damn APIs now!!!! ▪ 2-Way SMS APIs ▪ ~0 active clients ▪ ~0 API Calls Daily ▪ No product-market fit validation ▪ 2 Developers and 1 intern ▪ No venture capital cash
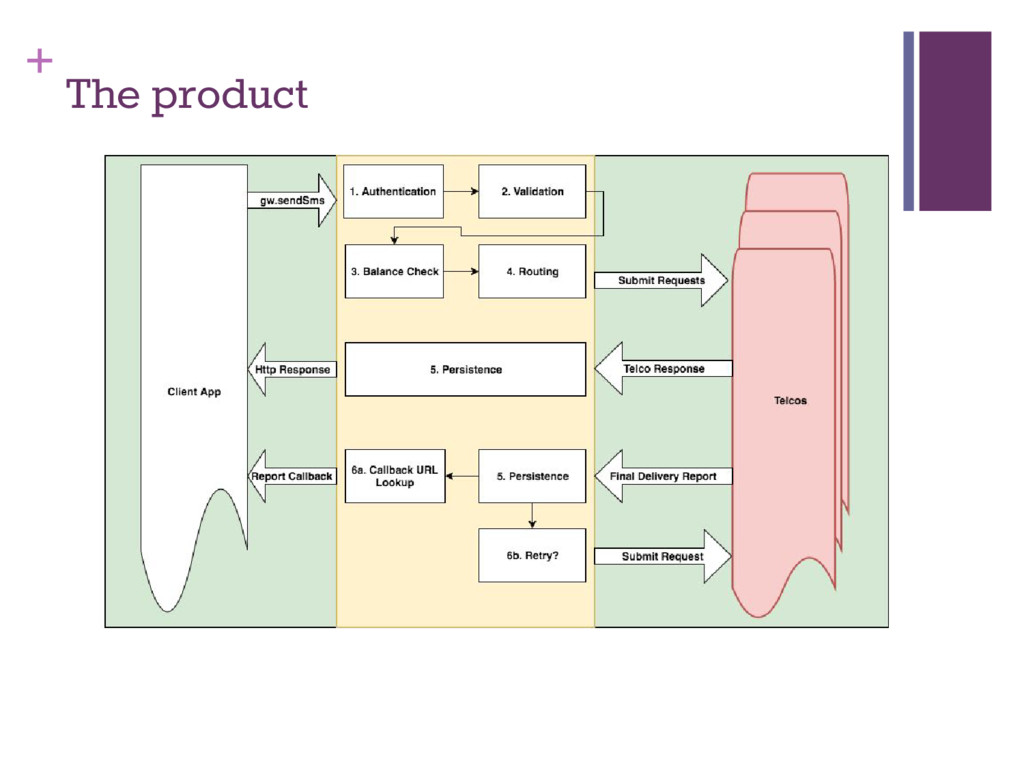
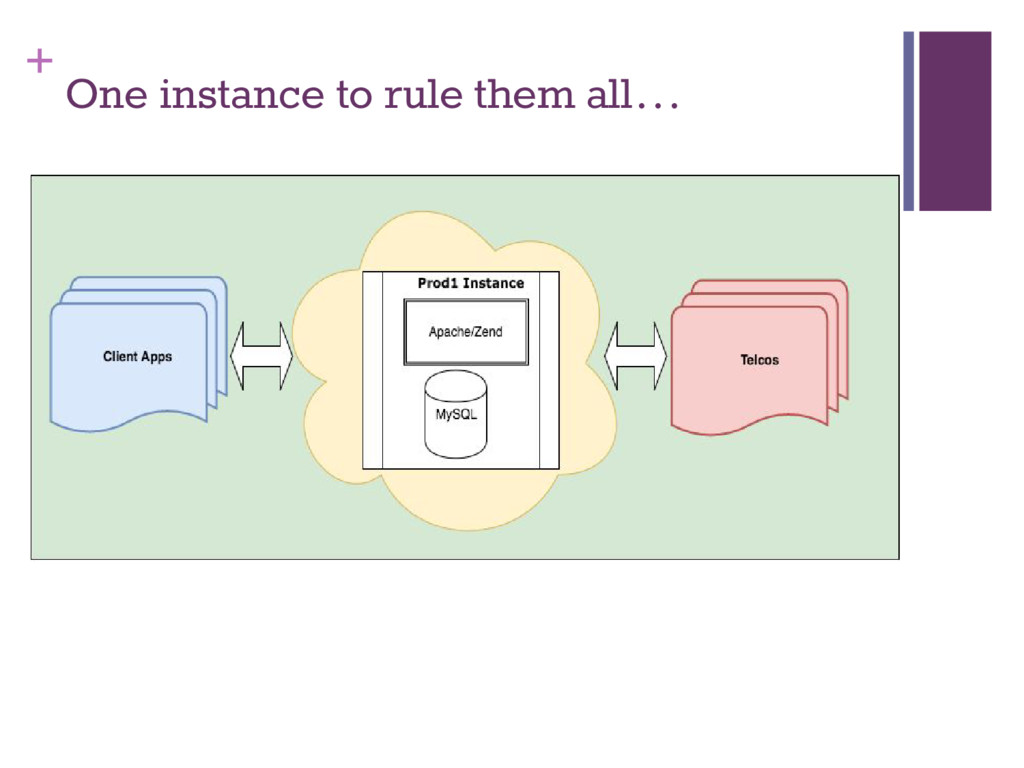
(we might need another one…) ▪ Rackspace since they are in the UK ▪ 1GB Instance ▪ Zend Application (who doesn’t know PHP?) ▪ POST to /version1/messaging controller for outgoing messages ▪ GET from /version1/messaging controller for incoming messages ▪ /gateway/safaricom/incoming-sms action for incoming messages ▪ /gateway/safaricom/dlr action for delivery reports ▪ /index controller for home, documentation and dashboards ▪ Mesh of wires in the office (to Yu and Safaricom)
