At Netconomy's 3rd Innovation Day (13th Jan. 2017) I gave a talk about selected features in MongoDB 3.4. Here is a slightly modified/extended version of the slide deck of my session.
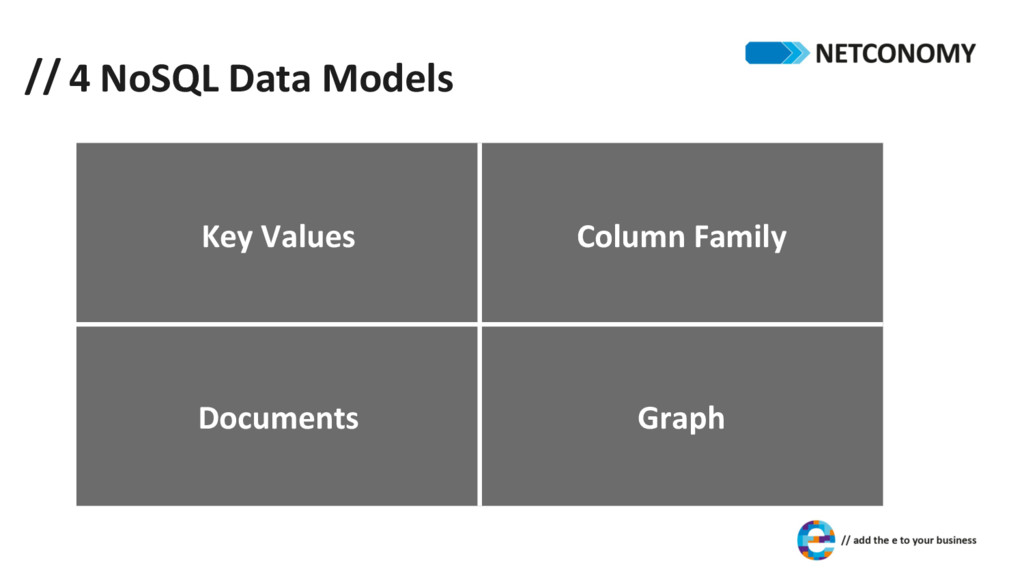
non-‐relaDonal database systems very different approaches to handle data persistence not a single agreed-‐upon definiDon common characterisDcs? any non-‐relaDonal data model mostly a very good fit for clustered environments designed for large/web-‐scale applicaDons no fixed schema typically open-‐source (at least their origins)
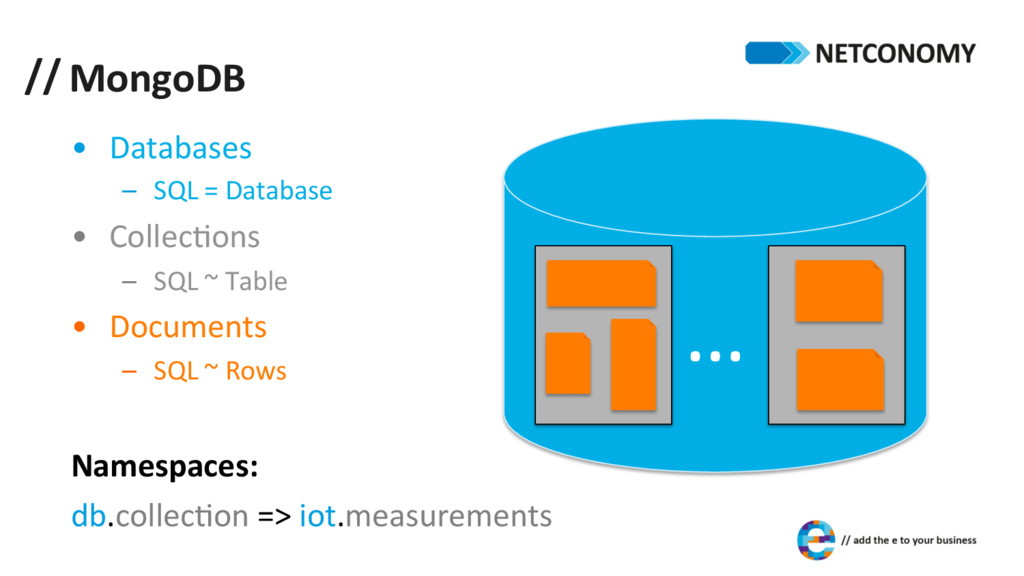
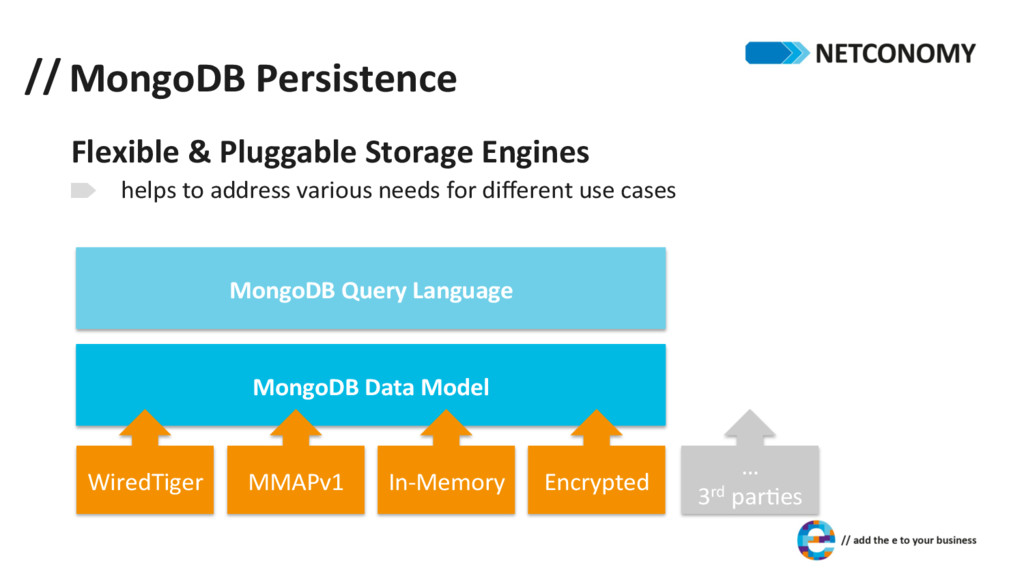
