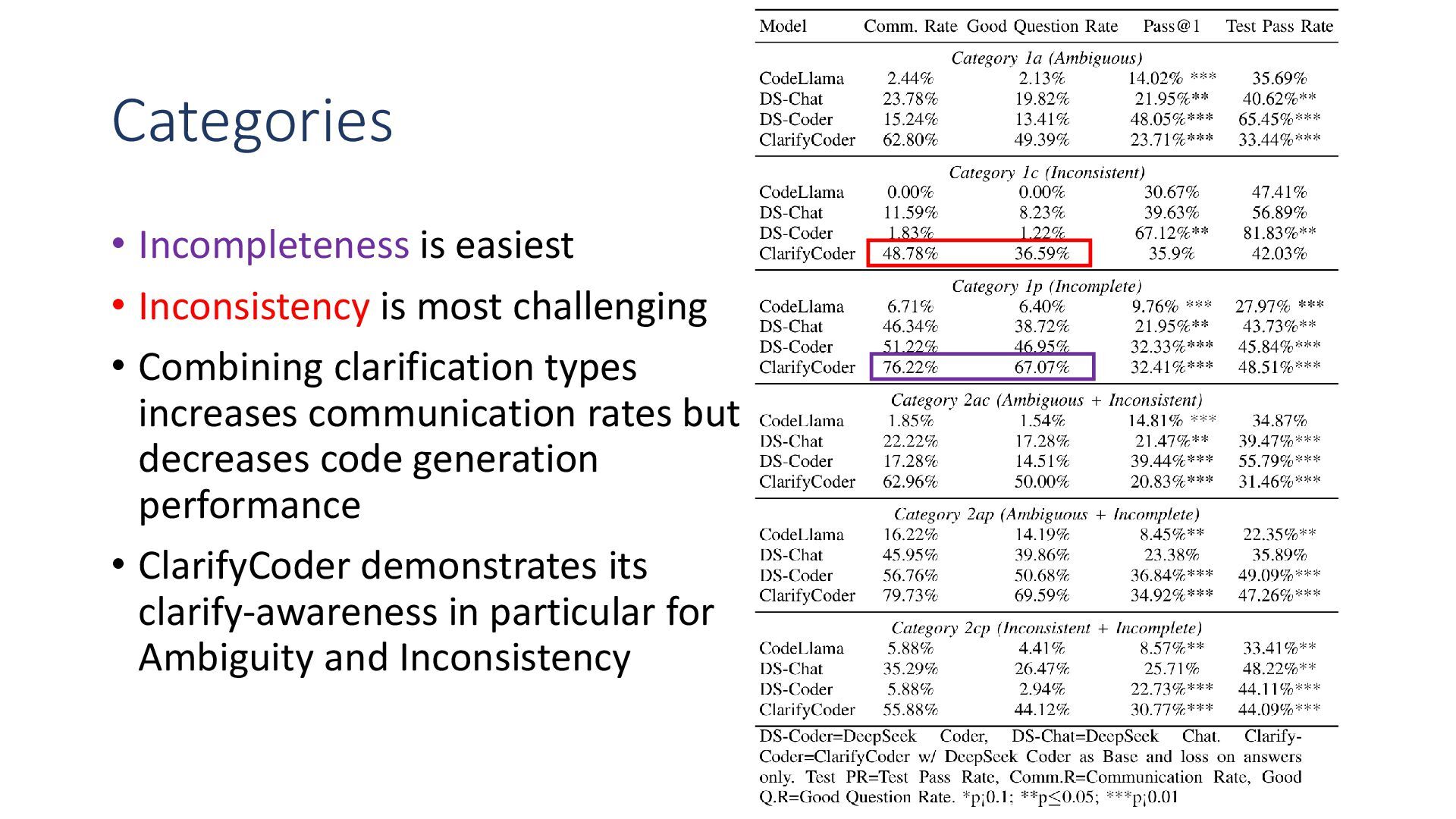{kind=link}
{kind=link}