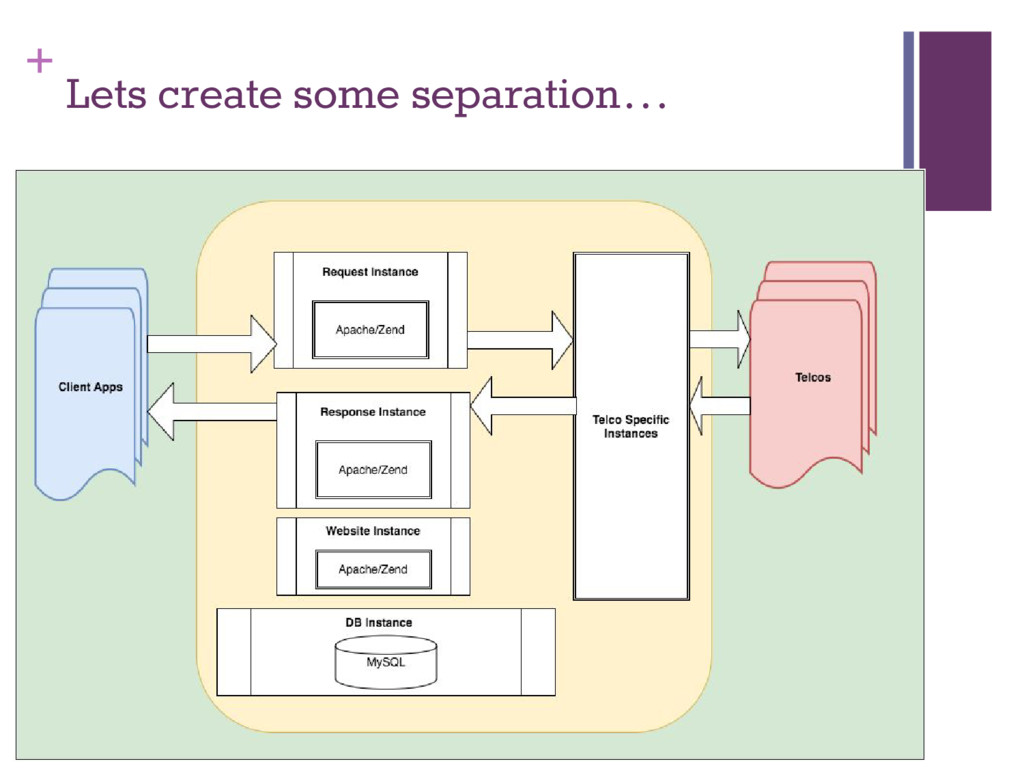
▪ Memory pressure from Apache/MySQL ▪ Increased to 4GB/4 VCPUs ▪ Separate Web Server, DB and Website ▪ Separate concerns ▪ Client Requests ▪ Telco Requests (Delivery reports, Incoming SMS) ▪ Abstract out telco-specific logic into separate instances
▪ 100 max number of concurrent calls based on 4GB Rule ▪ Only option is to scale up given “threading support” in PHP ▪ Long-running Requests ▪ Introduced enqueue parameter for clients ▪ Not enforced, just highly encouraged. Largest consumers were internal ▪ Long running Response Callbacks ▪ Client servers could be slow or unavailable ▪ Enqueue all telco requests and run cron jobs to clean up
