Python has lots of scientific, data analysis, and machine learning libraries. But there are many problems when starting out on a machine learning project. Which library do you use? How do they compare to each other? How can you use a model that has been trained in your production application?
TensorFlow is a new Open-Source framework created at Google for building Deep Learning applications. Tensorflow allows you to construct easy to understand data flow graphs in Python which form a mathematical and logical pipeline. Creating data flow graphs allow easier visualization of complicated algorithms as well as running the training operations over multiple hardware GPUs in parallel.
In this talk I will discuss how you can use TensorFlow to create Deep Learning applications. I will discuss how it compares to other Python machine learning libraries like Theano or Chainer. Finally, I will discuss how trained TensorFlow models could be deployed into a production system using TensorFlow Serve.
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![Google Cloud Platform 6 ["cat"] Input Hidden Output(label) pixels( )](https://files.speakerdeck.com/presentations/d912b632b8ef4e69a1705ffd27336a83/slide_5.jpg){kind=link}
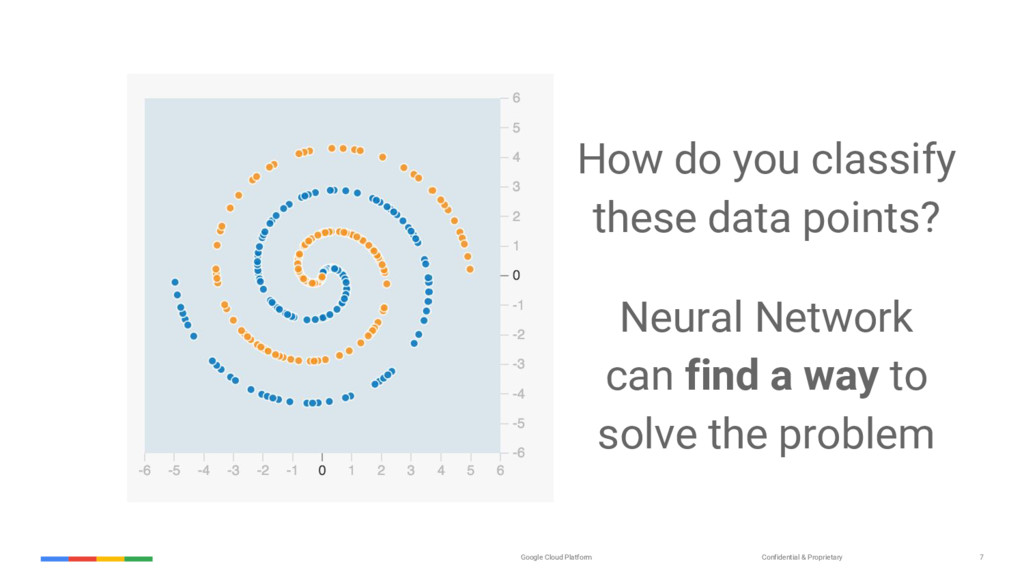{kind=link}
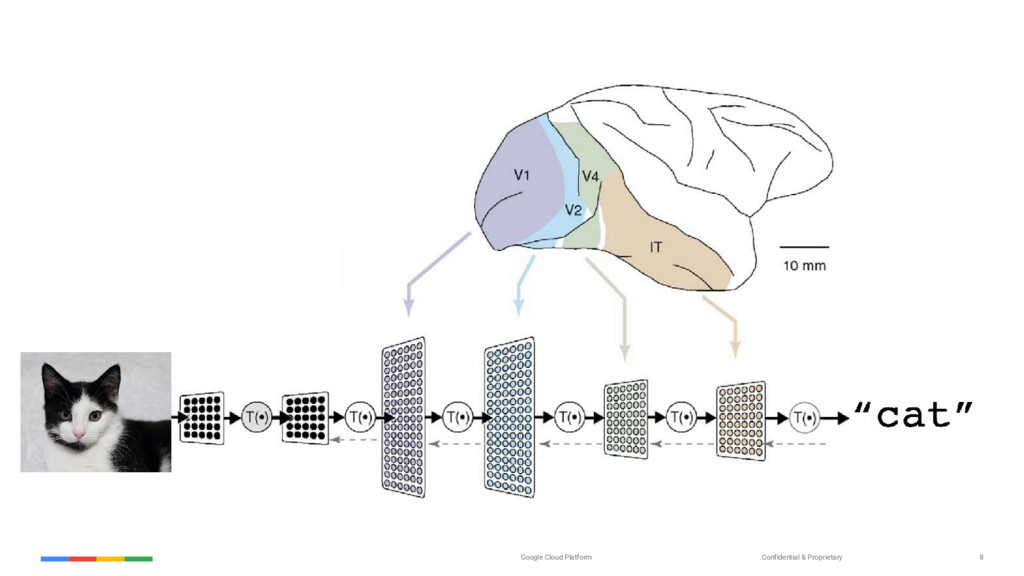{kind=link}
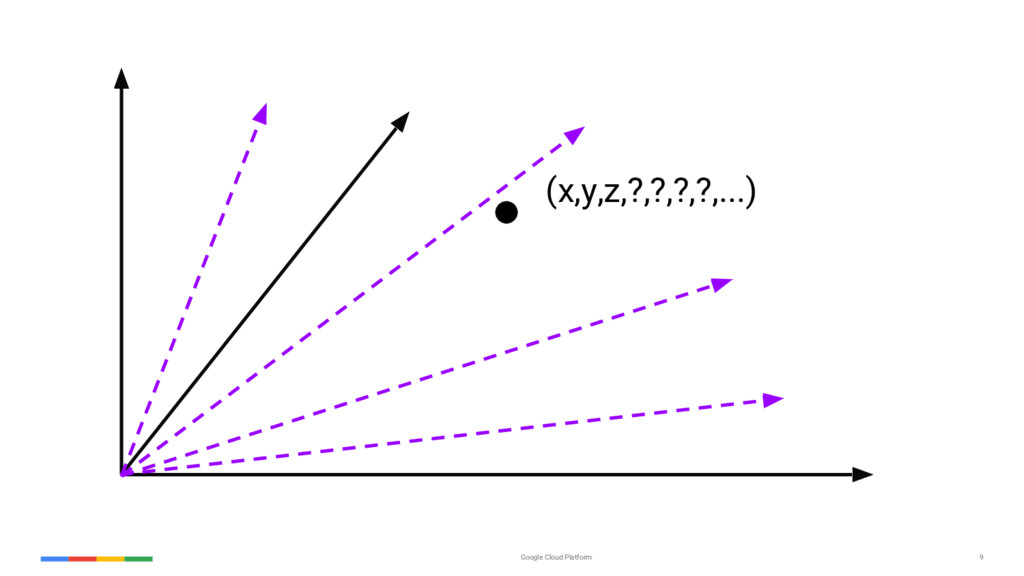{kind=link}
![Google Cloud Platform 10 v[x] => vector](https://files.speakerdeck.com/presentations/d912b632b8ef4e69a1705ffd27336a83/slide_9.jpg){kind=link}
