## Training # 1. Train a point forecast model model = LGBMRegressor().fit(X_train, y_train) # This can be any point forecast model Train Train Predict Hasson, 2021
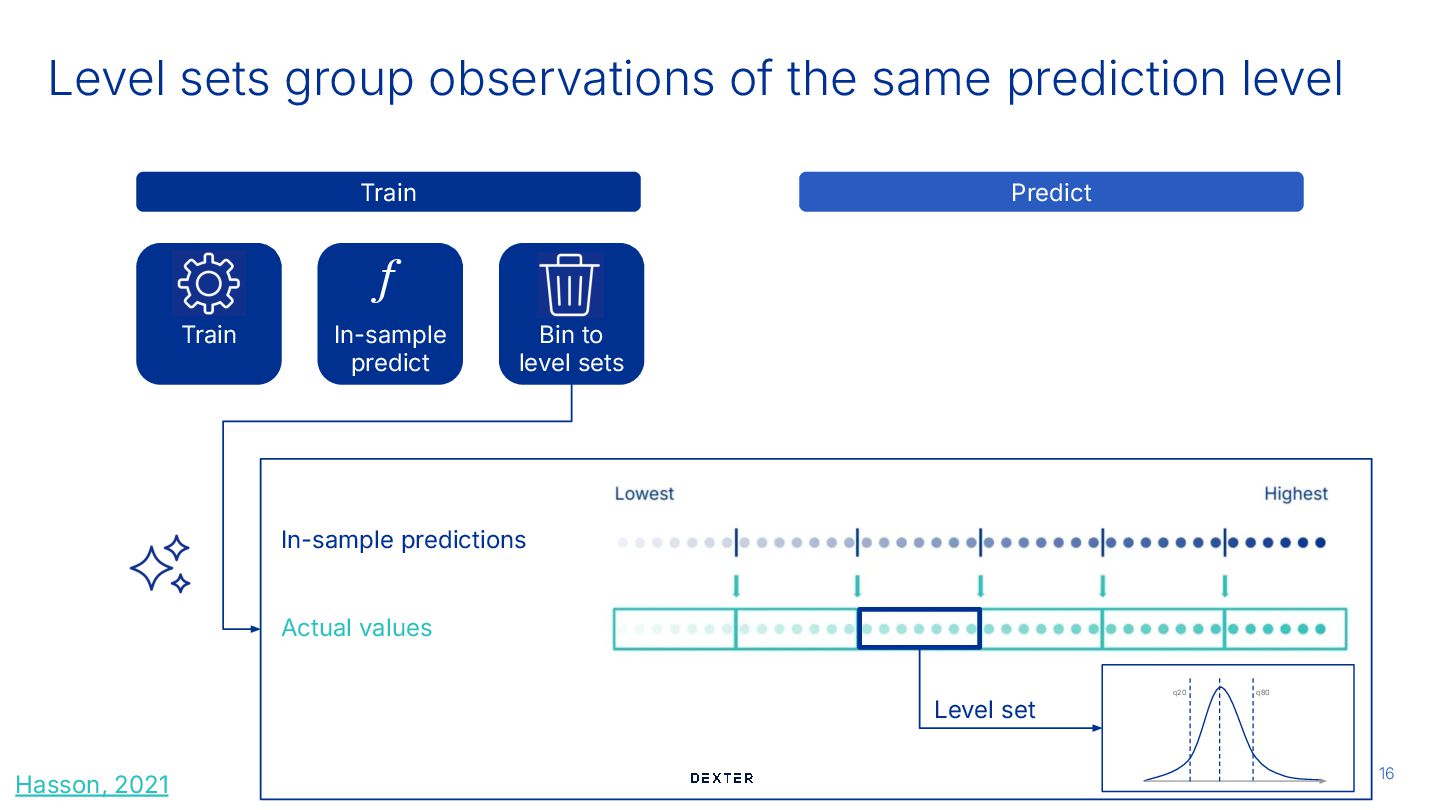
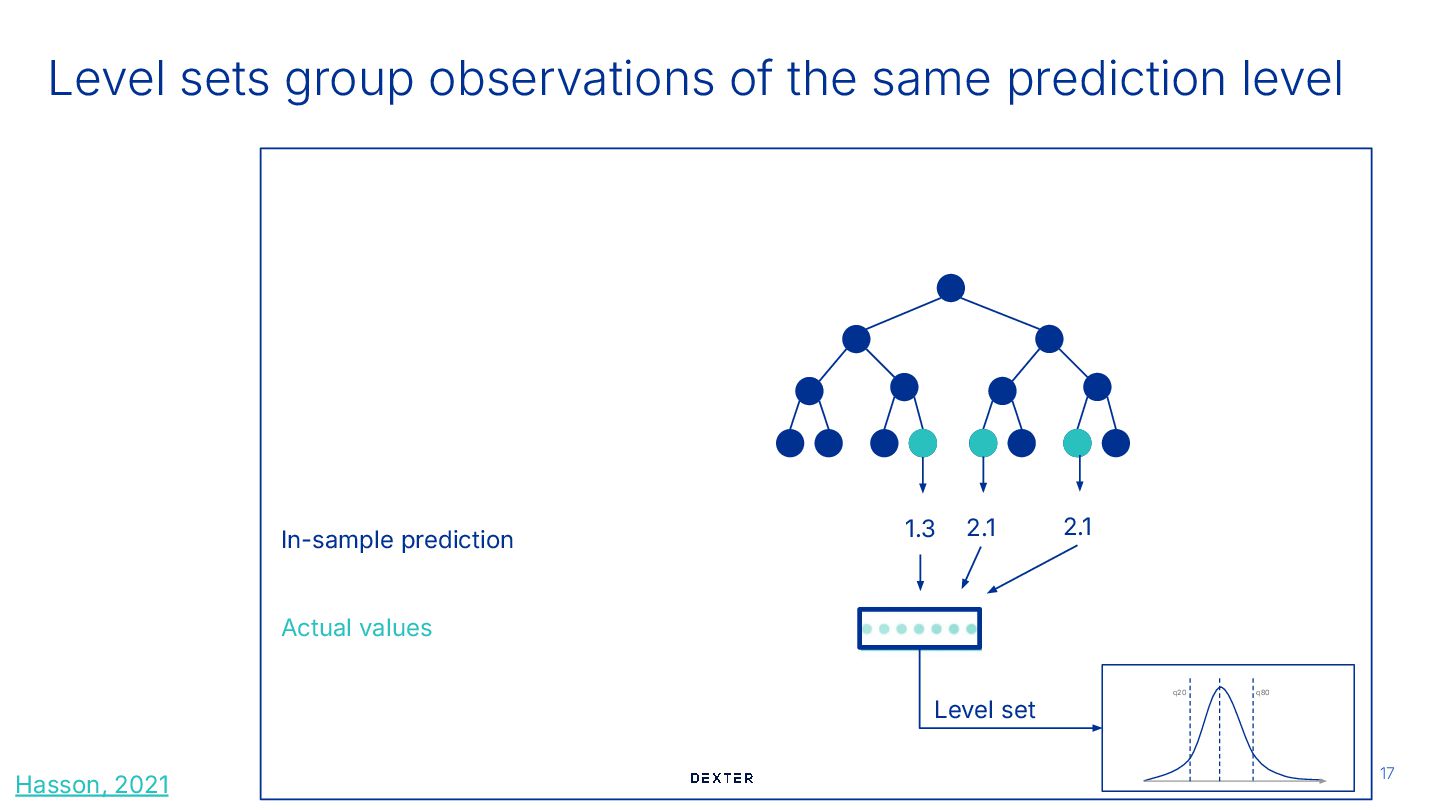
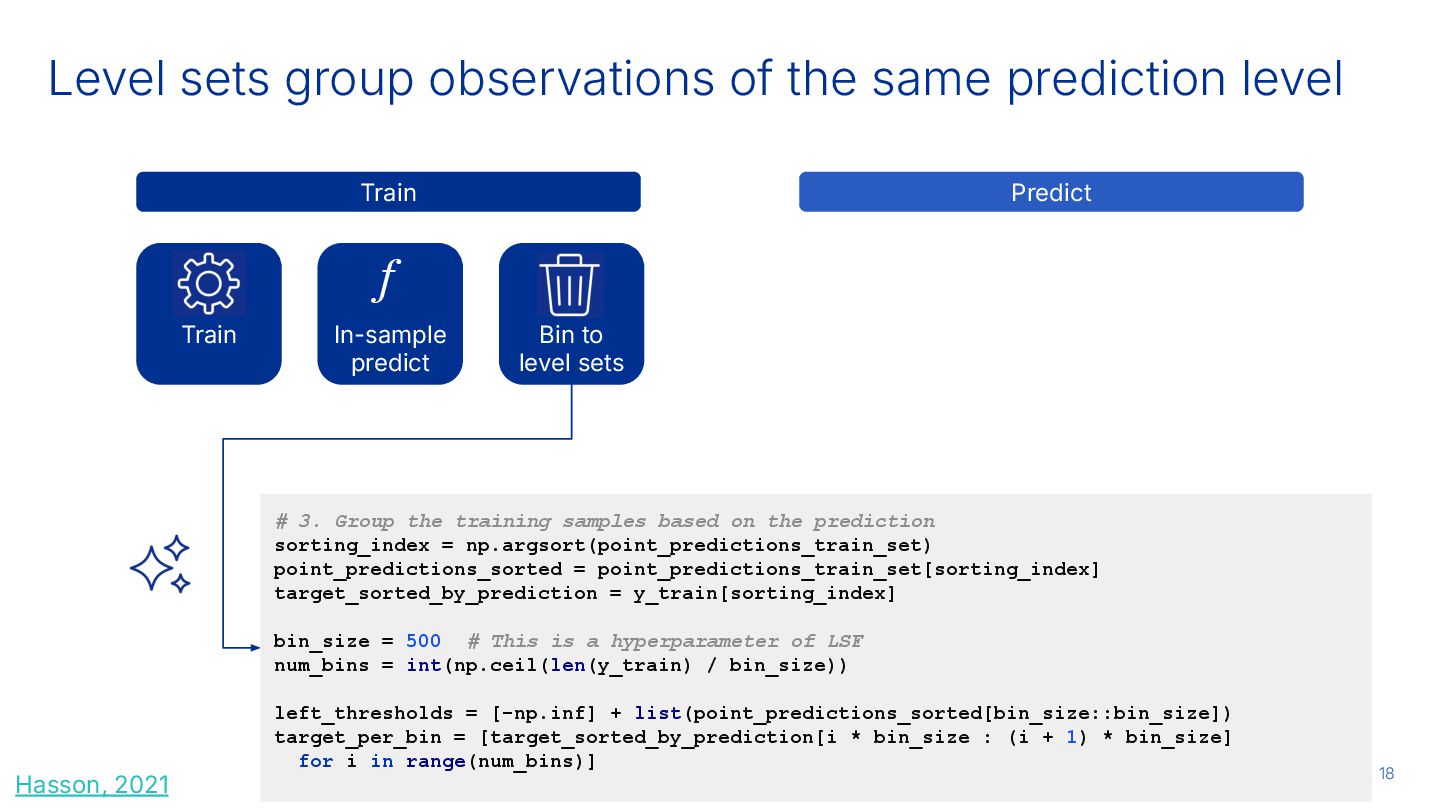
sets # 3. Group the training samples based on the prediction sorting_index = np.argsort(point_predictions_train_set) point_predictions_sorted = point_predictions_train_set[sorting_index] target_sorted_by_prediction = y_train[sorting_index] bin_size = 500 # This is a hyperparameter of LSF num_bins = int(np.ceil(len(y_train) / bin_size)) left_thresholds = [-np.inf] + list(point_predictions_sorted[bin_size::bin_size]) target_per_bin = [target_sorted_by_prediction[i * bin_size : (i + 1) * bin_size] for i in range(num_bins)] Hasson, 2021 Level sets group observations of the same prediction level
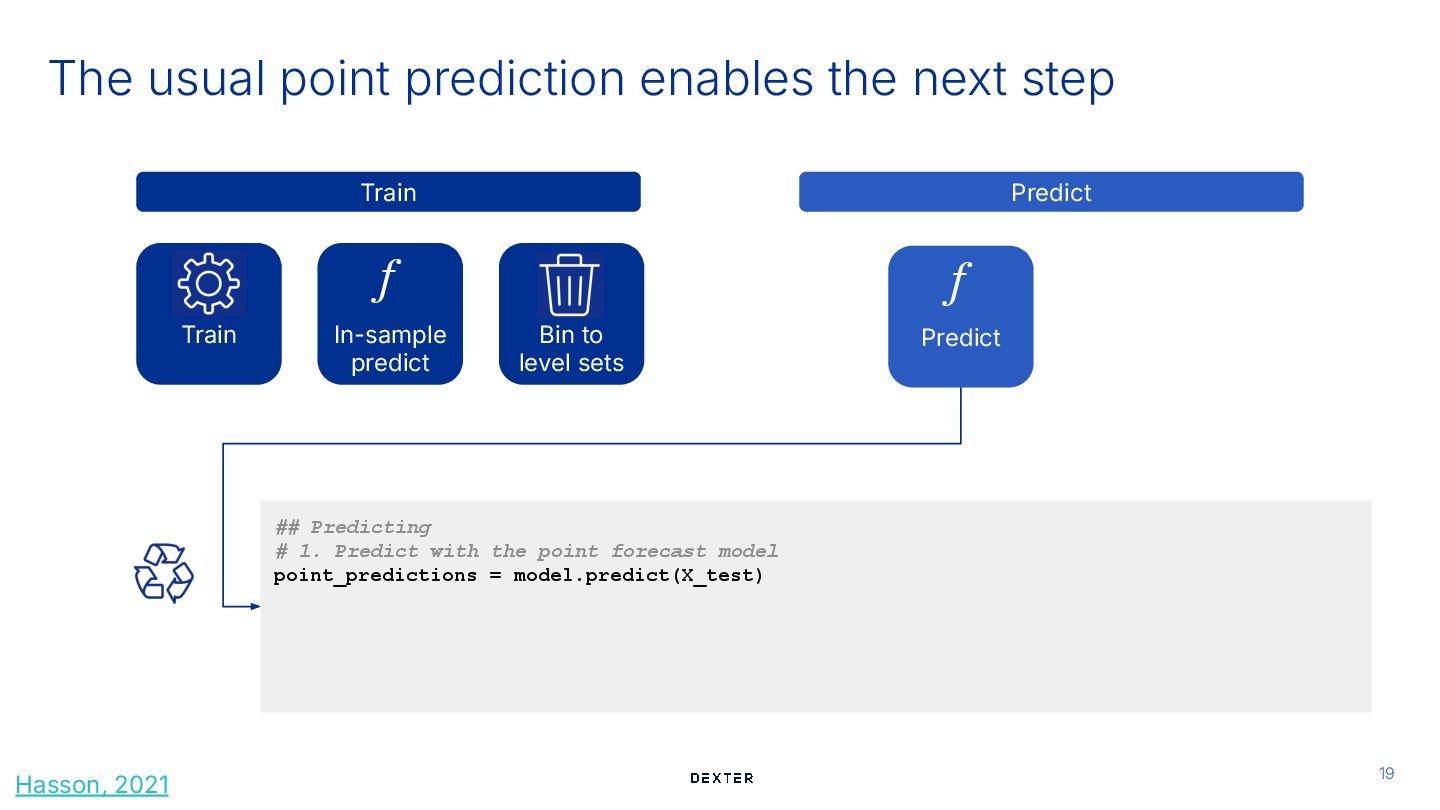
predict f Train Train Predict Bin to level sets Predict f ## Predicting # 1. Predict with the point forecast model point_predictions = model.predict(X_test) Hasson, 2021
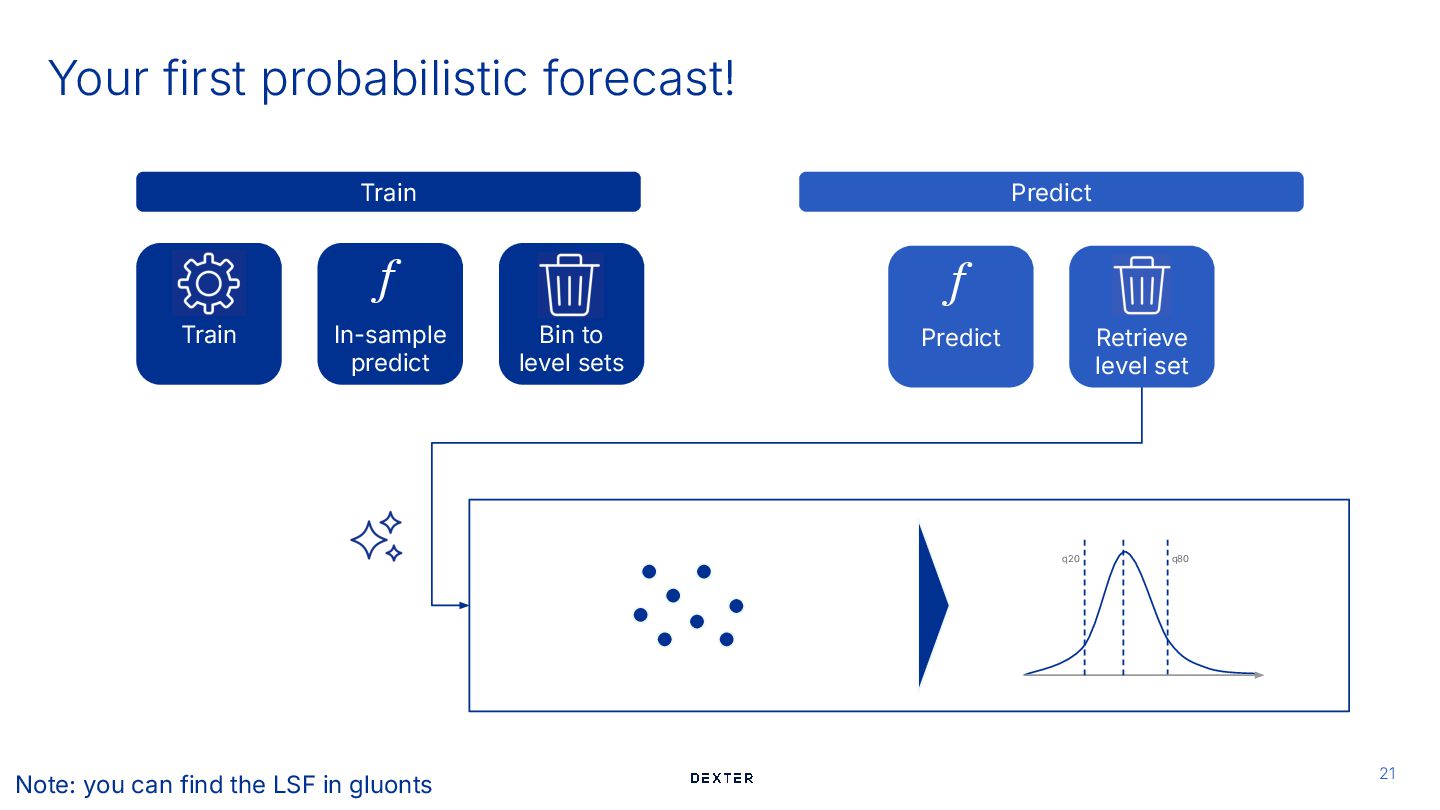