▪ Ever-growing DB tables ▪ Clean up old record using cron jobs ▪ Profiler to figure out smart indexing and querying ▪ Scaling up RAM ▪ No analytics ▪ Lock contention ▪ Billing & queue status updates ▪ Reduced throughput ▪ No TTL for records ▪ Cron jobs to clean up old/unnecessary records ▪ Not effective for caching
queue processors to python (twisted framework) ▪ Increase number of workers on Apache ▪ Testing burden with increased complexity ▪ No compiler ▪ Duck typing is NOT your friend any more ▪ Enforced standards amongst the 2 developers ☺ ▪ No shared state without involving a database ▪ Limited application state
grinding to a halt ▪ SMS Table had over 300 Million entries ▪ Cleanup jobs took a week ▪ Updates would take minutes ▪ Dashboard queries were hanging ▪ Deluge of client and telco requests ▪ Lots of downtime and dropped requests ▪ All servers were using swap space, all the time ▪ Fund raising was not going so well….
rewrite the entire application and scale horizontally ▪ Re-evaluate every technical decision we had made up to that point ▪ Programming language ▪ Storage layer ▪ Web server ▪ Queuing ▪ Analytics ▪ Monitoring
model) ▪ Type safety ▪ OOP with functional goodness ▪ Testable to your heart’s content ▪ Java interoperability ▪ Growing developer community ▪ First class concurrency (Actor model)!!!