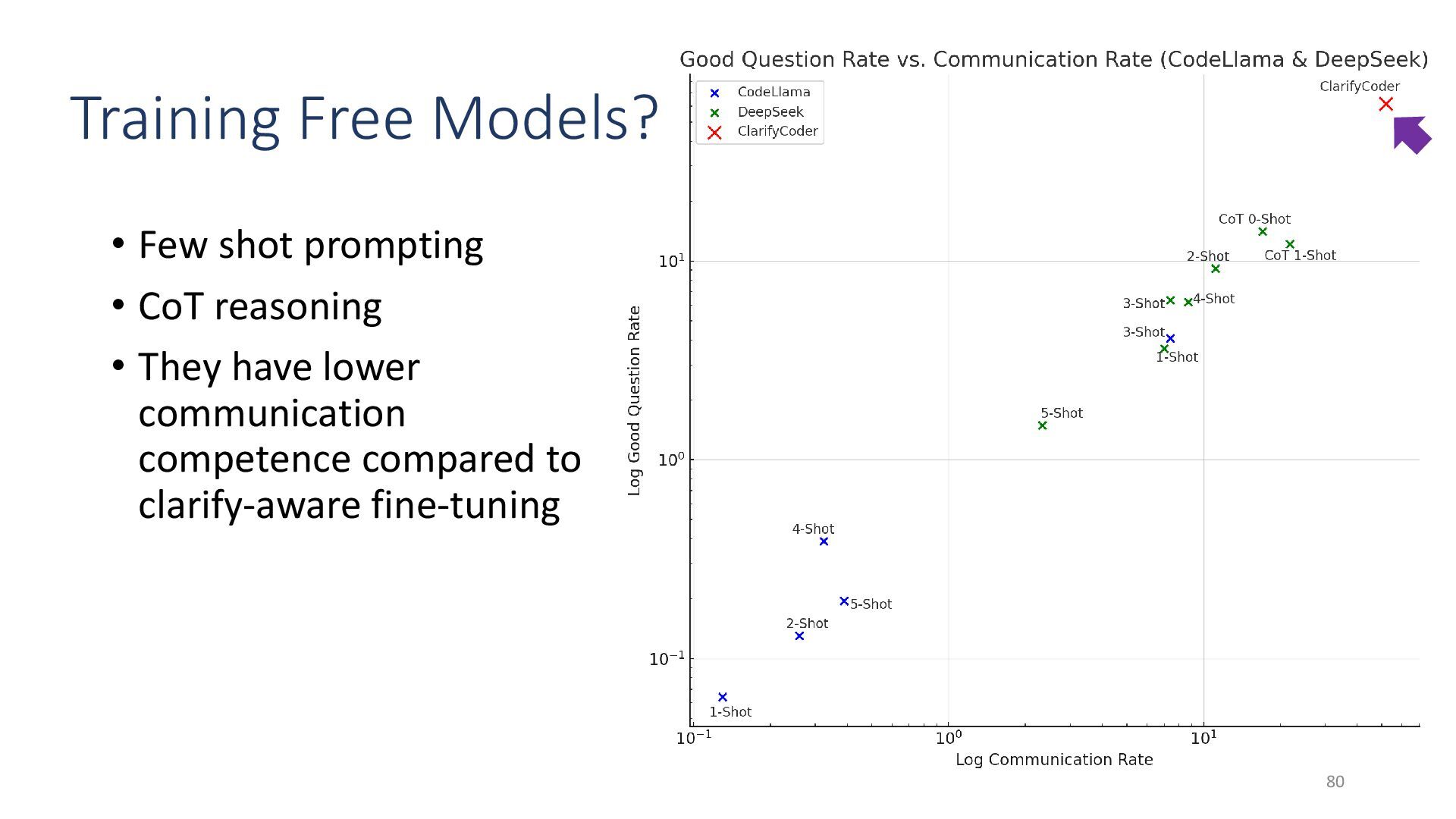{kind=link}
