Upgrade to Pro
— share decks privately, control downloads, hide ads and more …
Speaker Deck
Features
Speaker Deck
PRO
Sign in
Sign up for free
Search
Search
Amazon SageMaker Clarifyで始めるモデルモニタリング
Search
クルトン
July 20, 2023
Programming
0
1k
Amazon SageMaker Clarifyで始めるモデルモニタリング
モデルを作りっぱなしにしていませんか?
モデルは学習させて推論させる以外にも見ておくべき情報があります。
今回はSageMakerで使えるClarifyを使った方法をご紹介します。
クルトン
July 20, 2023
Tweet
Share
More Decks by クルトン
See All by クルトン
Amazon SageMakerでImagenを動かして猫画像生成してみた
hotoke_neko
0
950
Other Decks in Programming
See All in Programming
マイコンでもRustのtestがしたい その2/KernelVM Tokyo 18
tnishinaga
2
2.3k
Scale out your Claude Code ~自社専用Agentで10xする開発プロセス~
yukukotani
9
2.6k
管你要 trace 什麼、bpftrace 用下去就對了 — COSCUP 2025
shunghsiyu
0
460
Infer入門
riru
4
1.6k
物語を動かす行動"量" #エンジニアニメ
konifar
14
5.4k
STUNMESH-go: Wireguard NAT穿隧工具的源起與介紹
tjjh89017
0
380
デザインシステムが必須の時代に
yosuke_furukawa
PRO
2
100
実践 Dev Containers × Claude Code
touyu
1
240
SOCI Index Manifest v2が出たので調べてみた / Introduction to SOCI Index Manifest v2
tkikuc
1
110
レガシープロジェクトで最大限AIの恩恵を受けられるようClaude Codeを利用する
tk1351
2
980
実践!App Intents対応
yuukiw00w
1
350
Jakarta EE Core Profile and Helidon - Speed, Simplicity, and AI Integration
ivargrimstad
0
180
Featured
See All Featured
The Art of Delivering Value - GDevCon NA Keynote
reverentgeek
15
1.6k
Java REST API Framework Comparison - PWX 2021
mraible
33
8.8k
Large-scale JavaScript Application Architecture
addyosmani
512
110k
How STYLIGHT went responsive
nonsquared
100
5.7k
Into the Great Unknown - MozCon
thekraken
40
2k
Principles of Awesome APIs and How to Build Them.
keavy
126
17k
Stop Working from a Prison Cell
hatefulcrawdad
271
21k
Building a Modern Day E-commerce SEO Strategy
aleyda
43
7.5k
How GitHub (no longer) Works
holman
315
140k
Done Done
chrislema
185
16k
Designing for humans not robots
tammielis
253
25k
Rails Girls Zürich Keynote
gr2m
95
14k
Transcript
2023/07/19 データアナリティクス事業本部 クルトン Amazon SageMaker Clarifyで 始めるモデルモニタリング
• 名前:クルトン • 所属:インテグレーション部 MLチーム • 経歴:2022年新卒入社 ◦ 入社前はクラウドほとんど未経験 自己紹介
ご意見・ご感想は #devio2023 を入れてツイートしてください!
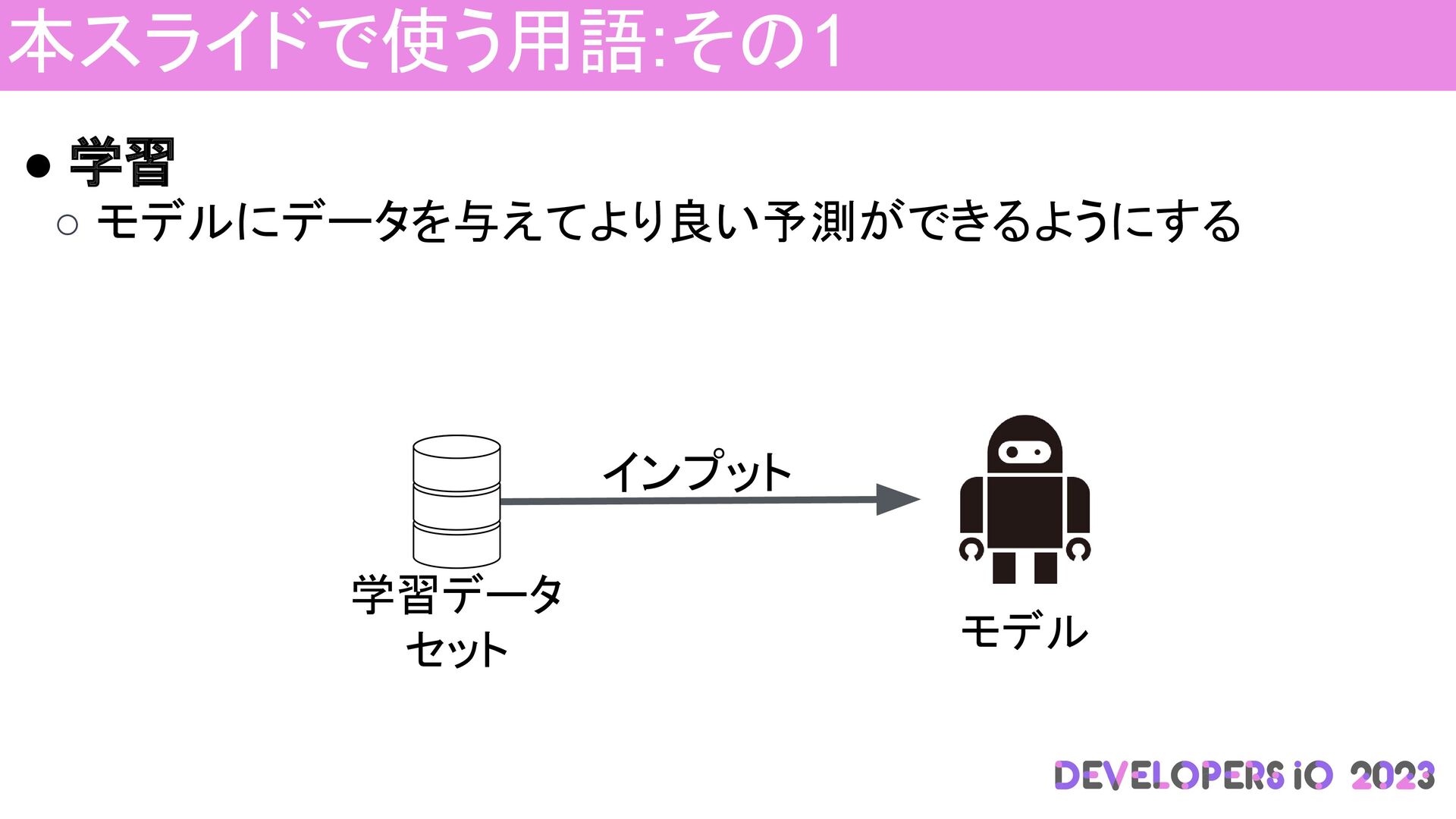
本スライドで使う用語:その1 • 学習 ◦ モデルにデータを与えてより良い予測ができるようにする 学習データ セット インプット モデル
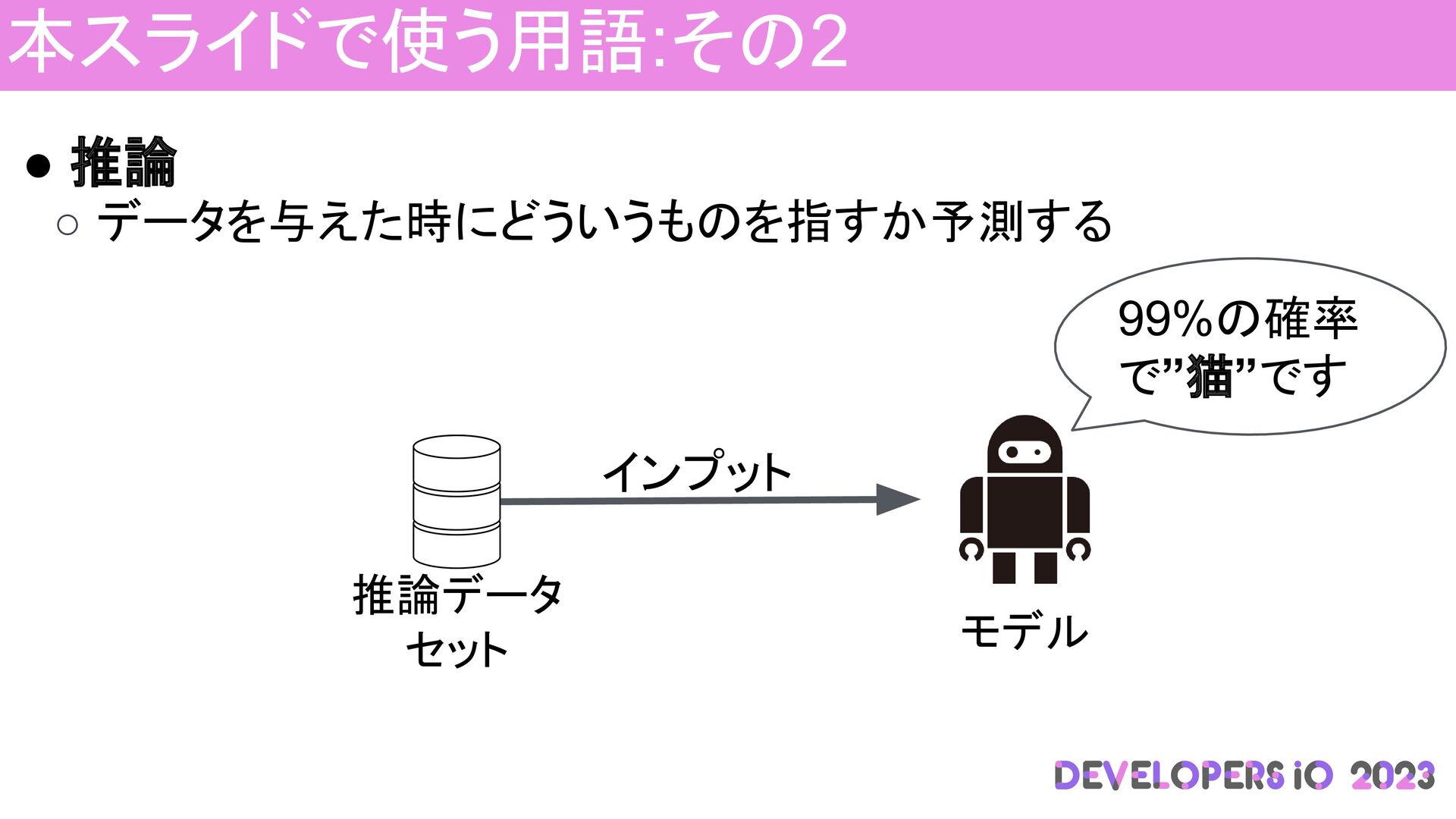
本スライドで使う用語:その2 • 推論 ◦ データを与えた時にどういうものを指すか予測する 99%の確率 で”猫”です 推論データ セット インプット
モデル
本スライドで使う用語:その3 • 特徴量 ◦ データの名前 例えば猫なら…… 種類 体重[kg] 年齢[年] メインクーン
5 1 ラグドール 4.5 1 ベンガル 5 7
セッション概要 モデルを作りっぱなしにしていませんか? モデルは学習させて推論させる以外にも見ておくべき情報 があります。 今回はSageMakerで使えるClarifyを使った方法をご紹介 します。
推論以外の情報 推論以外の見ておくべき情報とは?
