In this video from ATPESC 2019, David Keyes from KAUST presents: The Convergence of Big Data and Large-scale Simulation.
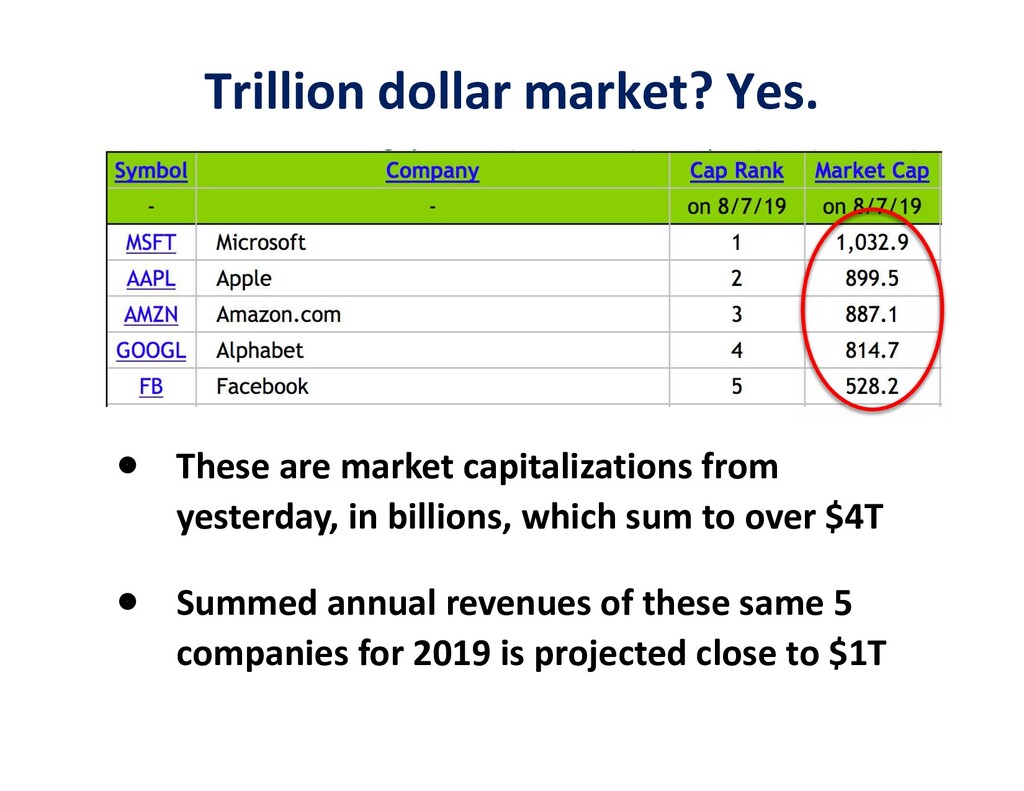
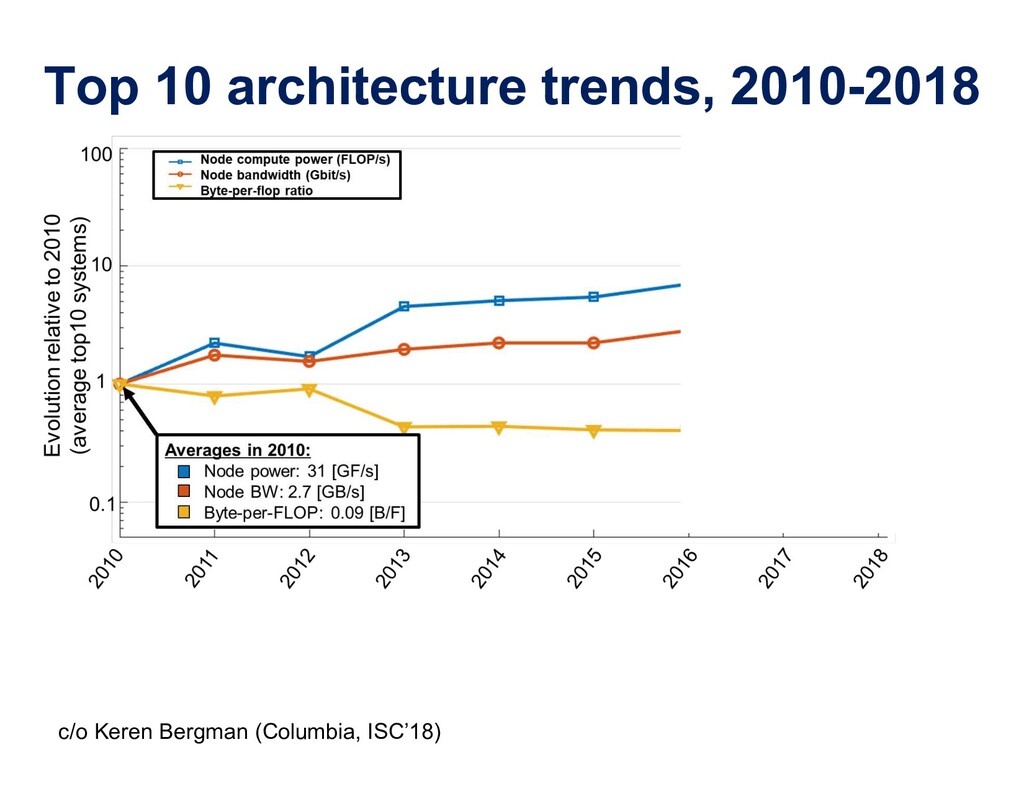
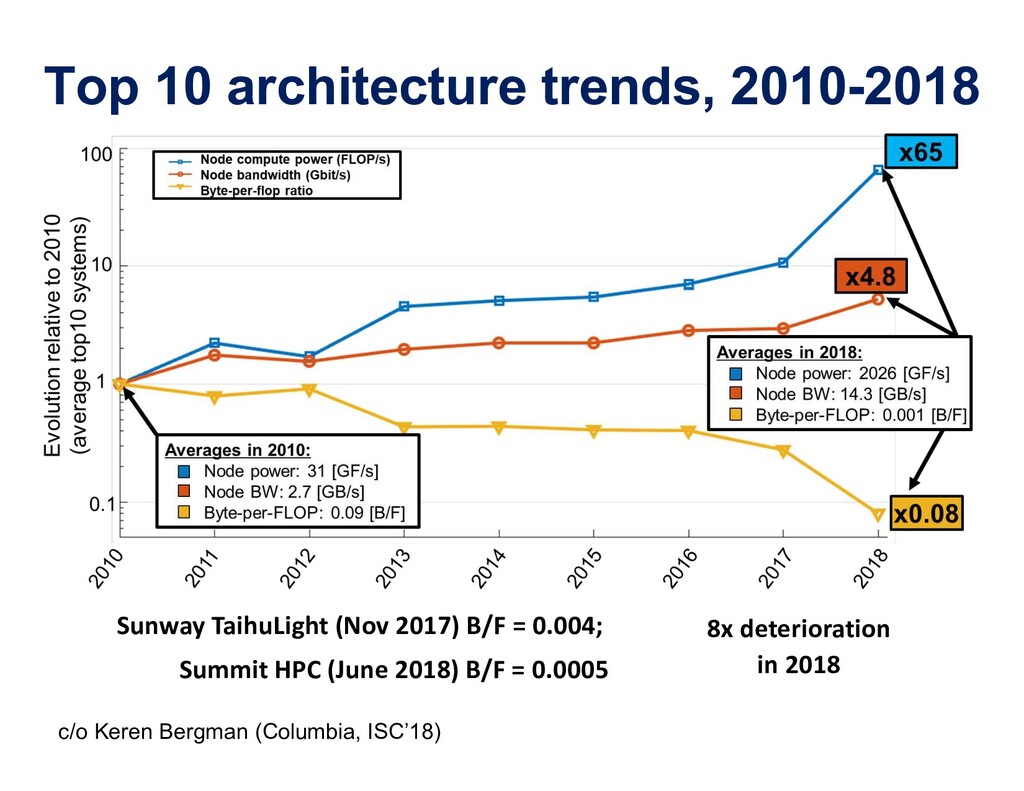
"Motivations abound for the convergence of large-scale simulation and big data. The most important are scientific and engineering advances, but computational and data storage efficiency, economy of data center operations, development of a competitive workforce, and computer architecture forcing are also compelling reasons to bring together communities that are today rather divergent.
