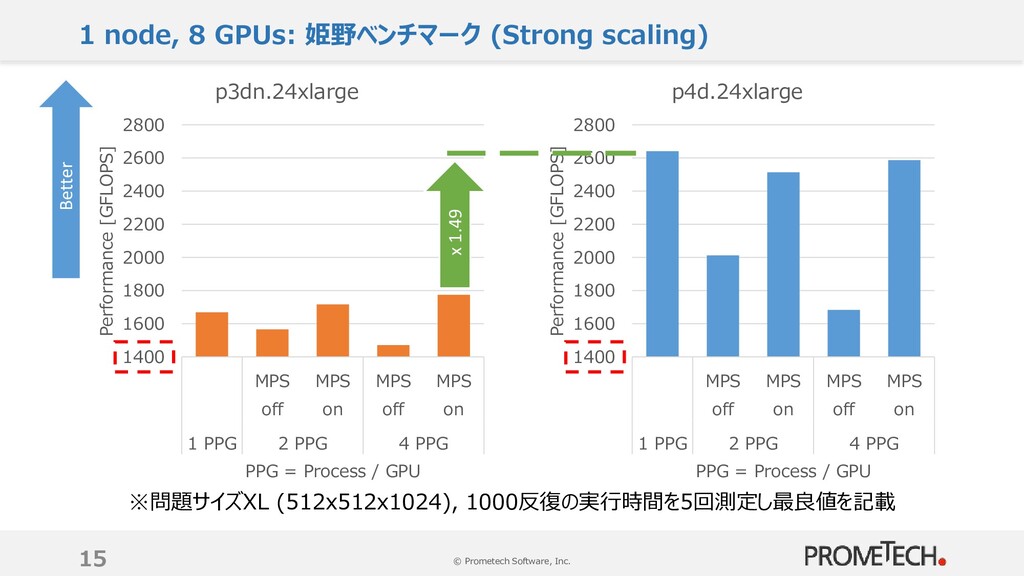
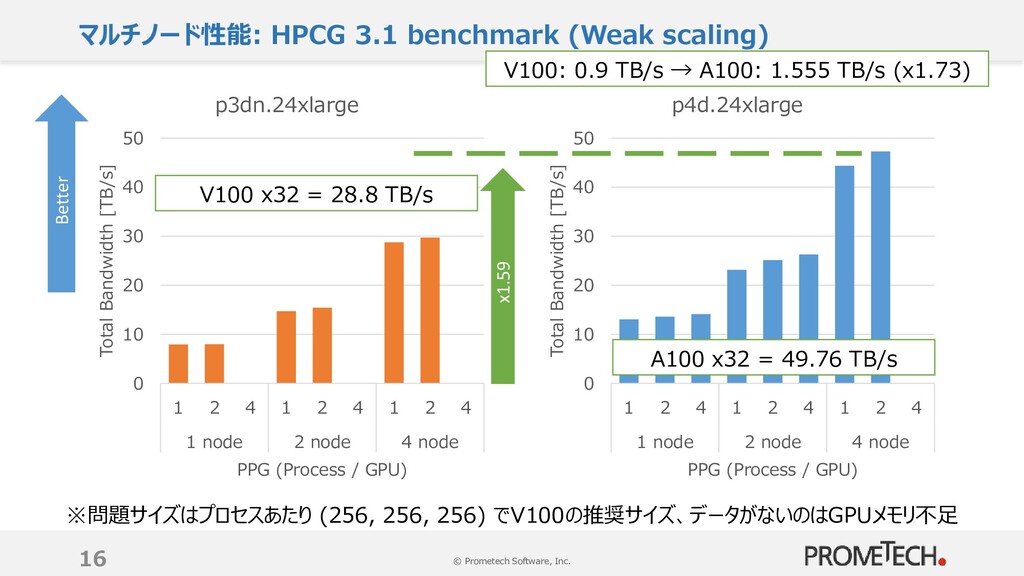
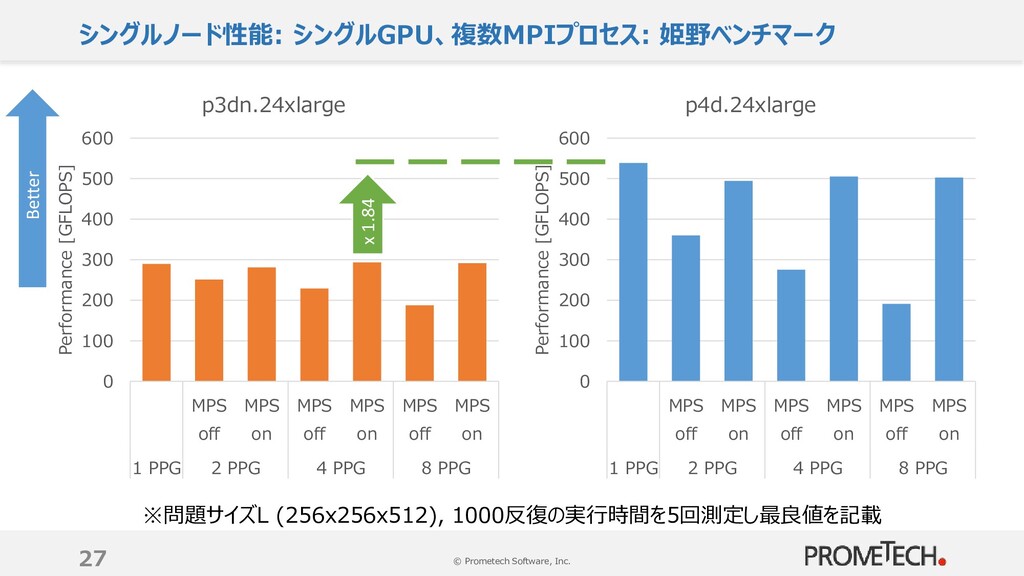
1000反復の実行時間を5回測定し最良値を記載 0 100 200 300 400 500 600 MPS off MPS on MPS off MPS on MPS off MPS on 1 PPG 2 PPG 4 PPG 8 PPG Performance [GFLOPS] p3dn.24xlarge Better 0 100 200 300 400 500 600 MPS off