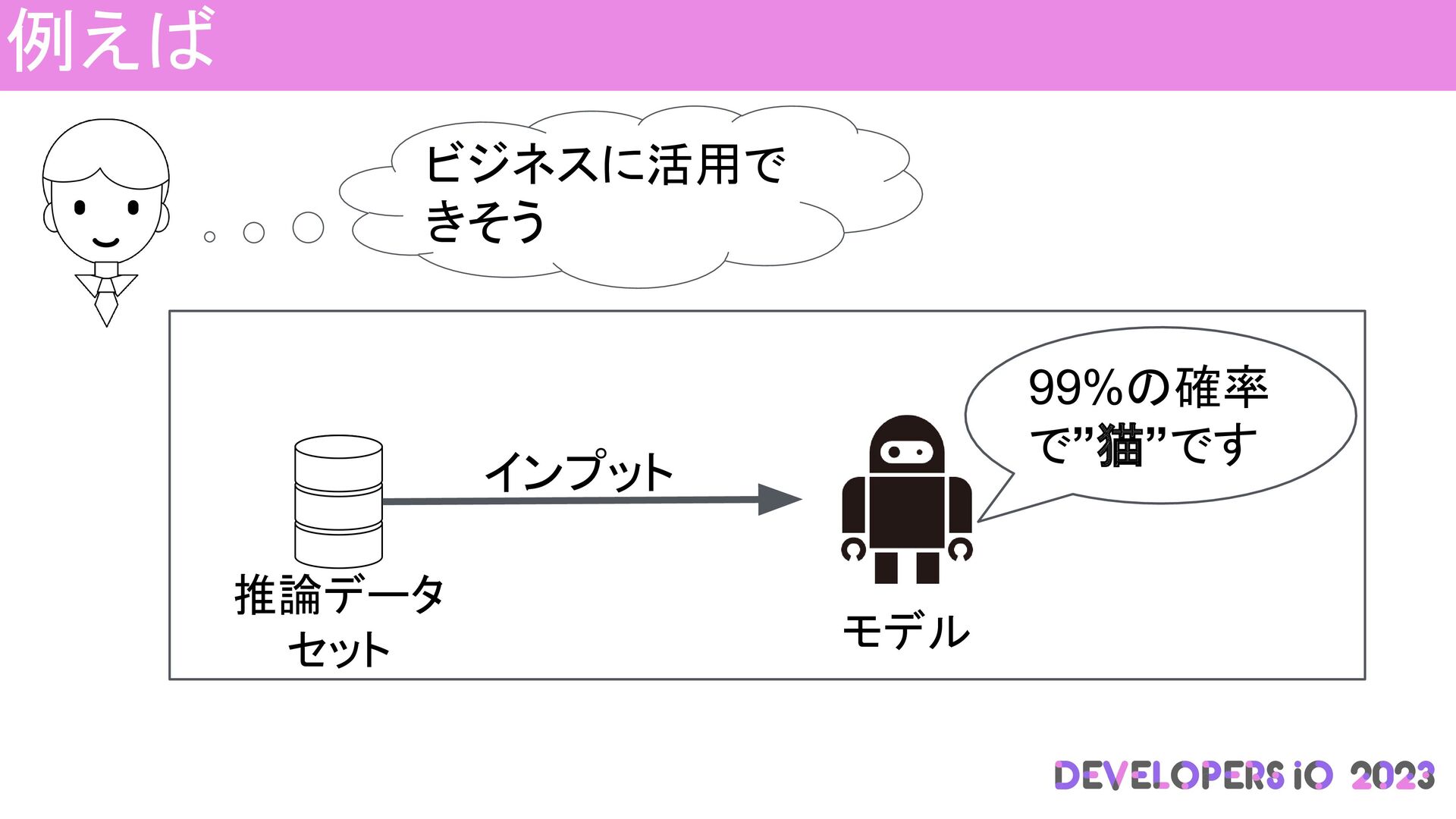
例えば ビジネスに活用で きそう 推論データ セット インプット 99%の確率 で”猫”です モデル
他者の反応 で、なんでそう予測し たの? 上司Aさん
推論できるだけで良いの? 誰かに説明するには根拠が必要!
モデルが推論をした理由
モデルモニタリング • モデルが適切であること ◦ 学習結果が適切であること ◦ 運用中のモデルが適切であること ◦ モデルの予測が適切であること •
データが適切であること ◦ 異常なデータが入っていないこと(ドリフト検出)
モデルモニタリング • モデルが適切であること ◦ 学習結果が適切であること ◦ 運用中のモデルが適切であること ◦ モデルの予測が適切であること •
データが適切であること ◦ 異常なデータが入っていないこと(ドリフト検出) 今回の説明はここ
• SageMakerについて • SageMakerでの一連の処理の流れ ◦ モデル学習のコード • SageMaker Clarifyで出力するレポートについて ◦
レポート出力をさせるコード • Clarifyで出力したレポートの見方 お品書き
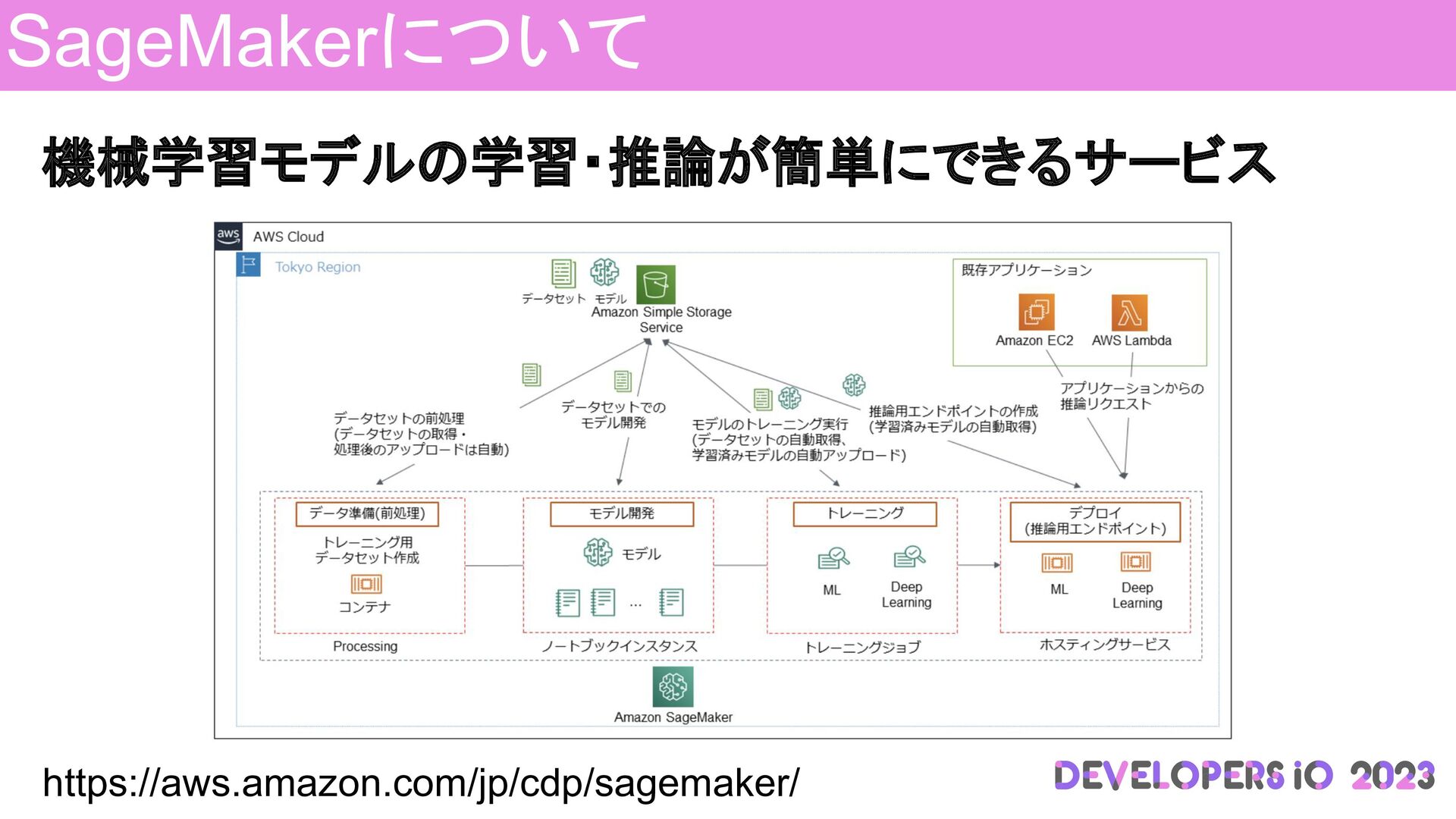
機械学習モデルの学習・推論が簡単にできるサービス SageMakerについて https://aws.amazon.com/jp/cdp/sagemaker/
3つの開発環境 • SageMaker notebook instance • SageMaker Studio •
SageMaker Studio Lab SageMakerの開発環境 Jupyterノートブックインスタンスが立ち上がり開発 ができる
1. データを用意 2. S3バケットへ用意したデータをアップロード 3. モデルを用意 4. S3にあるデータを使って学習 5.
モデルを推論エンドポイントへデプロイ 6. 推論エンドポイントを使って予測 SageMakerの特徴 学習データ準備 モデル学習 推論 プロビジョニングや環境構築を 自分でしなくて良い!
