Upgrade to Pro
— share decks privately, control downloads, hide ads and more …
Speaker Deck
Features
Speaker Deck
PRO
Sign in
Sign up for free
Search
Search
IQ-MEANS: Web-Scale Image Clustering Revisited
Search
Sponsored
·
Your Podcast. Everywhere. Effortlessly.
Share. Educate. Inspire. Entertain. You do you. We'll handle the rest.
→
Keisuke OGAKI
February 06, 2016
94
0
Share
Embed
Copy iframe code
Copy JS code
Copy link
Start on current slide
IQ-MEANS: Web-Scale Image Clustering Revisited
コンピュータビジョン勉強会: ICCV2015読み会での論文紹介です
https://kantocv.connpass.com/event/24696/
Keisuke OGAKI
February 06, 2016
More Decks by Keisuke OGAKI
See All by Keisuke OGAKI
アクセント学: "エムスリー"のアクセントは-3型なのか平板型なのかの謎に迫る
hiking
0
62
Slackの絵文字サジェストを機械学習でリバースエンジニアリング
hiking
0
2.6k
gokart Feature Proposal: ConditionalSignificantParameter
hiking
0
170
Gokart Feature Discussion: What's read_environ()
hiking
0
160
画像から撮影場所を当てる話 ~ 理論的背景 & どこが〇〇区らしいか ~
hiking
0
280
KDD2021読み会
hiking
0
130
SIGIR2021読み会
hiking
0
230
臨床AIイントロダクション
hiking
0
5.1k
アンケートと組み合わせて 説明可能なログ分析を行う
hiking
3
2.6k
Featured
See All Featured
SEO Brein meetup: CTRL+C is not how to scale international SEO
lindahogenes
1
2.8k
Learning to Love Humans: Emotional Interface Design
aarron
275
41k
Building Adaptive Systems
keathley
44
3.1k
How To Speak Unicorn (iThemes Webinar)
marktimemedia
1
500
How to Build an AI Search Optimization Roadmap - Criteria and Steps to Take #SEOIRL
aleyda
1
2.1k
I Don’t Have Time: Getting Over the Fear to Launch Your Podcast
jcasabona
34
2.8k
Rebuilding a faster, lazier Slack
samanthasiow
85