MPS on MPS off MPS on MPS off MPS on 1 PPG 2 PPG 4 PPG 8 PPG Performance [GFLOPS] p4d.24xlarge x 1.84
{kind=link}
{kind=link}
{kind=link}
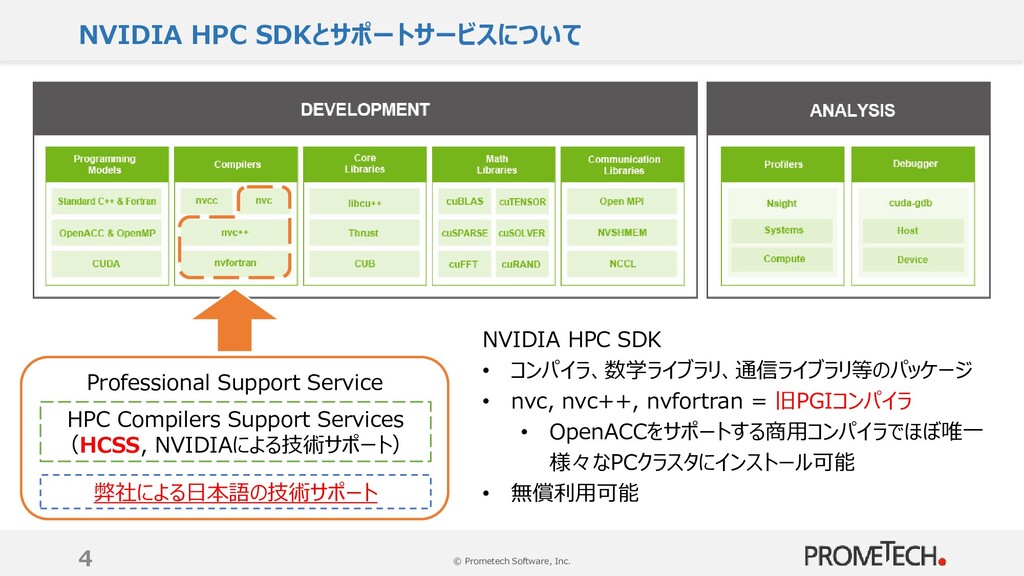{kind=link}
{kind=link}
{kind=link}
{kind=link}
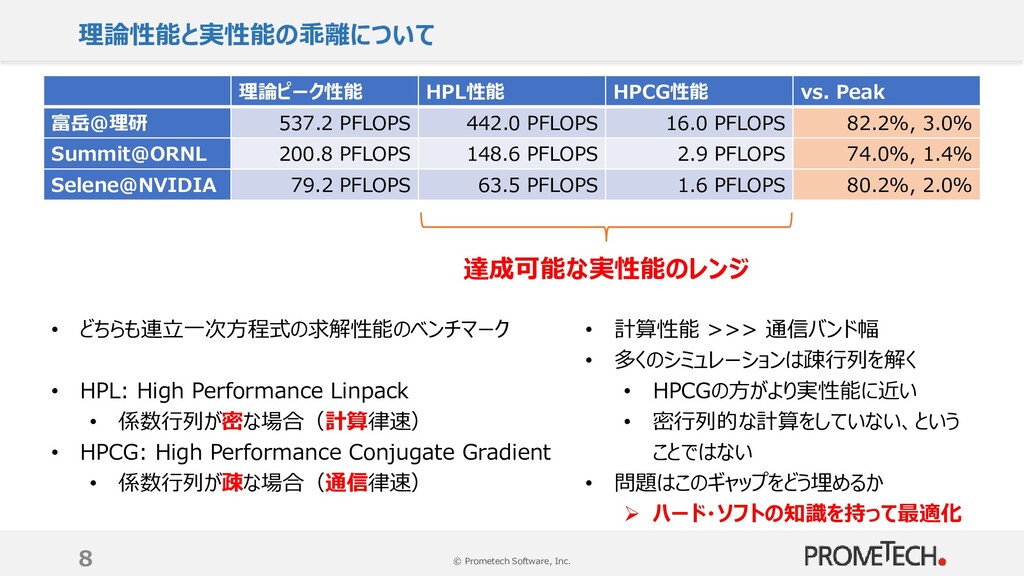{kind=link}
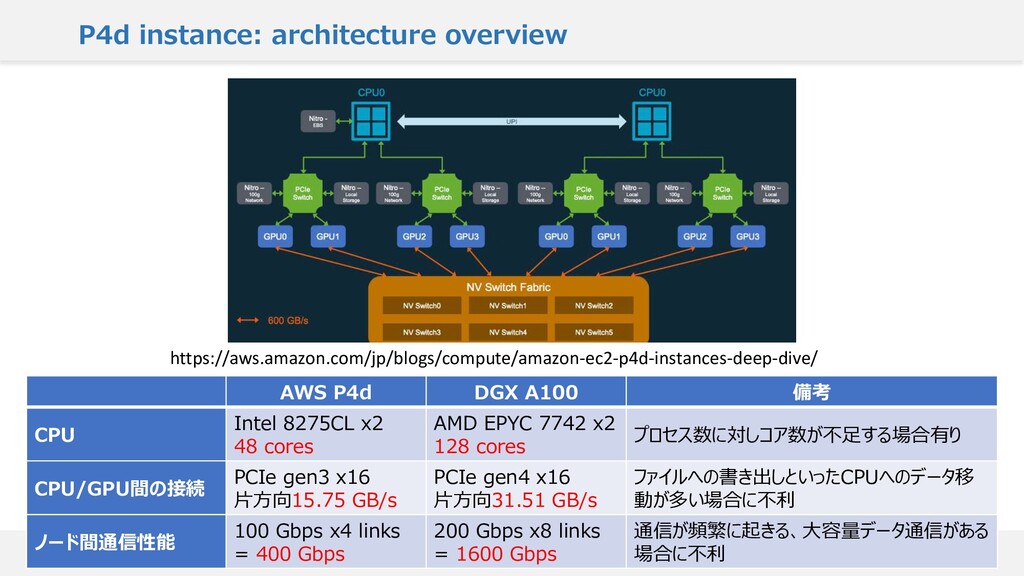{kind=link}
