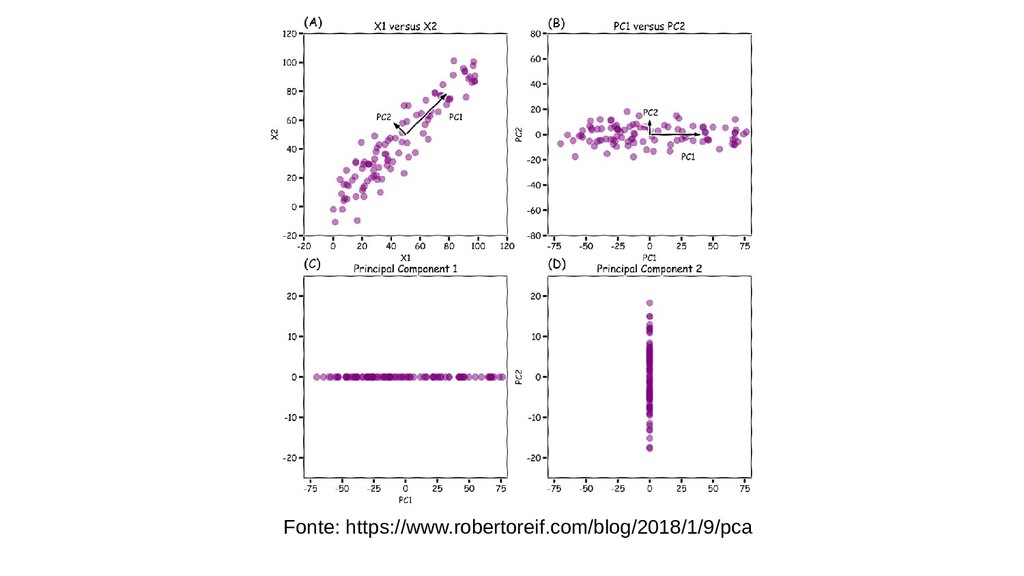
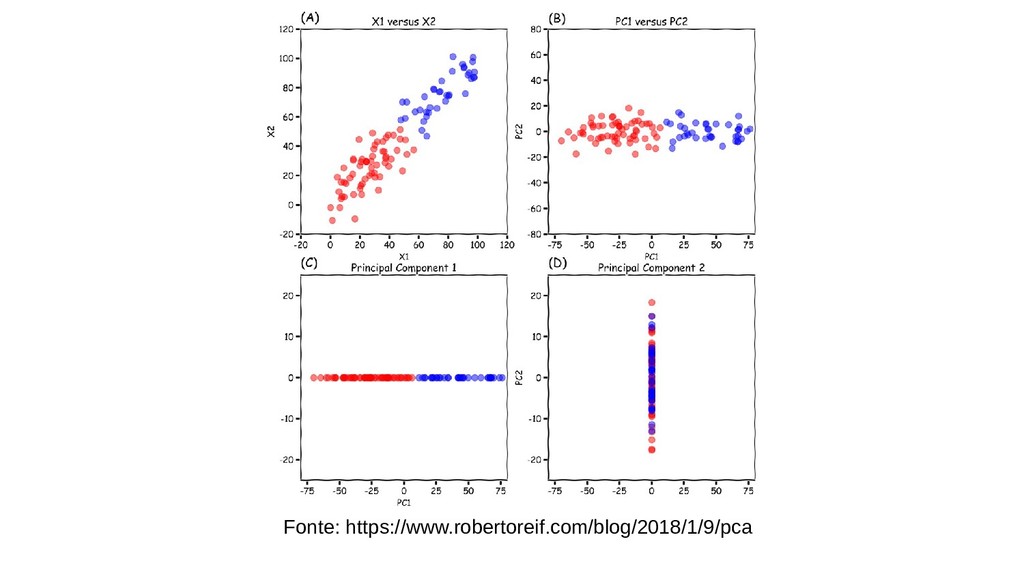
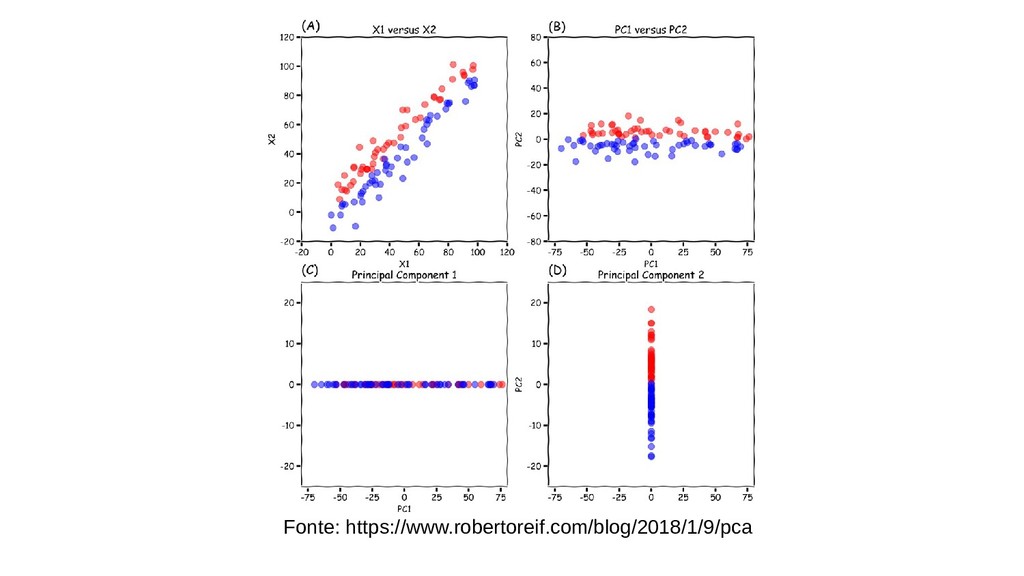
Veremos como reduzir as dimensões de um dataset com baixa perda de informação usando PCA bem como seus pontos fortes e fracos.