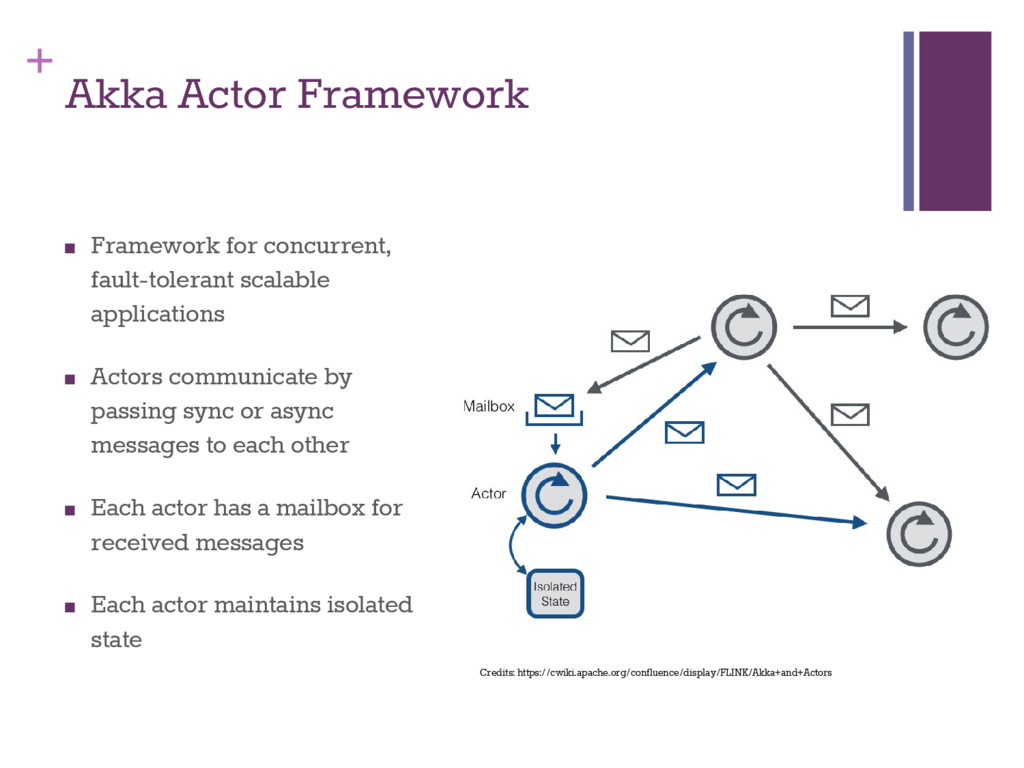
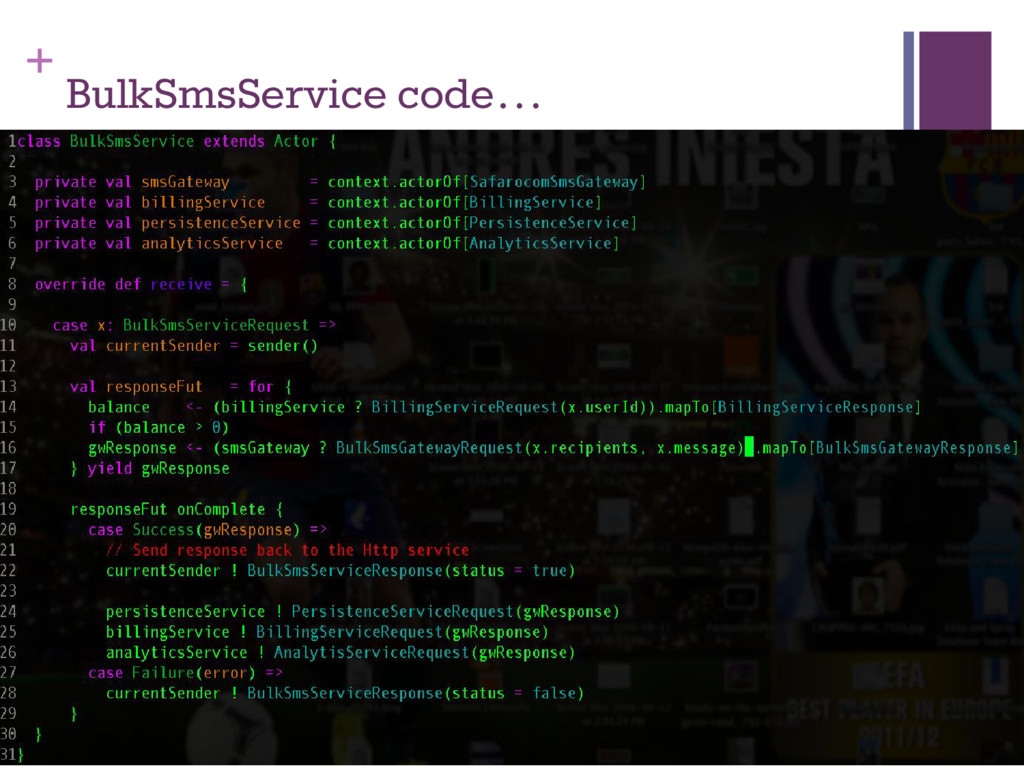
applications ▪ Actors communicate by passing sync or async messages to each other ▪ Each actor has a mailbox for received messages ▪ Each actor maintains isolated state Credits: https://cwiki.apache.org/confluence/display/FLINK/Akka+and+Actors
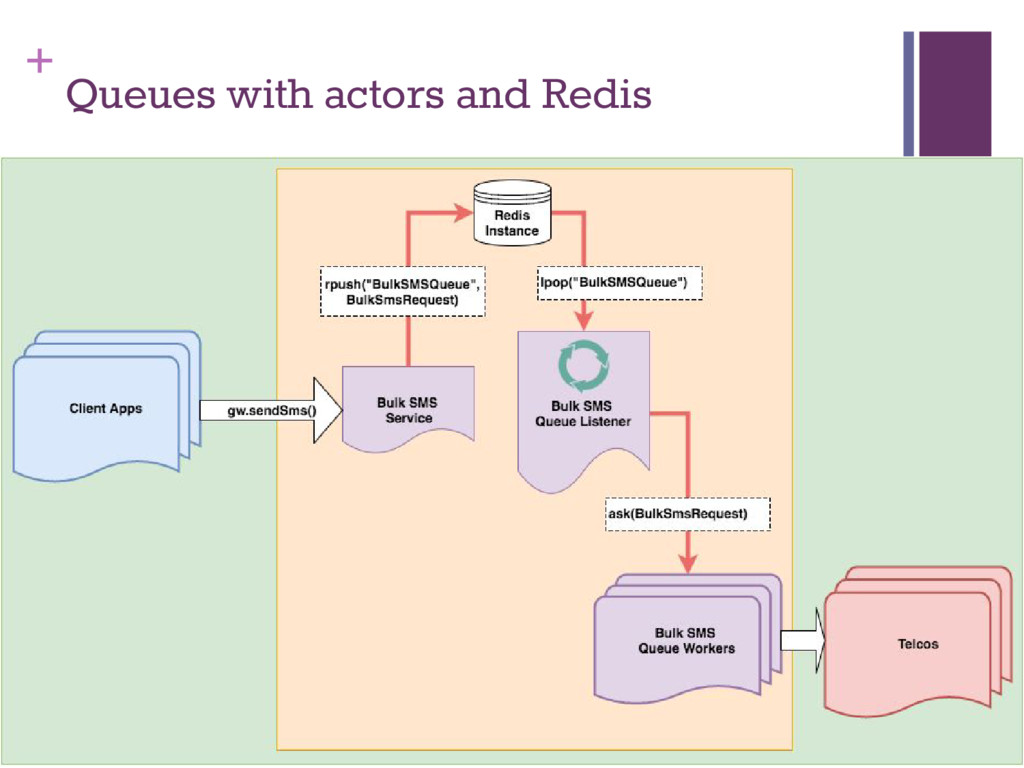
(could be 400+) ▪ Evenly distributed load across multiple processors ▪ Each actor processes messages sequentially ▪ No error prone locking and state management ▪ Even thought each actor is essentially single-threaded, a