structure internal format: BSON* § binary-‐encoded superset of JSON § more datatypes § fast encoding/decoding § efficient in storage space document size à max. 16 MB *details see h+p://bsonspec.org
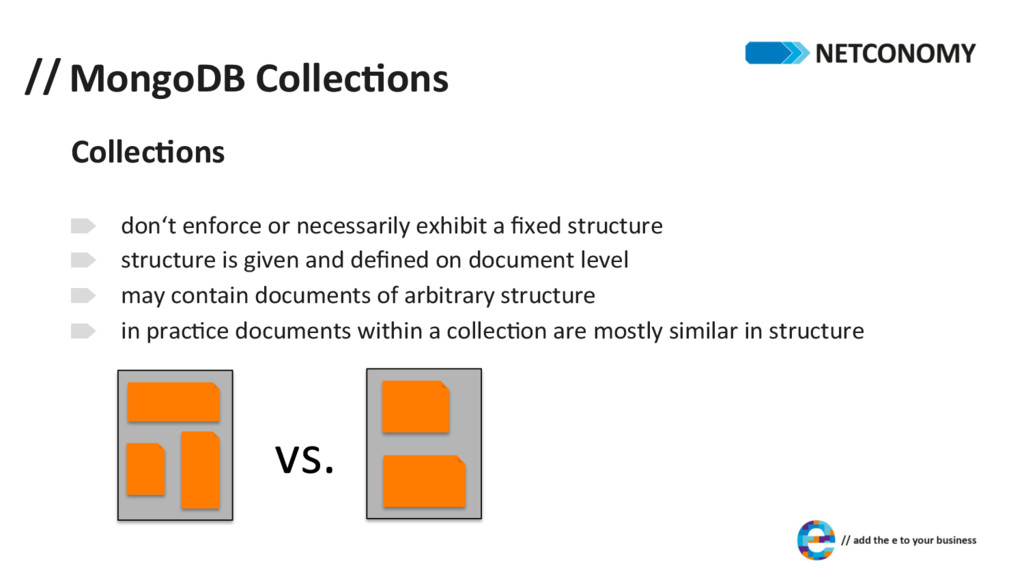
exhibit a fixed structure structure is given and defined on document level may contain documents of arbitrary structure in pracDce documents within a collecDon are mostly similar in structure vs.
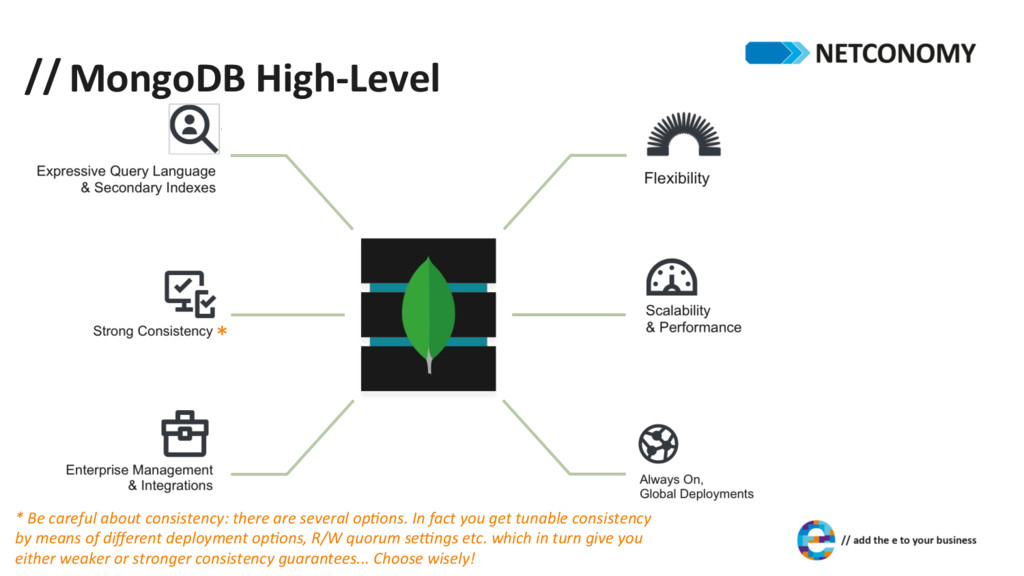
about consistency: there are several op;ons. In fact you get tunable consistency by means of different deployment op;ons, R/W quorum seCngs etc. which in turn give you either weaker or stronger consistency guarantees... Choose wisely!
