Upgrade to Pro
— share decks privately, control downloads, hide ads and more …
Speaker Deck
Features
Speaker Deck
PRO
Sign in
Sign up for free
Search
Search
RealSense T265とD415とUFACTORY Lite 6で模倣学習の実験
Search
hygradme
November 24, 2023
Technology
940
0
Share
Embed
Copy iframe code
Copy JS code
Copy link
Start on current slide
RealSense T265とD415とUFACTORY Lite 6で模倣学習の実験
第42回ロボティクス勉強会の発表資料です。
hygradme
November 24, 2023
More Decks by hygradme
See All by hygradme
ロボットハンドの調査・自作
hygradme
0
340
UFACTORY Lite 6用リーダーフォロワーシステムの作成
hygradme
0
1.2k
Other Decks in Technology
See All in Technology
Vポイント分析基盤におけるデータモデリング20年史
taromatsui_cccmkhd
4
770
セキュリティ研修【MIXI 26新卒技術研修】
mixi_engineers
PRO
10
10k
AI時代におけるテストの基礎の再定義 / Rethinking the Fundamentals of Testing in the AI Era
mineo_matsuya
15
5.7k
論語・武士道・産業革命から見る かわるもの、かわらないもの
ichimichi
8
1.2k
データベース研修【MIXI 26新卒技術研修】
mixi_engineers
PRO
1
340
WEBフロントエンド研修【MIXI 26新卒技術研修】
mixi_engineers
PRO
1
330
2026年のソフトウェア開発を考える(2026/07版) / Agentic Software Engineering 2026-07 Findy Edition
twada
PRO
30
16k
エンタープライズデータへ安全につなぐ Production-ready なエージェント設計 ― AI × MCP リファレンスアーキテクチャ ― #AIDevDay
cdataj
1
110
AI Agent を本番環境へ―― Microsoft Foundry × Azure Serverless で作る Enterprise-Ready な基盤
shibayan
PRO
1
530
ソフトウェアアーキテクチャ研修【MIXI 26新卒技術研修】
mixi_engineers
PRO
2
540
2年前に削除したPHPクラスが、 ある日突然決済をエラーにした
ykagano
1
840
システム監視入門
grimoh
3
580
Featured
See All Featured
4 Signs Your Business is Dying
shpigford
187
22k
sira's awesome portfolio website redesign presentation
elsirapls
0
310
Stop Working from a Prison Cell
hatefulcrawdad
274
21k
Fireside Chat
paigeccino
42
4k
Money Talks: Using Revenue to Get Sh*t Done
nikkihalliwell
0
420
How to Align SEO within the Product Triangle To Get Buy-In & Support - #RIMC
aleyda
2
1.7k
Performance Is Good for Brains [We Love Speed 2024]
tammyeverts
12
1.7k
Getting science done with accelerated Python computing platforms
jacobtomlinson
2
350
Why Mistakes Are the Best Teachers: Turning Failure into a Pathway for Growth
auna
0
190
Between Models and Reality
mayunak
4
380
Digital Projects Gone Horribly Wrong (And the UX Pros Who Still Save the Day) - Dean Schuster
uxyall
1
2.1k
AI Search: Where Are We & What Can We Do About It?