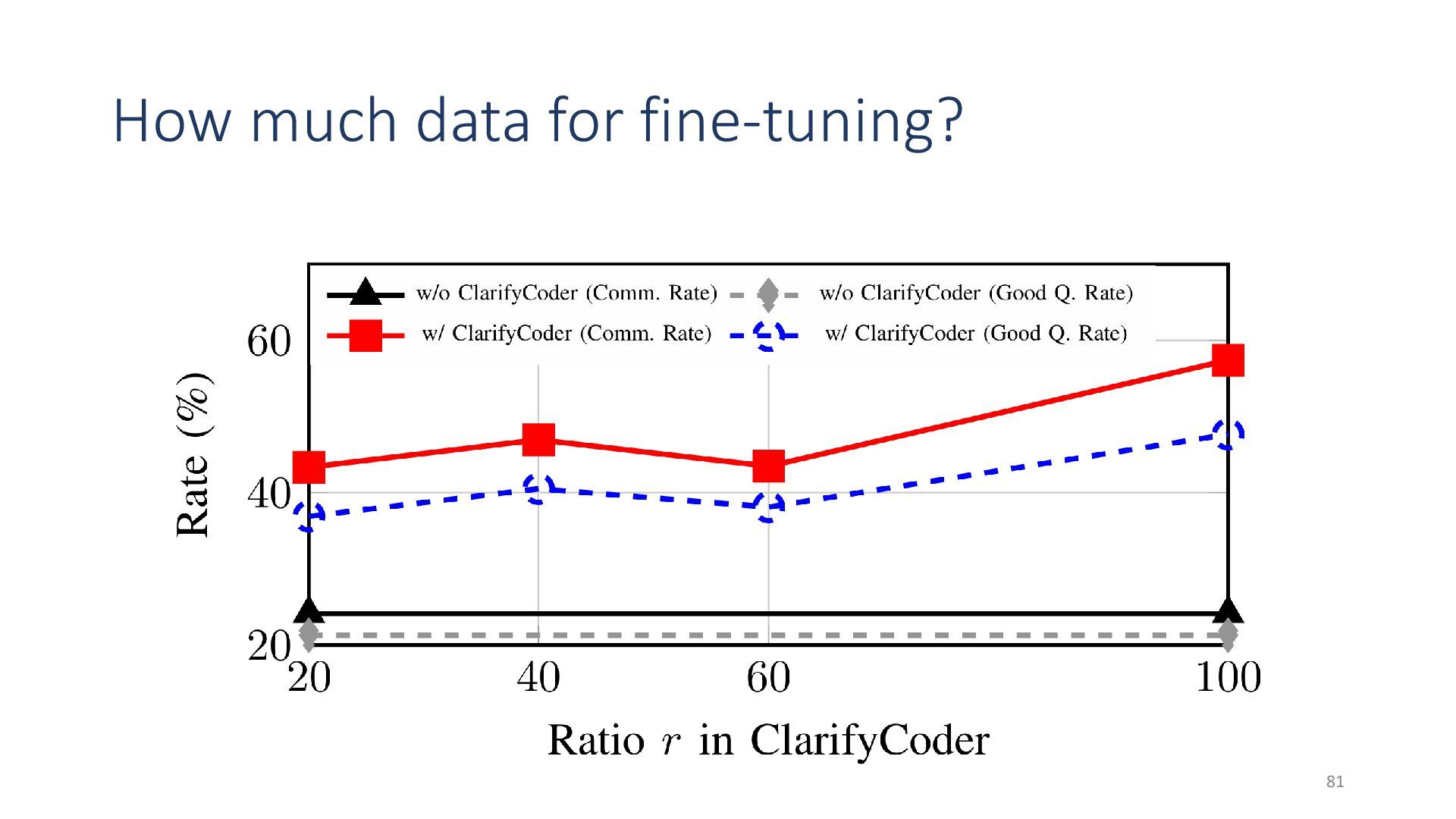{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