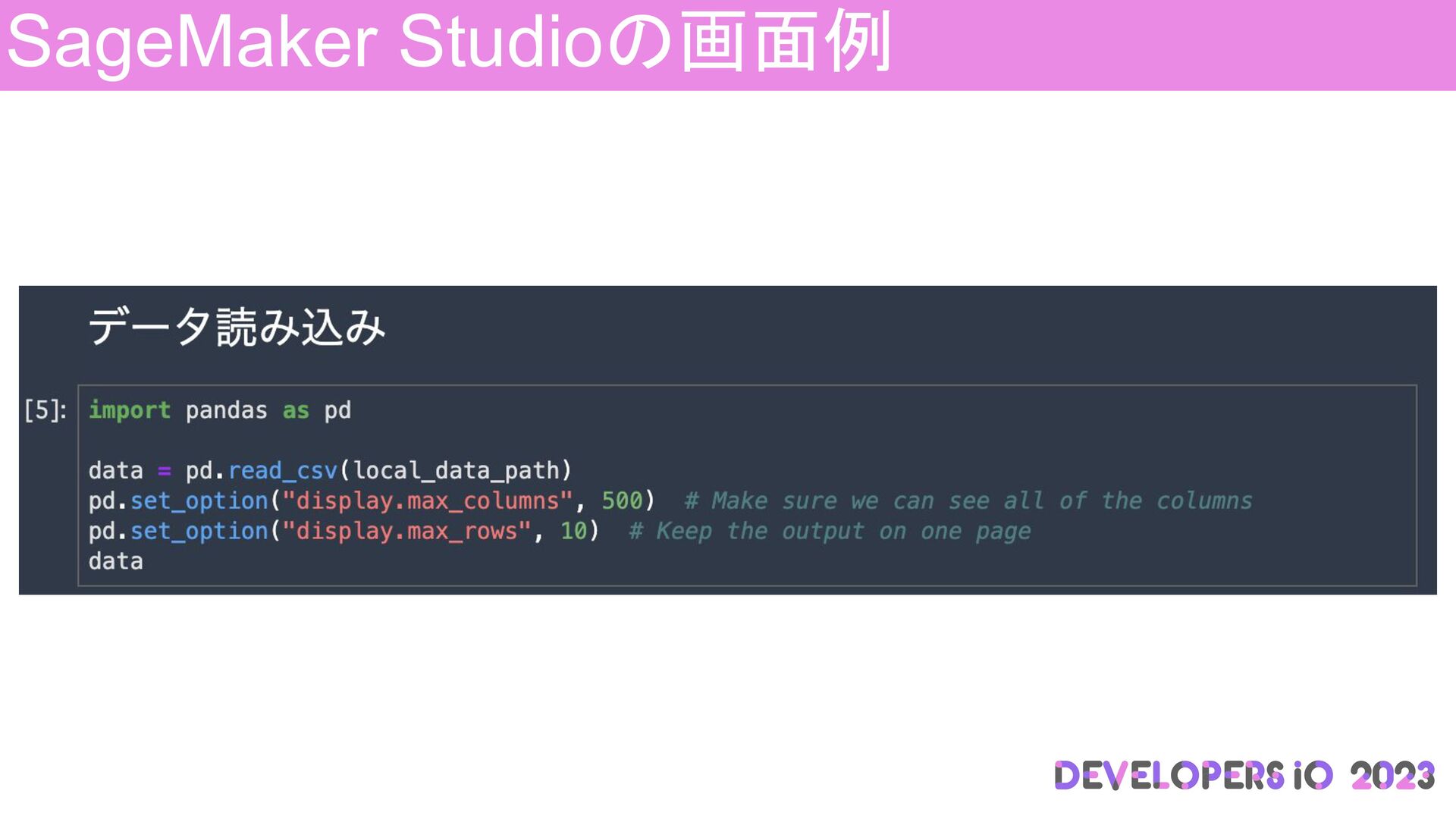
SageMaker Studioの画面例
1. データを用意 2. S3バケットへ用意したデータをアップロード 3. モデルを用意 4. S3にあるデータを使って学習 5.
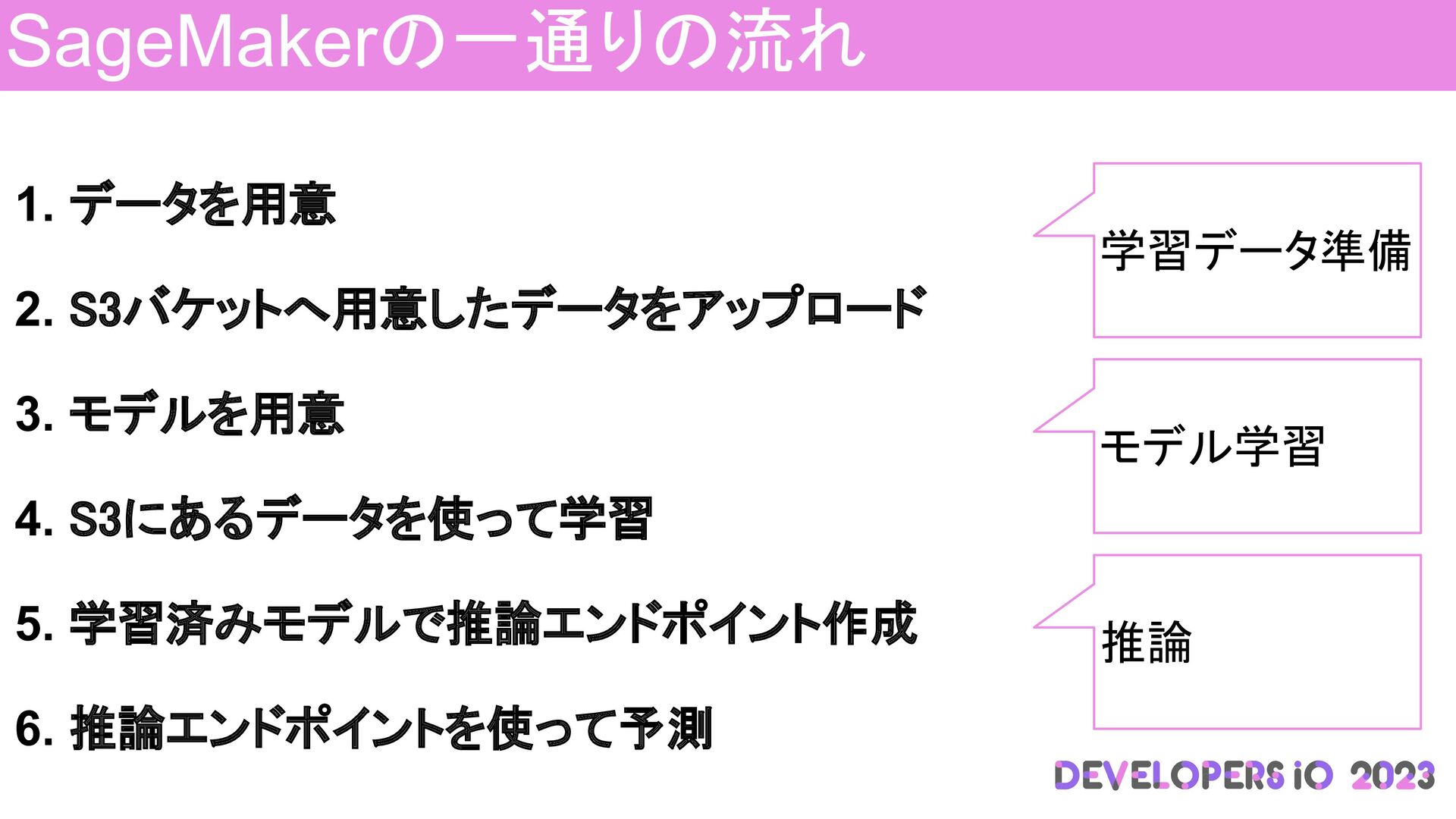
学習済みモデルで推論エンドポイント作成 6. 推論エンドポイントを使って予測 SageMakerの一通りの処理の流れ
1. データを用意 2. S3バケットへ用意したデータをアップロード 3. モデルを用意 4. S3にあるデータを使って学習 5.
学習済みモデルで推論エンドポイント作成 6. 推論エンドポイントを使って予測 SageMakerの一通りの流れ 学習データ準備
1. データを用意 2. S3バケットへ用意したデータをアップロード 3. モデルを用意 4. S3にあるデータを使って学習 5.
学習済みモデルで推論エンドポイント作成 6. 推論エンドポイントを使って予測 SageMakerの一通りの流れ 学習データ準備 モデル学習 推論
1. データを用意 2. S3バケットへ用意したデータをアップロード 3. モデルを用意 4. S3にあるデータを使って学習 5.
学習済みモデルで推論エンドポイント作成 6. 推論エンドポイントを使って予測 SageMakerの一通りの流れ 学習データ準備 モデル学習 推論
1. データを用意 2. S3バケットへ用意したデータをアップロード 3. モデルを用意 4. S3にあるデータを使って学習 5.
学習済みモデルで推論エンドポイント作成 6. 推論エンドポイントを使って予測 SageMakerの一通りの流れ 学習データ準備 モデル学習 推論
SageMakerの一通りの流れ Amazon SageMaker Amazon S3 (学習データ) Amazon S3 (推論データ) 推論エンドポイント
学習データ セット アップロード 学習 作成 アップロード 推論結果 推論
1. データを用意 2. S3バケットへ用意したデータをアップロード 3. モデルを用意 4. S3にあるデータを使って学習 5.