aleyda
0
7.7k
Transcript
RealSense T265とD415と UFACTORY Lite 6で模倣学習の 実験 2023/11/24 第42回ロボティクス勉強会
・2019年: KickstarterでxArm 5という低価格のアームロボが欲しくなりバックして無事届く。 ・2020年: 卓球の自動返球ロボを MakerFaire Tokyo 2020に出展。第5回ロボゼミで発表 ・2021年: ROS
2の入門としてxArm 5を使ったカルタ取りロボシステム制作。第 19回ロボゼミで発表 ・2022年: KickstarterでバックしていたAmber B1という7軸アームロボットが届く。押入れに眠る。 ・2022年: KickstarterでバックしていたUFACTORY Lite 6が届く ・2022年: Lite 6用の軽量電動並行グリッパーを自作・ GitHubで公開(OpenParallelGripper) ・2023年: ML-Agentsで強化学習に入門。今回の前身となる御玉でボール拾いの学習に挑戦 ・2023年: T265とD415とLite 6を使った模倣学習実験を始める @EL2031watson higradom 過去には四速歩行ロボ にも少し手を出した 卓球ロボ(MakerFaire2020) 自己紹介 カルタ取りロボシステム 冬眠前のAmber B1 OpenParallelGripper with UFACTORY Lite 6 ML-Agentsの実験
https://www.youtube.com/watch?v=5wfc20p2Lek カルタ取りロボシステム実際の稼働時の映像
カルタ取りロボットはルールベースのみ (画像認識で目標位置を決定、動作は MoveItに一任) →ロボットで機械学習使った動作生成試してみたい →実ロボットで機械学習使った動作生成を試してみたい →とりあえず危なそうなのでシミュレーション上で試してみたい。 →UnityのML-Agentsで強化学習のタスクを3つほど試す。 ルールベースから機械学習ベースの動作生成へ