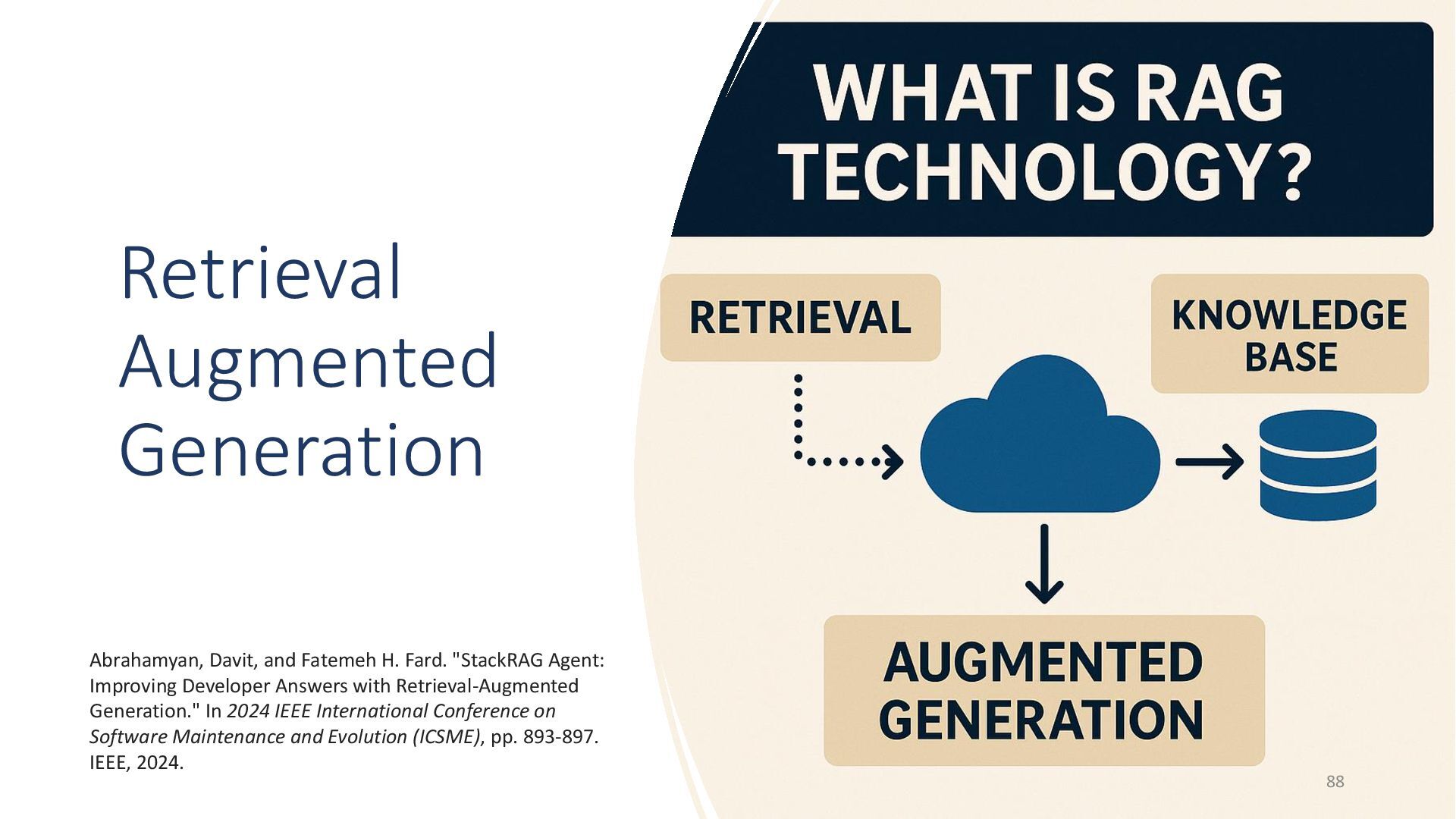{kind=link}