Após a palestra vamos ter um bate-papo sobre machine learning. A ideia é compartilhar aplicações, tirar dúvidas e disseminar um pouco de conhecimento.
Meetup: https://www.meetup.com/pt-BR/hackerspaceblumenau/events/263787166/
Gravação: https://www.youtube.com/watch?v=tEkVjk3oXwo&feature=youtu.be
{kind=link}
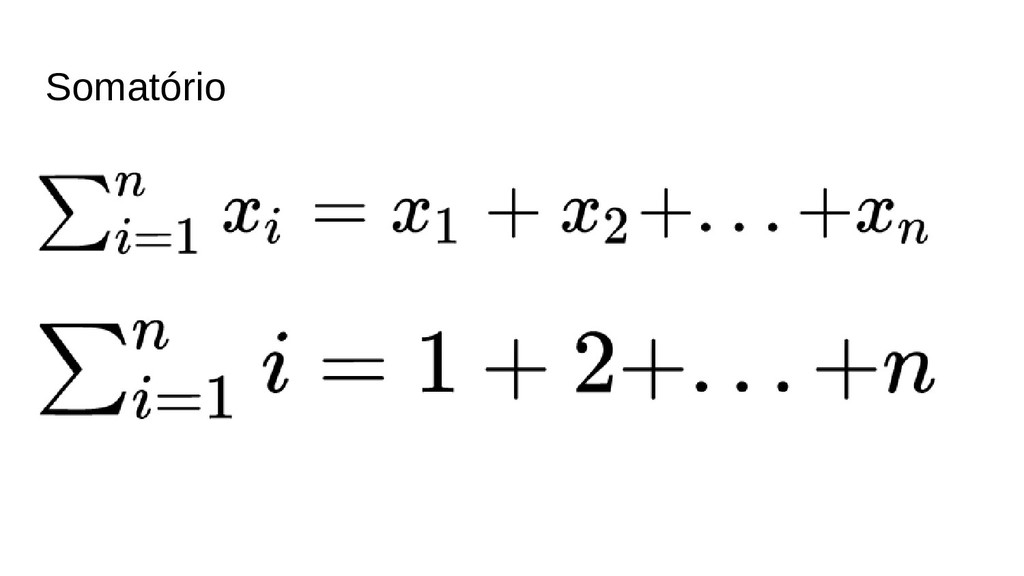{kind=link}
{kind=link}
{kind=link}
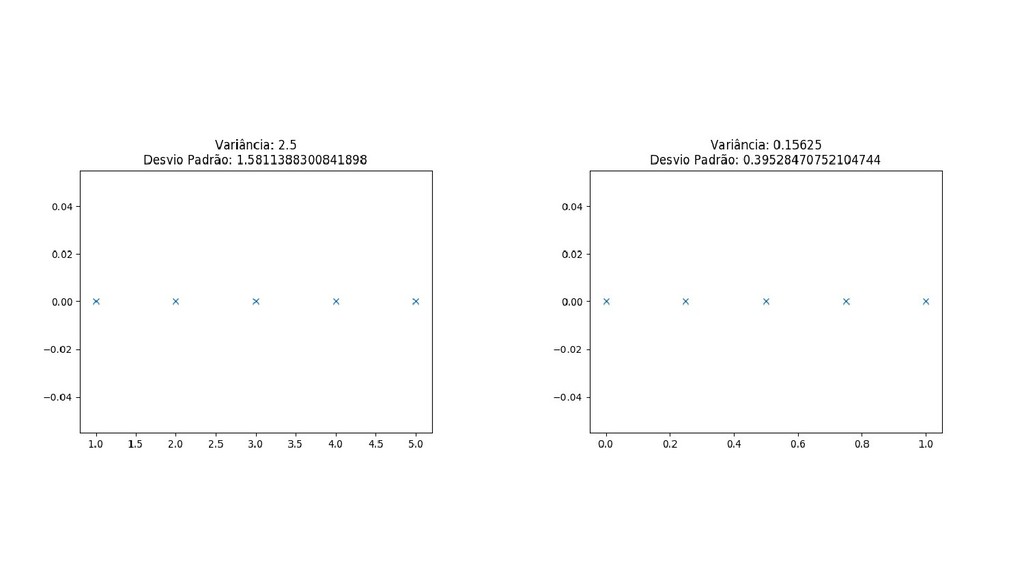{kind=link}
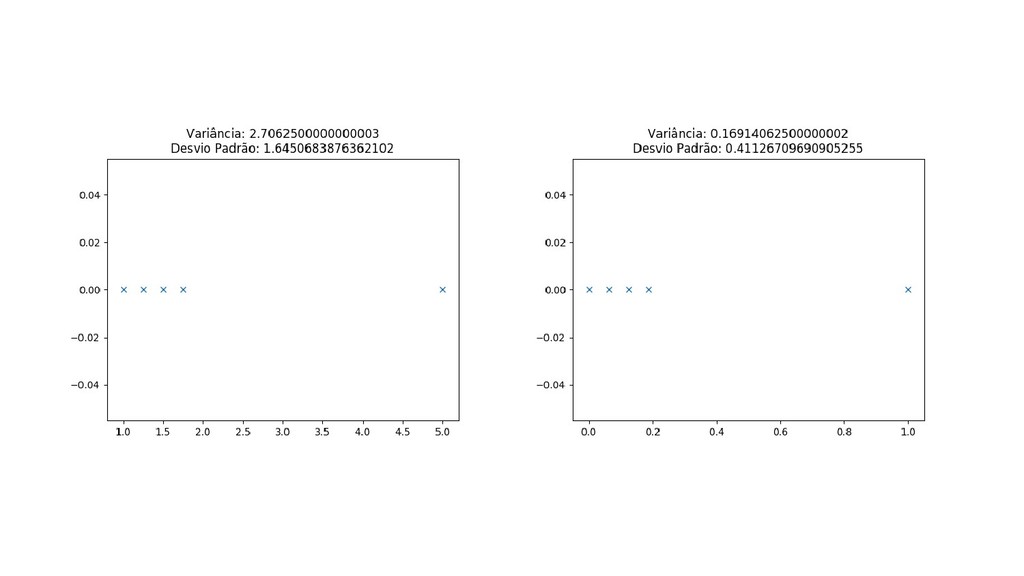{kind=link}
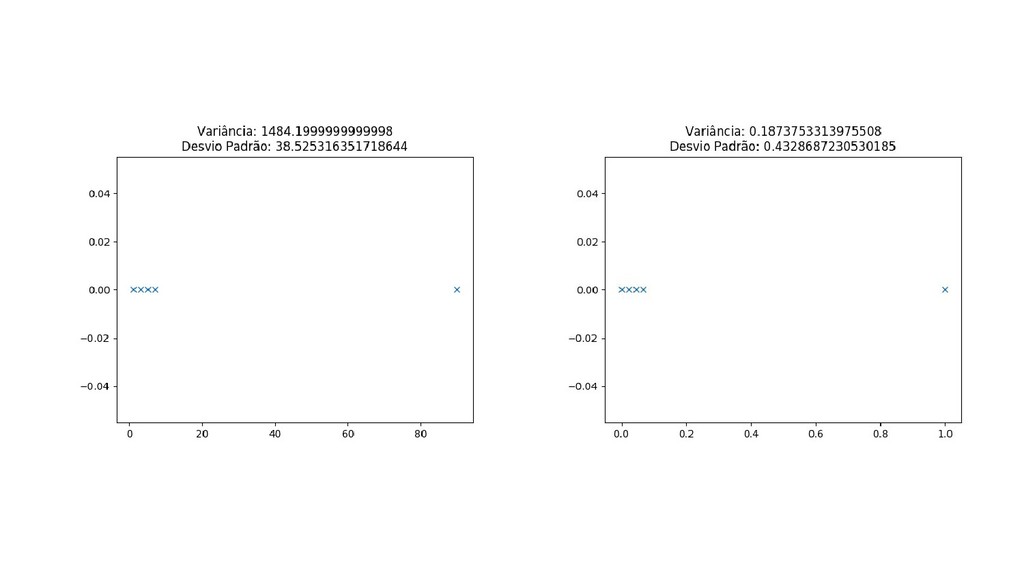{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}