![Google Cloud Platform 11 m[x][y][z] => matrix](https://files.speakerdeck.com/presentations/d912b632b8ef4e69a1705ffd27336a83/slide_10.jpg){kind=link}
![Google Cloud Platform 12 t[x][y][z][?][?]... => tensor](https://files.speakerdeck.com/presentations/d912b632b8ef4e69a1705ffd27336a83/slide_11.jpg){kind=link}
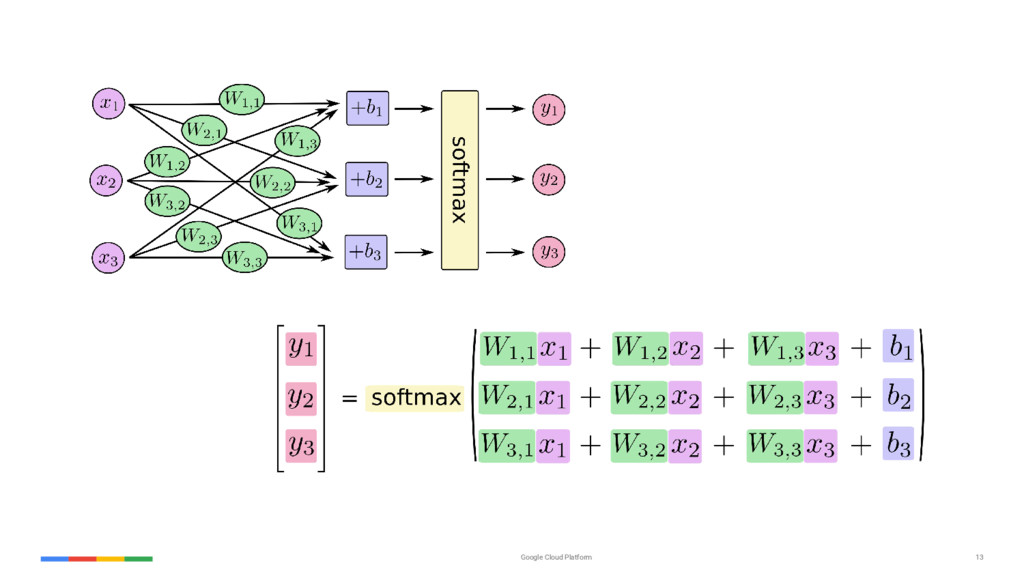{kind=link}
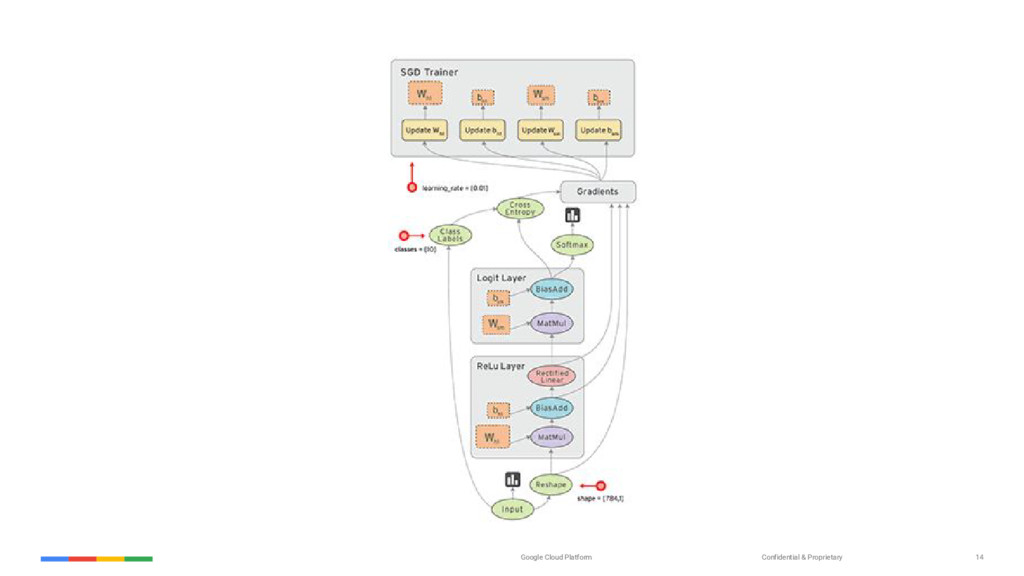{kind=link}
{kind=link}
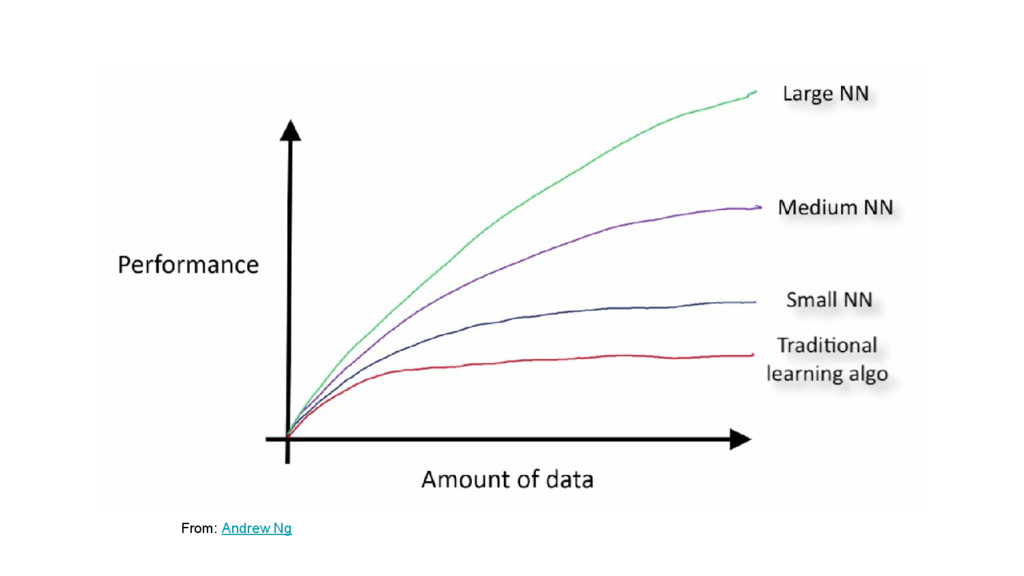{kind=link}
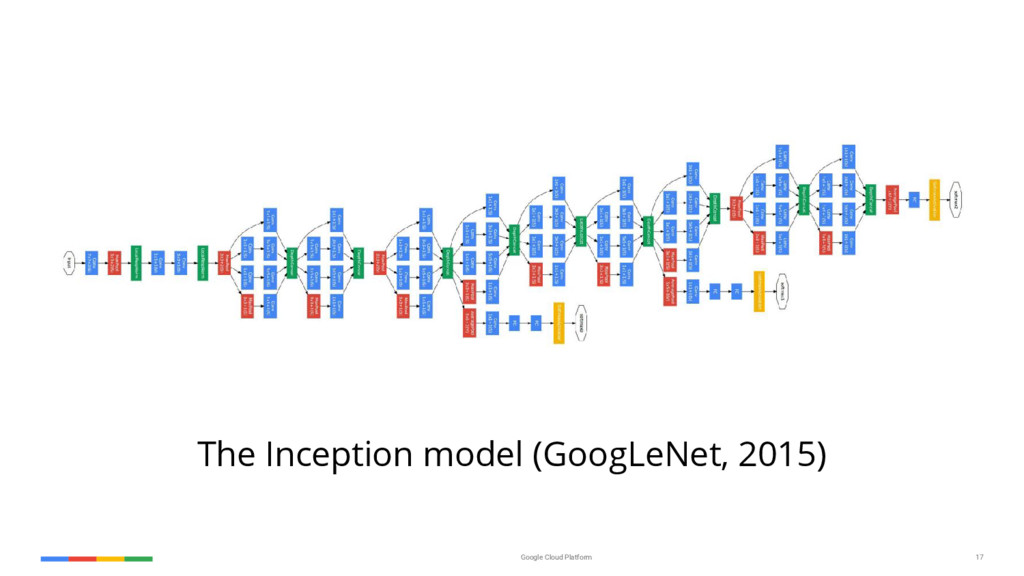{kind=link}
{kind=link}
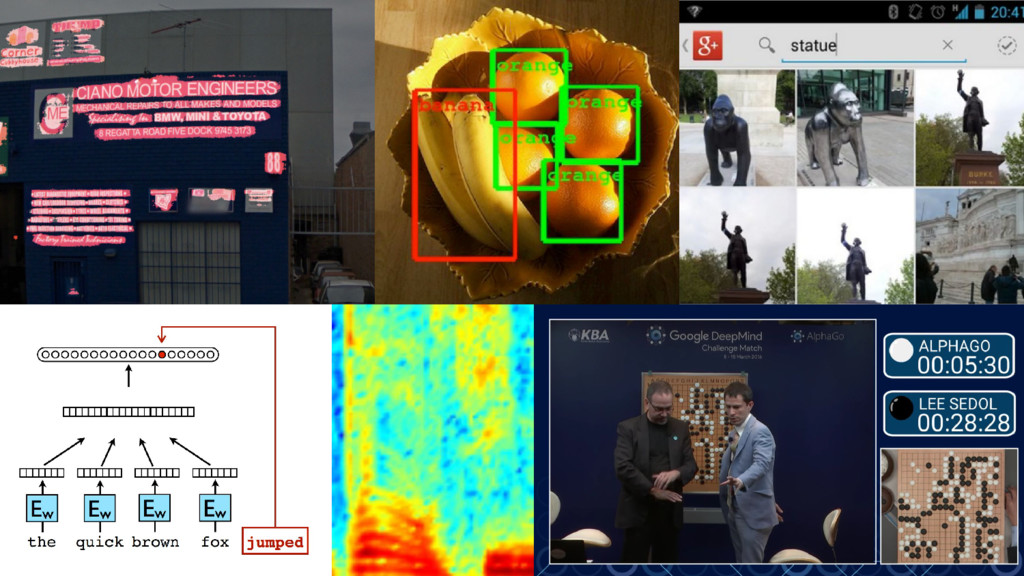{kind=link}
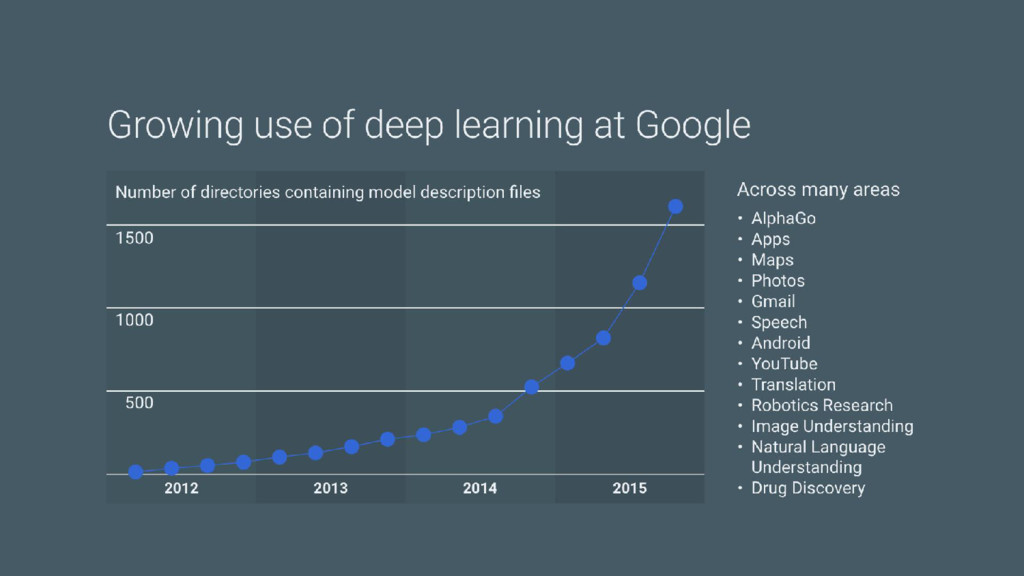{kind=link}
{kind=link}
{kind=link}
{kind=link}