モデルを推論エンドポイントへデプロイ 6. 推論エンドポイントを使って予測 SageMakerの特徴2 学習データ準備 モデル学習 推論 開発に集中できるサービス
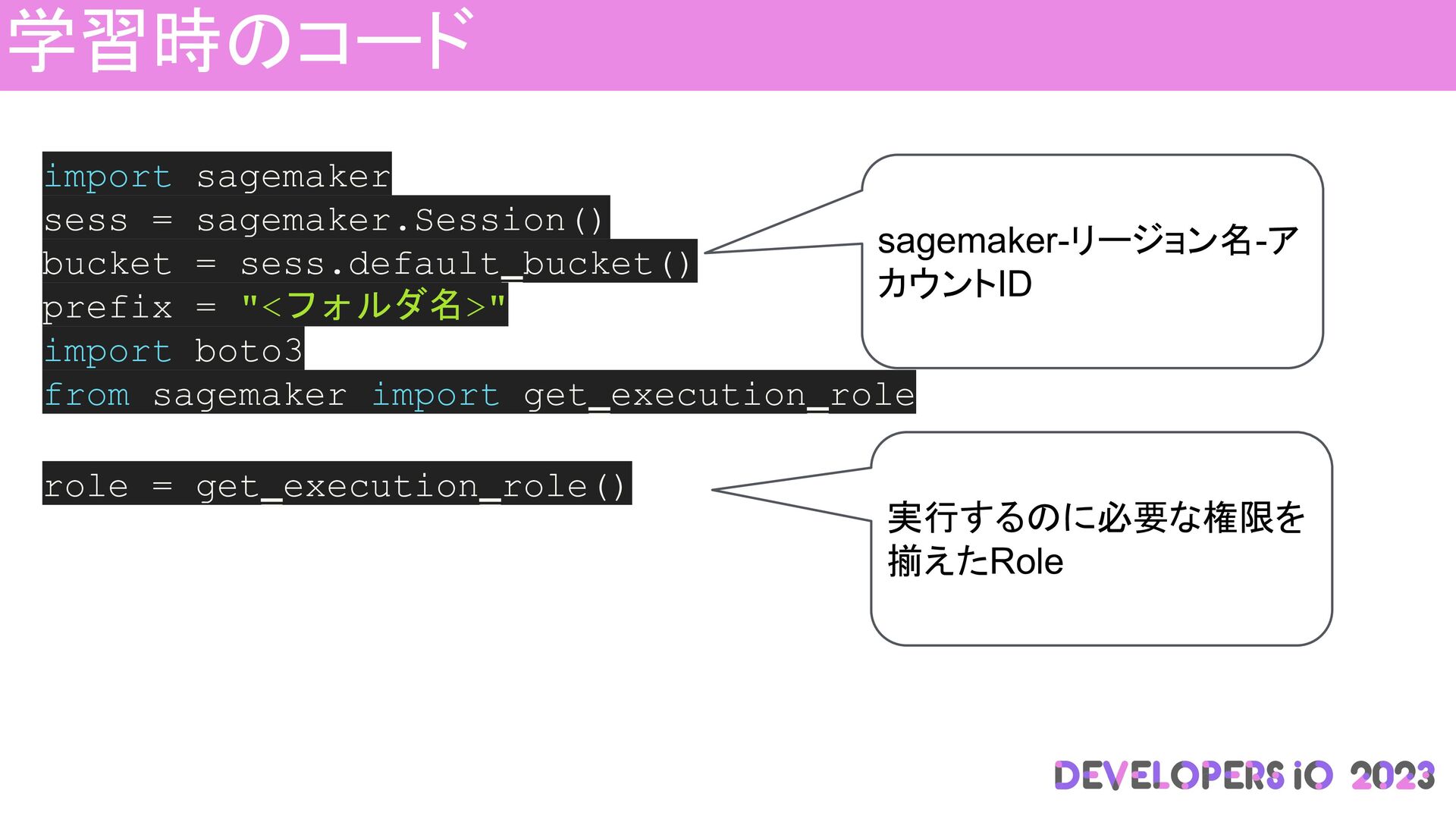
学習時のコード import sagemaker sess = sagemaker.Session() bucket = sess.default_bucket() prefix
= "<フォルダ名>" import boto3 from sagemaker import get_execution_role role = get_execution_role() sagemaker-リージョン名-ア カウントID 実行するのに必要な権限を 揃えたRole
モデル用意: コンテナの準備2選 • 公式が用意しているコンテナの読み込み • ECRに登録したカスタムコンテナのURIをstr型で書く container = sagemaker.image_uris.retrieve("xgboost",sess.boto_region_nam e,
"1.5-1") container = '<ご自身のアカウントID>.dkr.ecr.<リージョン名>.amazonaws.com/<コン テナ名>:latest'
モデル学習 xgb = sagemaker.estimator.Estimator( container, role, instance_count=1, instance_type="ml.m4.xlarge", output_path="s3://{}/{}/output".format(bucket, prefix),
sagemaker_session=sess, ) xgb.fit("<学習用データセットがあるS3 URI>")
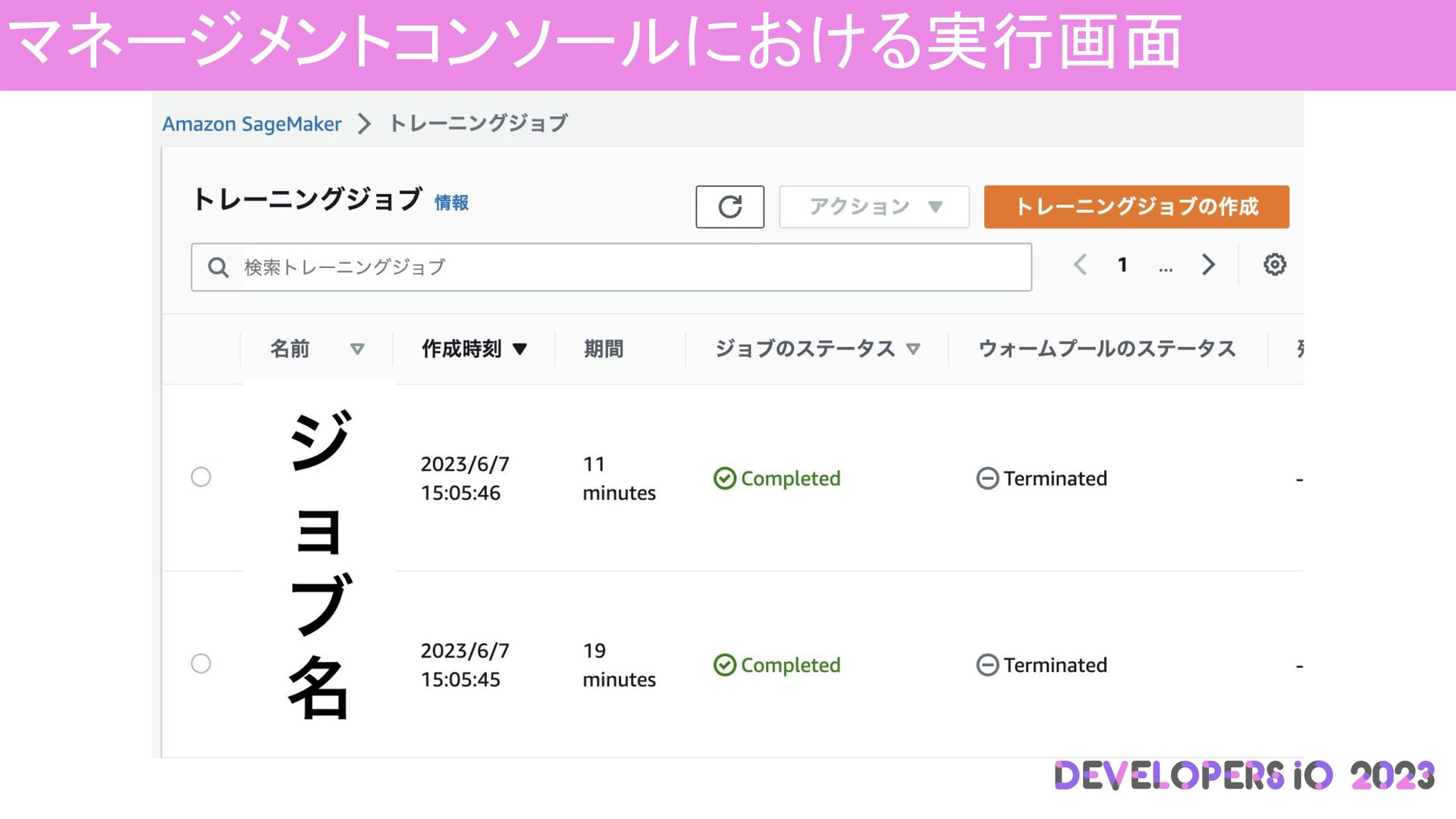
マネージメントコンソールにおける実行画面
• Clarifyでレポート出力 ◦ 推論結果の理由を考えられる ◦ PDP, SHAPの2種類 レポート出力の概要 基本的にPDPとSHAP両方を出力して確認しよう!