{kind=link}
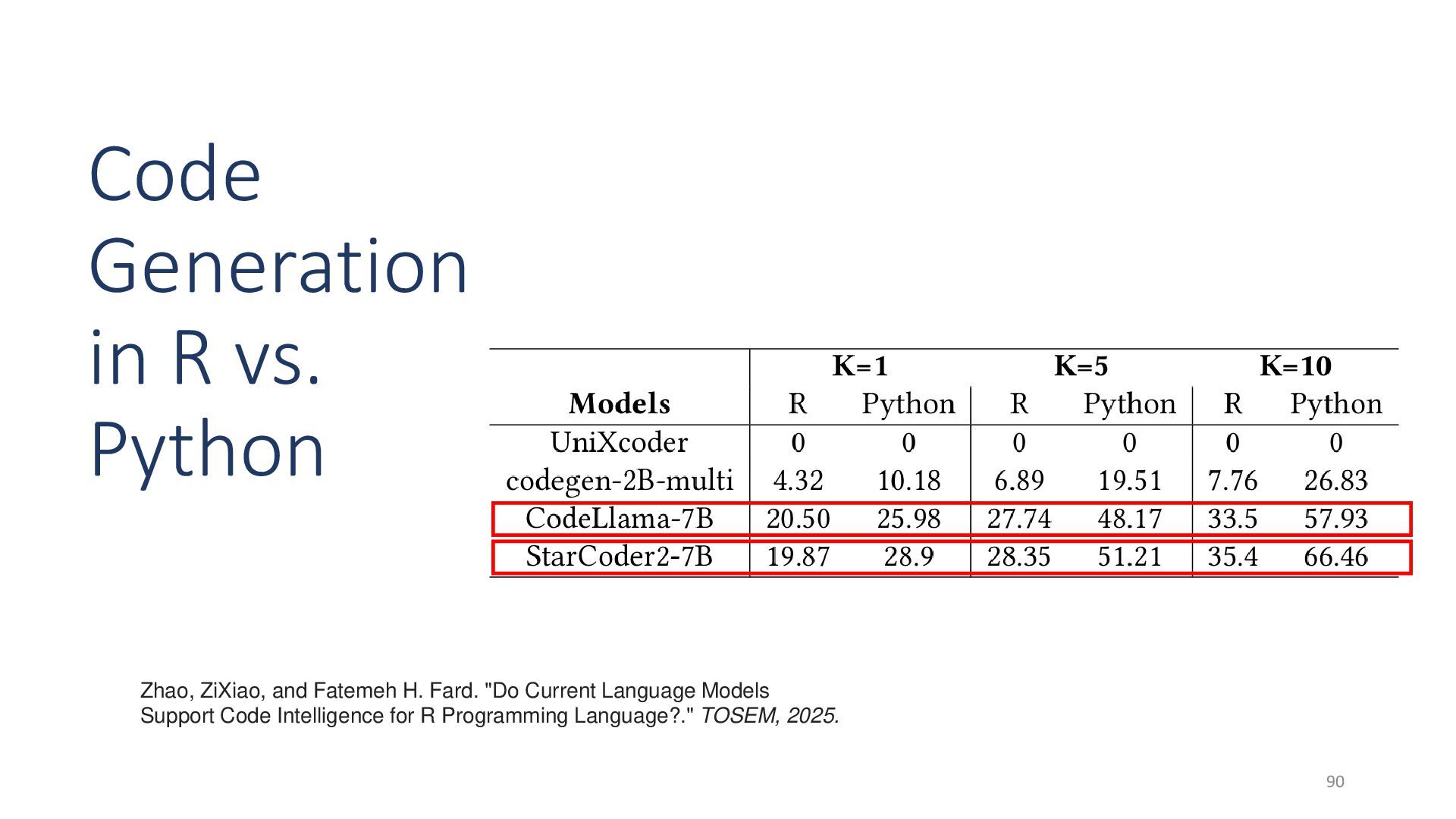{kind=link}