9.6k
State of Search Keynote: SEO is Dead Long Live SEO
ryanjones
0
220
Collaborative Software Design: How to facilitate domain modelling decisions
baasie
1
260
[RailsConf 2023] Rails as a piece of cake
palkan
59
6.7k
SEO in 2025: How to Prepare for the Future of Search
ipullrank
3
3.6k
ラッコキーワード サービス紹介資料
rakko
1
3.9M
Transcript
WEB-SCALE IMAGE CLUSTERING REVISITED IQ-MEANS 株式会社ドワンゴ コンピュータヴィジョングループ 大垣慶介
WEB-SCALE IMAGE CLUSTERING REVISITED • Yannis Avrithis, Yannis Kalantidis, Evangelos
Anagnostopoulos, Ioannis Z. Emiris , from University of Athens, Yahoo! Labs • Oral Session 2C - Statistical Methods and Learning • プロダクト量子化したコードをK-meansする、IQ-Meansを提案
背景
WEB-SCALE K-MEANS Webの強豪企業たちの戦い。 • 2010, WWW: “Web-Scale K-Means Clustering” •
Google • ターゲットは特に画像ではない • Mini batch法。sklearnにも実装されてるのでお世話になっている • 2015, CVPR: “Web Scale Photo Hash Clustering on A Single Machine” • Facebook AIラボ • バイナリ特徴を使う • 2015, ICCV: “Web-scale image clustering revisited” • Yahoo! Labs • コードブックを用いた、より効率のよいハッシング(IQ)
WEB-SCALE K-MEANS web企業は皆それぞれ、大量の画像をユーザーから投稿されており、 大量の画像データ・特徴を実時間で行う問題を抱えている おそらく現在最大の画像データセットは、Flickrの100Mデータセット。 Alexnet最終層を特徴とすると、100M×4096×32bitで1.6TB
WEB-SCALE K-MEANS web企業は皆それぞれ、大量の画像をユーザーから投稿されており、 大量の画像データ・特徴を実時間で行う問題を抱えている Google->Picasa おそらく現在最大の画像データセットは、Flickrの100Mデータセット。 Alexnet最終層を特徴とすると、100M×4096×32bitで1.6TB
WEB-SCALE K-MEANS web企業は皆それぞれ、大量の画像をユーザーから投稿されており、 大量の画像データ・特徴を実時間で行う問題を抱えている Google->Picasa Facebook->Facebook おそらく現在最大の画像データセットは、Flickrの100Mデータセット。 Alexnet最終層を特徴とすると、100M×4096×32bitで1.6TB