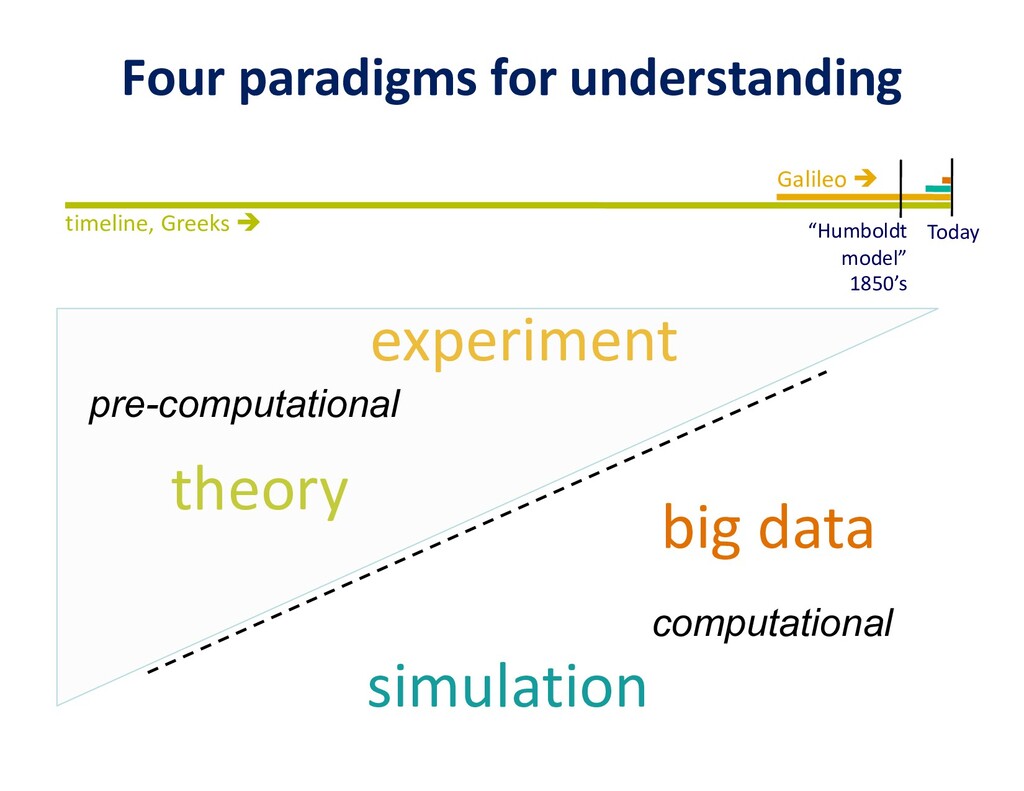
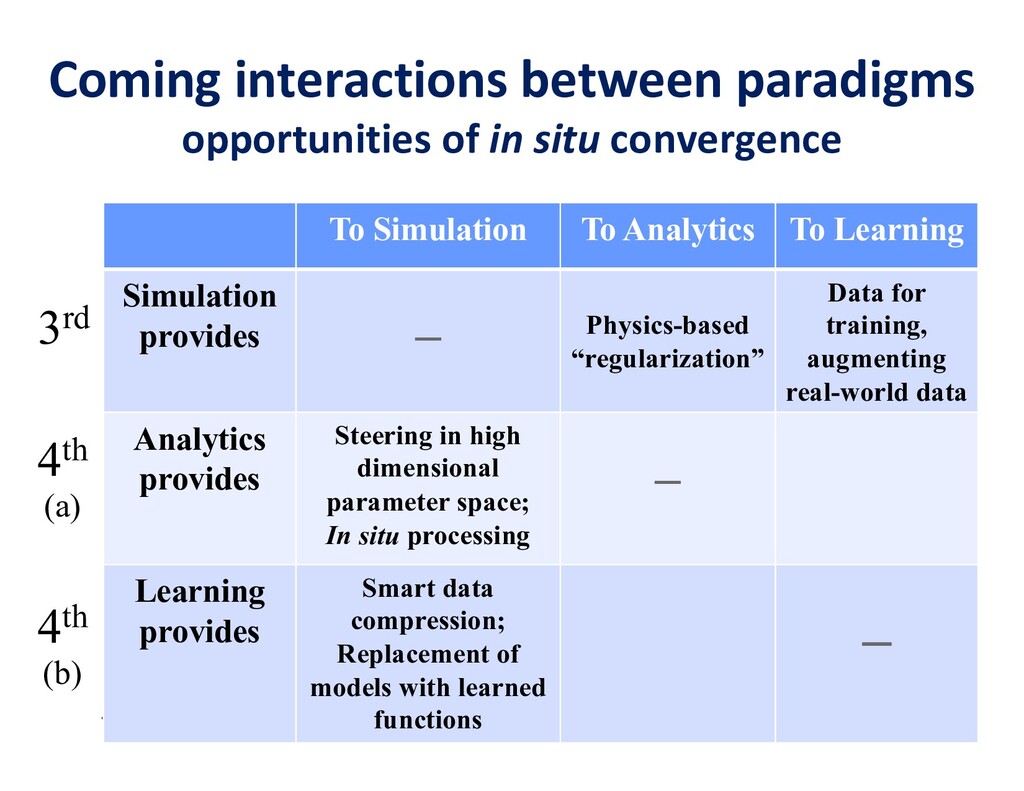
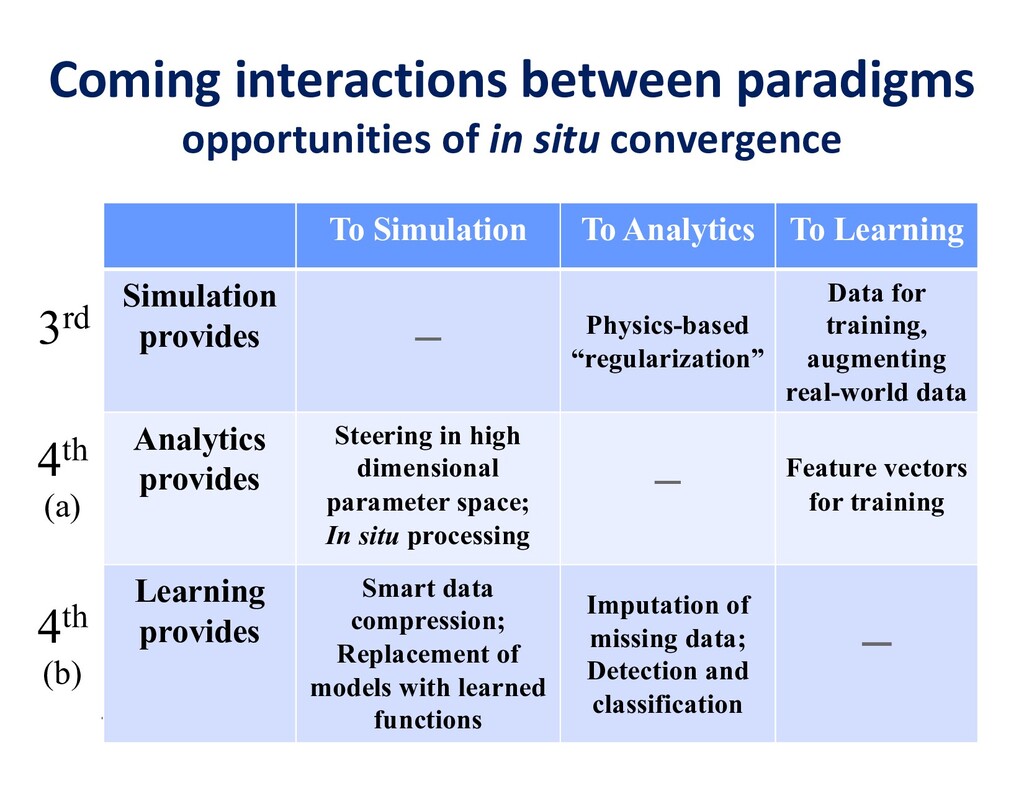
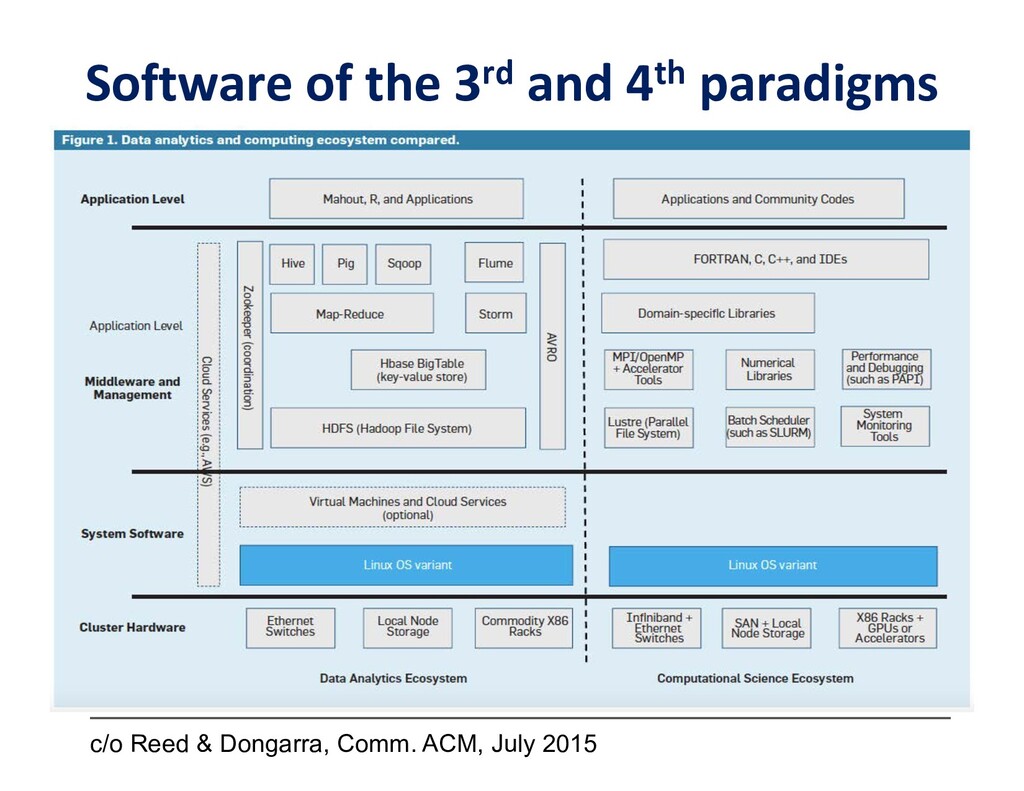
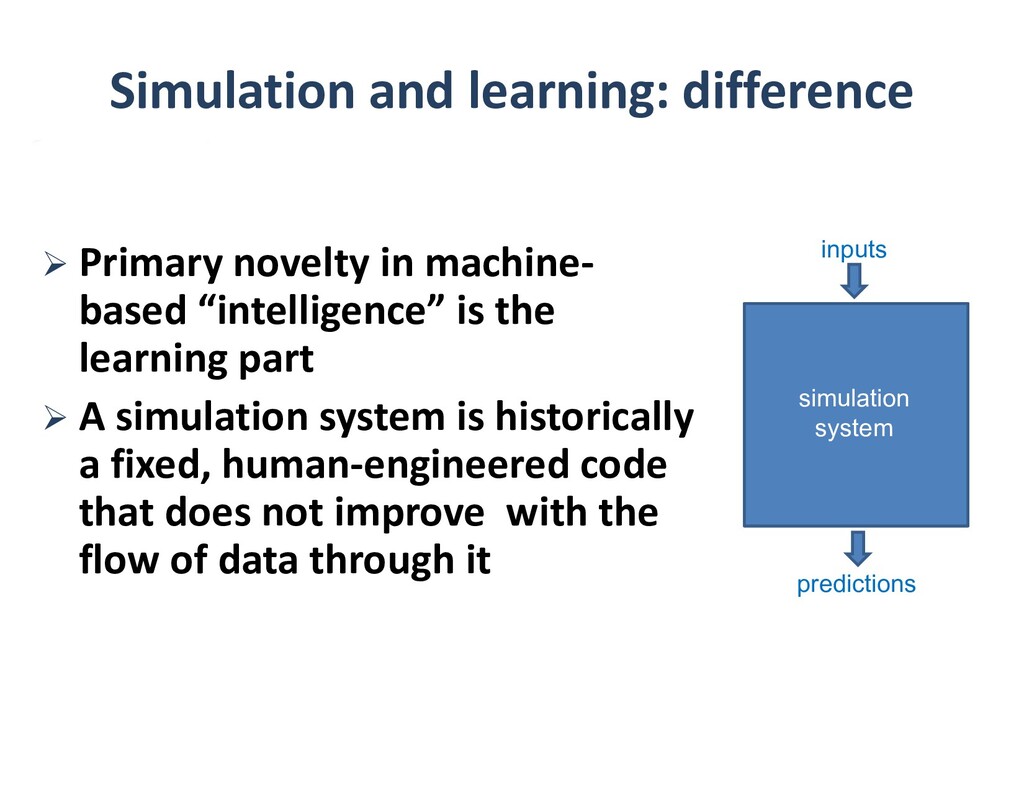
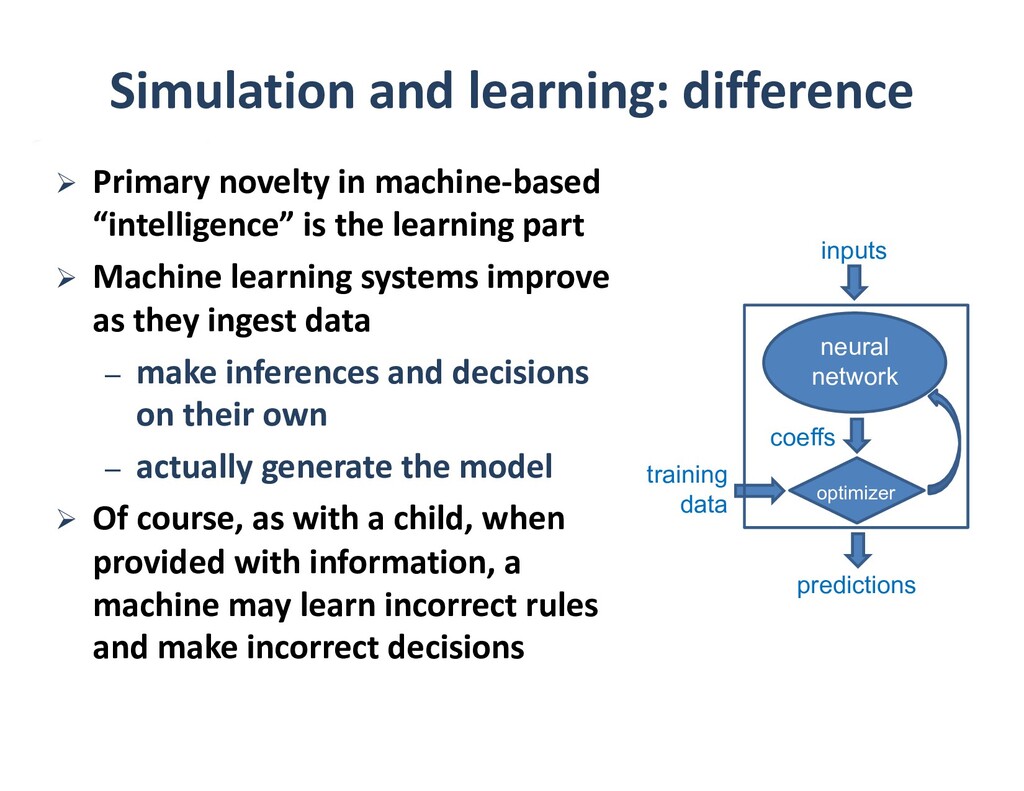
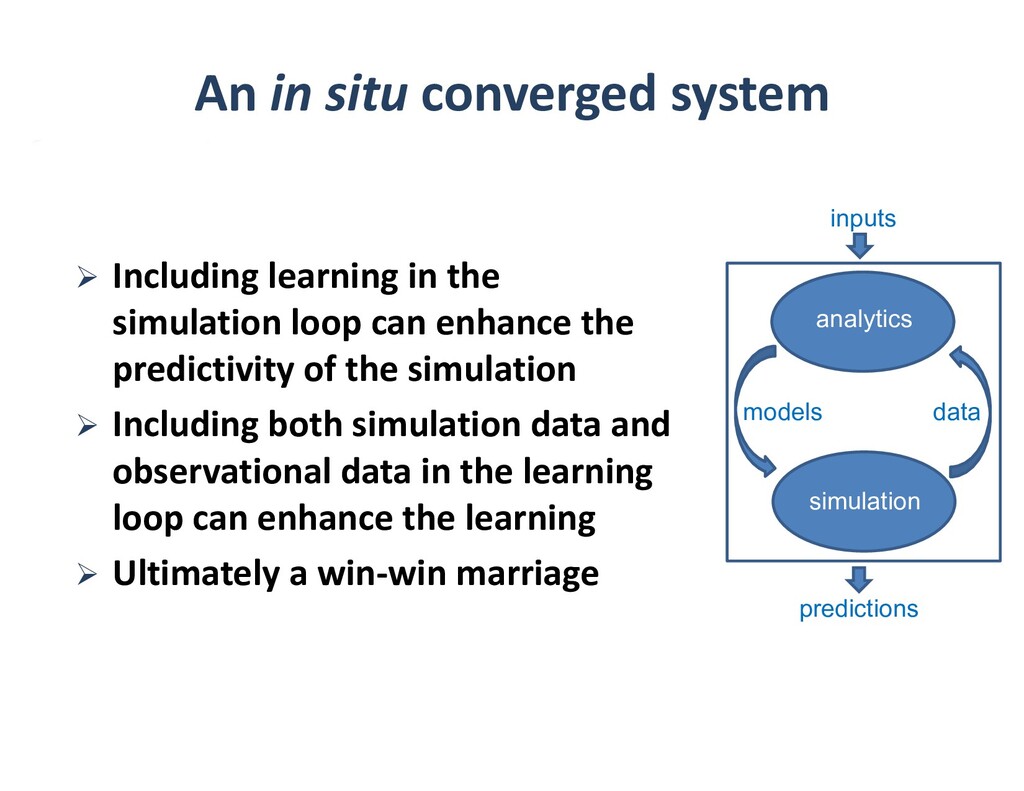
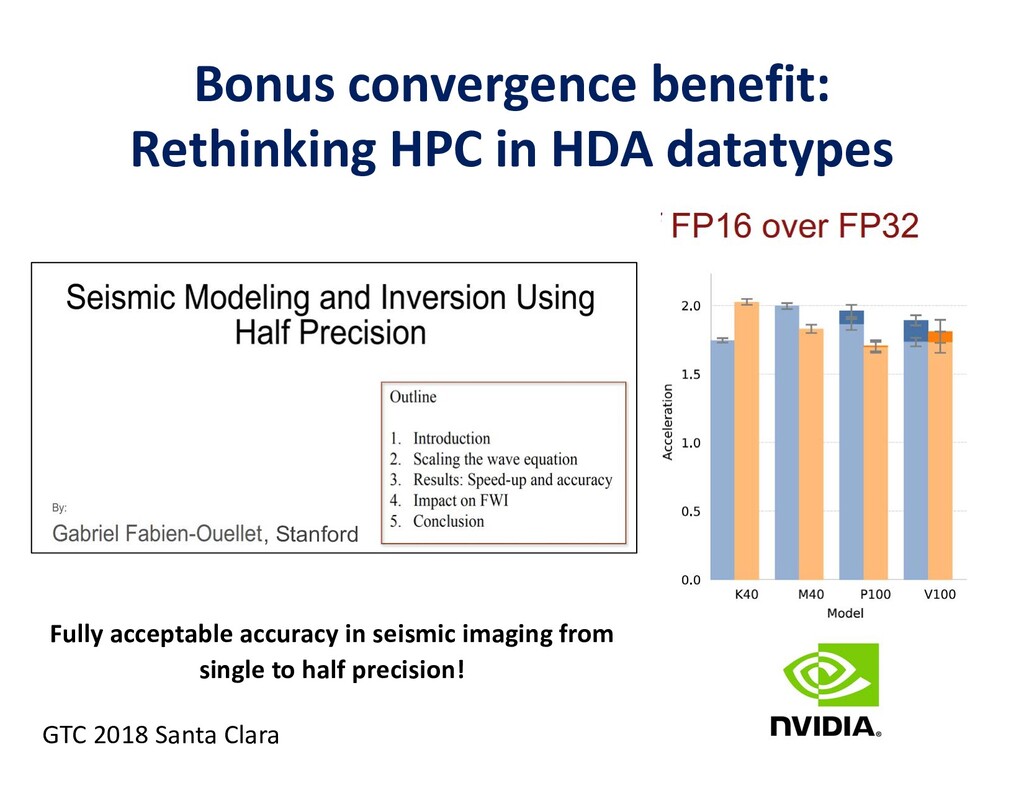
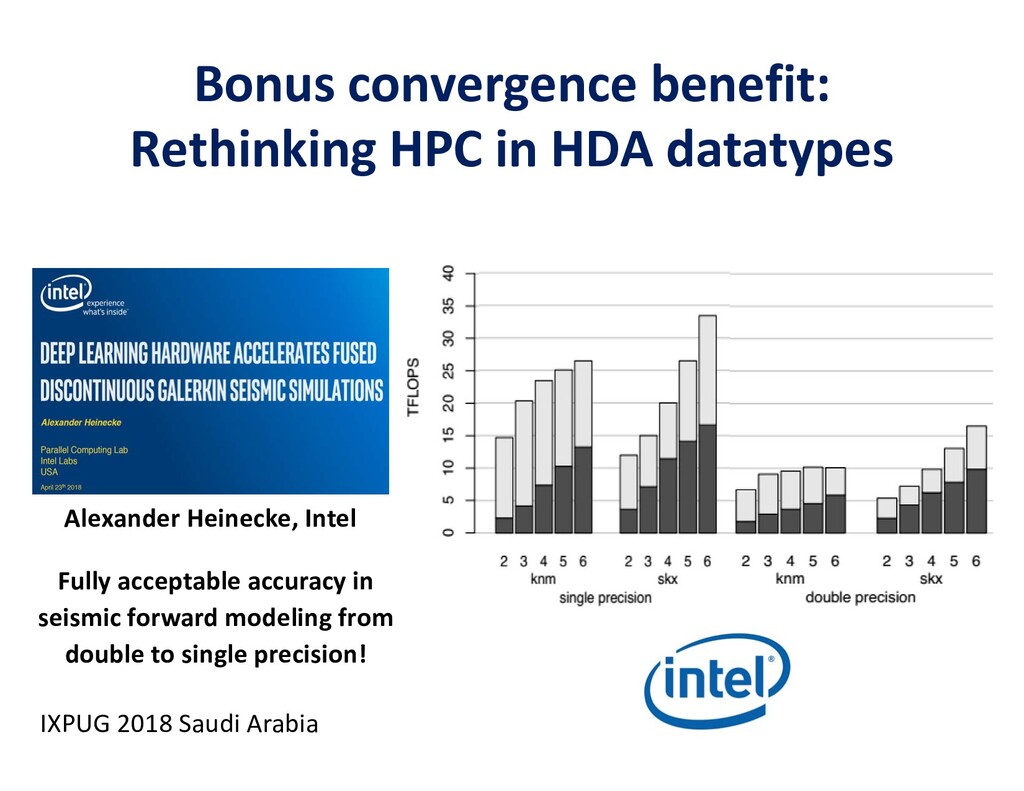
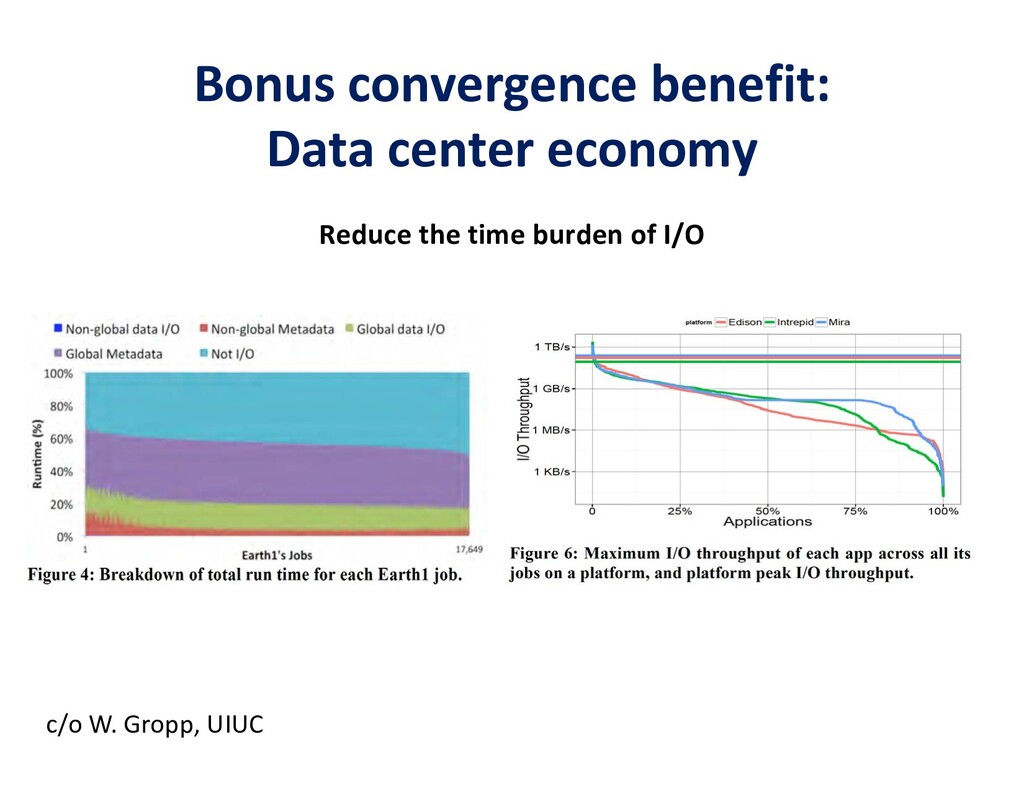
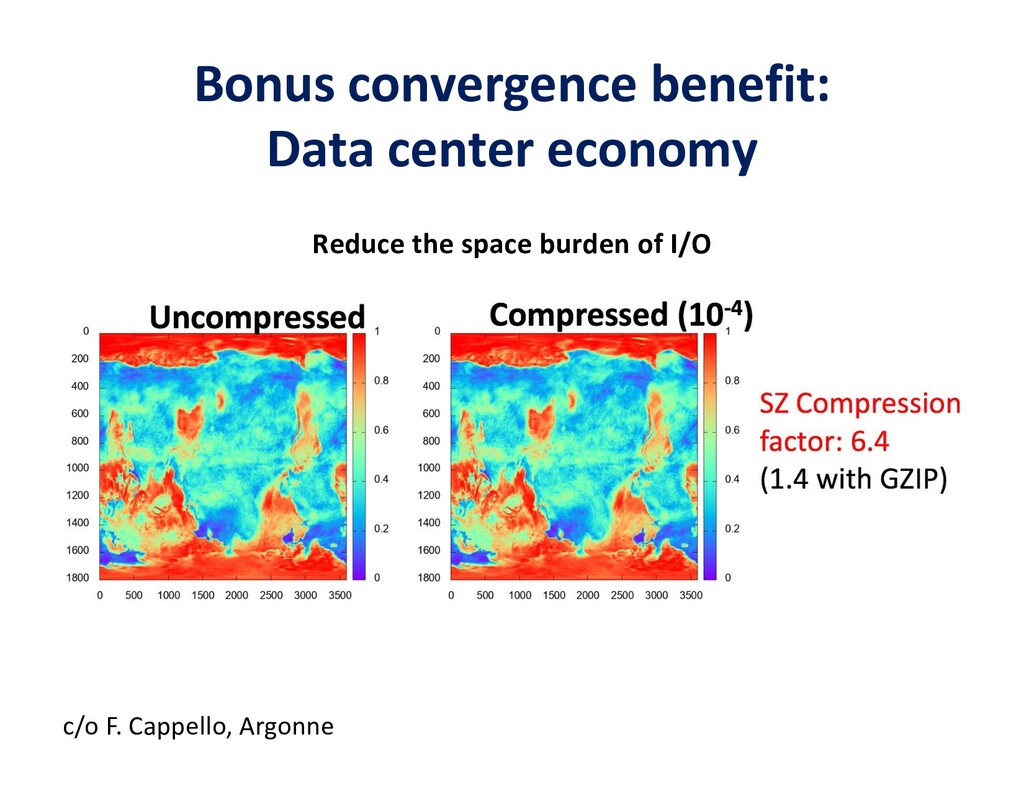
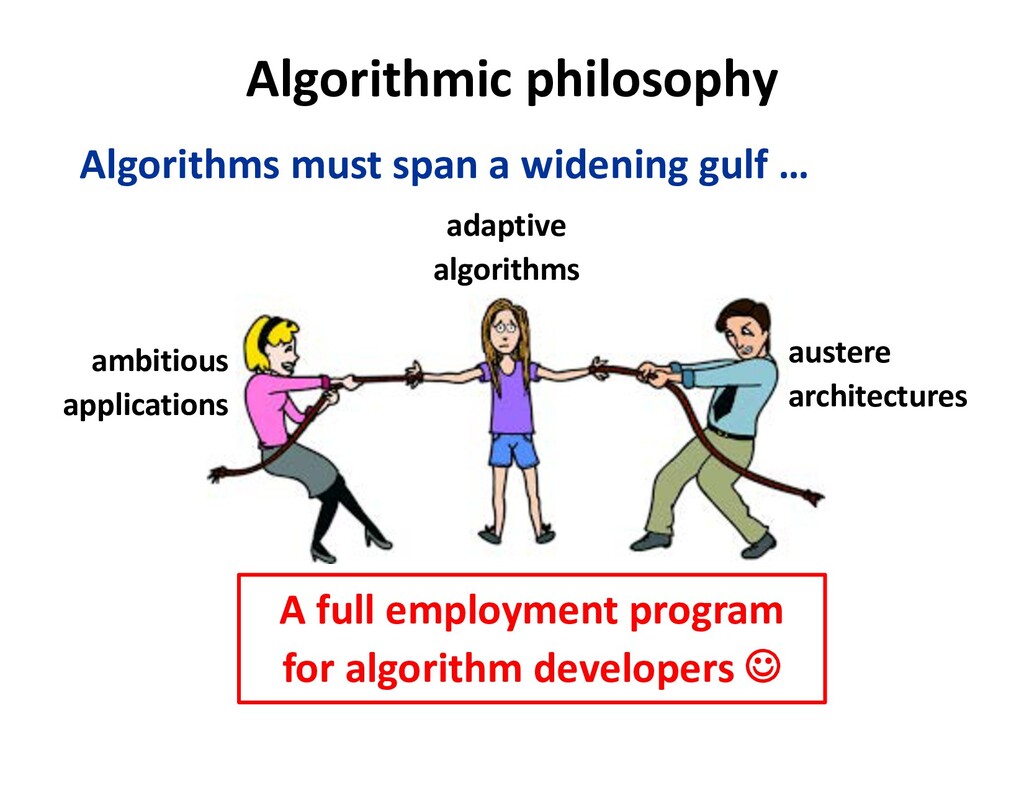