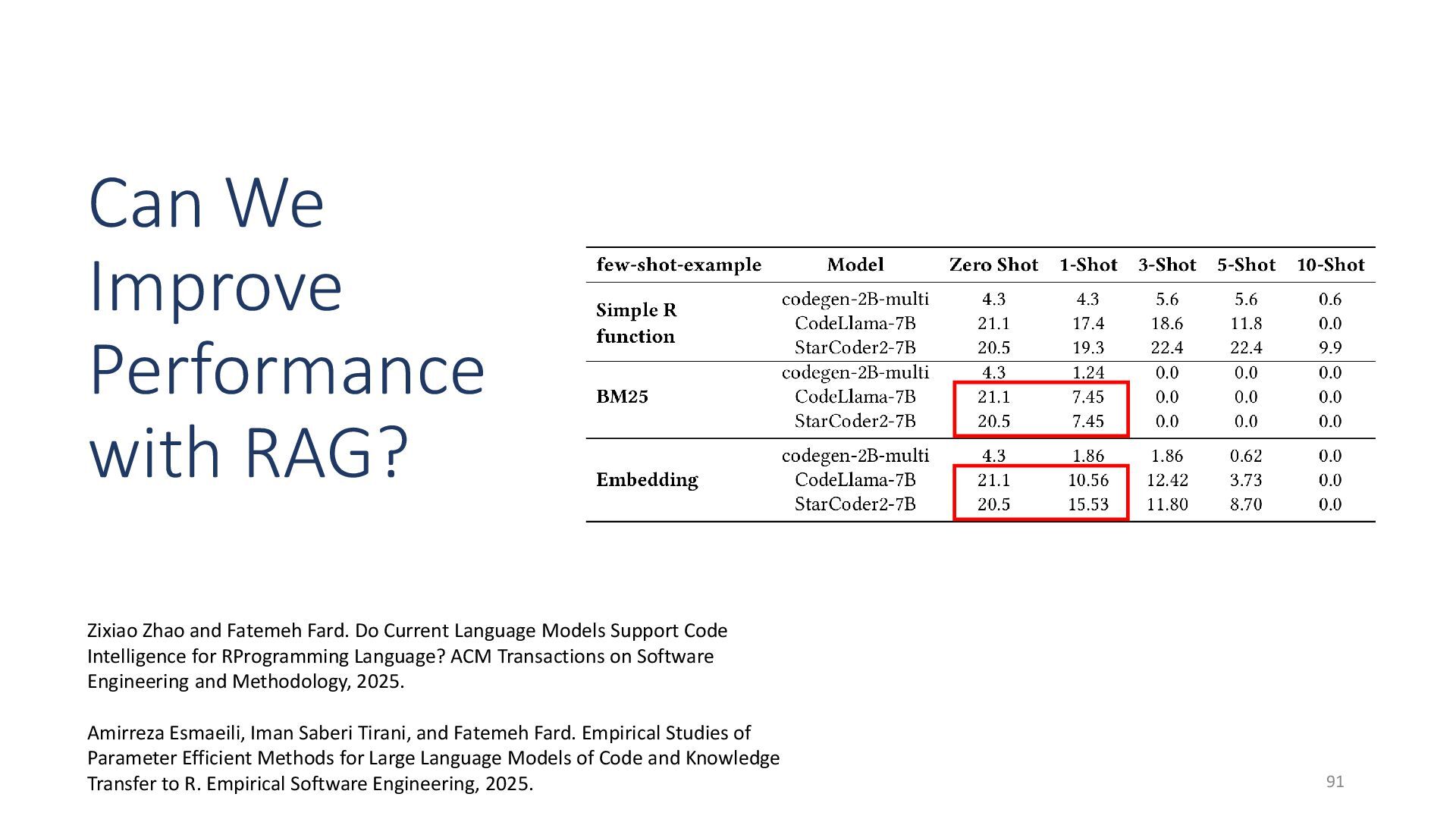{kind=link}
{kind=link}