WEB-SCALE K-MEANS web企業は皆それぞれ、大量の画像をユーザーから投稿されており、 大量の画像データ・特徴を実時間で行う問題を抱えている Google->Picasa Facebook->Facebook Yahoo!->Flickr おそらく現在最大の画像データセットは、Flickrの100Mデータセット。 Alexnet最終層を特徴とすると、100M×4096×32bitで1.6TB
WEB-SCALE K-MEANS web企業は皆それぞれ、大量の画像をユーザーから投稿されており、 大量の画像データ・特徴を実時間で行う問題を抱えている Google->Picasa Facebook->Facebook Yahoo!->Flickr Dwango->ニコニコ静画2M おそらく現在最大の画像データセットは、Flickrの100Mデータセット。 Alexnet最終層を特徴とすると、100M×4096×32bitで1.6TB
400k分データセット公開中!
WEB-SCALE K-MEANS web企業は皆それぞれ、大量の画像をユーザーから投稿されており、 大量の画像データ・特徴を実時間で行う問題を抱えている Google->Picasa Facebook->Facebook Yahoo!->Flickr Dwango->ニコニコ静画2M おそらく現在最大の画像データセットは、Flickrの100Mデータセット。 Alexnet最終層を特徴とすると、100M×4096×32bitで1.6TB
https://nico-opendata.jp/ja/demo/similar/ index.html?image_id=4986539 類似画像検索 400k分データセット公開中!
WEB-SCALE K-MEANS web企業は皆それぞれ、大量の画像をユーザーから投稿されており、 大量の画像データ・特徴を実時間で行う問題を抱えている Google->Picasa Facebook->Facebook Yahoo!->Flickr Dwango->ニコニコ静画2M ニコニコ動画13M おそらく現在最大の画像データセットは、Flickrの100Mデータセット。
Alexnet最終層を特徴とすると、100M×4096×32bitで1.6TB https://nico-opendata.jp/ja/demo/similar/ index.html?image_id=4986539 類似画像検索 400k分データセット公開中!
より小さな空間でのK-MEANS 1M~1B枚の巨大な画像データセットを扱いたい。そのためにはメモリ・ 時間を節約したい。1台のマシンのメモリに全部乗るくらいのサイズ(1 枚100Byte以下)で扱いたい。 プロダクト量子化やバイナリハッシングといった、元の距離の空間を保 つように小さな空間にエンコードする研究がある。 ここでの問題は、エンコーディングされた空間の特徴を活かしながらク ラスタリングを達成すること。例えば、元空間にデコードしてから距離を 計算してクラスタリングしてしまっては、せっかくエンコードした意味が 無い。
WEB-SCALE K-MEANS Webの強豪企業たちの戦い。 • 2010, WWW: “Web-Scale K-Means Clustering” •
Google • ターゲットは特に画像ではない • Mini batch法。sklearnにも実装されてるのでお世話になっている • 2015, CVPR: “Web Scale Photo Hash Clustering on A Single Machine” • Facebook AIラボ • バイナリ特徴を使う • 2015, ICCV: “Web-scale image clustering revisited” • Yahoo! Labs • コードブックを用いた、より効率のよいハッシング(IQ)