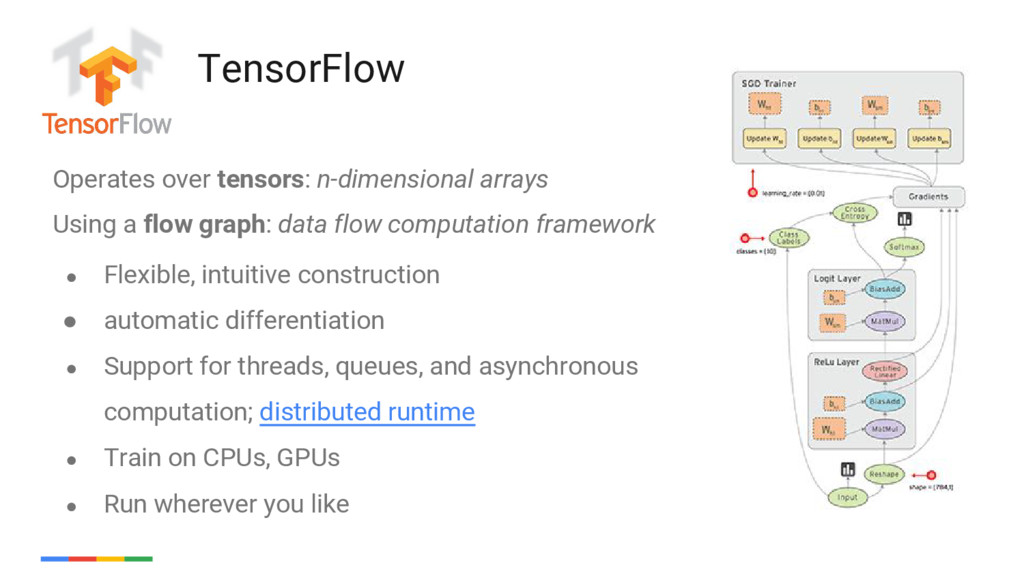{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
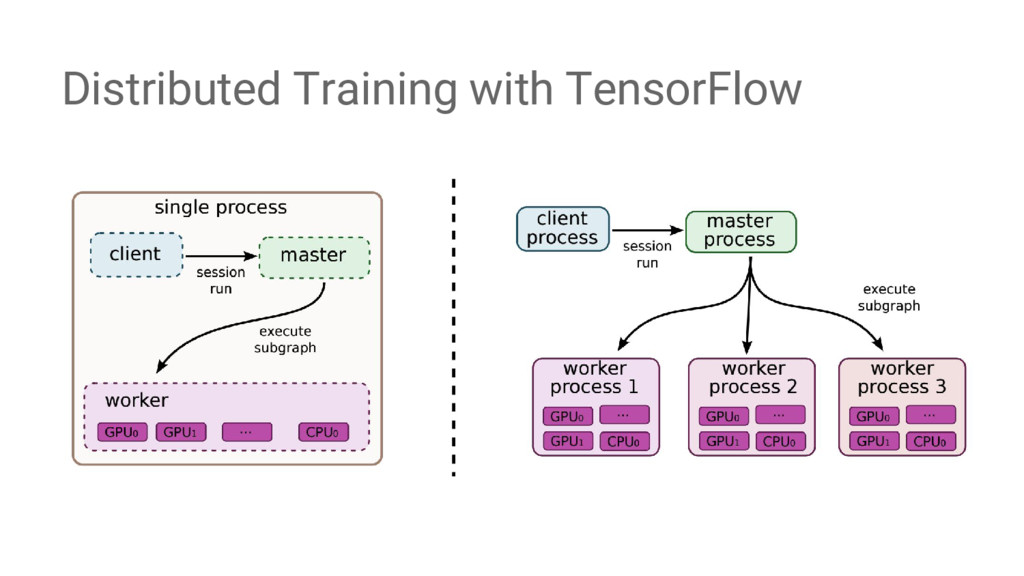{kind=link}
{kind=link}
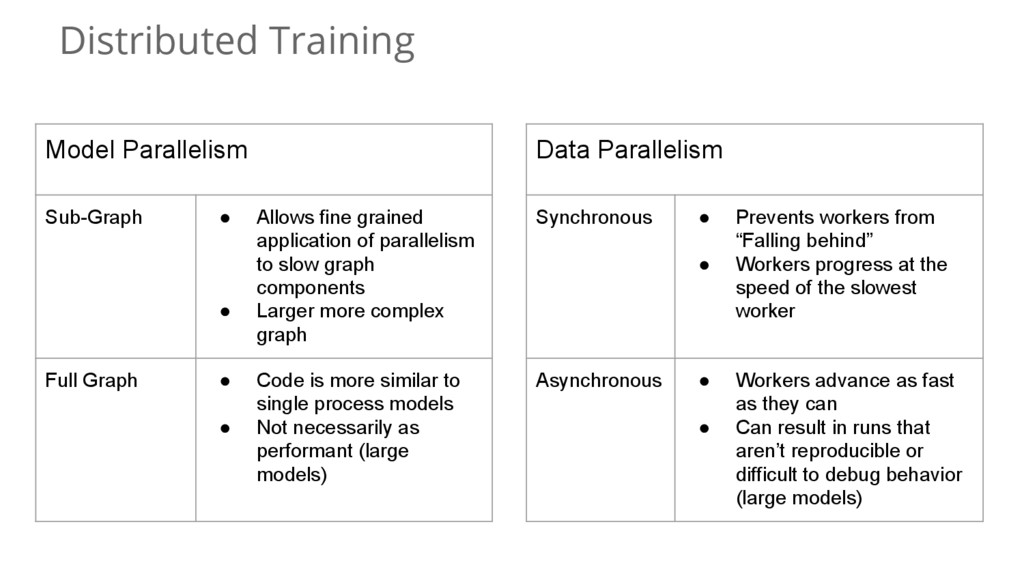{kind=link}
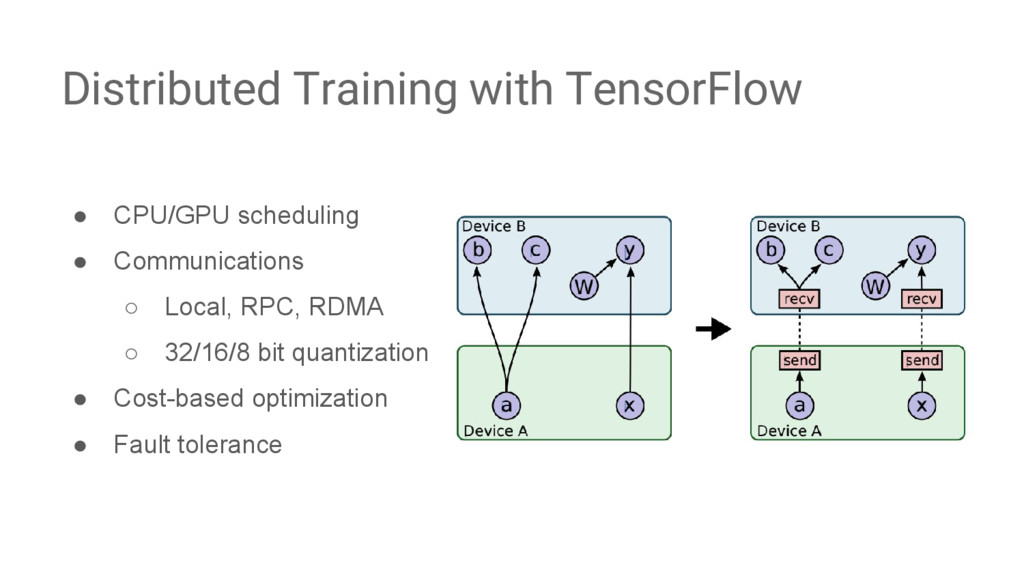{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
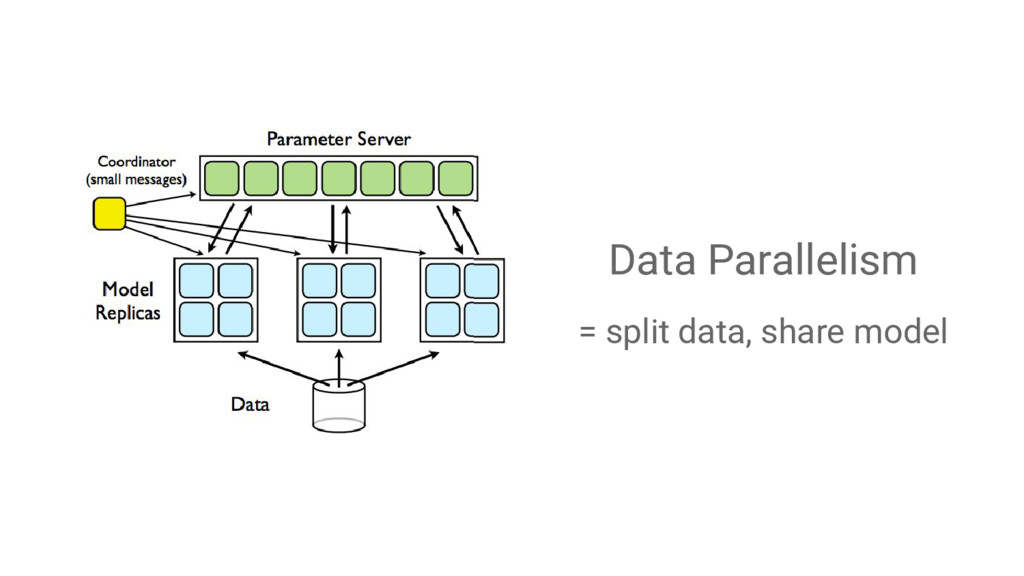{kind=link}