強化学習 with ML-Agents 赤・緑のブロックを仕分けする 茶色の棒を「コの字」の中に入れる 白い容器の中から青いボールを取り出す Implicit Behavioral Cloning https://arxiv.org/abs/2109.00137
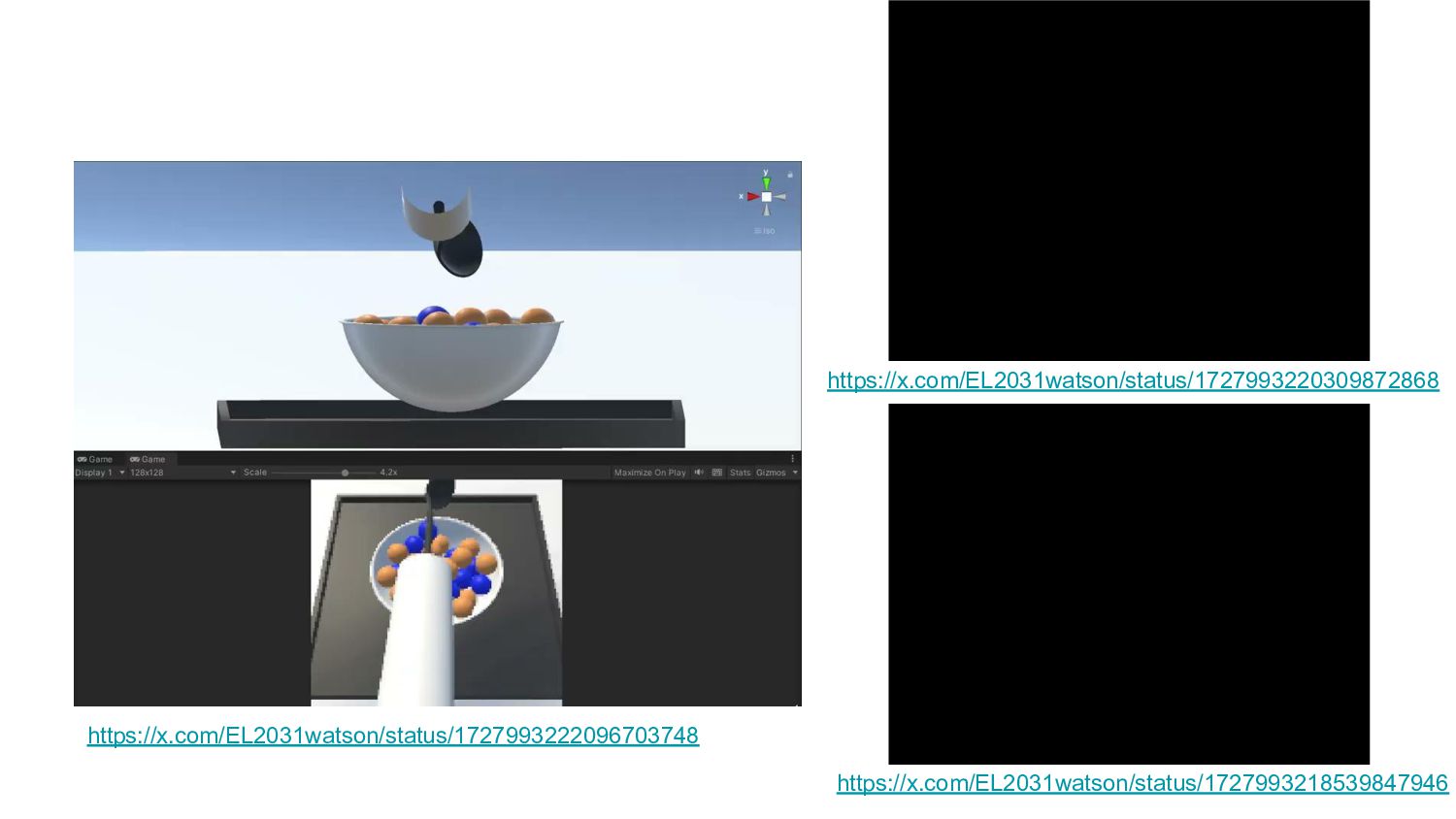
https://x.com/EL2031watson/status/1727993222096703748 https://x.com/EL2031watson/status/1727993220309872868 https://x.com/EL2031watson/status/1727993218539847946
シミュレーションから実ロボットへ 特定の色・物体を避けながら必要な物体を取り出すタスク (おでん、異物除去等?) →ルールベースでもできなくはなさそうだが結構大変そう コーヒー豆の中に枝豆が混入してしまった際に拾い上げるタスクにチャレンジ
データセットの取得 { "date": "2023-09-27_14-52-07", "info": [ { "count": 0, "time":
0.0, "position": [ 0.189421967, -0.084732452, 0.298651855, -2.578459, -0.878688, -0.549324 ], "angle": [ -0.572315, -0.092542, 0.730648, 0.659826, 0.98231, -1.648518, 0.0 ] }, { …. UFACTORY Lite 6のTCPにスプーンを取り付け、 TCPと連動するRealSense T265を使ってスプーンで豆を掬う。動作 中は30fpsでRealSense D415のRGB画像も取得する。 T265 Lite 6 D415 ・train:495試行、validation124:試行。 ・各試行は200-600枚程度の画像とそれぞれの時点でのジョイント角情報を含む ・画像合計: train: 153990枚, val:36473枚 画像とジョイント(TCP位置) https://x.com/EL2031watson/status/1728007549860077869
