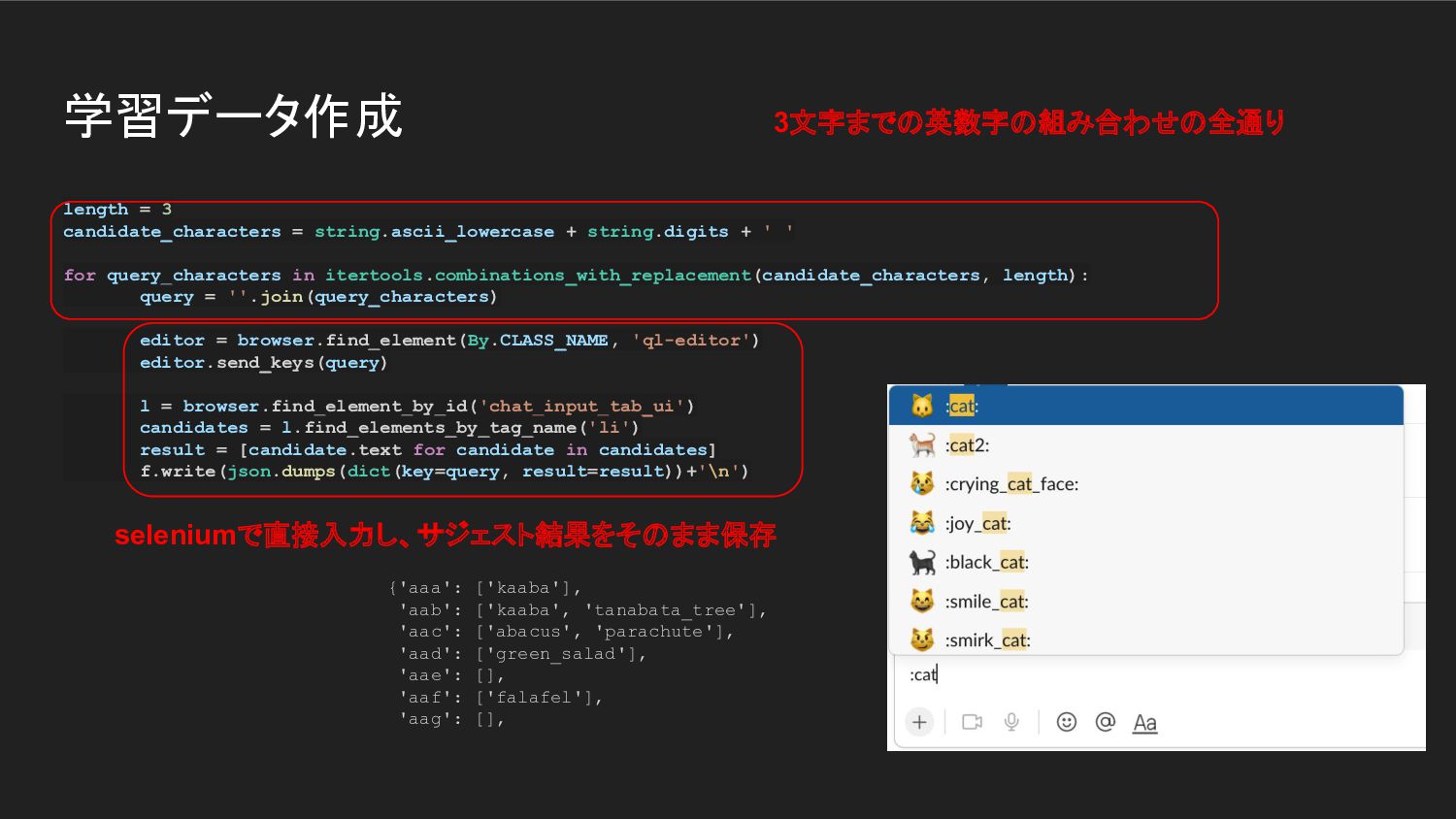
99999 else: return target.find(query[0]) 文字列がサブセットになっているか 59.65 マッチ部の最小長さ+出現位置 def distance2(query, target): if not set(query).issubset(target): return 9999999999 else: pattern = '.*?'.join(query) matches = re.findall(pattern, target) if not matches: return 999999999 else: return min(len(found) for found in