prediction In-sample predict f Train Train Predict Bin to level sets Predict f # 2. Select the bin probabilistic_predictions = [] for i, prediction in enumerate(point_predictions): bin_index = np.argmax(left_thresholds >= prediction) probabilistic_predictions.append([target_per_bin[bin_index]]) Retrieve level set Hasson, 2021
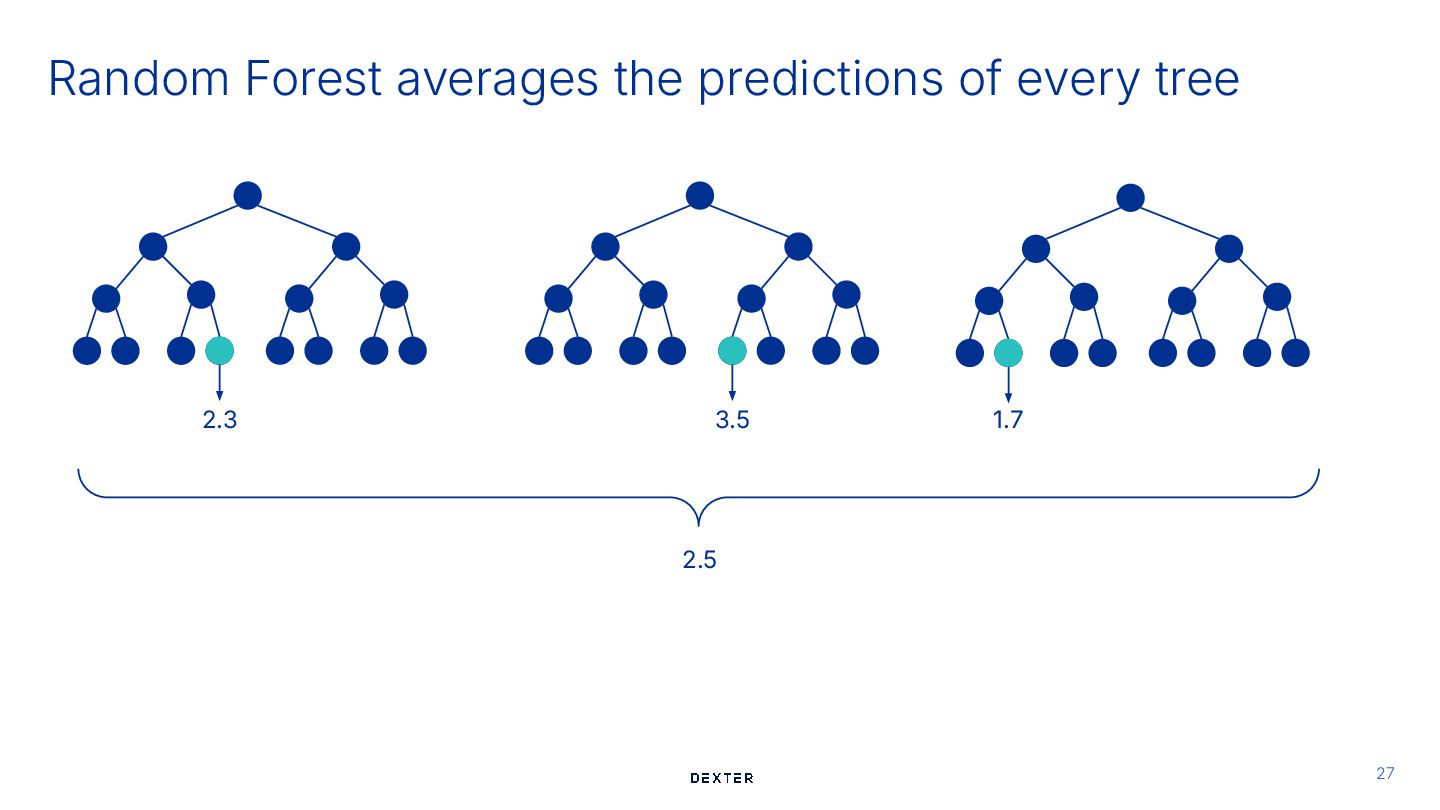
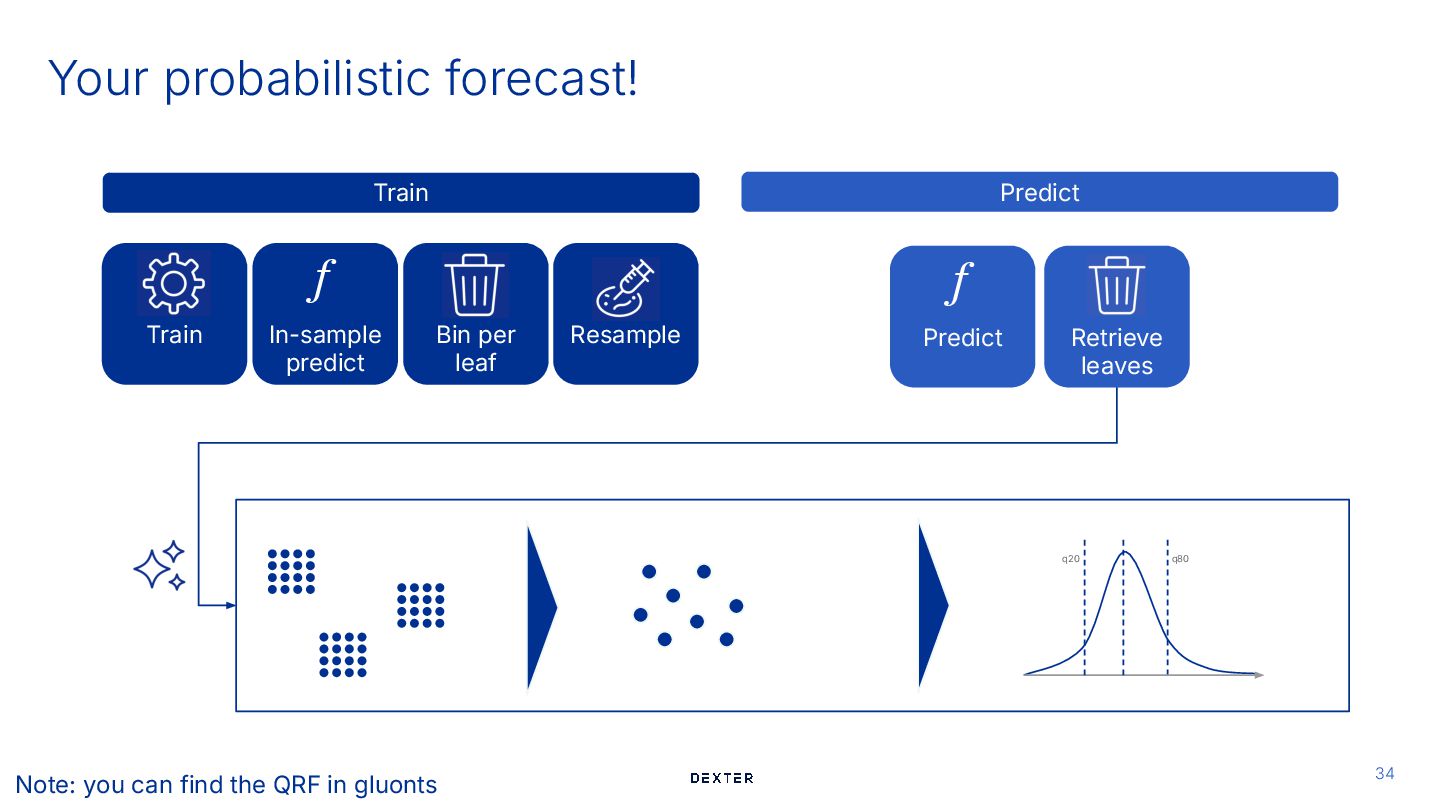
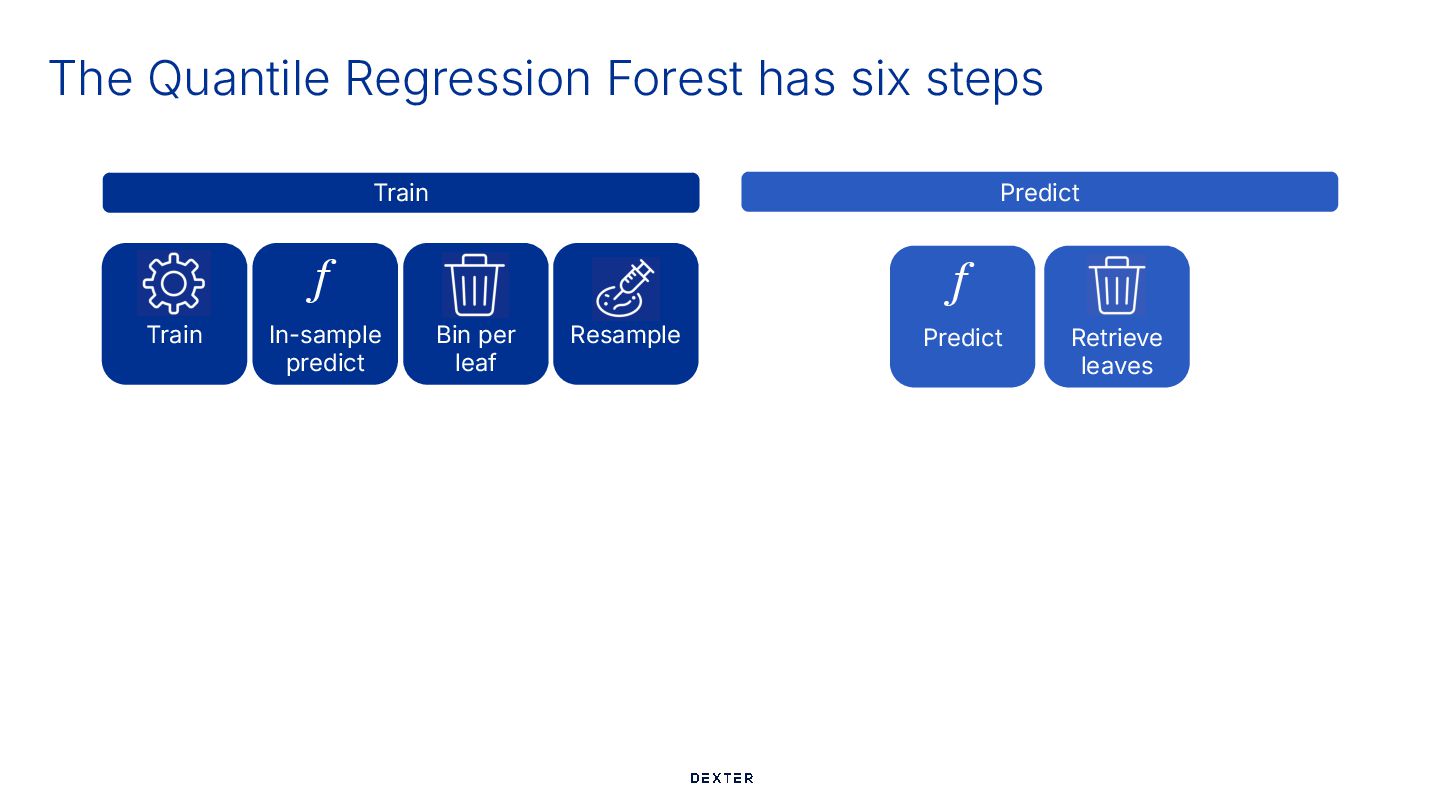
usual ## Training # 1. Train a point forecast model: Random Forest model = RandomForestRegressor().fit(X_train, y_train) Train Predict Train Meinhausen, 2006
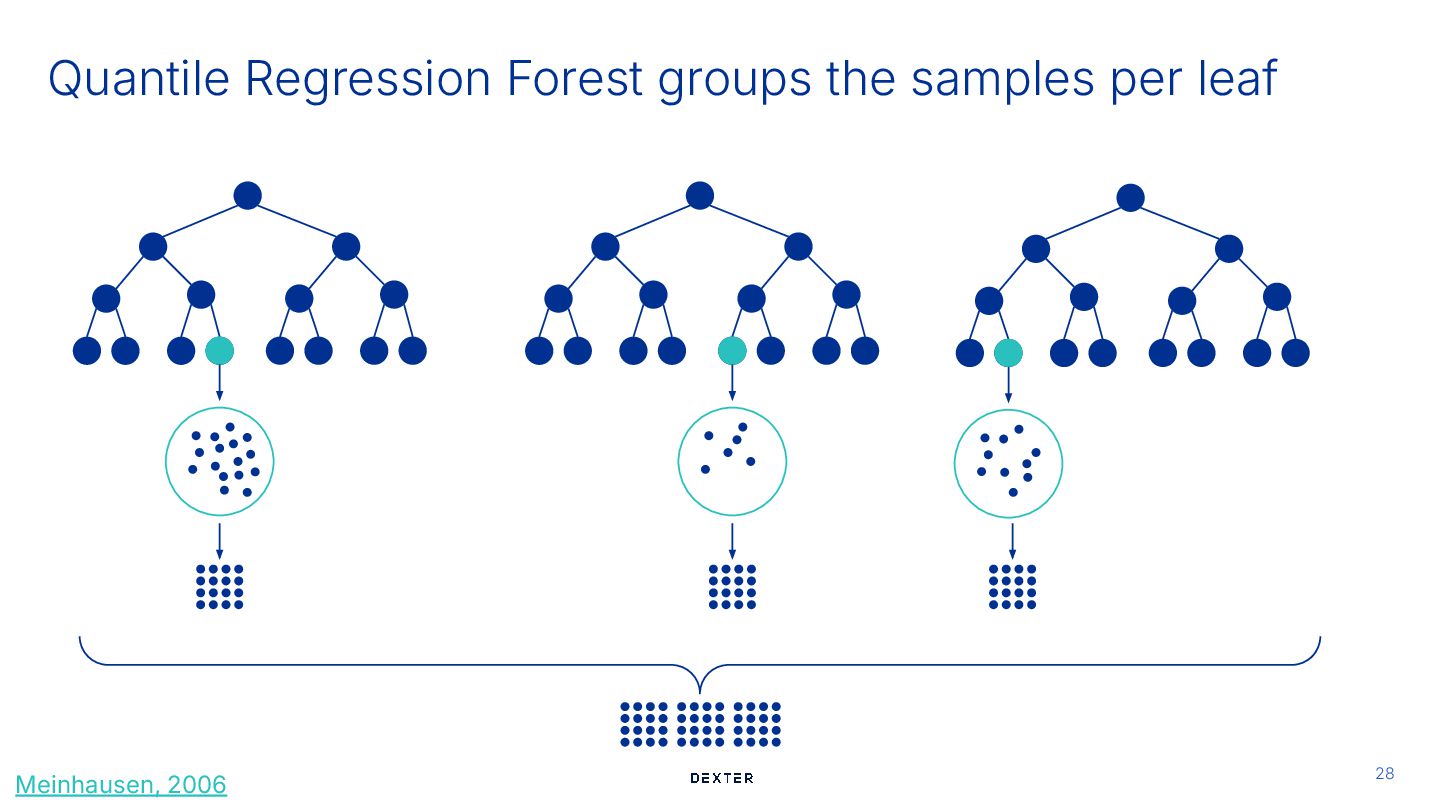