レポートの出力内容: PDP 特徴量A
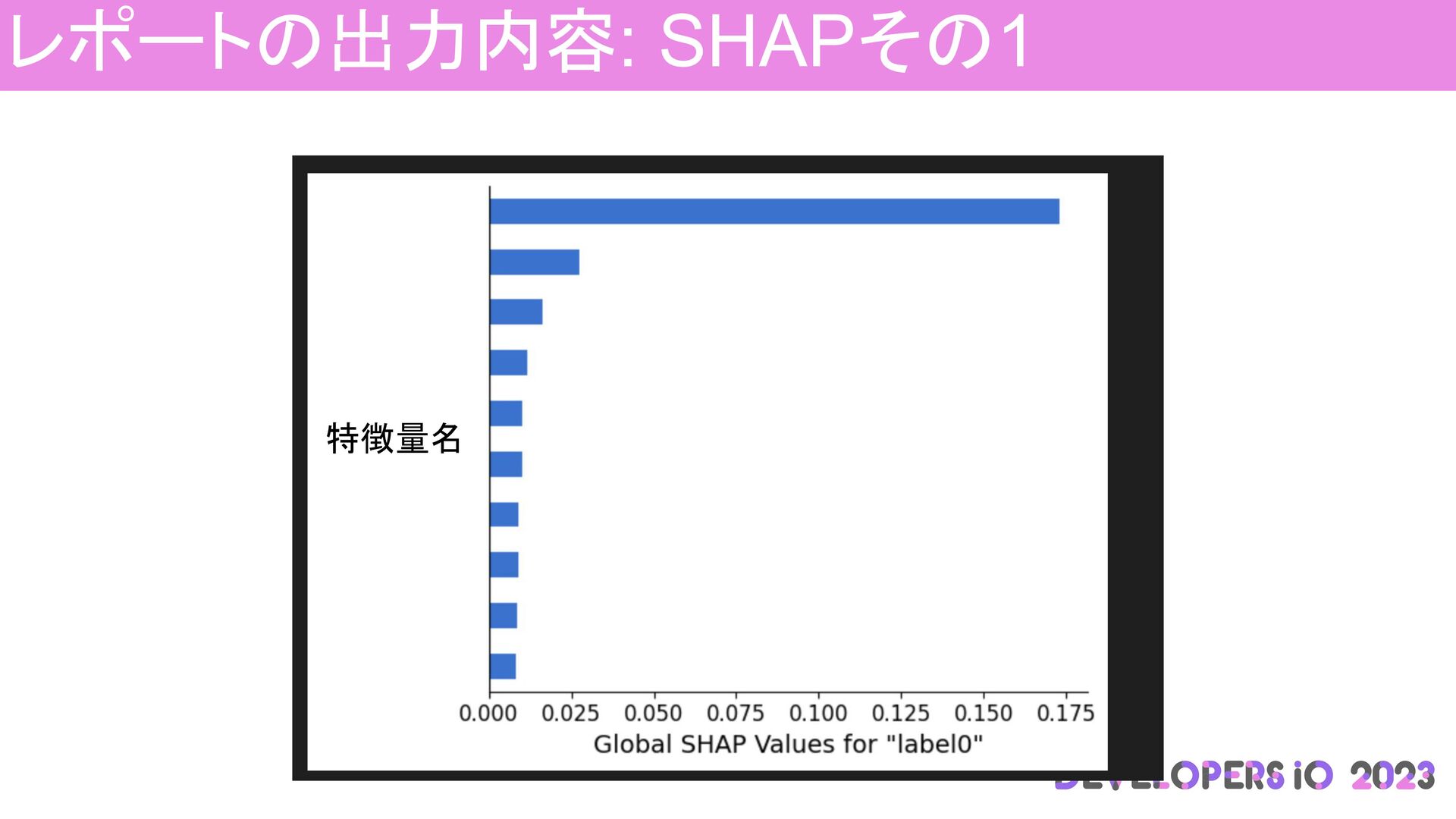
レポートの出力内容: SHAPその1 特徴量名
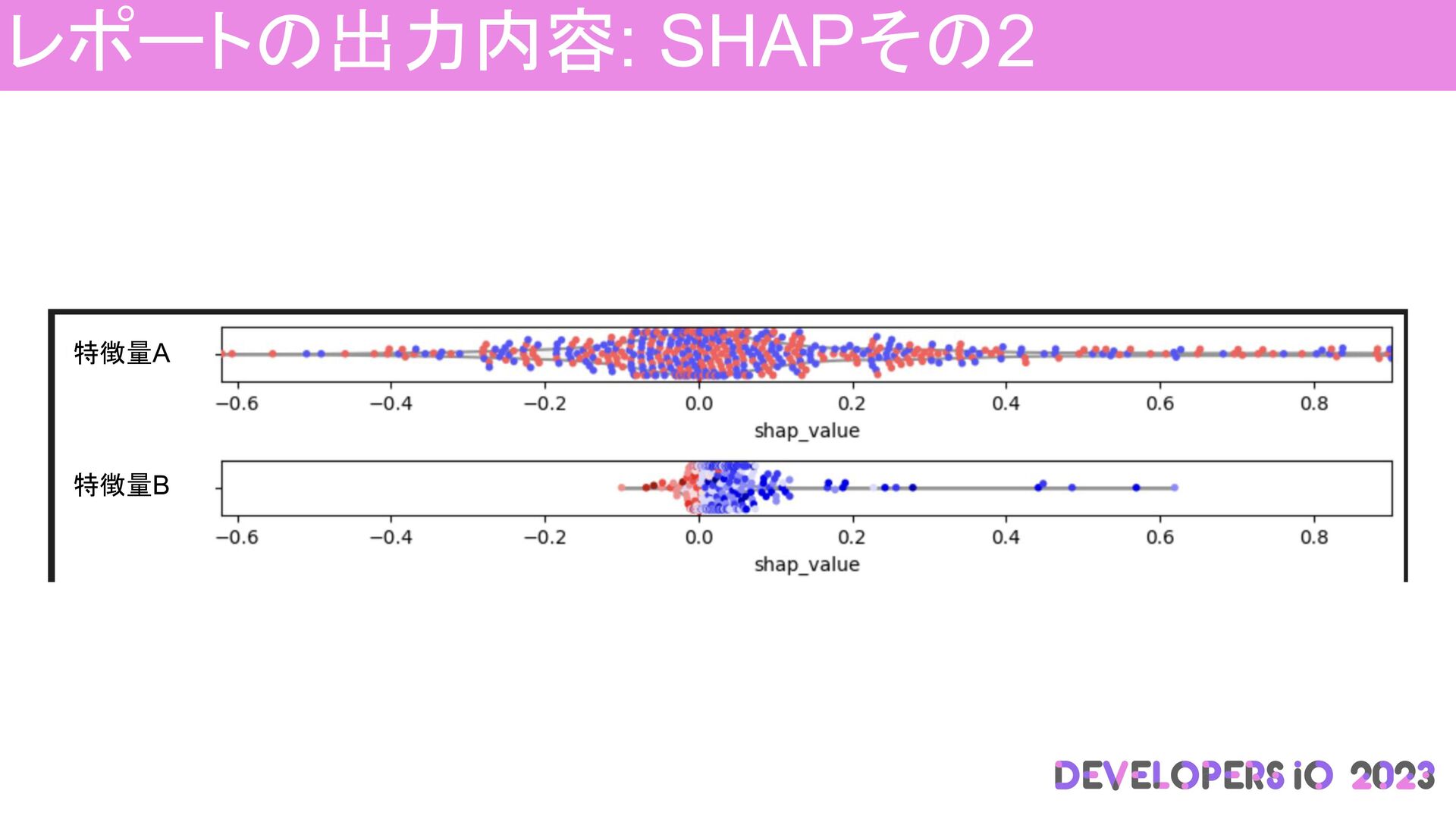
レポートの出力内容: SHAPその2 特徴量A 特徴量B
PDPとは ある特徴量1つ(2つ)が与える予測への平均的な影響を確認 できるもの
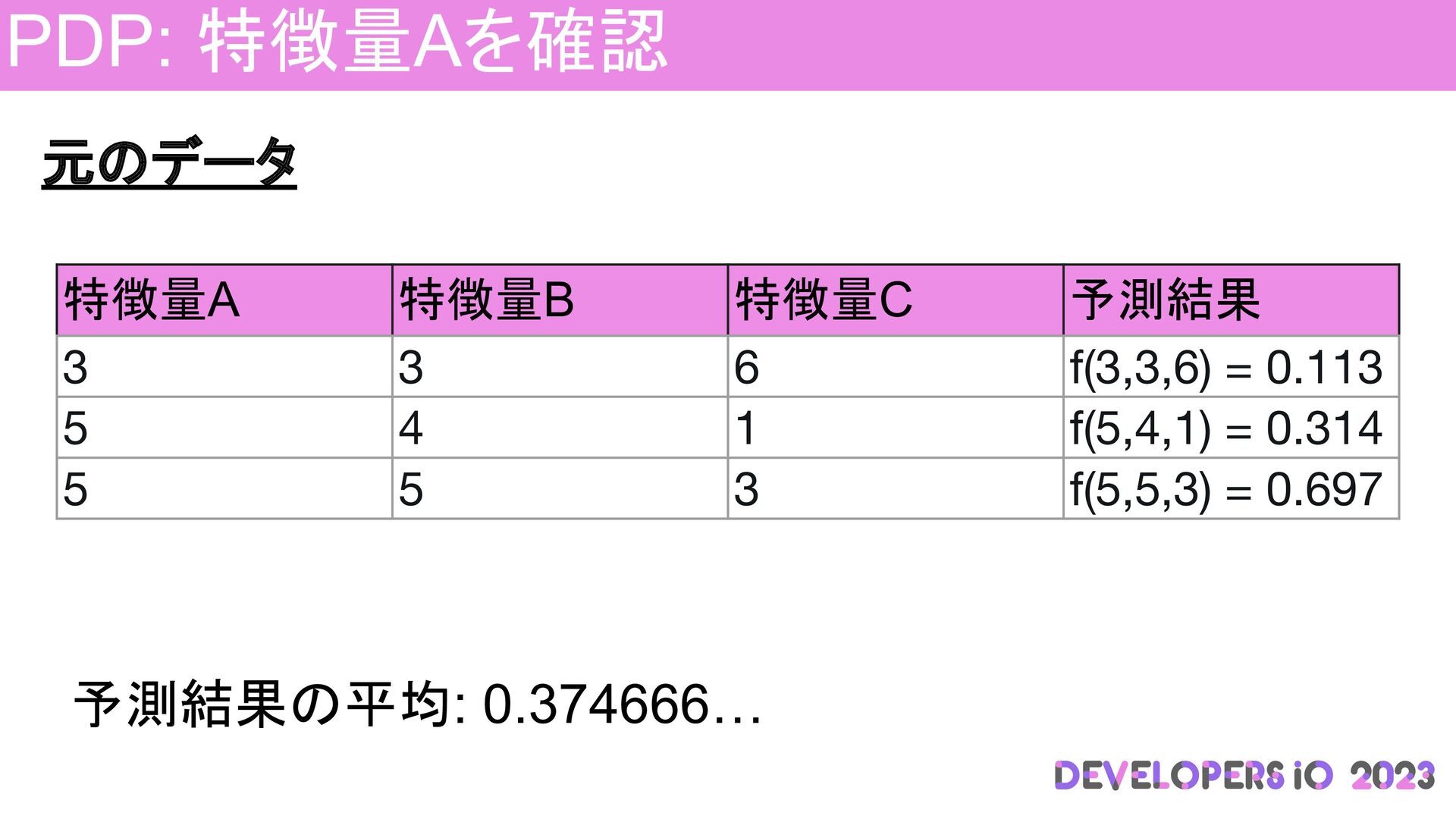
PDP: 特徴量Aを確認 元のデータ 特徴量A 特徴量B 特徴量C 予測結果 3 3 6
f(3,3,6) = 0.113 5 4 1 f(5,4,1) = 0.314 5 5 3 f(5,5,3) = 0.697 予測結果の平均: 0.374666…
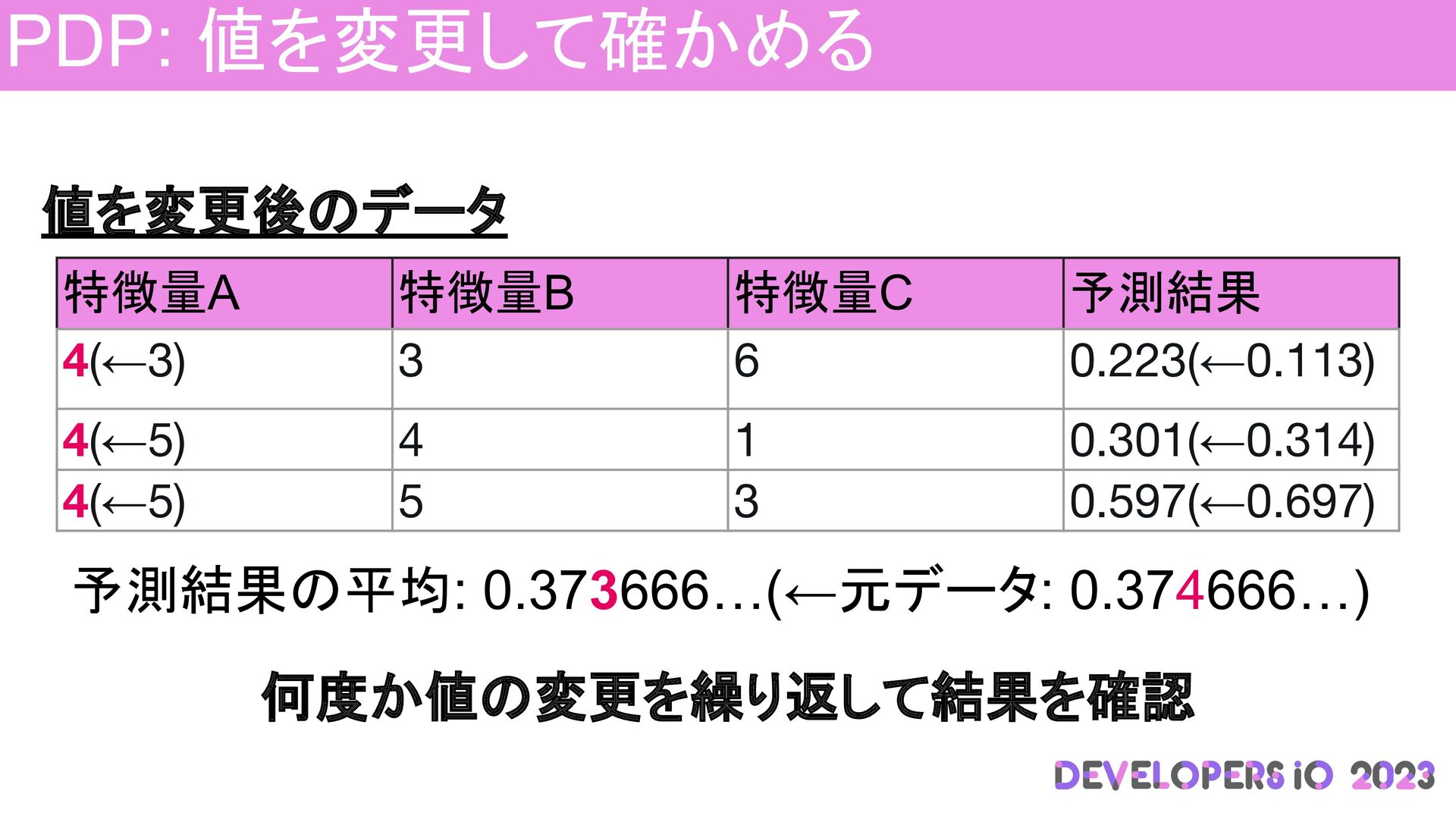
PDP: 値を変更して確かめる 値を変更後のデータ 何度か値の変更を繰り返して結果を確認 予測結果の平均: 0.373666…(←元データ: 0.374666…) 特徴量A 特徴量B 特徴量C
予測結果 4(←3) 3 6 0.223(←0.113) 4(←5) 4 1 0.301(←0.314) 4(←5) 5 3 0.597(←0.697)
SHAPとは 特徴量が予測にどれだけ役立ったか確認できるもの
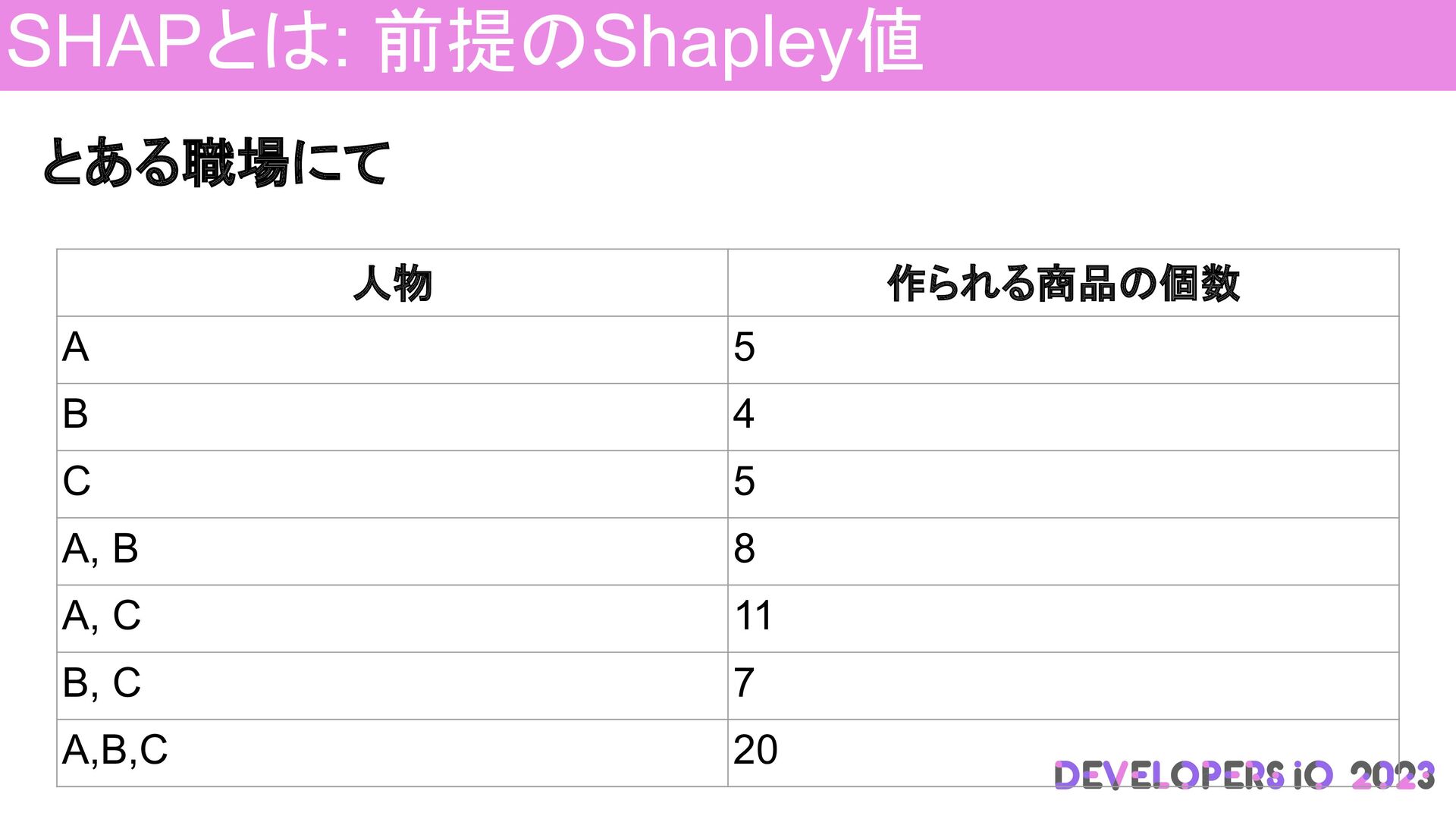
SHAPとは: 前提のShapley値 とある職場にて 人物 作られる商品の個数 A 5 B 4 C
5 A, B 8 A, C 11 B, C 7 A,B,C 20
SHAPとは: 限界貢献度 Aさんが作る商品数の各状況における最大数を確認したい • Aさんのみなら5個 • Bさんが働いてる時 ◦ Aさん加わると8-4=4個がプラス •
Cさんが働いてる時 ◦ Aさん加わると11-5=6個がプラス • BさんとCさんが働いてる時 ◦ Aさん加わると20-7=13個がプラス 人物 作られる商品 の個数 A 5 B 4 C 5 A, B 8 A, C 11 B, C 7 A,B,C 20
SHAPとは: 限界貢献度 Aさんが作る商品数の各状況における最大数を確認したい • Aさんのみなら5個 • Bさんが働いてる時 ◦ Aさん加わると8-4=4個がプラス •
Cさんが働いてる時 ◦ Aさん加わると11-5=6個がプラス • BさんとCさんが働いてる時 ◦ Aさん加わると20-7=13個がプラス 人物 作られる商品 の個数 A 5 B 4 C 5 A, B 8 A, C 11 B, C 7 A,B,C 20 各データにおいて 注目している特徴量でどういったデータが予 測に役立っているか確認可能