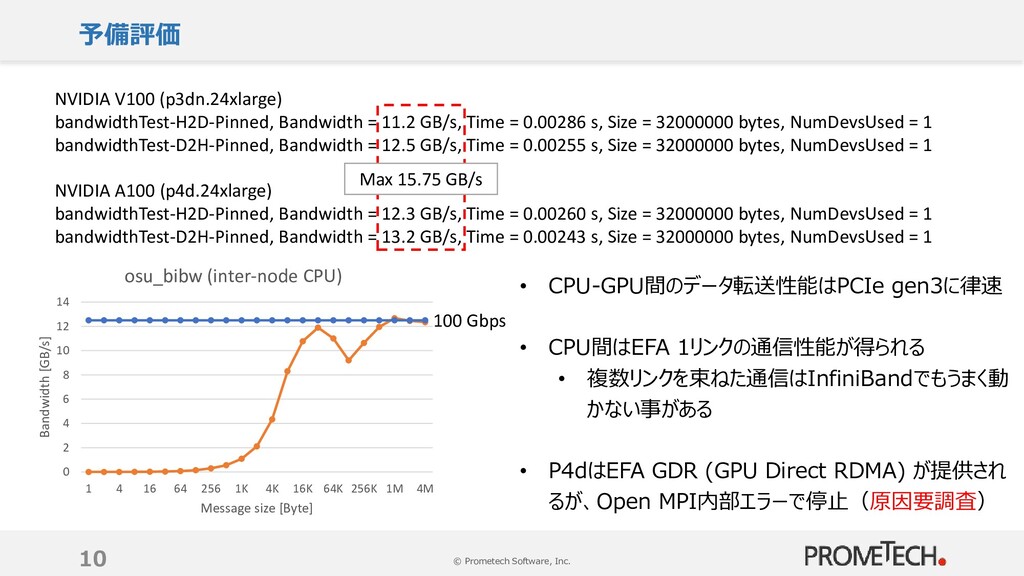{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![© Prometech Software, Inc. [PR] HPCコミュニティサイト “HPC WORLD” のオープン 25](https://files.speakerdeck.com/presentations/45efbdf222c44bef8704a556b6a14f4c/slide_24.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}