read-‐only provide easy data access (hide aggregaDons) redact document fields (hide sensiDve data) more fine-‐grained security (no direct access) Tooling OperaDons Develop ment
don‘t directly contain any documents built based on aggregaDon pipelines view definiDons à system.views collecDon no writes allowed for obvious reasons Tooling OperaDons Develop ment
used for analyzing tree or graph structures logical extension of $lookup (eq. lei-‐outer join) works by doing recursive lookups query filters and depth can be defined supports „self“ or „cross“ collecDons lookups Tooling OperaDons Develop ment
manipulate, inspect & analyze mulD-‐dimension data perform faceted search & navigaDon facets as filters to narrow result sets use cases: catalog browsing & grouping analyDcs,... Tooling OperaDons Develop ment
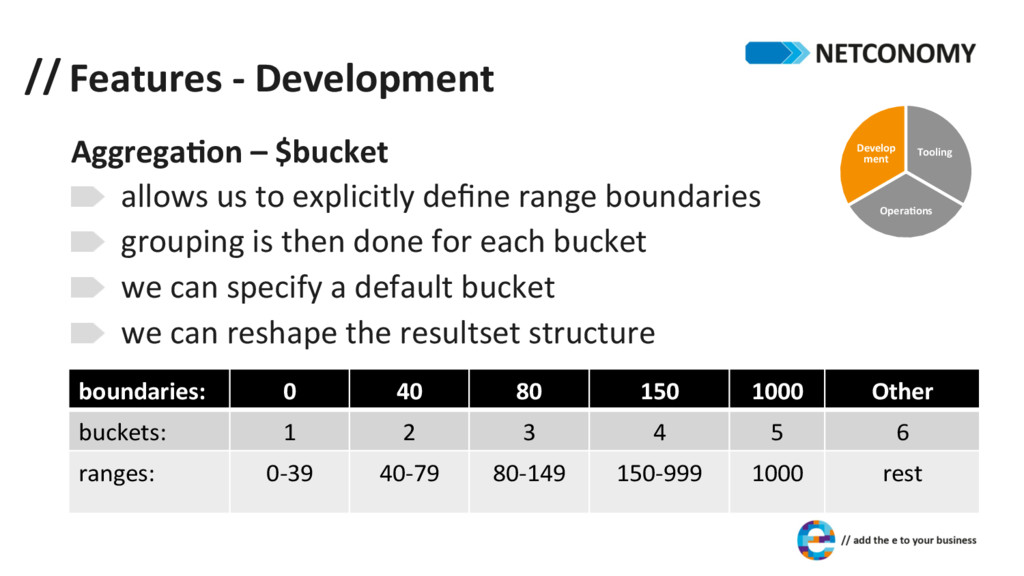
us to explicitly define range boundaries grouping is then done for each bucket we can specify a default bucket we can reshape the resultset structure Tooling OperaDons Develop ment boundaries: 0 40 80 150 1000 Other buckets: 1 2 3 4 5 6 ranges: 0-‐39 40-‐79 80-‐149 150-‐999 1000 rest
hinDng on #buckets to split into finds boundaries automagically tries to evenly distribute data across buckets output reshaping also supported granularity can be specified for numeric types Tooling OperaDons Develop ment
tunable consistency (linearizable reads J finally) extensive collaDons support (several languages) new BSON Type Decimal128 (exact precision/ rounding) a bunch of new Array/String/ISOdate operators ... Tooling OperaDons Develop ment
sync (Primary à Secondaries) all indexes (not only _id) are being build during the sync retry logic to compensate network issues intra cluster compression snappy to achieve up to 70% compression benefits w.r.t. network throughput reduce network traffic costs in cloud environments Tooling OperaDons Develop ment
awareness for cluster components faster balancing due to parallel chunk migraDons balancer runs on config servers primary node config servers run as normal replica sets (no mirroring) sharding zones (supersede old tag-‐ware sharding) Tooling OperaDons Develop ment
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}