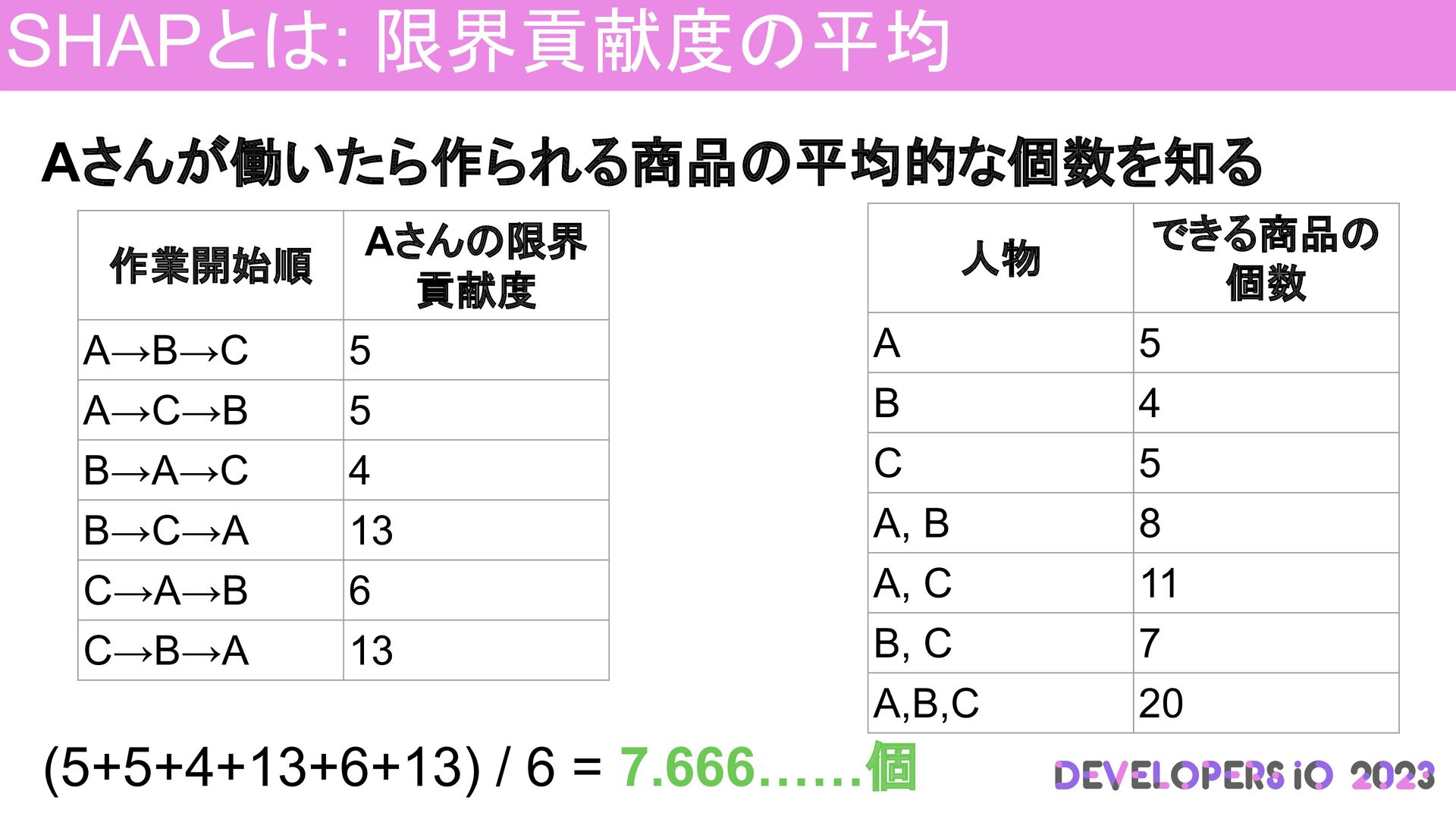
SHAPとは: 限界貢献度の平均 Aさんが働いたら作られる商品の平均的な個数を知る 人物 できる商品の 個数 A 5 B 4
C 5 A, B 8 A, C 11 B, C 7 A,B,C 20 作業開始順 Aさんの限界 貢献度 A→B→C 5 A→C→B 5 B→A→C 4 B→C→A 13 C→A→B 6 C→B→A 13 (5+5+4+13+6+13) / 6 = 7.666……個
SHAPとは: 限界貢献度の平均 Aさんが働いたら作られる商品の平均的な個数を知る 人物 できる商品の 個数 A 5 B 4
C 5 A, B 8 A, C 11 B, C 7 A,B,C 20 作業開始順 Aさんの限界 貢献度 A→B→C 5 A→C→B 5 B→A→C 4 B→C→A 13 C→A→B 6 C→B→A 13 (5+5+4+13+6+13) / 6 = 7.666……個 各特徴量について限界貢献度の平均を求め るとどの特徴量が予測に役立っているか 確認できる
レポート出力までのステップ 1. モデルのデプロイ 2. 4つのconfigを設定 3. Clarifyを実行
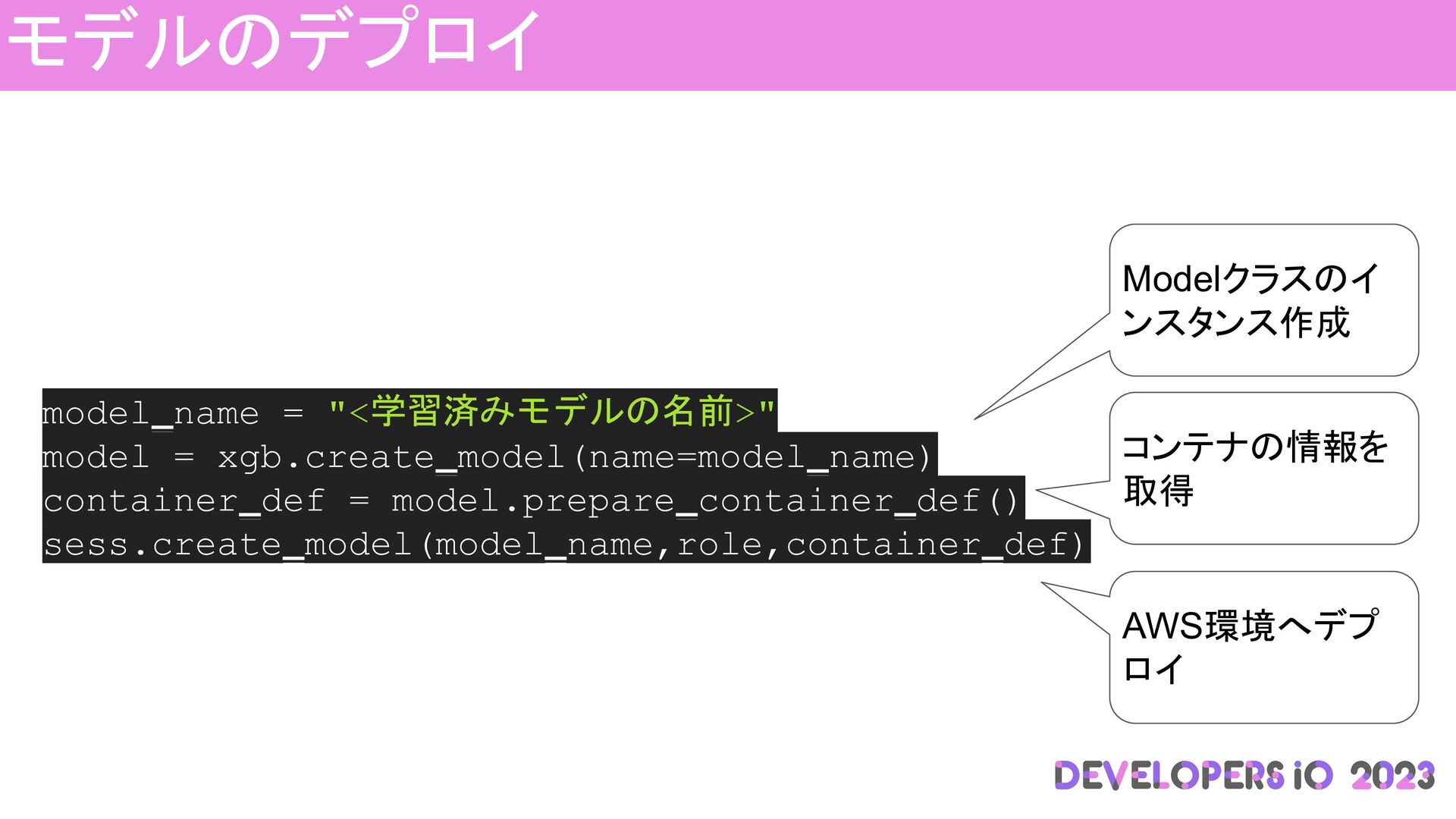
モデルのデプロイ model_name = "<学習済みモデルの名前>" model = xgb.create_model(name=model_name) container_def = model.prepare_container_def()
sess.create_model(model_name,role,container_def) Modelクラスのイ ンスタンス作成 コンテナの情報を 取得 AWS環境へデプ ロイ
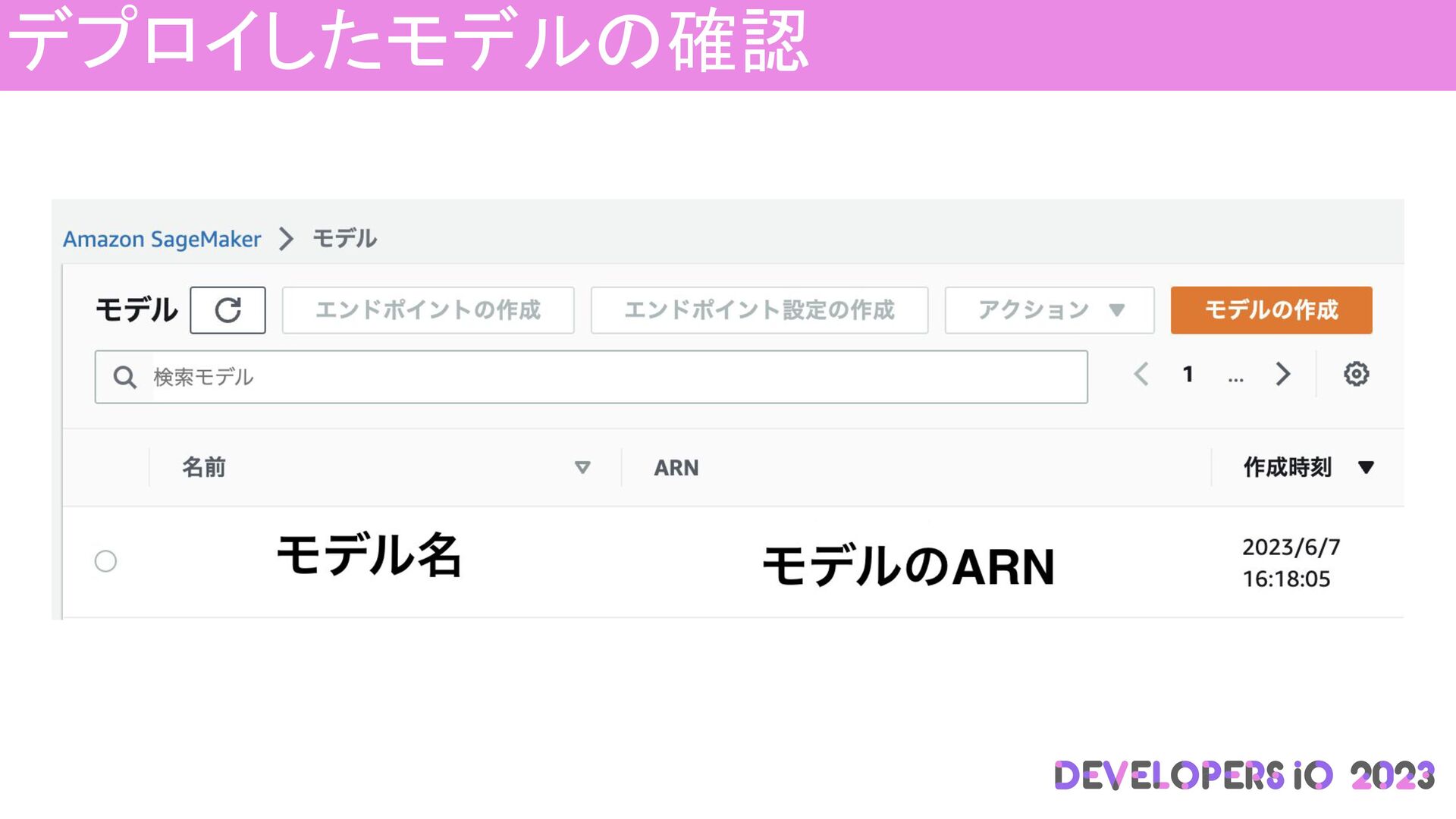
デプロイしたモデルの確認
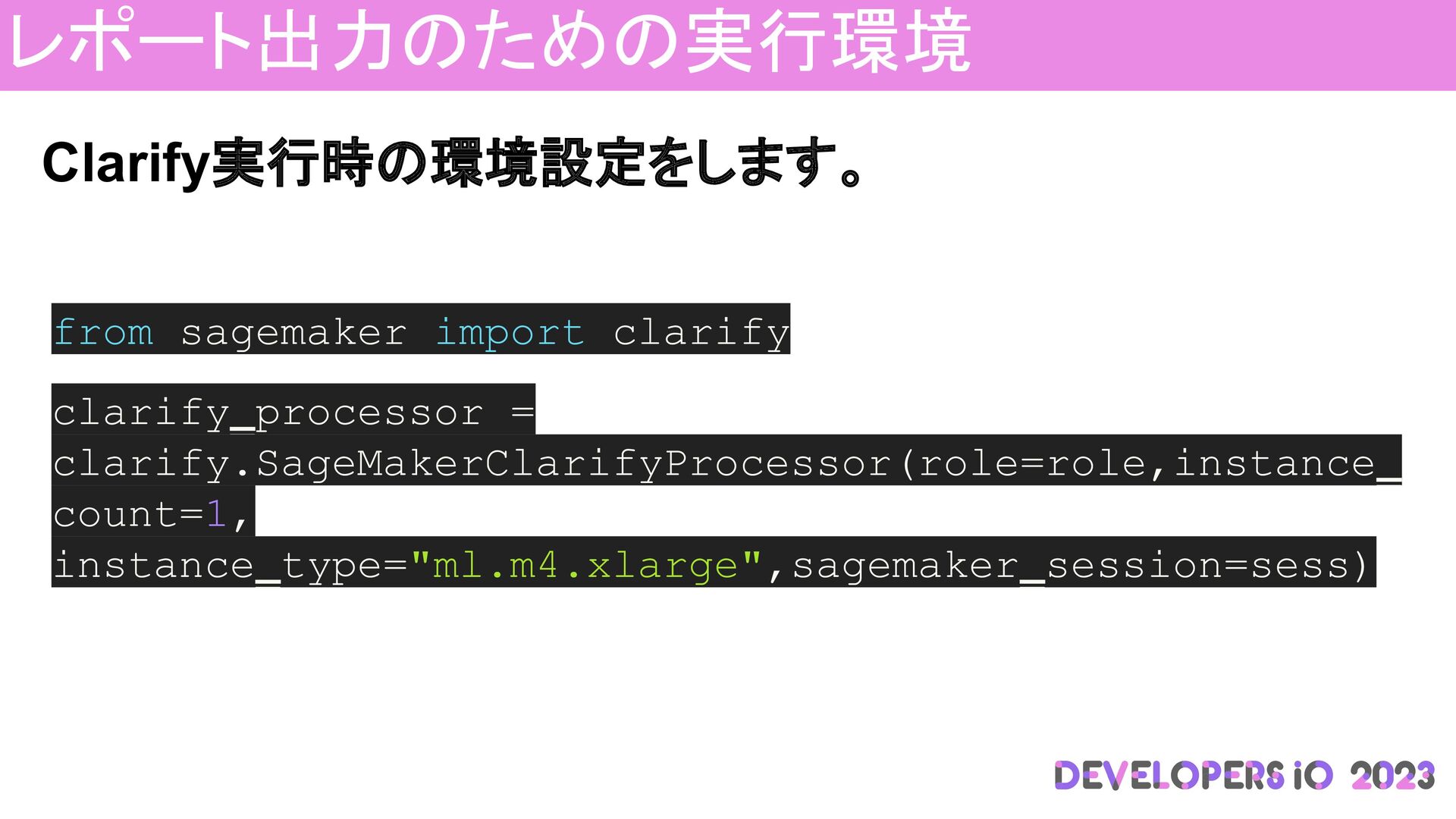
レポート出力のための実行環境 Clarify実行時の環境設定をします。 from sagemaker import clarify clarify_processor = clarify.SageMakerClarifyProcessor(role=role,instance_ count=1,
instance_type="ml.m4.xlarge",sagemaker_session=sess)