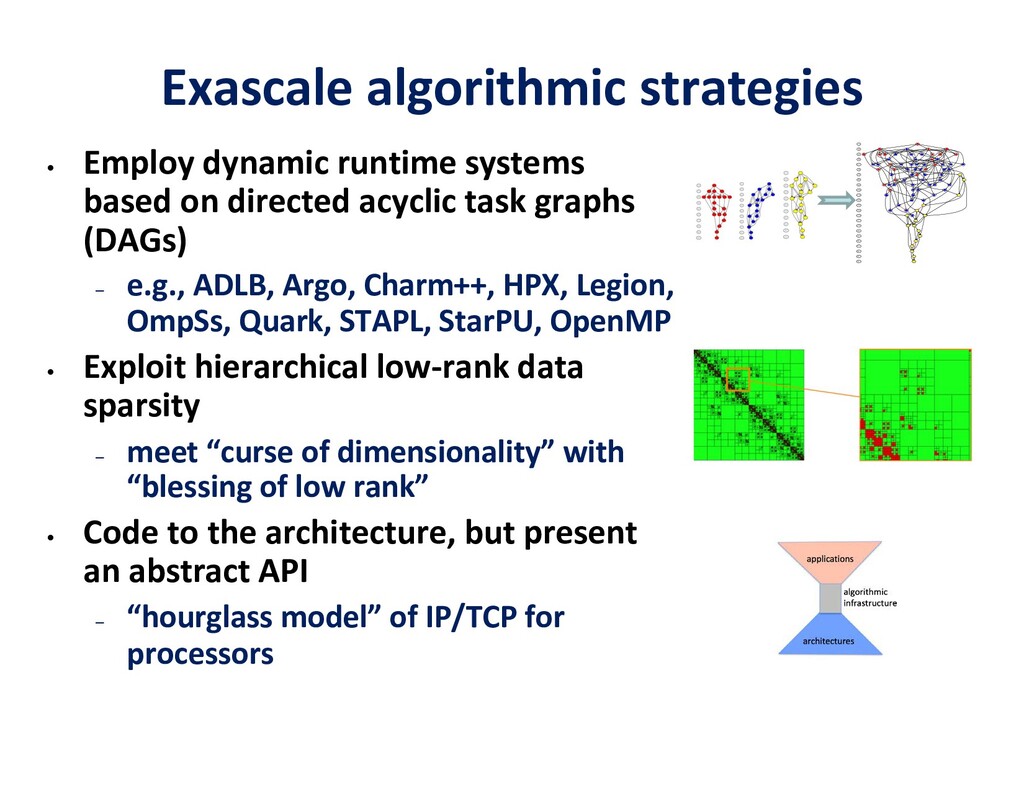
To take advantage of advances in analytics and learning, large-scale simulations should evolve to incorporate these technologies in-situ, rather than as forms of post-processing. This potentially reduces burdens of file transfer and the runtime IO that produces the files. In some applications, IO consumes more resources than the computation, itself. Smart steering may obviate significant computation, along with the IO that would accompany it, in unfruitful regions