In this video from FOSDEM 2020, Felix Abecassis and Jonathan Calmels present: Distributed HPC Applications with Unprivileged Containers.
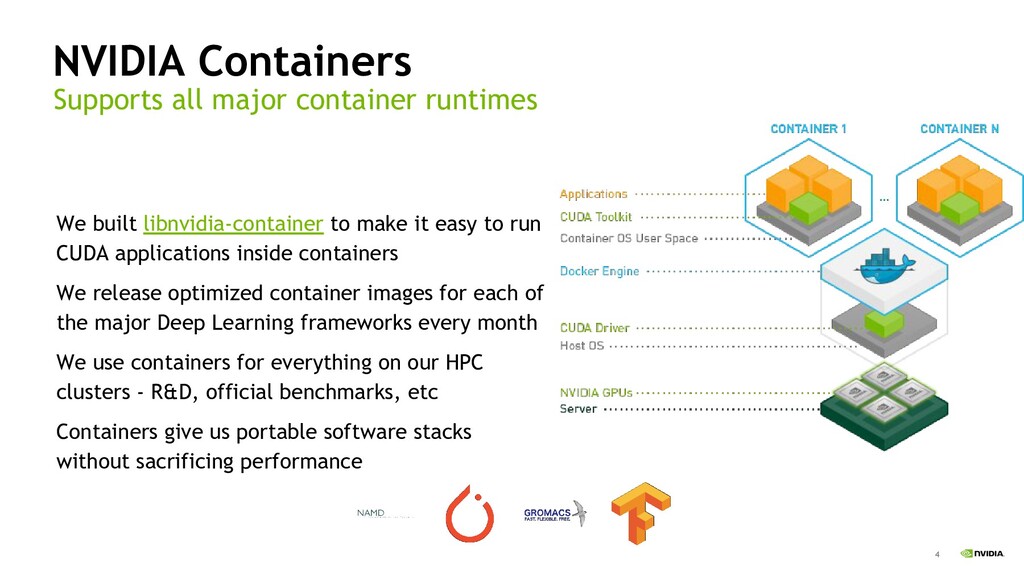
"We will present the challenges in doing distributed deep learning training at scale on shared heterogeneous infrastructure. At NVIDIA, we use containers extensively in our GPU clusters for both HPC and deep learning applications. We love containers for how they simplify software packaging and enable reproducibility without sacrificing performance. Docker is a popular tool for running application containers on Linux, and while it is possible to enable container workflows for users by granting them access to the docker daemon, the security impact needs to be carefully considered, especially in a shared environment. Relying on docker for the container runtime also requires a large amount of complicated boilerplate code to start multi-node jobs using the Message Passing Interface (MPI) for communication. In this presentation, we will introduce a new lightweight container runtime inspired from LXC and an associated plugin for the Slurm Workload Manager. Together, these two open-source projects enable a more secure architecture for our clusters, while also enabling a smoother user experience with containers on multi-node clusters.
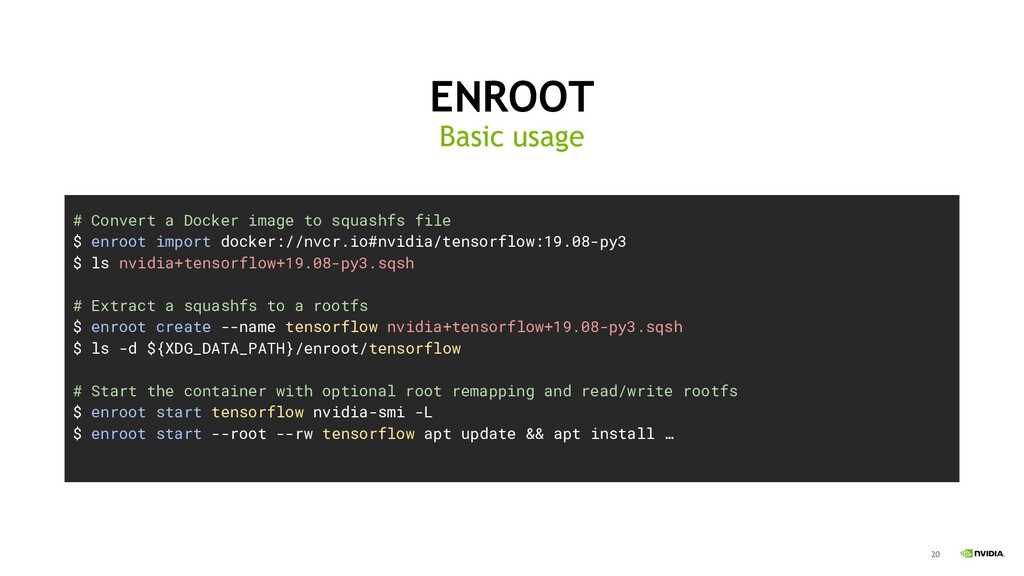
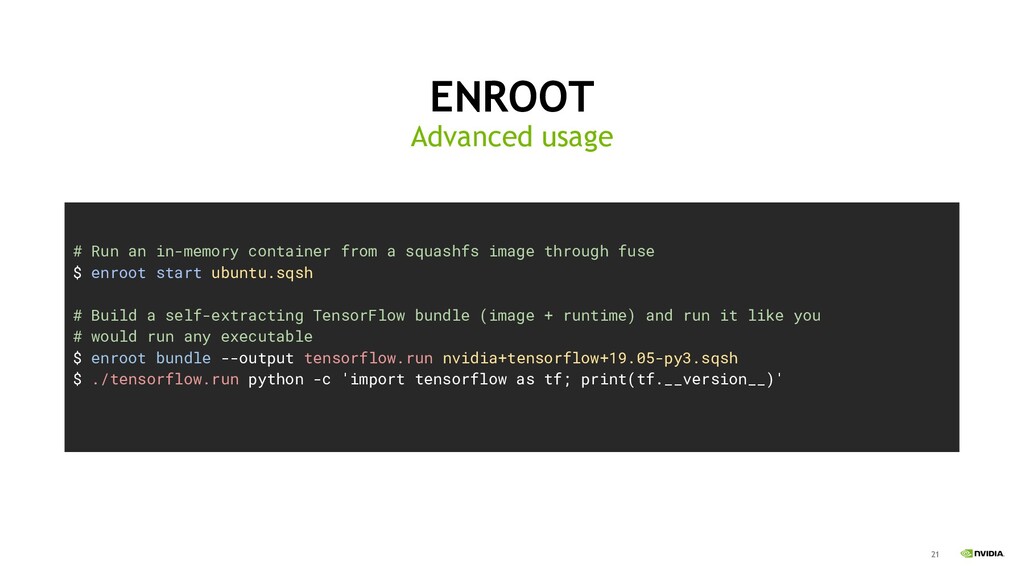
There are many container runtimes available, but none met all of our needs for running distributed applications with no performance overhead and no privileged helper tools. For our use case, we built a simple container runtime called enroot - it's a tool to turn traditional container images into lightweight unprivileged sandboxes; a modern chroot. One key feature is that enroot remaps all UIDs inside the container to a single UID on the