system of actors is highly concurrent and scalable ▪ Important: ensure no blocking calls in the critical path ▪ Small pool of actors for core business logic ▪ Army of workers for blocking network/io calls
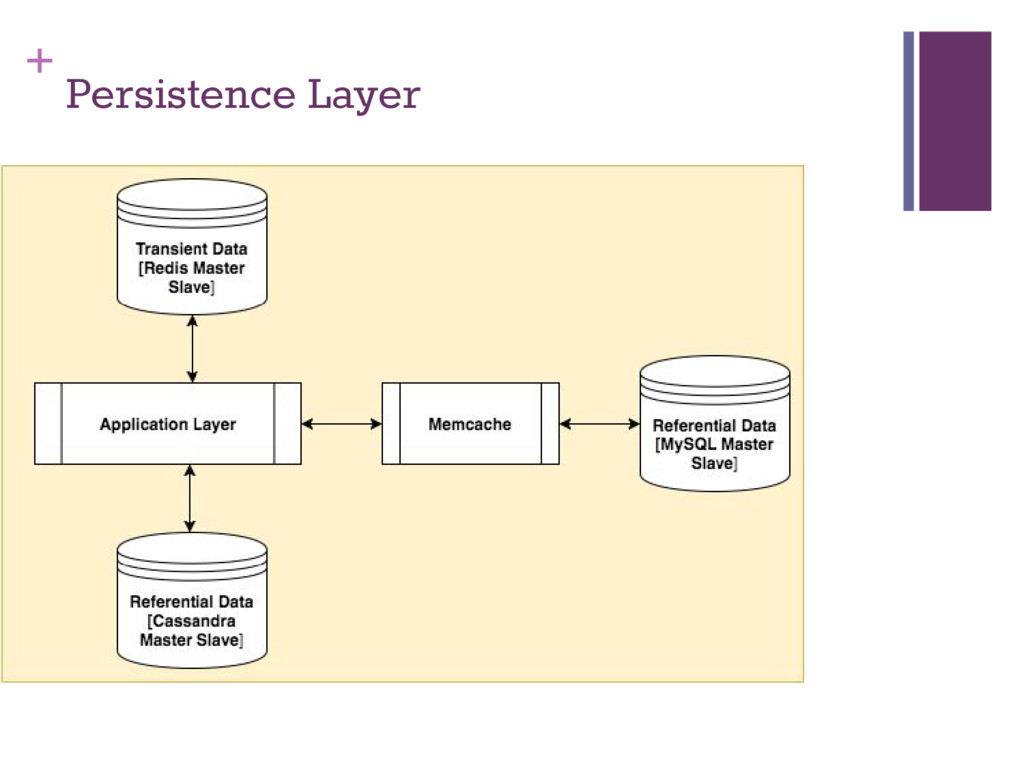
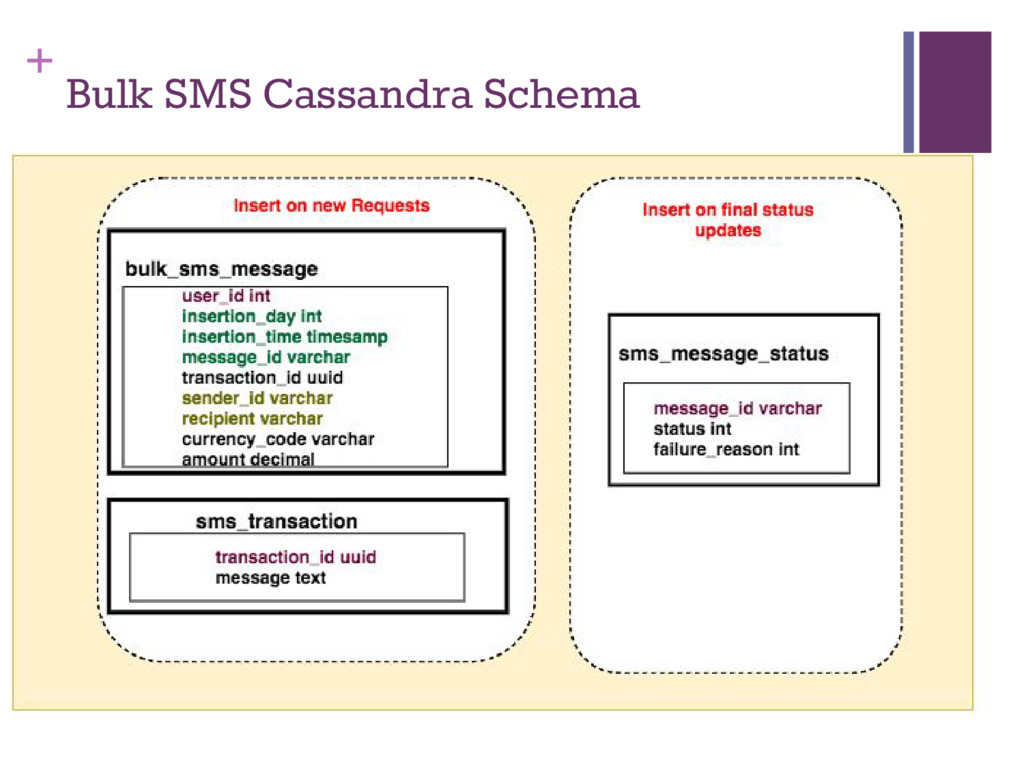
keys to distribute data with respect to access patterns ▪ Lookups should ideally only access one node ▪ Reduce lookups when writing in favor of inserts ▪ Write heavy loads ▪ Bulk SMS access: ▪ By userId ▪ Ordered by insertion time (latest first) ▪ Lookup by date ▪ Lookup by recipient and senderId
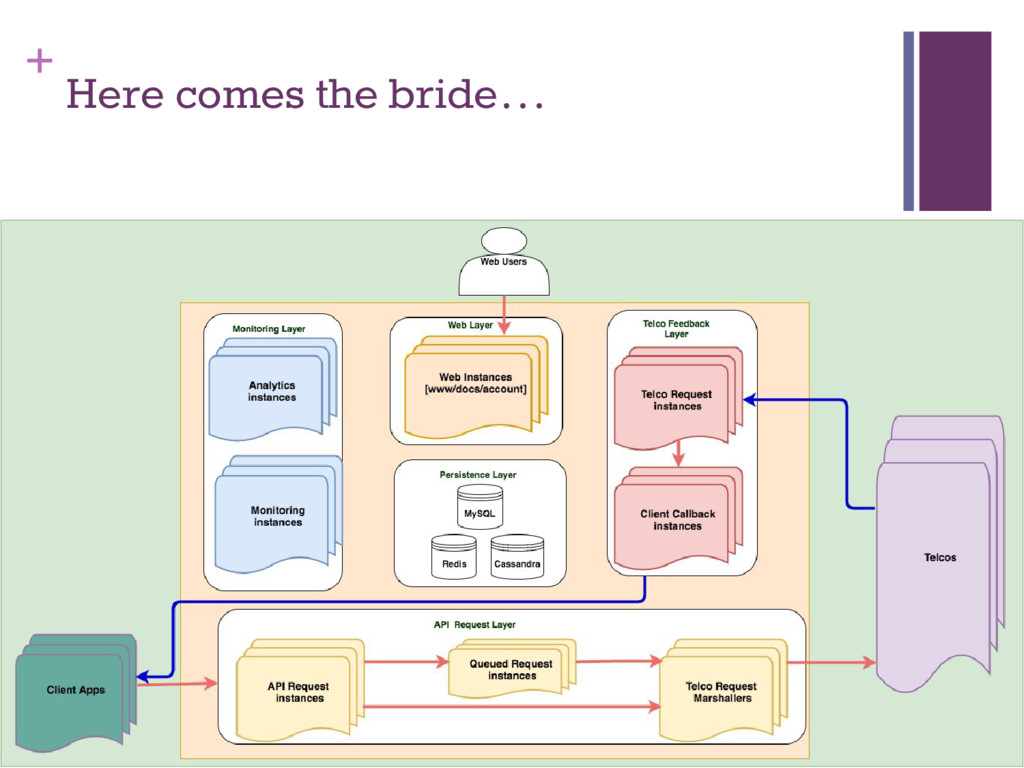
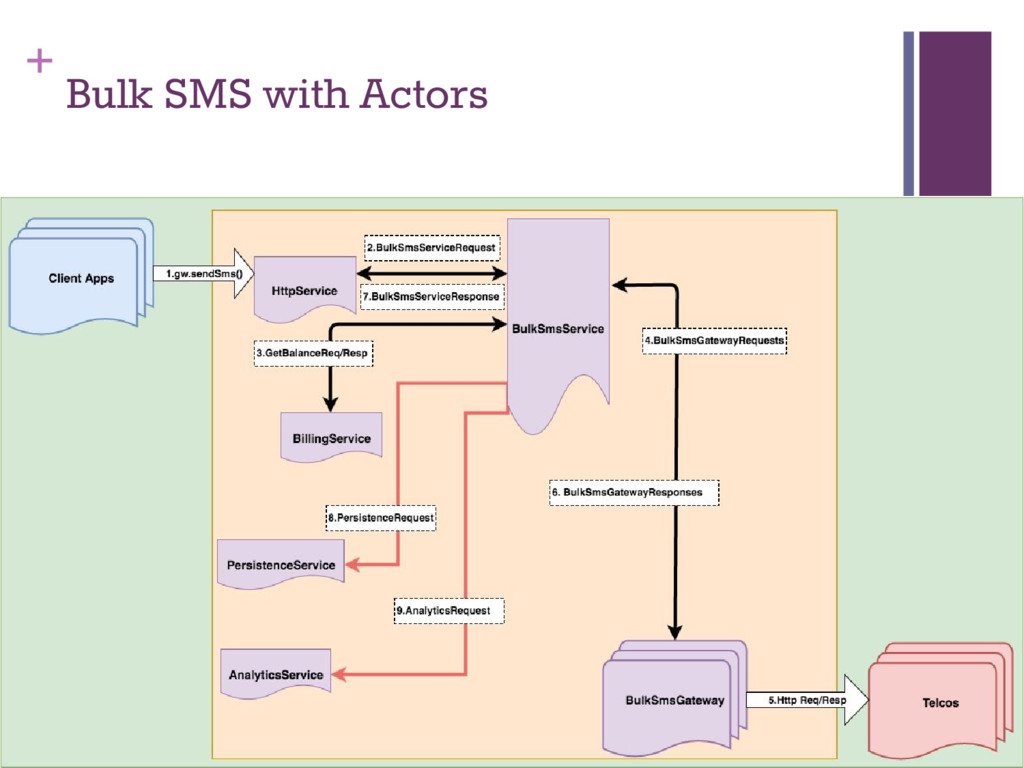
