This talk will explain my experience when I join in a new engineering team. I mean a DevOps team as a team that includes developers and IT operations working collaboratively throughout the product lifecycle.
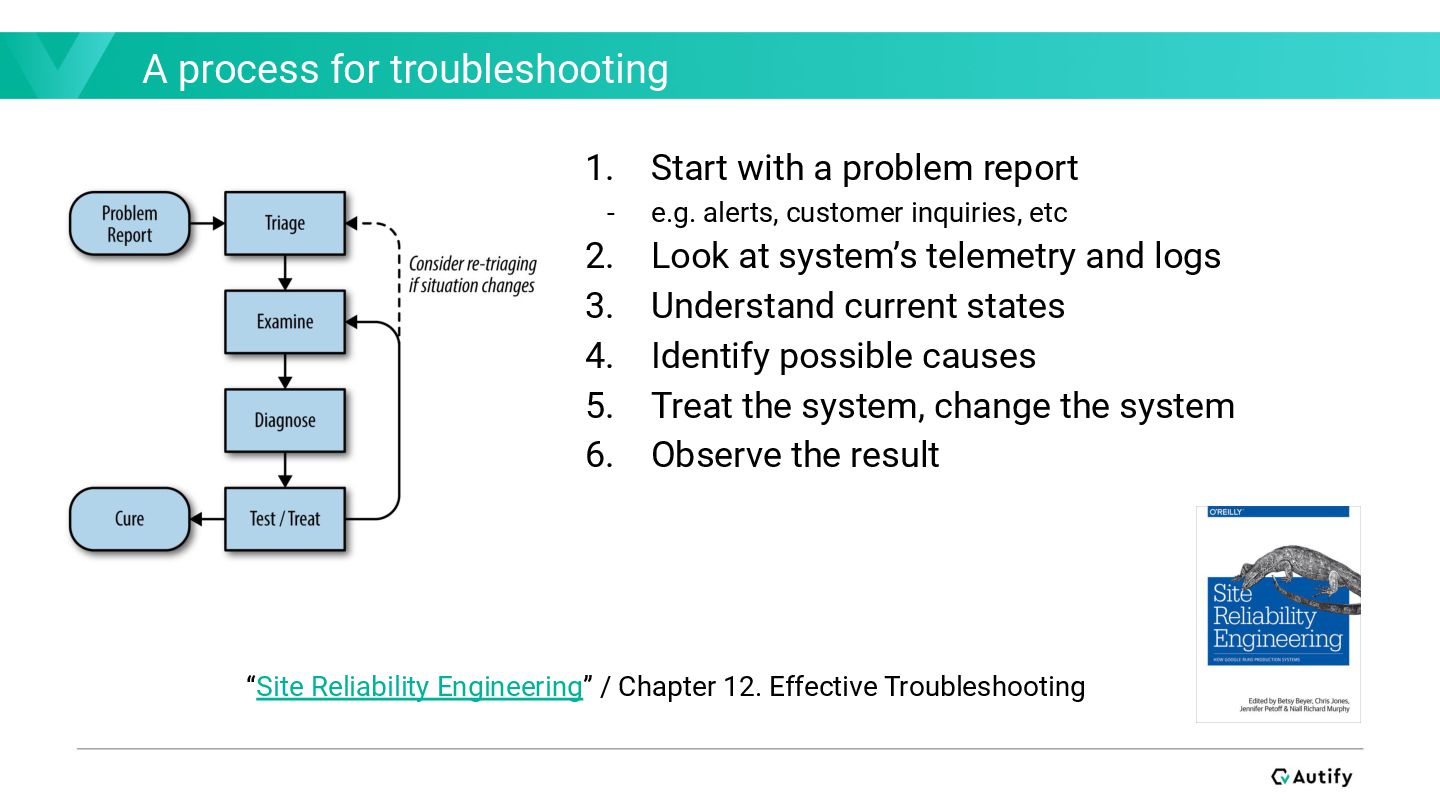