BK-MEANS バイナリ特徴のK-means。入力データをバイナリにエンコードして、セント ロイドもバイナリとして得る 1. エンコードは Iterative Quantization • “Iterative quantization:
A Procrustean approach to learning binary codes for large-scale image retrieval.” • 実数からハッシュに落とす時に、回転行列Rをかけてからハッ シュにする。1) ハッシュ割り当て、2)回転の最適化、を交互に繰 り返すのでiterative 2. UpdateStep • 割り当てられたベクトルを全部足して、各次元ごとに正になるか 負になるかで更新できる 3. Assignment Step • “Fast search in hamming space with multi-index hashing” • N次元ハッシュで距離N以下だったら必ず1次元は衝突する、とい う原理に基づき高速探索
PQ空間
SUBSPACE QUANTIZATION 詳しくは、第27回勉強会での @ketsumedo_yarou の資料を参照 http://www.slideshare.net/ketsumedo_yarou/presentation-for-web-44080684?related=1 0.34 0.22 0.68 1.02
0.03 0.71 入力特徴群 2つの部分空間毎にk-means (一部データでも十分な精度) 割り当てられたセントロイドで 2次元にエンコード(全データ) … 4096次元とか
SUBSPACE QUANTIZATION 詳しくは、第27回勉強会での @ketsumedo_yarou の資料を参照 http://www.slideshare.net/ketsumedo_yarou/presentation-for-web-44080684?related=1 0.34 0.22 0.68 1.02
0.03 0.71 入力特徴群 … 2つの部分空間毎にk-means (一部データでも十分な精度) 割り当てられたセントロイドで 2次元にエンコード(全データ) ID:2 0.32 0.27 0.73 ID:501 1.08 0.01 0.78 … … … … … … この結果はコードブックとして、距離の 計算などに使い回す Kはこの論文では128~1024 4096次元とか
SUBSPACE QUANTIZATION 詳しくは、第27回勉強会での @ketsumedo_yarou の資料を参照 http://www.slideshare.net/ketsumedo_yarou/presentation-for-web-44080684?related=1 0.34 0.22 0.68 1.02
0.03 0.71 入力特徴群 … 2つの部分空間毎にk-means (一部データでも十分な精度) 割り当てられたセントロイドで 2次元にエンコード(全データ) ID:2 0.32 0.27 0.73 ID:501 1.08 0.01 0.78 … … … … … … 2 501 … この結果はコードブックとして、距離の 計算などに使い回す Kはこの論文では128~1024 4096次元とか
問題の整理 1. 全てのデータは2次元(ただし離散) ベクトルになっている。セルの番地 で表現できる 2. ただし、2次元空間での距離は元空 間での距離を表さない。 3. それぞれのセルに対応する元空間