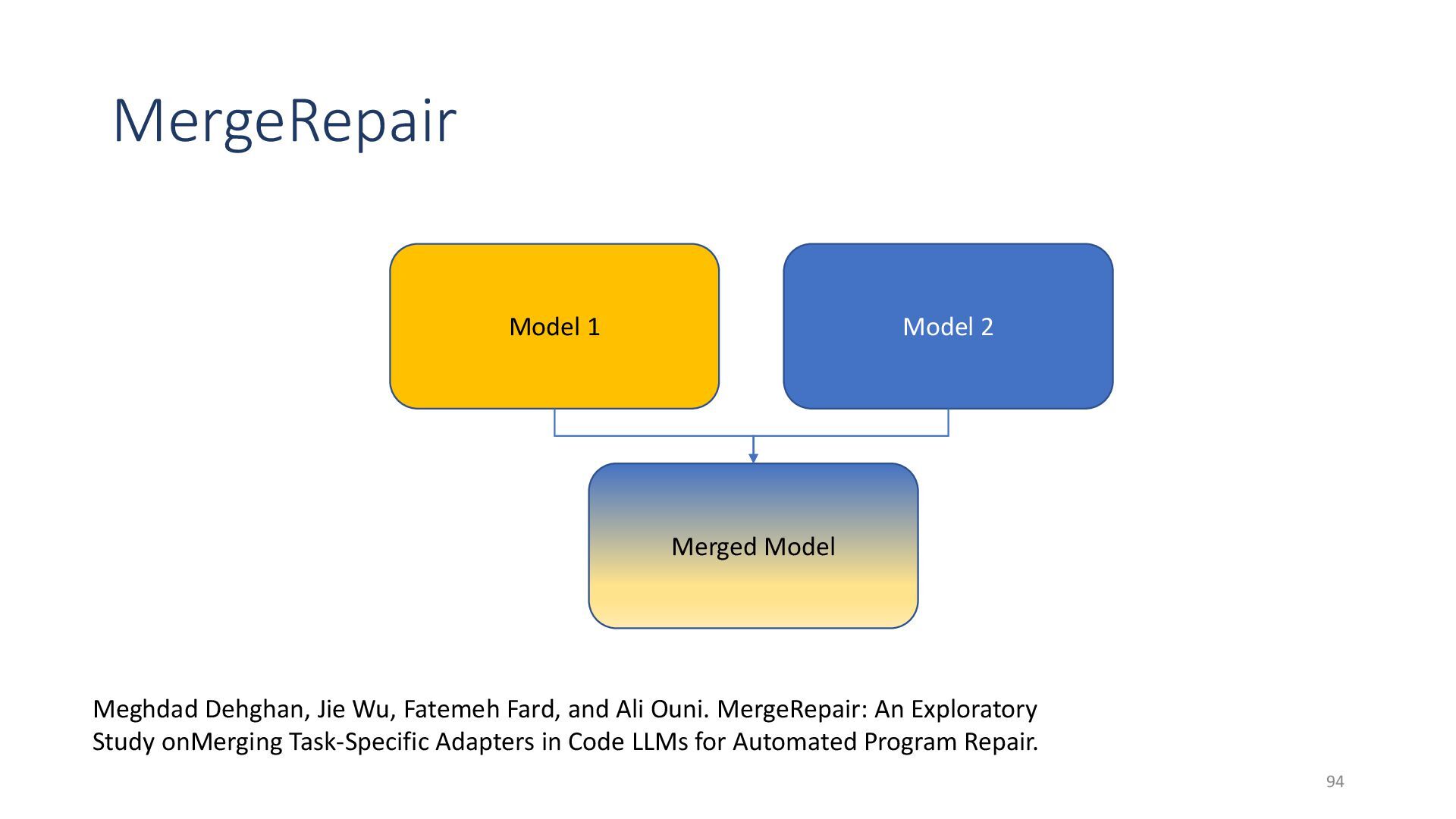{kind=link}
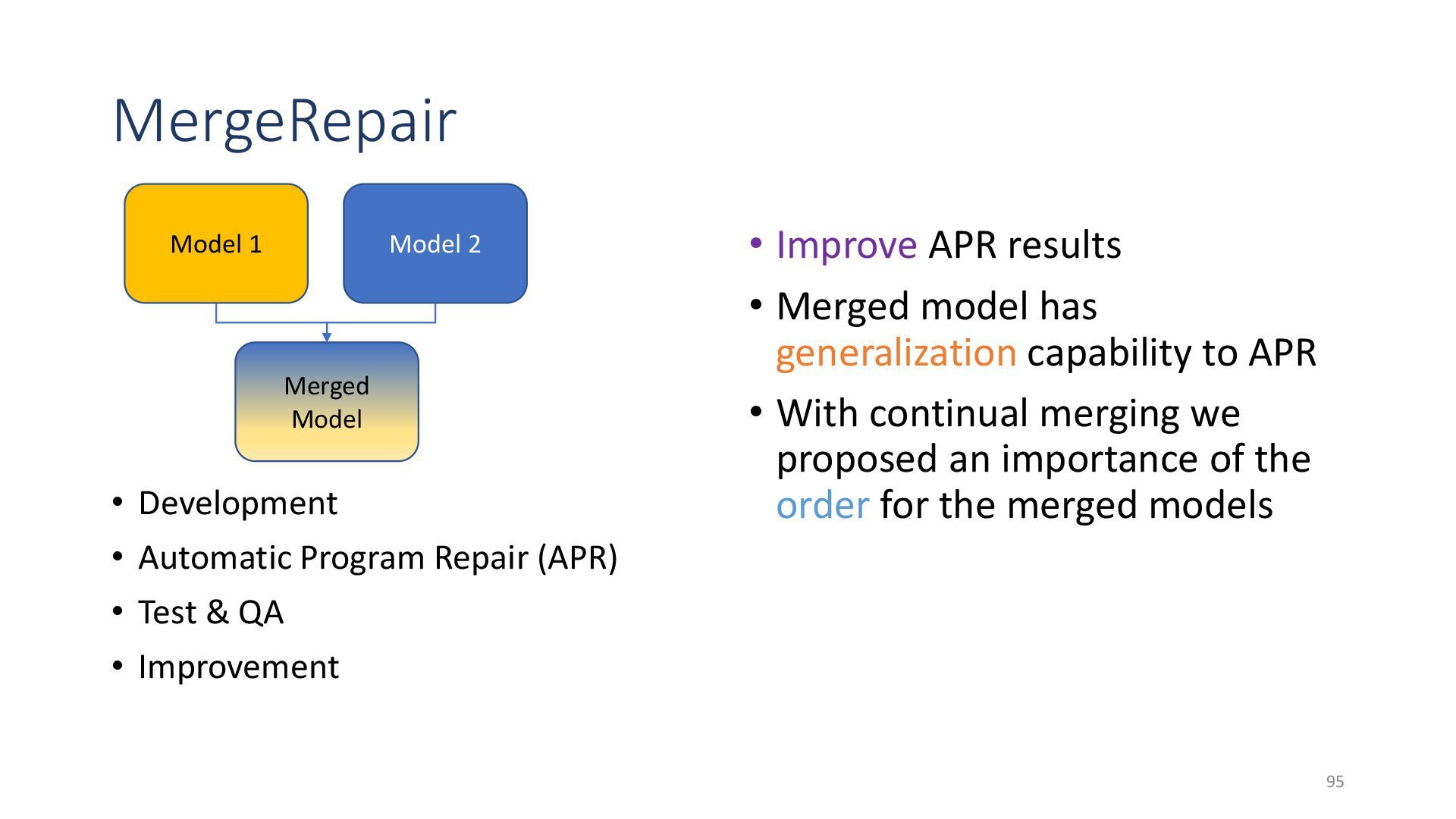{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}