config1つ目: PDPConfig PDPの出力を設定 pdp_config_with_shap = clarify.PDPConfig( top_k_features=5, grid_resolution=25) SHAPの結果を見 て重要度TOP5ま
でPDPで確認 出力の平均を確 認する回数
config2つ目: SHAPConfig SHAPの出力 shap_config = clarify.SHAPConfig( baseline=[<データ>], num_samples=15, agg_method="mean_abs", )
SHAP値計算の基 準 SHAP値の計算に 使うデータ数 SHAP値の絶対値 の平均
config3つ目: DataConfig データの入出力先などを設定 explainability_data_config = clarify.DataConfig( s3_data_input_path="<学習に使っていないデータセットS3 URI>", s3_output_path="<レポートの出力先 S3
URI>", label="<正解ラベルの名前>", headers=<各特徴量の名前(list型)>, dataset_type="text/csv", )
config4つ目: ModelConfig 推論エンドポイントのインスタンス model_config = clarify.ModelConfig( model_name=model_name, instance_type="ml.m4.xlarge", instance_count=1, accept_type="text/csv",
content_type="text/csv", ) デプロイしたモデ ルの名前 モデルがアウトプットする ファイル拡張子 モデルがインプットを受け 付けるファイル拡張子
Clarifyの実行 clarify_processor.run_explainability( data_config=explainability_data_config, model_config=model_config, explainability_config=[pdp_config_with_shap, shap_config], logs=False, )
再掲: PDPとは ある特徴量1つ(2つ)が与える予測への平均的な影響を確認 できるもの
PDP 横軸 割り当てた数値 縦軸 予測値 特徴量A
再掲: SHAPとは 特徴量が予測にどれだけ役立ったか確認できるもの