でのベクトルをコードブックに保存し てあるので、それを用いてセル同士 の距離は計算できる 4. 必須項目ではないが、この手法では、 データは2次元セル番地だが、セン トロイドは元空間で求める。 この条件から、高速・省メモリでk-meansを行う
手法
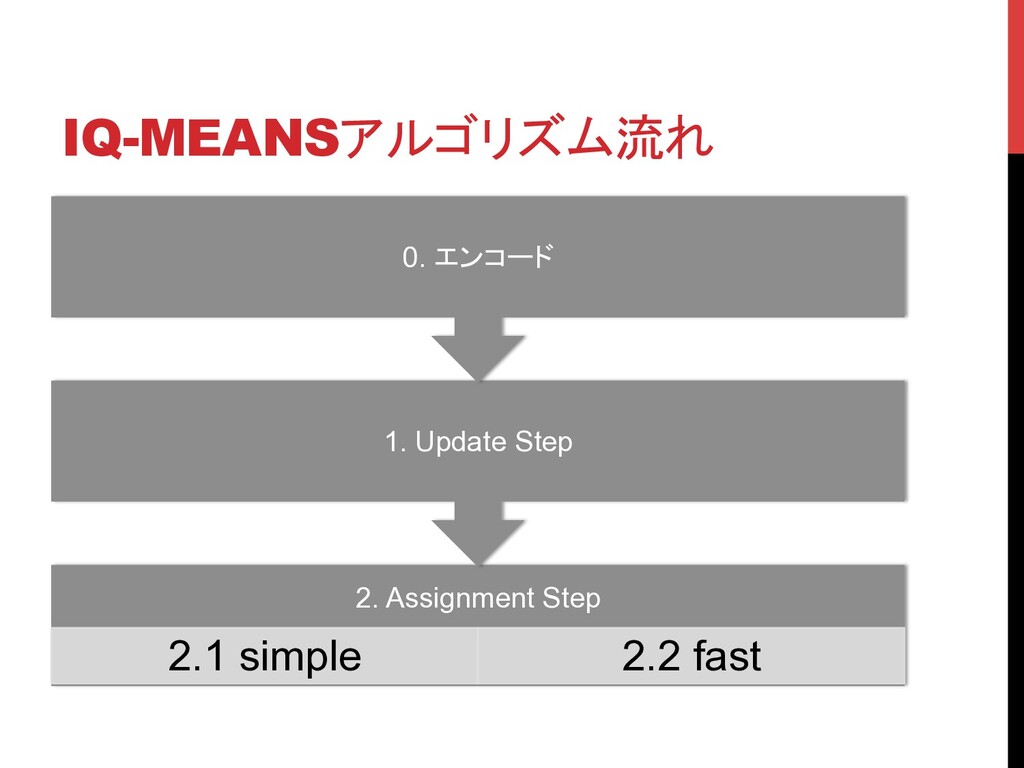
IQ-MEANSアルゴリズム流れ 2. Assignment Step 2.1 simple 2.2 fast 1. Update
Step 0. エンコード
エンコード “Optimized Product Quantization for Approximate Nearest Neighbor Search”(by MSR)
に従う。先の図のように前半次元と後 半次元でやってもいいんだけど、簡単に最適化する方法が有るので。 • PQかける前の生ベクトルに回転行列RをかけてからPQすることで、 より量子化歪みを小さくする • 1. 回転を固定して、量子化歪みを最小化するようにPQのエン コーダを求める。(普通にk-means) • 2. PQのエンコーダを固定して、量子化歪みを最小化するよう に回転を求める。(直交プロクラステス回転を求める問題であり、 閉形式解が求まる) • 1と2を収束するまで繰り返す
UPDATE STEP セントロイドCmに割り当てられるセルについて、そのセルの平均ベクト ルの重み付き和が割り当てられる pα: いくつのサンプルがそのセルに 割り当てられているか µα: そのセルの(生空間での)平均ベクトル。コードブックから取り出す
ASSIGMENT STEP (1) SIMPLE すべてのセルuについて、元空間でセントロイドとの距離を計測して、 最小のものをとる 1024x1024個のセルについて4096次元の距離計算をk回やる。まだ 計算時間がツライ
ASSIGNMENT STEP (2) FAST せっかくセルの2次元空間に落としてるんだから、全部のセント ロイドと全部のセルを比較する必要はないよね。。 すべてのセントロイドについて以下の操作をする 1. サブ空間U1, U2それぞれの中で距離が近いw個(論文で
は16)のインデックスを取り出す 2. 近い順に並べた新しい2次元 (例b) を作る 3. 最も近いセル(新しい2次元での(0,0))から初めて、距離 が近い順に周囲のセルを探索していく。 1. そのセルの、今までのセントロイドとの最小距離よ りも小さければ更新 4. 終了条件に達したら次のセントロイドへ 1. 終了条件は、それまでに訪問したセルに含まれて いた累計サンプル数が閾値T(論文中ではT=全サ ンプル/k)を超えたら。 2. あるいは、w×wを全部訪問したら
コントリビューション 1. 2次元にPQした空間で効率的に探索する方法を提案 2. Centroid同士の距離を効率的に探索することで、kの推定を効率 的にやる方法を提案
コントリビューション 1. 2次元にPQした空間で効率的に探索する方法を提案 2. Centroid同士の距離を効率的に探索することで、kの推定を効率 的にやる方法を提案 おまけの、ちょっと嬉しい話
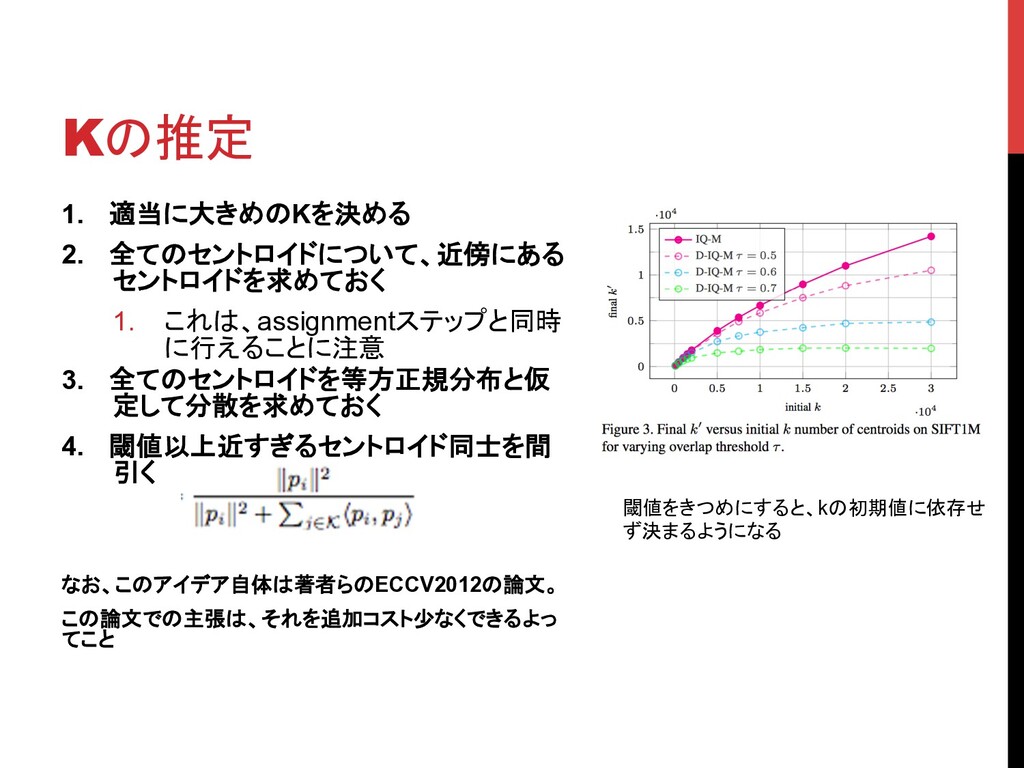
Kの推定 1. 適当に大きめのKを決める 2. 全てのセントロイドについて、近傍にある セントロイドを求めておく 1. これは、assignmentステップと同時 に行えることに注意 3.