matches)*100+target.find(query[0]) 17.29 def distance4(query, target): if not set(query).issubset(target): return 9999999999 else: pattern = '.*?'.join(query) matches = re.findall(pattern, target) if not matches: return 999999999 else: return min(len(found) for found in matches)*1000+len(target)*10+target.find( matches[0]) マッチ部の最小長さ+文字列長+出現 位置 14.94
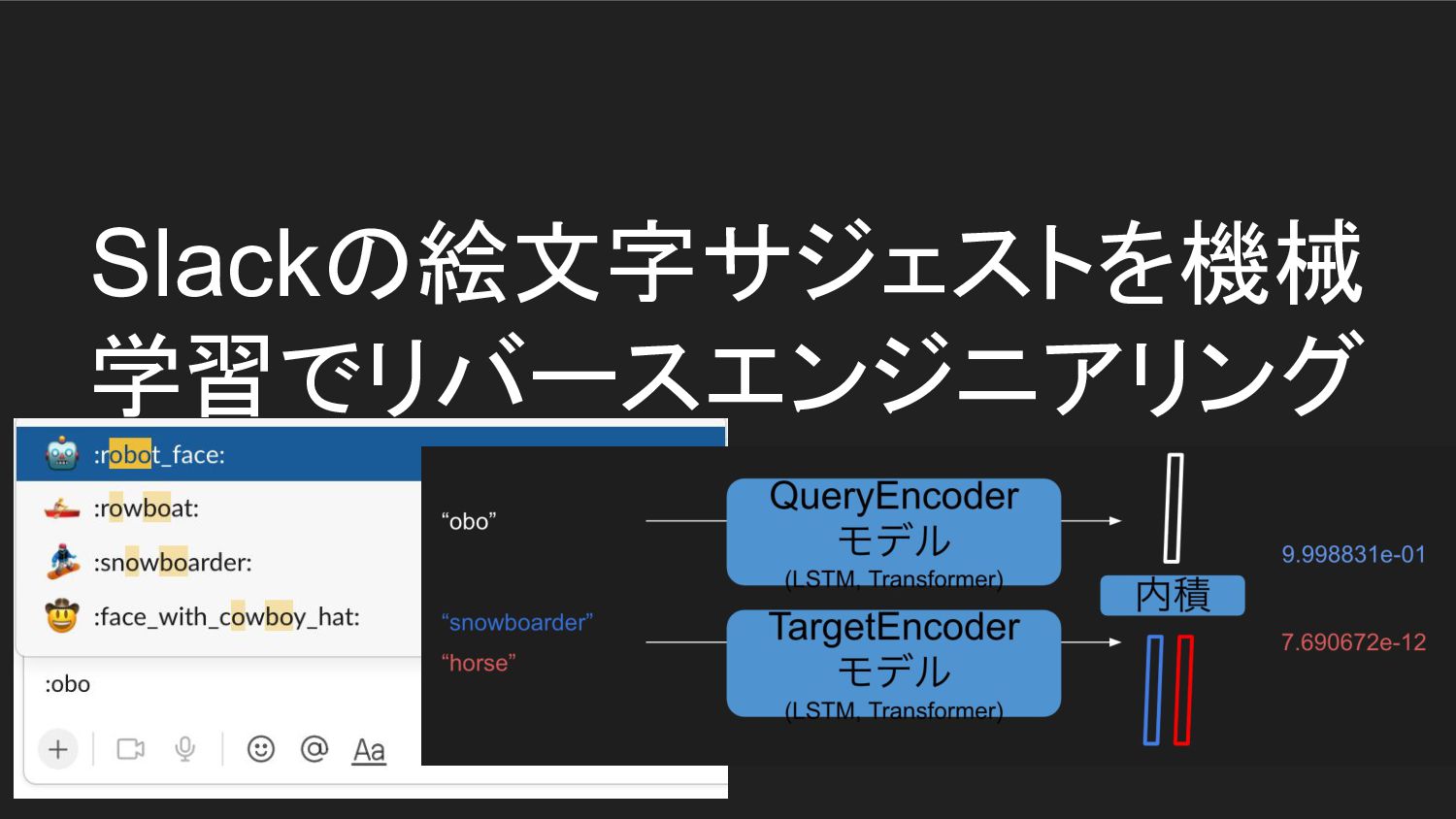