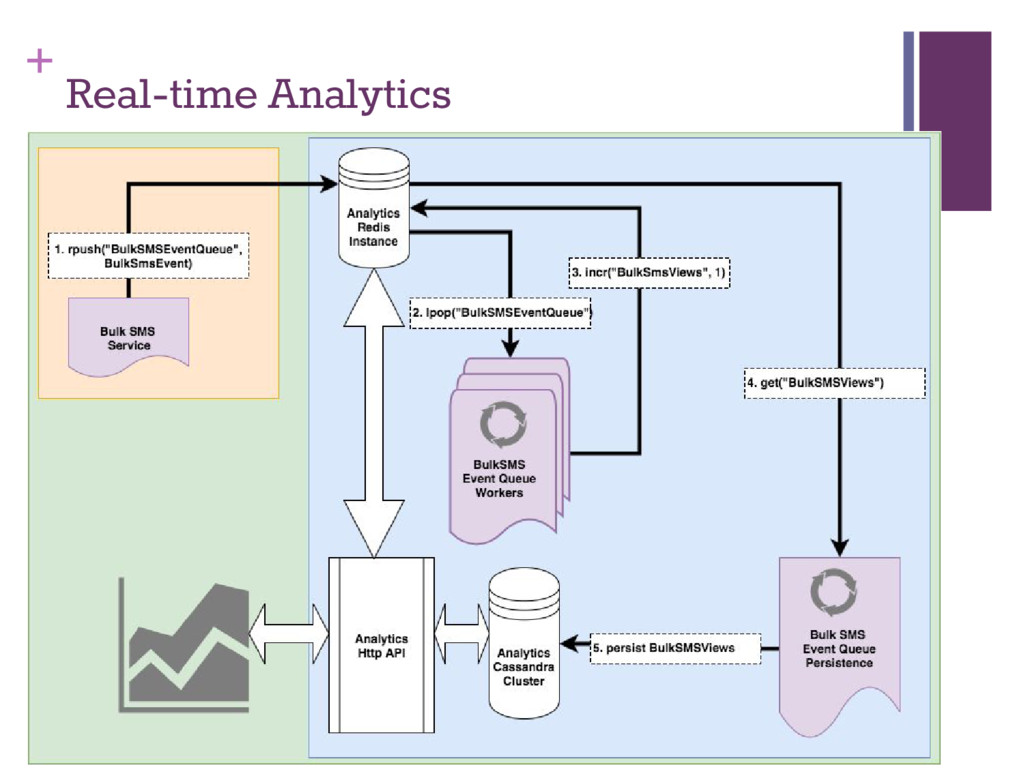
Manage growth ▪ Answer client requests ▪ Talk to investors ▪ Event-based Real-time analytics framework across all products ▪ Actors generate events (sendBulkSms, failedUssdHop) ▪ Events converted into views, bucketed by hour and day in Redis ▪ Views continuously stored in Cassandra ▪ API layer generated JSON views for display to clients
across 6 countries ▪ Hybrid solution to monitor at server, network and application layers ▪ Instant notifications over SMS/Email when things break ▪ Integration with client apps is wanting ▪ Configuration management ▪ Load-balanced servers ▪ Sandbox/production environment ▪ Currently evaluating solutions ▪ Security ▪ Enough said ▪ New products with different characteristics ▪ Voice/Video: real-time, network heavy, local hosting ▪ Payments: Acid transactions, robust error handling
if you HAVE TO (product-market fit) ▪ Use solutions that match your budget ▪ Control as much of the stack as you can ▪ Buys you speed and flexibility as you grow ▪ Build on the shoulders of (free) giants ▪ Open source where possible ▪ Small, agile teams rule ▪ Find good talent and throw hard problems at it ▪ Apply the same thinking into growing the business ▪ Nothing beats a tech background on the hot seat
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}