全てのセントロイドを等方正規分布と仮 定して分散を求めておく 4. 閾値以上近すぎるセントロイド同士を間 引く なお、このアイデア自体は著者らのECCV2012の論文。 この論文での主張は、それを追加コスト少なくできるよっ てこと 閾値をきつめにすると、kの初期値に依存せ ず決まるようになる
手法
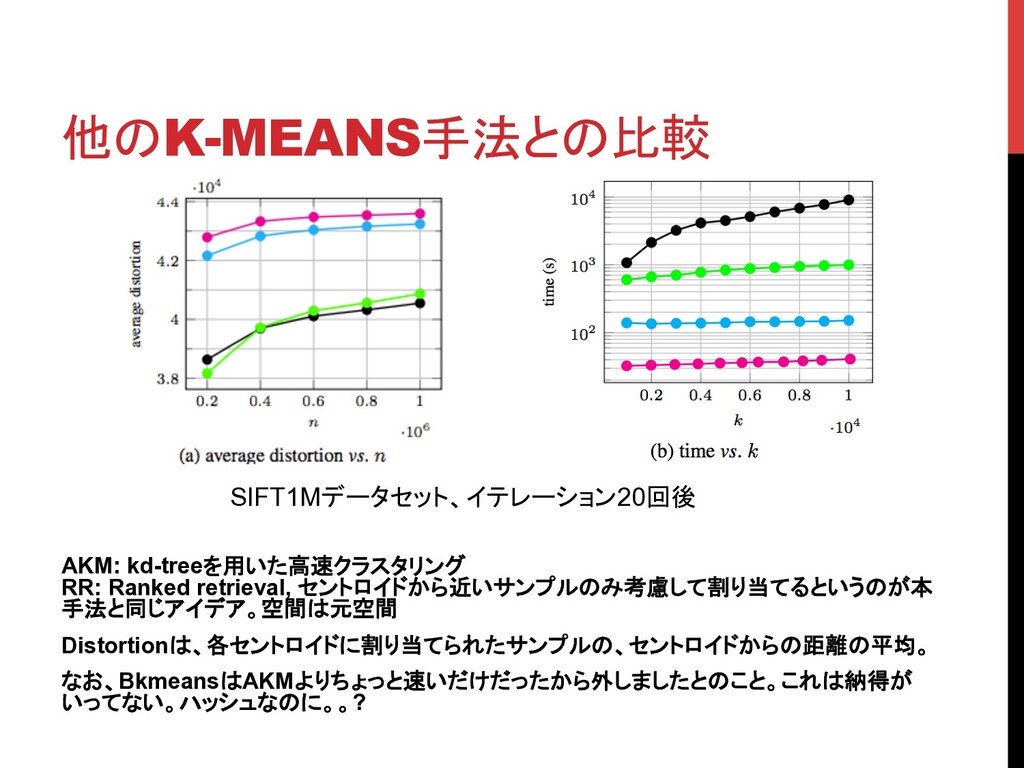
他のK-MEANS手法との比較 AKM: kd-treeを用いた高速クラスタリング RR: Ranked retrieval, セントロイドから近いサンプルのみ考慮して割り当てるというのが本 手法と同じアイデア。空間は元空間 Distortionは、各セントロイドに割り当てられたサンプルの、セントロイドからの距離の平均。 なお、BkmeansはAKMよりちょっと速いだけだったから外しましたとのこと。これは納得が
いってない。ハッシュなのに。。? SIFT1Mデータセット、イテレーション20回後
巨大データセットでの実験 Yahoo flicker 100M dataset • Flickrに投稿された100M枚のデータセット • ここから、Alexnetの最終層を特徴として抽出して(4096次元)、PCAで 128次元にしたもの
• DKM: Apache Spark をもちいた、分散k-means。スケールアウト手 法との比較。 CKM: 2次元のセル座標そのものをk-meansした場合。ただのベース ライン。そんなに比較する意味は無い precisionは、教師ラベルありデータをクラスタリングした、クラスタ内 のラベルの純度(最も多いラベルの割合) • 分散手法よりも全然早い。
WEB企業的に、実用上は たしかに、k-meansを正確にやらなきゃいけないというシーンはあまりな い。速度・メモリ・マシン台数を減らすほうが、実用上は大事。 • 安直に金をつぎ込んでsparkで解決するべき問題じゃないという考察 は素晴らしい。 • 実用上のクラスタリングの精度、というのは難しい。ユーザーさんが納 得できる結果であればいいってことが多い。 •
クラスタリング自体が主問題なら、コードも公開されているし、IQ- meansを利用する価値はある。 • https://github.com/iavr/iqm • ただ、PQに特有の、コードブックを利用しなきゃ距離計算が出来ない デメリットは有るので、元空間の距離を保った次元圧縮を使ったほうが 取り回しやすいシーンは多いか。 • あと、ハイパーパラメータが多いところに不安がある。閾値設定とかミ スると論文通りの性能は出ないかと • たぶんこの論文でBk-meansが遅かったのもそういう事情なんじゃ ないかな
WE’RE HIRING
WE’RE HIRING
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}