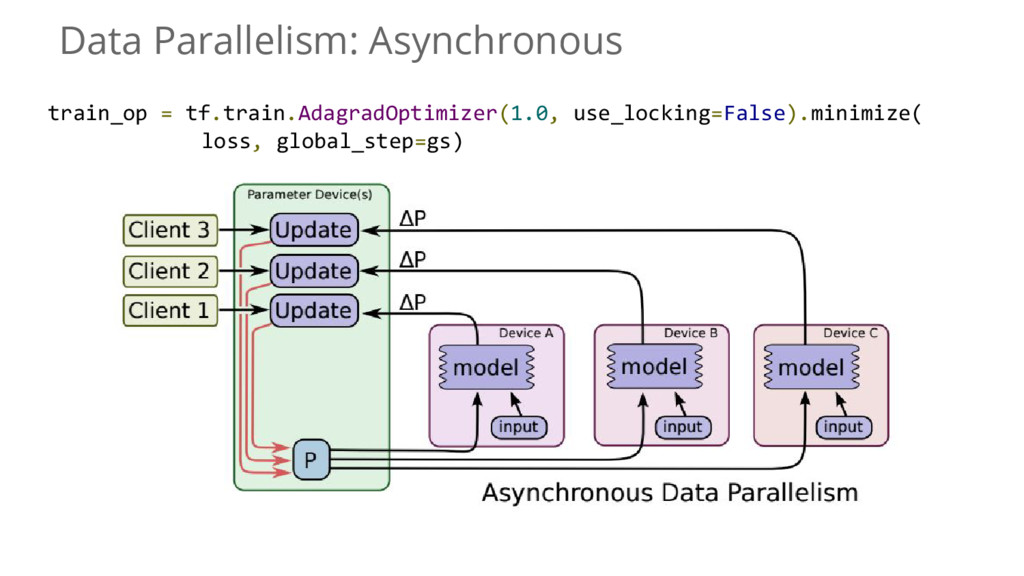{kind=link}
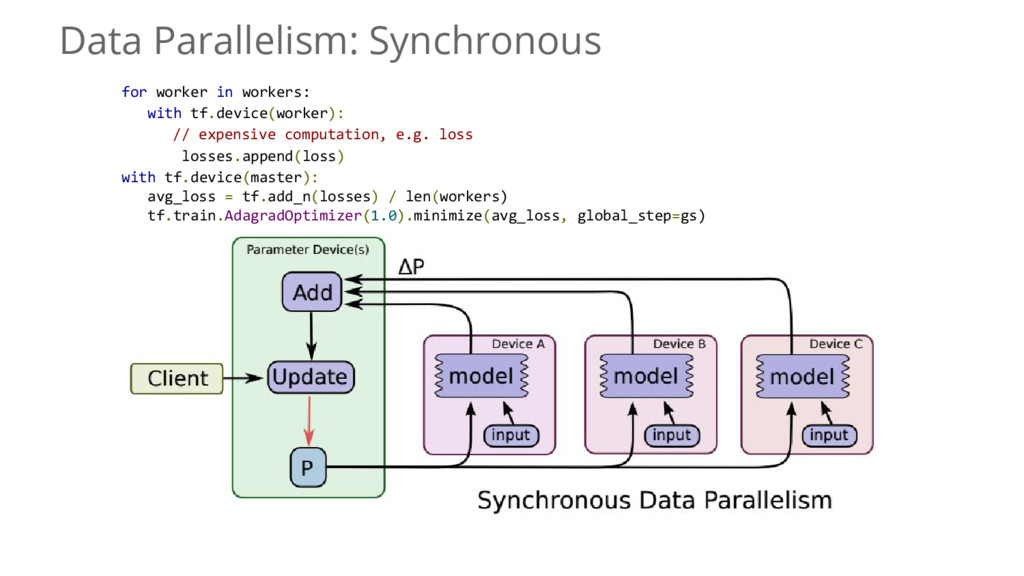{kind=link}
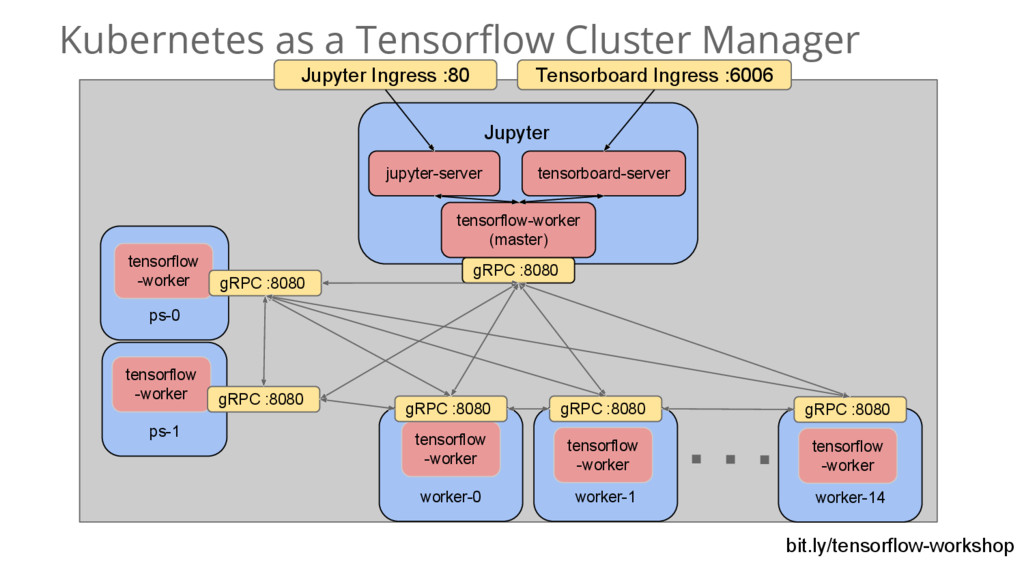{kind=link}
{kind=link}
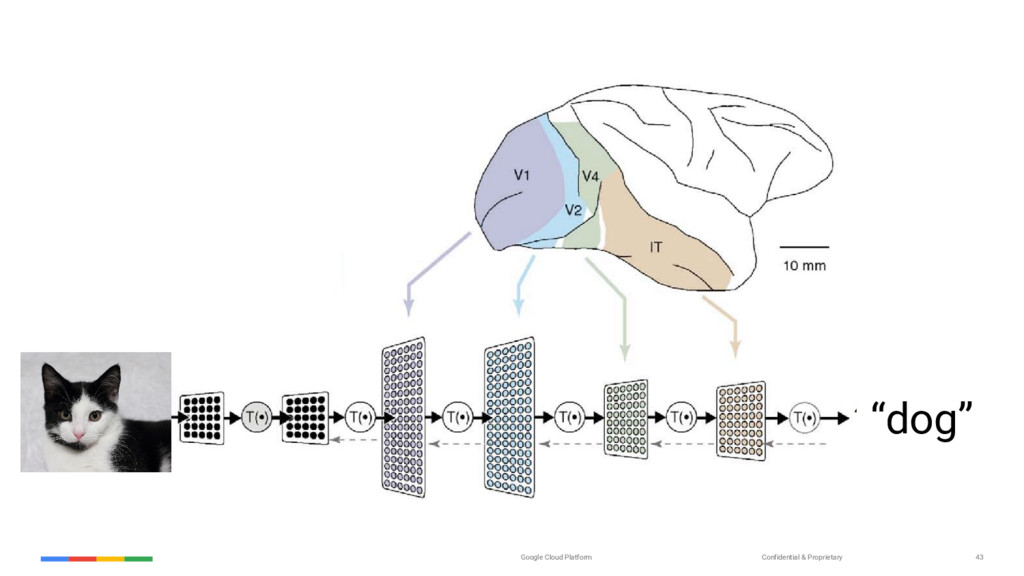{kind=link}
{kind=link}
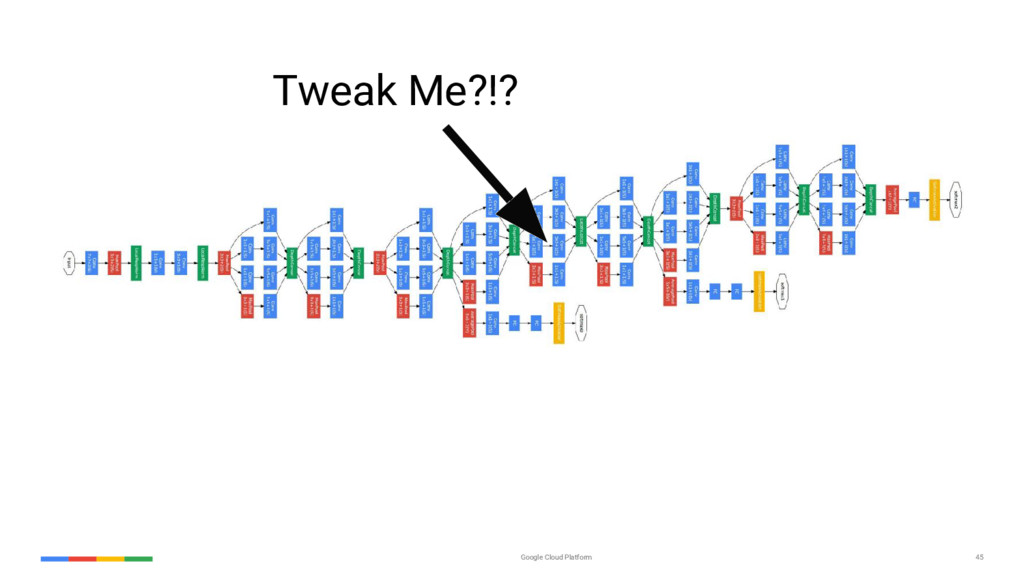{kind=link}
{kind=link}
{kind=link}
{kind=link}
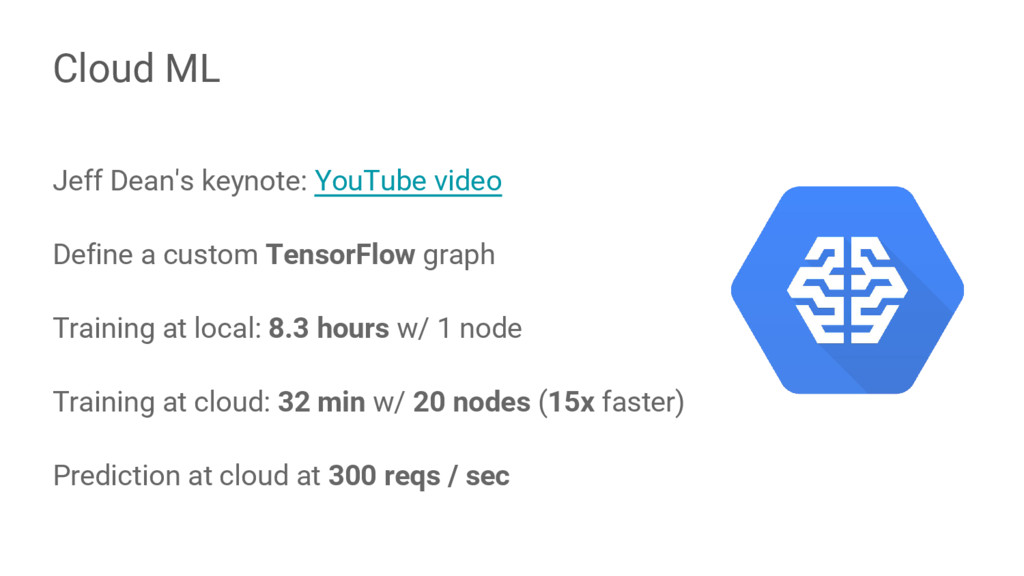{kind=link}
{kind=link}
{kind=link}