tree of the Random Forest listed_predictions_per_tree = [tree.predict(X_test) for tree in model.estimators_] predictions_per_tree = np.column_stack(listed_predictions_per_tree) # Every column is a tree and every row is an observations In-sample predict f Train Predict Train Meinhausen, 2006 Quantile Regression Forest groups the samples per leaf
Predict f Retrieve leaves Train # 3. Group the true values based on prediction (leaf value) for every tree leaf_values_per_tree: List[Dict[float, np.ndarray]] = [ ( pd.DataFrame( {"predictions": predictions_per_tree[:, i], "true_values": y_train.copy()} ) .sort_values("predictions") .groupby("predictions")["true_values"].apply(list).to_dict() ) for i in range(model.n_estimators) ] # Every dictionary in the list is a tree: # every key a predicted value of a leave, the items are the true values in that leaf Meinhausen, 2006 Quantile Regression Forest groups the samples per leaf
Train # 4. Resample the true values to have a constant leaf weight leaf_size = 100 # the number of values in every leaf after resampling balanced_values_per_leaf = [ { leaf: resample(true_values, sample_size=leaf_size) for leaf, true_values in tree.items() } for tree in leaf_values_per_tree ] Meinhausen, 2006 Quantile Regression Forest groups the samples per leaf
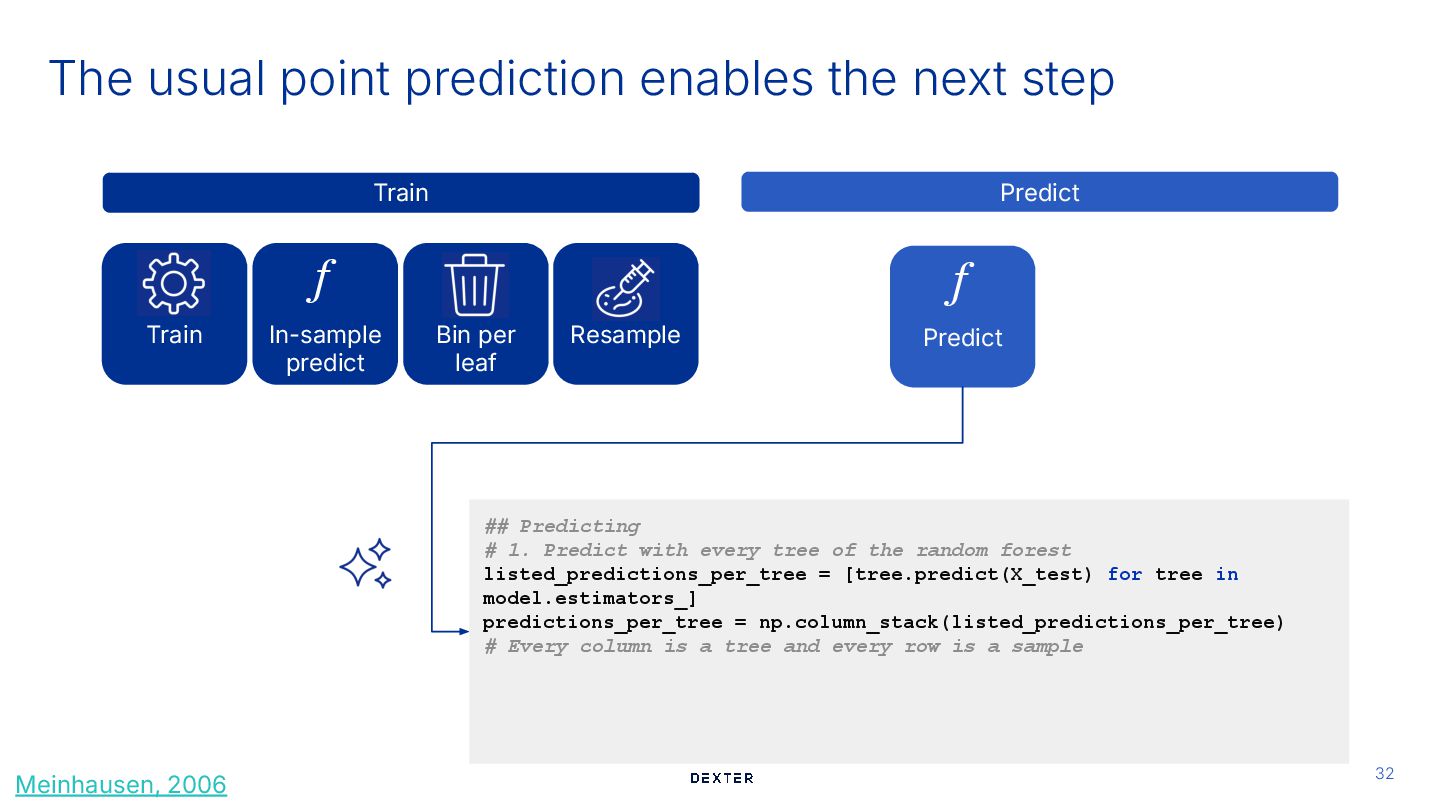
In-sample predict f Train Predict Bin per leaf Predict f Train ## Predicting # 1. Predict with every tree of the random forest listed_predictions_per_tree = [tree.predict(X_test) for tree in model.estimators_] predictions_per_tree = np.column_stack(listed_predictions_per_tree) # Every column is a tree and every row is a sample Meinhausen, 2006
Resample In-sample predict f Train Predict Bin per leaf Predict f Retrieve leaves Train # 