SHAP: 全体的な評価 上から順番に予測に 役立った特徴量 特徴量名
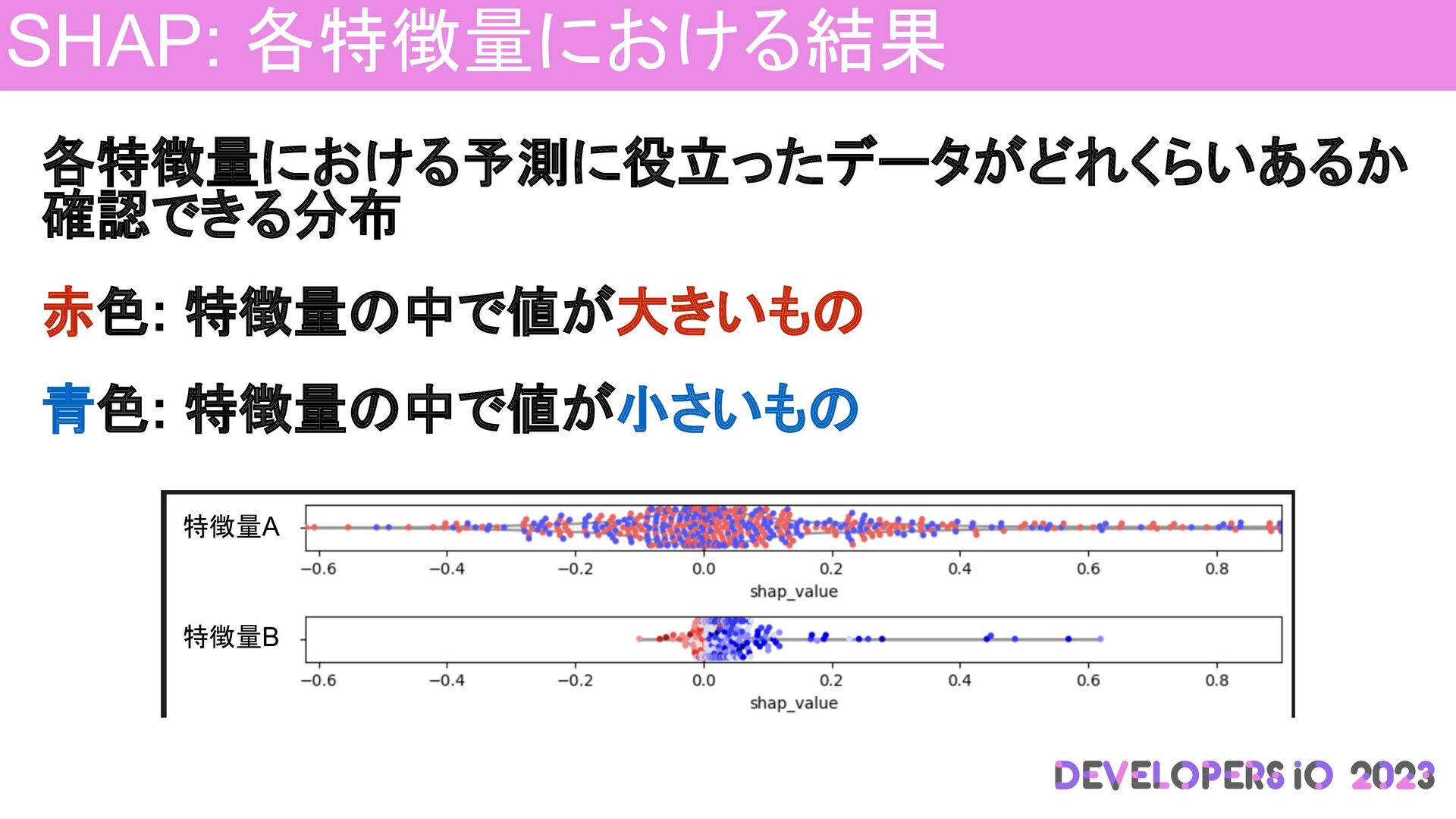
SHAP: 各特徴量における結果 各特徴量における予測に役立ったデータがどれくらいあるか 確認できる分布 赤色: 特徴量の中で値が大きいもの 青色: 特徴量の中で値が小さいもの 特徴量A 特徴量B
クルトン先輩によるまとめ • 機械学習モデルは学習してから推論する • SageMakerでは簡単に学習や推論ができる環境がある • 良い推論であっても油断しちゃダメ!根拠は何? • SageMaker Clarifyを使って推論結果について考えてみよ
う
None
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![本スライドで使う用語:その3 • 特徴量 ◦ データの名前 例えば猫なら…… 種類 体重[kg] 年齢[年] メインクーン](https://files.speakerdeck.com/presentations/2f565a52625844fbb2e9f04332ac5728/slide_5.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![config2つ目: SHAPConfig SHAPの出力 shap_config = clarify.SHAPConfig( baseline=[<データ>], num_samples=15, agg_method="mean_abs", )](https://files.speakerdeck.com/presentations/2f565a52625844fbb2e9f04332ac5728/slide_48.jpg){kind=link}
{kind=link}
{kind=link}
![Clarifyの実行 clarify_processor.run_explainability( data_config=explainability_data_config, model_config=model_config, explainability_config=[pdp_config_with_shap, shap_config], logs=False, )](https://files.speakerdeck.com/presentations/2f565a52625844fbb2e9f04332ac5728/slide_51.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}