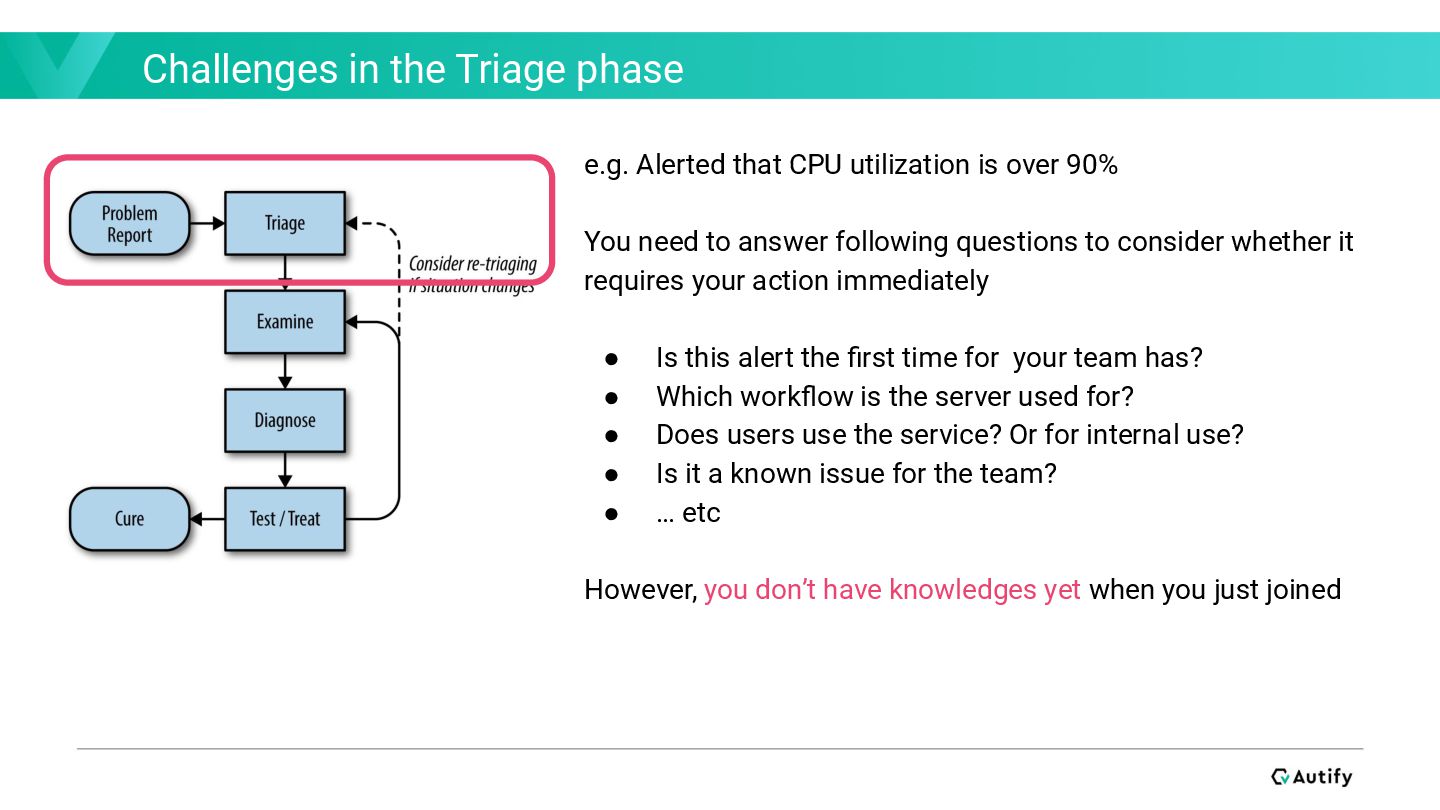
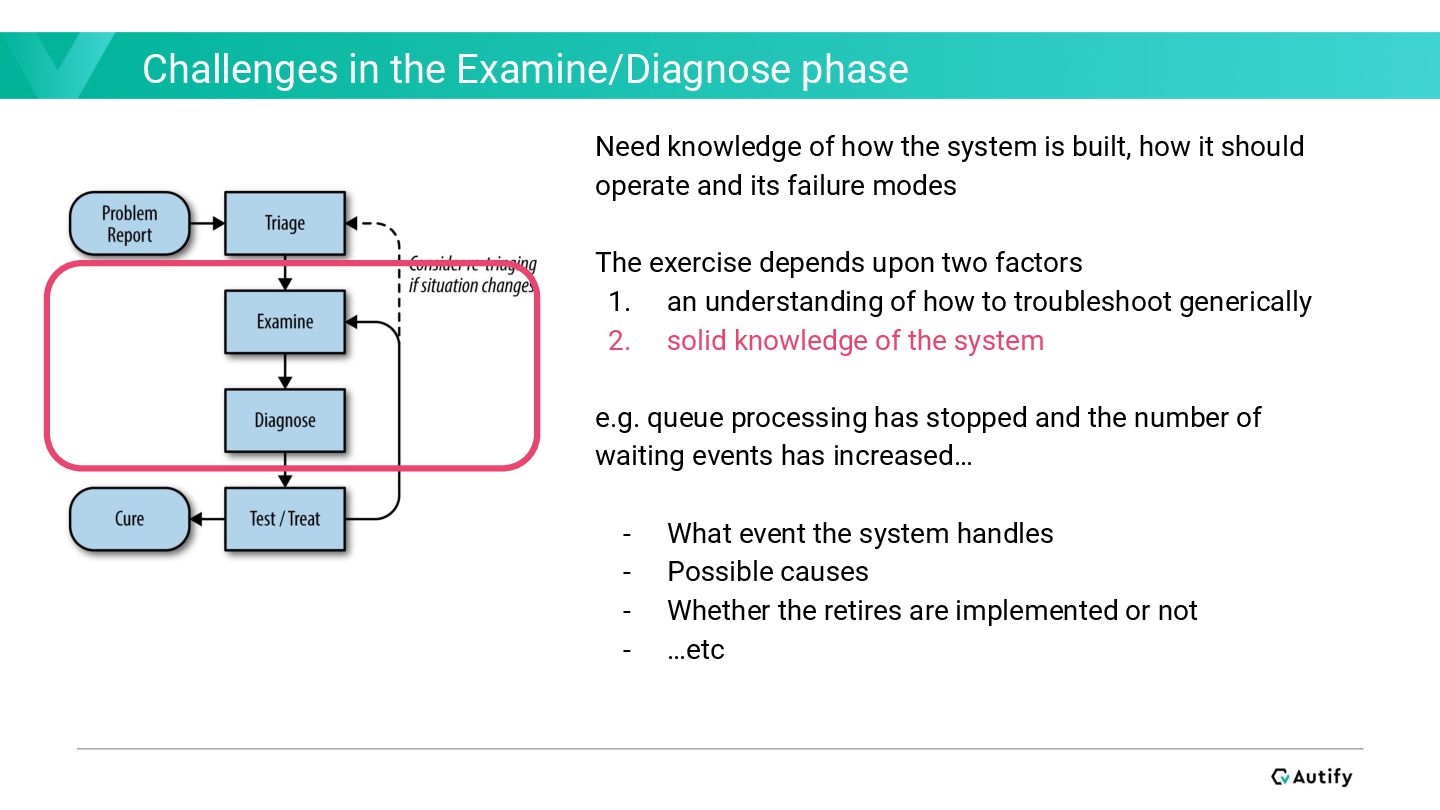
In the recording phase, let’s write up missing documentation behalf of teammates. Even if you cannot solve issues directly, it would be helpful to your team. There, writing Runbooks give you chances to understand your service and participate in operations. I would recommend you write the “Architecture” part to organize your understanding of your service’s technical design.
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}