2. Collect all true values of the relevant leave per tree probabilistic_predictions_QRF = np.zeros( [predictions_per_tree.shape[0], predictions_per_tree.shape[1] * leaf_size] ) for sample in range(predictions_per_tree.shape[0]): # Loop over all samples for tree in range(predictions_per_tree.shape[1]): # Loop over all trees start_idx = tree * leaf_size end_idx = start_idx + leaf_size probabilistic_predictions_QRF[sample, start_idx:end_idx] = ( balanced_values_per_leaf[tree][predictions_per_tree[sample, tree]] ) Meinhausen, 2006
Regression Forest Grouping Based on predictions Based on features Full distribution 🟢 🟢 No assumptions on distribution 🟢 🟢 Good performance 🟢 🟢 Model agnostic 🟢 🔴 Distinct forecast per sample 🔴 🟢 Fast 🟢 🟠
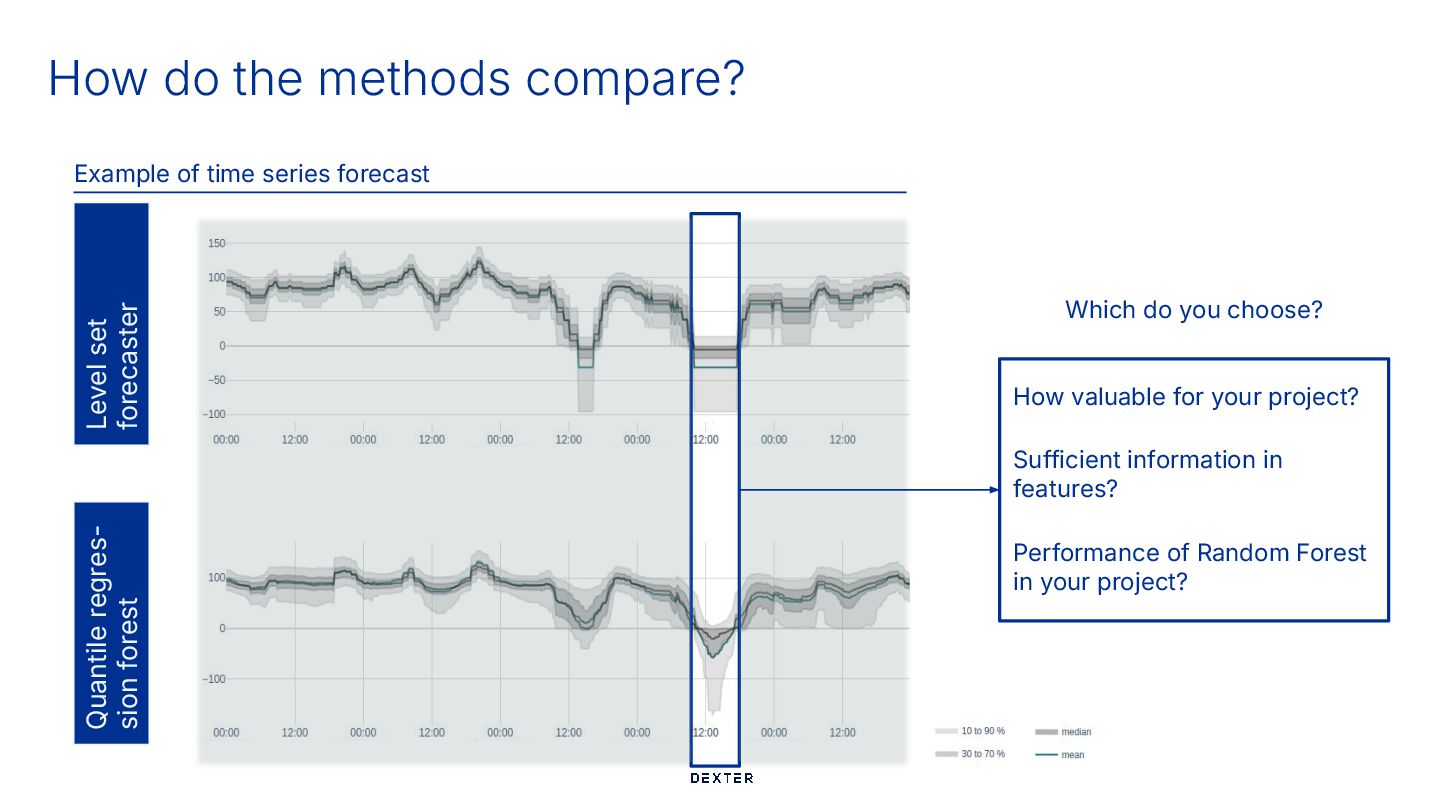
Level set forecaster Quantile regres- sion forest How valuable for your project? Sufficient information in features? Performance of Random Forest in your project? Which do you choose?
you can start today Tailoring evaluation to probabilistic metrics is crucial to boost performance Probabilistic forecasts provide valuable information for decision making
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}