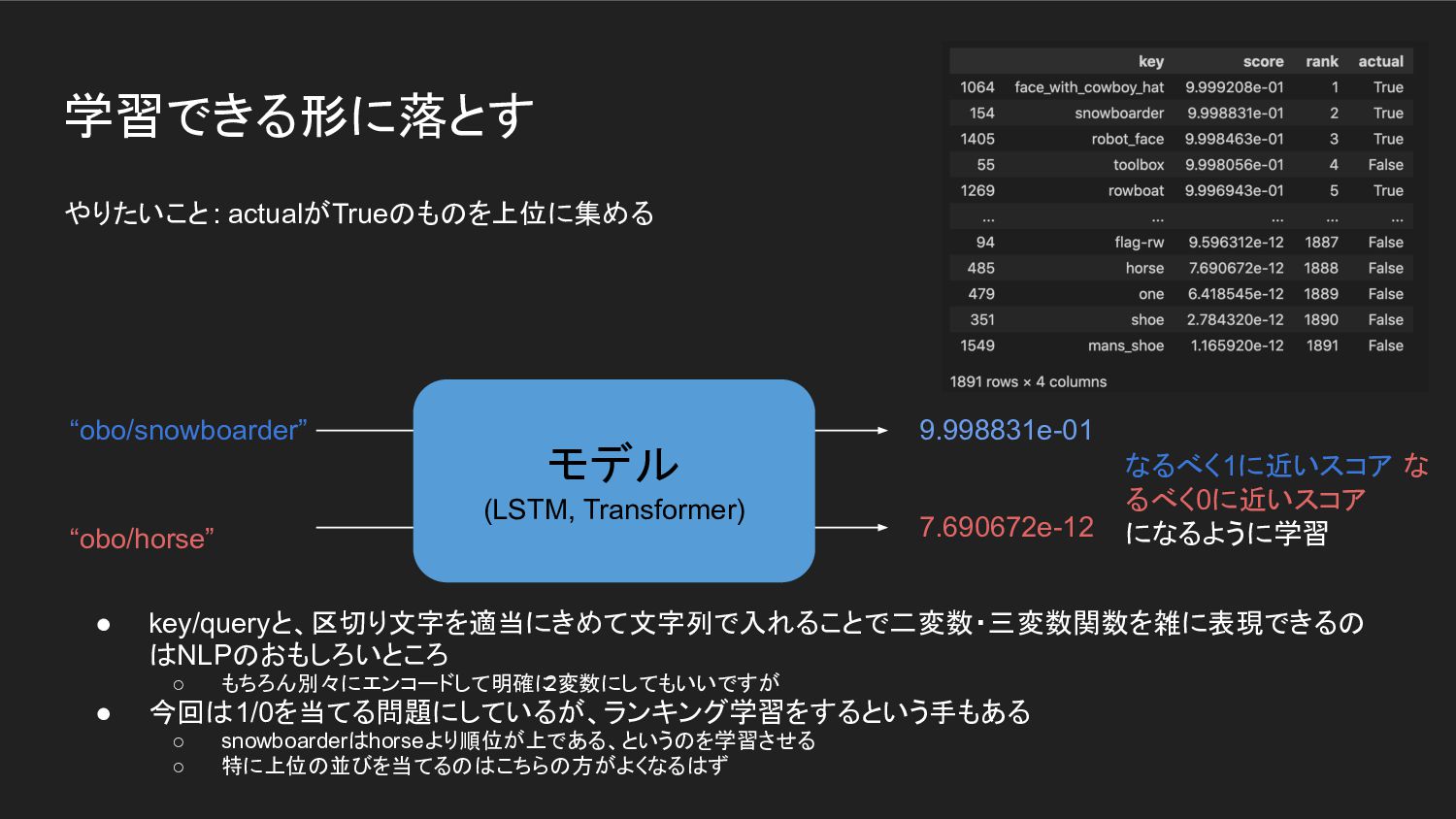
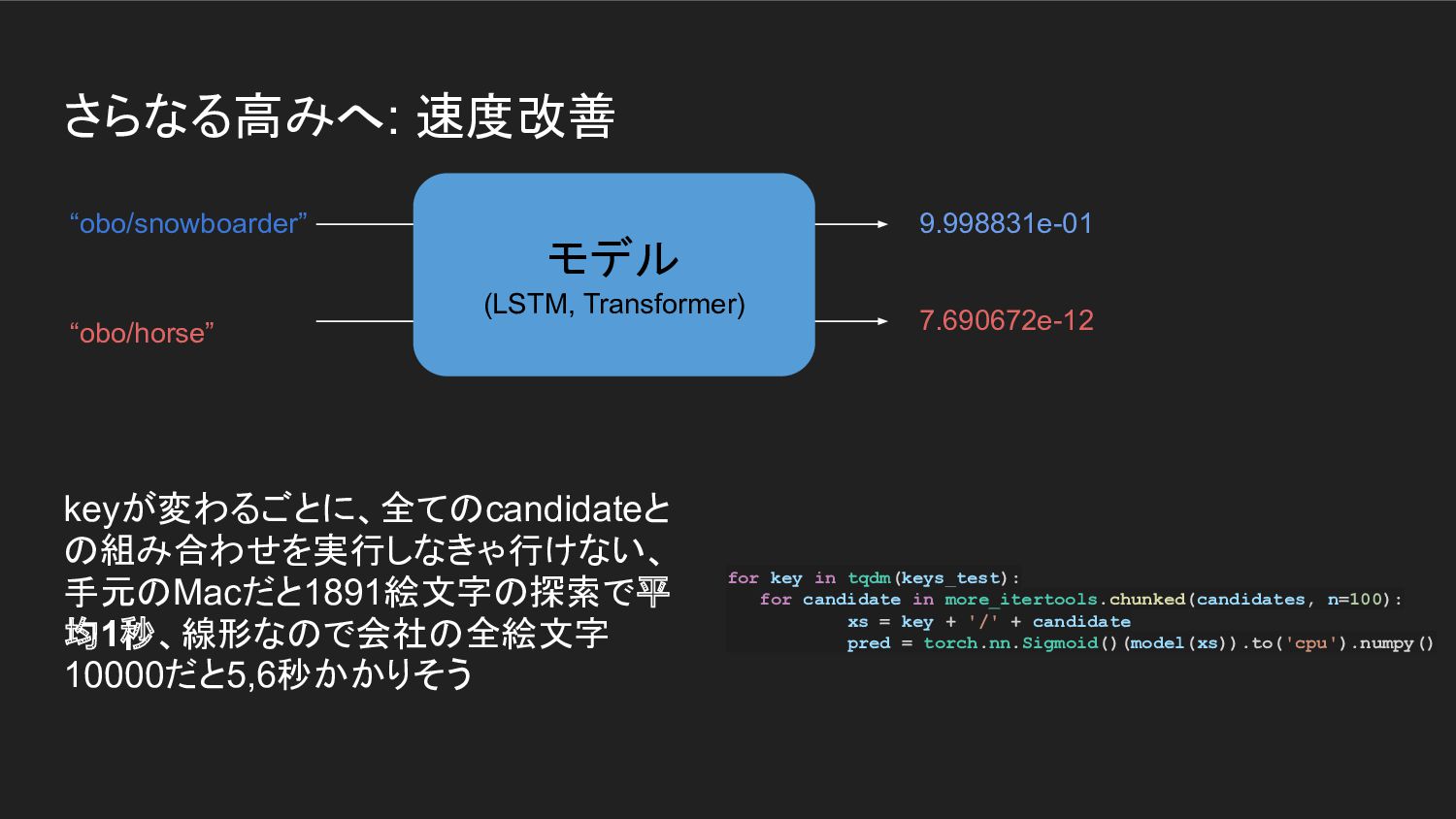
7.690672e-12 モデル (LSTM, Transformer) for key in tqdm(keys_test): for candidate in more_itertools.chunked(candidates, n=100): xs = key + '/' + candidate pred = torch.nn.Sigmoid()(model(xs)).to('cpu').numpy()
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![アルゴリズムの一致度の評価はどうやる? query -> answerが1:1ではないので、precision@k, recall@kではなく、平均順位を評価指標とする {'aaa': ['kaaba'], 'aab': ['kaaba', 'tanabata_tree'],](https://files.speakerdeck.com/presentations/4e87bbc2bb284649846c728d5328e4b3/slide_6.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
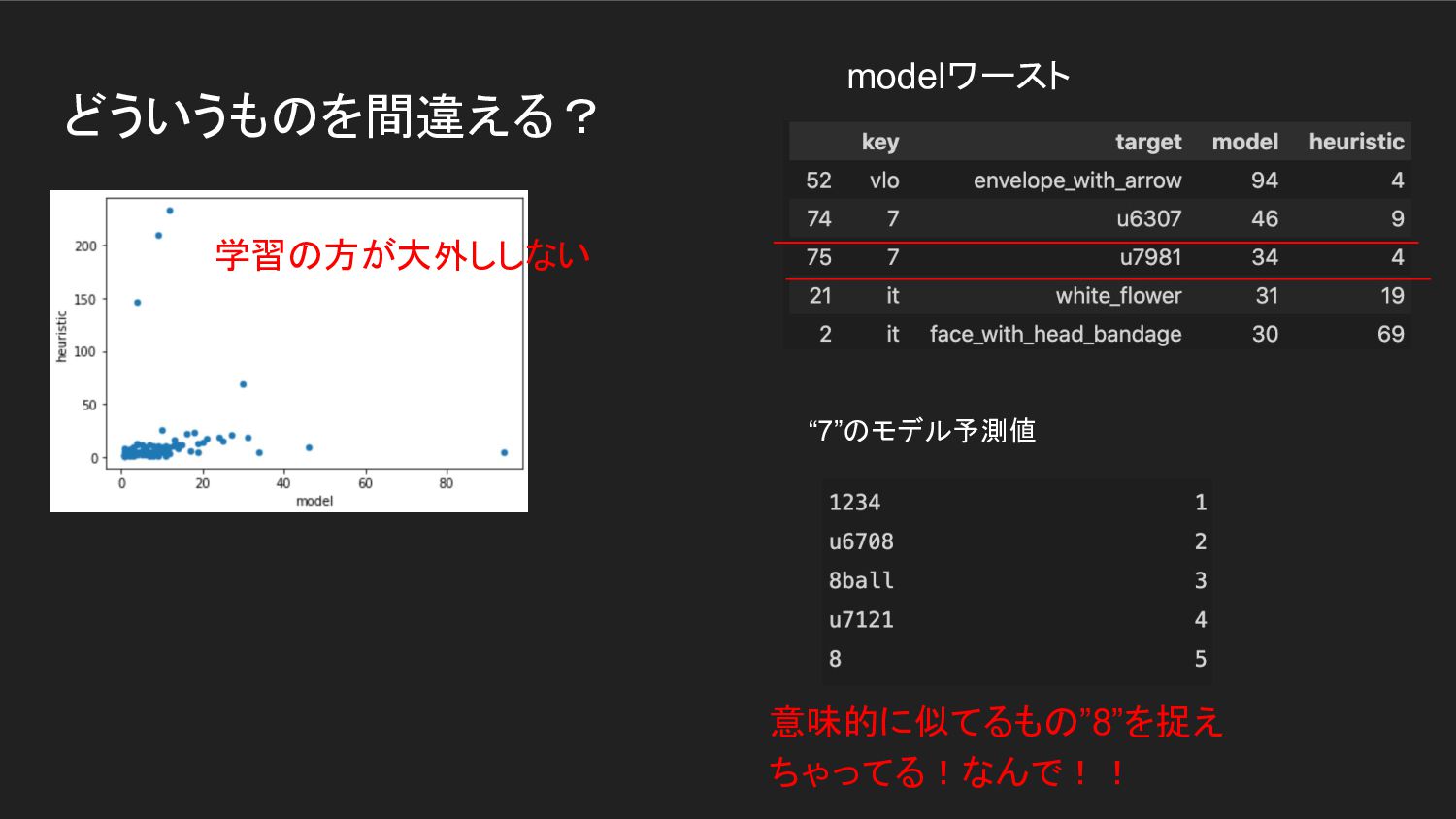
![結果: SoTA達成、勝利 [ヒューリスティック] マッチ部の最小長さ+文字列長+出現位置 14.94 (+7.24) [学習] LSTM, 2layer, 100D](https://files.speakerdeck.com/presentations/4e87bbc2bb284649846c728d5328e4b3/slide_10.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![結果 平均順位 時間 [ヒューリスティック] マッチ部の最小長さ+文字列長+ 出現位置 14.94 (+7.24) 0.008s [学習]](https://files.speakerdeck.com/presentations/4e87bbc2bb284649846c728d5328e4b3/slide_15.jpg){kind=link}
{kind=link}
{kind=link}