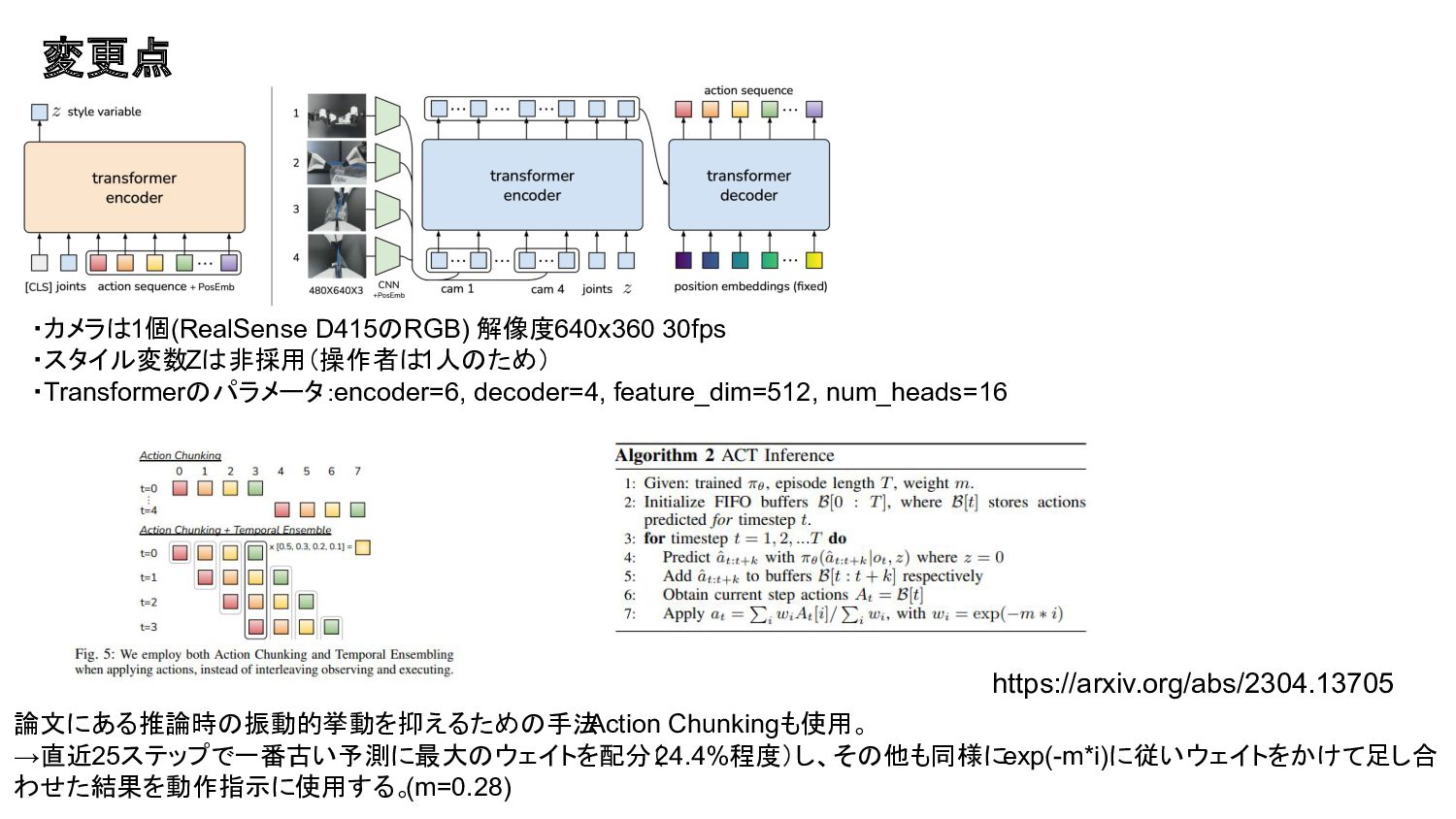
参考にした手法 https://arxiv.org/abs/2304.13705 ViperX 300(Follower)をWidowX 250(Leader)で操作する ALOHAというOSSプロジェクトの論文。 ALOHA: 低価格ロボットデータ収集ツール 学習は複数視点のRGB画像とアームロボットのジョイント角を 入力として、nステップ先までのジョイント角を出力とした
Transformerモデル。 →シンプルなBehaviour Cloningと呼ばれる模倣学習 L1 Lossを使用。 作業者の動作の癖を吸収するためにスタイル変数Zを導入 https://www.trossenrobotics.com/viperx-300-robot-arm-6dof.aspx ViperX 300 Robot Arm 6DOF
変更点 ・カメラは1個(RealSense D415のRGB) 解像度640x360 30fps ・スタイル変数Zは非採用(操作者は1人のため) ・Transformerのパラメータ:encoder=6, decoder=4, feature_dim=512, num_heads=16
論文にある推論時の振動的挙動を抑えるための手法 Action Chunkingも使用。 →直近25ステップで一番古い予測に最大のウェイトを配分( 24.4%程度)し、その他も同様に exp(-m*i)に従いウェイトをかけて足し合 わせた結果を動作指示に使用する。 (m=0.28) https://arxiv.org/abs/2304.13705
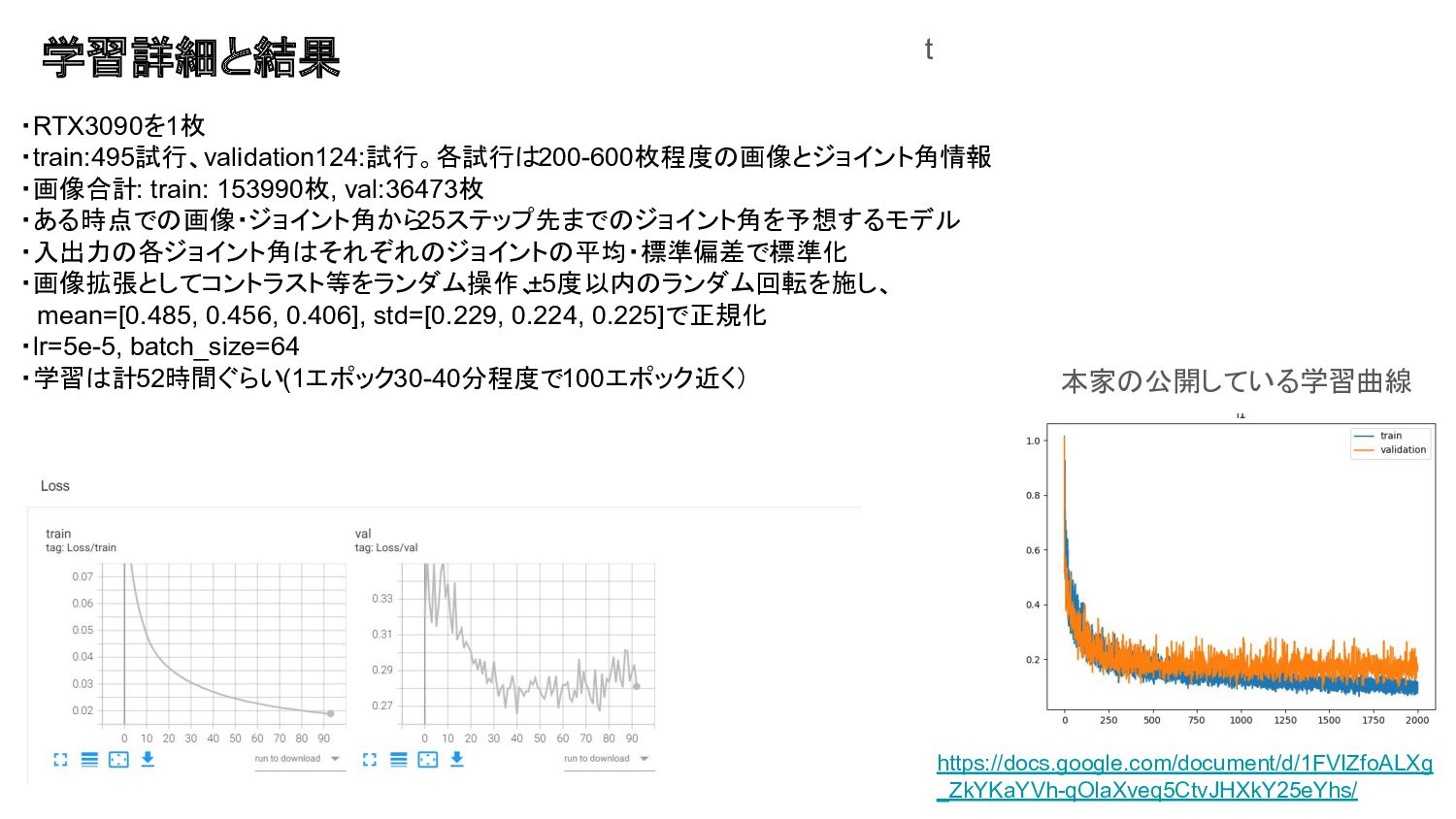