host. So, unlike runtimes which rely on /etc/subuid and /etc/subgid, with enroot there is no risk of overlapping UID ranges on a node, and no need to synchronize ranges across the cluster. It is also trivial to remap to UID 0 inside the container which enables users to safely run apt-get install to add their own packages. Enroot is also configured to automatically mount drivers and devices for accelerators from NVIDIA and Mellanox using enroot's flexible plugin system. Finally, enroot is highly optimized to download and unpack large docker images, which is particularly useful for images containing large applications.
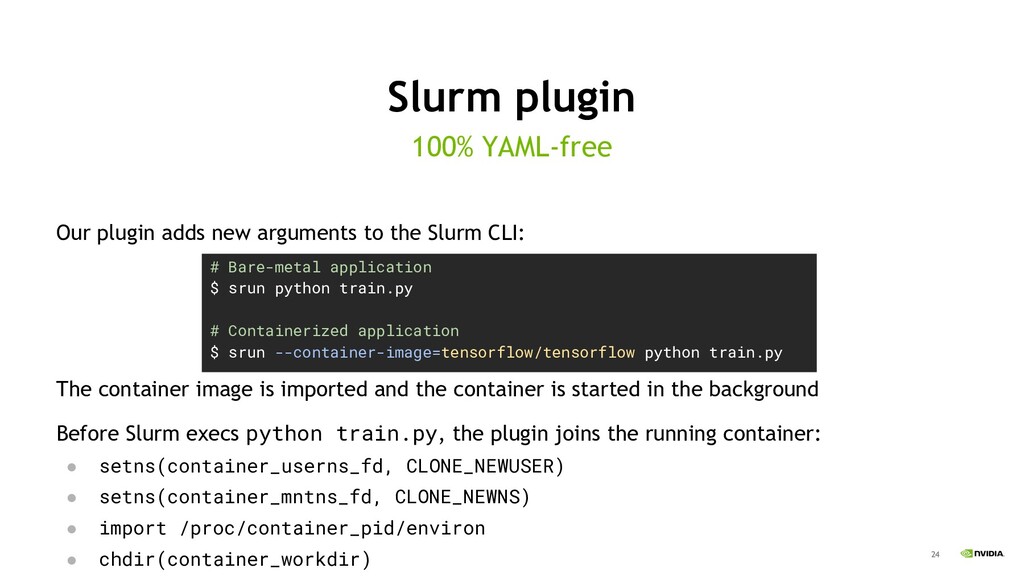
We also created a new plugin for the Slurm Workload manager which adds command-line flags for job submission. When the “--container-image” flag is set, our plugin imports a container image, unpacks it on the local filesystem, creates namespaces for the container, and then attaches the current job to these new namespaces. Therefore, tasks transparently land inside of the container with minimal friction. Users can even make use of the PMI2 or PMIx APIs to coordinate workloads inside the containers without needing to invoke mpirun, further streamlining the user experience. Currently, the plugin works with two different tools - enroot and LXC. It could be extended to other container runtimes in the future."
Watch the video: https://wp.me/p3RLHQ-ltn
Learn more: https://fosdem.org/2020/schedule/events/
Sign up for our insideHPC Newsletter: http://insidehpc.com/newsletter
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![23 ENROOT “Container” from scratch $ curl https://cdimage.ubuntu.com/[...]/ubuntu-base-16.04-core-amd64.tar.gz | tar](https://files.speakerdeck.com/presentations/77e21f2951e8436698fa3f8a170af436/slide_22.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}