学習詳細と結果 ・RTX3090を1枚 ・train:495試行、validation124:試行。各試行は200-600枚程度の画像とジョイント角情報 ・画像合計: train: 153990枚, val:36473枚 ・ある時点での画像・ジョイント角から 25ステップ先までのジョイント角を予想するモデル ・入出力の各ジョイント角はそれぞれのジョイントの平均・標準偏差で標準化
・画像拡張としてコントラスト等をランダム操作、 ±5度以内のランダム回転を施し、 mean=[0.485, 0.456, 0.406], std=[0.229, 0.224, 0.225]で正規化 ・lr=5e-5, batch_size=64 ・学習は計52時間ぐらい(1エポック30-40分程度で100エポック近く) https://docs.google.com/document/d/1FVIZfoALXg _ZkYKaYVh-qOlaXveq5CtvJHXkY25eYhs/ 本家の公開している学習曲線 t
推論の様子 https://x.com/EL2031watson/status/1727993216564335025
他に試したこと ・TCPの6次元の予測(x, y, z, rx, ry, rz ただし回転は単位回転軸ベクトルに回転量をかけた軸角表現 ) →最初はTCP予測をしていたが、上手く行かずジョイント角予測に変えたが試行錯誤が足りなかっただけかもしれな
い。 ・予測する出力の形式を絶対量ではなく、変位の予測をする( RT-1等のいくつかの論文では変位予測になっている) →ML-Agentsではこの方法で上手く行ったが、今回は失敗。予測結果がずれた場合に誤差が時間ごとに蓄積して いって復帰不能になると論文にも記載されていた その他 試した方がいいかと思ったが試していないこと ・変位出力を離散化したものを予測 →RT-1はx,y,z,roll, pitch, yawそれぞれに関して256段階の予測を行う形式になっ ている
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}