of physical parameter space, as guided by the in-situ analytics. In-situ machine learning offers smart data compression, which complements analytics in leading to reduced IO and reduced storage. Machine learning has the potential to improve the simulation, itself, since many simulations incorporate empirical relationships, such as constitutive parameters or functions that are not derived from first principles, but tuned from dimensional analysis, intuition, observation, or other simulations. Machine learning in-the-loop may ultimately be more effective than the tuning of human experts.
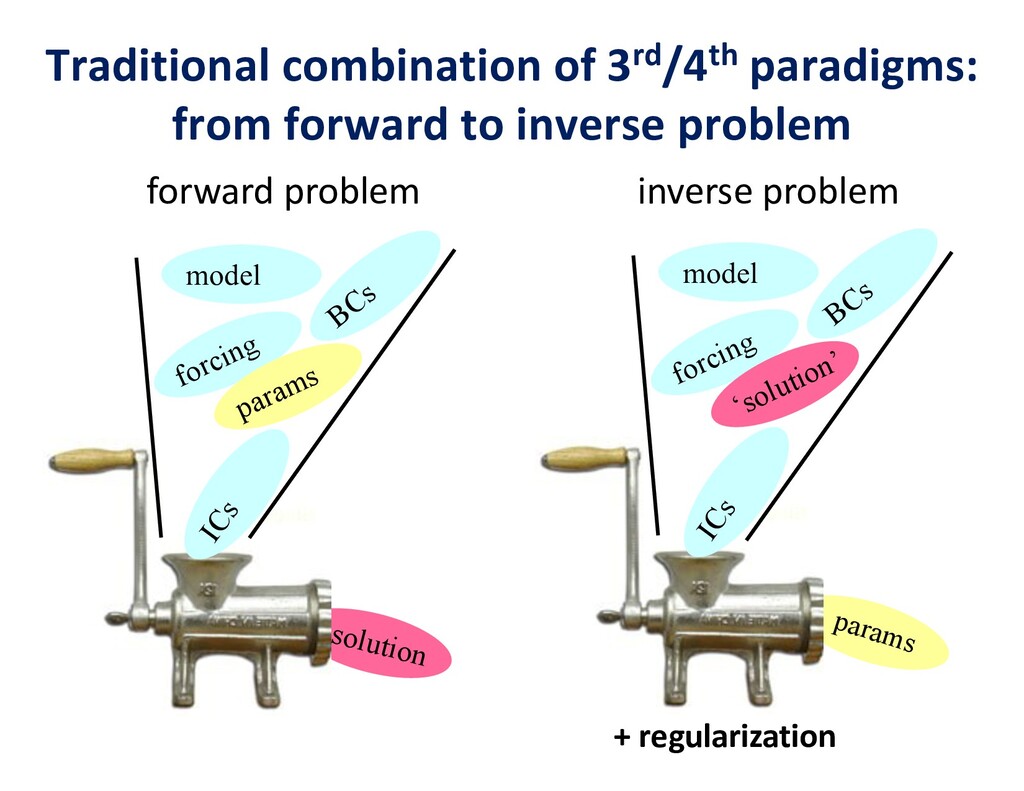
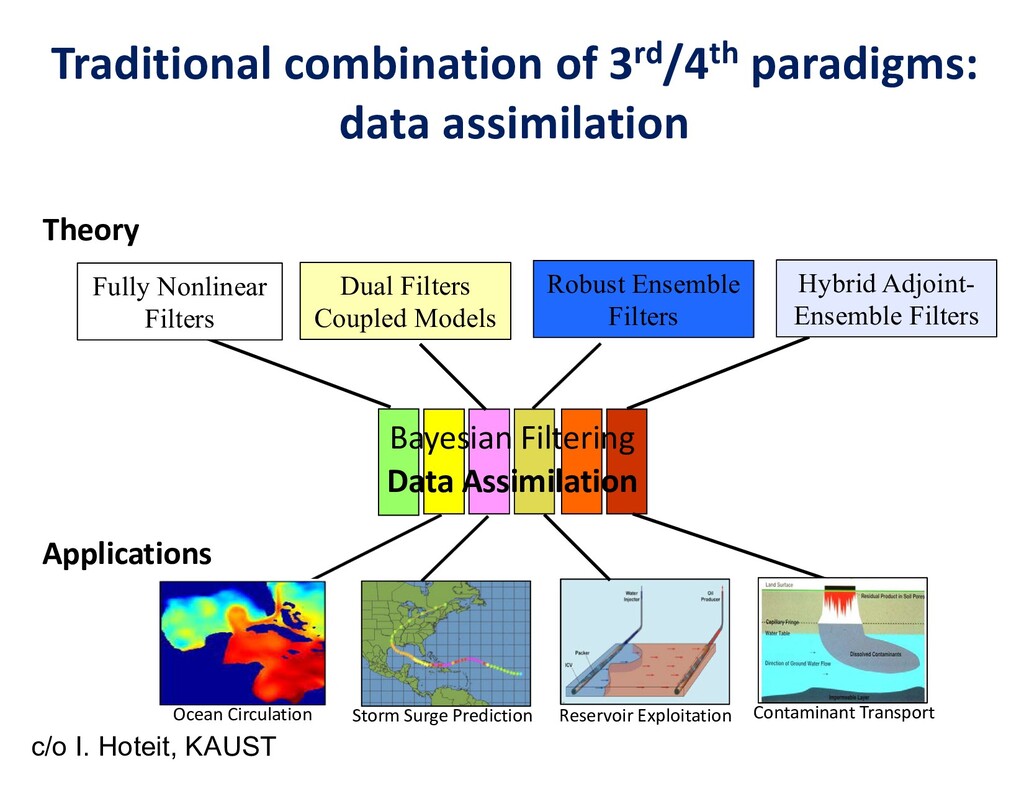
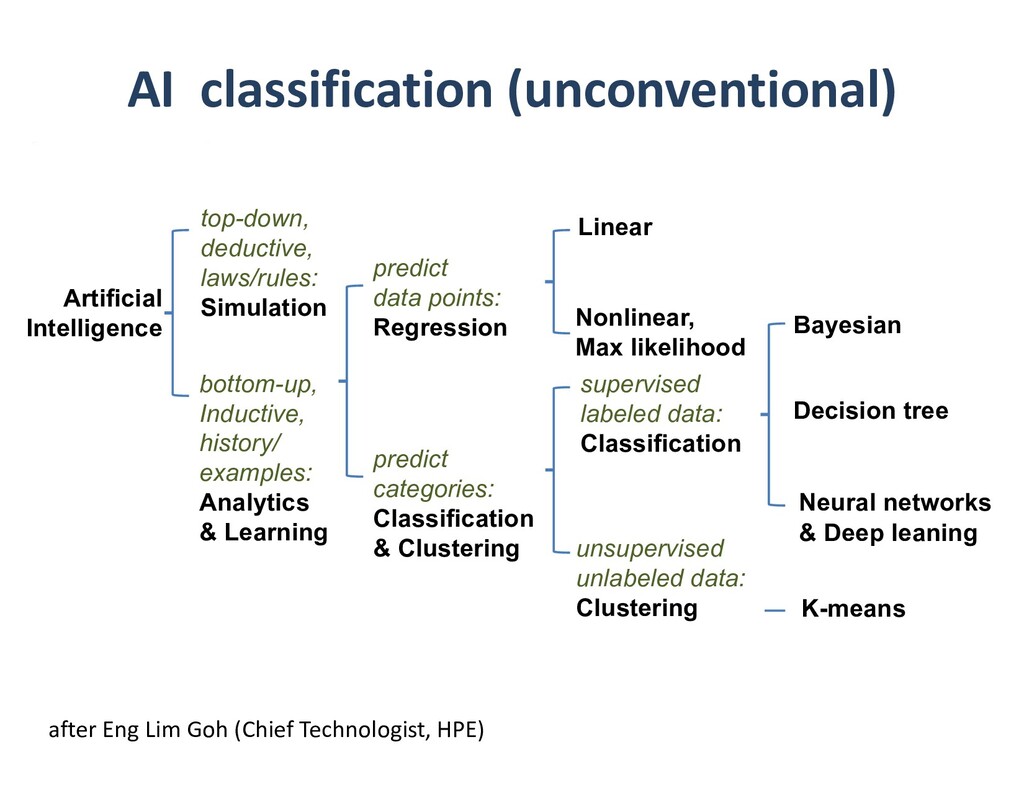
Flipping the perspective, simulation potentially provides significant benefits in return to analytics and learning workflows. Theory-guided data science is an emerging paradigm that aims to improve the effectiveness of data science models, by requiring consistency with known scientific principles (e.g., conservation laws). It is analogous to “regularization” in optimization, wherein non-unique candidates are penalized by some physically plausible constraint (such as minimizing energy) to narrow the field. In analytics, among statistically equally plausible outcomes, the field could be narrowed to those that satisfy physical constraints, as checked by simulations. Simulation can also provide training data for machine learning, complementing data that is available from experimentation and observation. There are also beneficial interactions between the two types of workflows within big data. Analytics can provide to machine learning feature vectors for training. Machine learning, in turn, can impute missing data and provide detection and classification. The scientific opportunities are potentially enormous enough to overcome the inertia of the specialized communities that have gathered around each of paradigms and spur convergence."
Watch the video: https://insidehpc.com/2020/01/video-the-convergence-of-big-data-and-large-scale-simulation/
Learn more: https://extremecomputingtraining.anl.gov/archive/atpesc-2019/agenda-2019/
Sign up for our insideHPC Newsletter: http://insidehpc.com/newsletter
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![Convergence for performance [email protected] n It is not only the](https://files.speakerdeck.com/presentations/2b0d80daede741b89570f2929d9bea97/slide_19.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
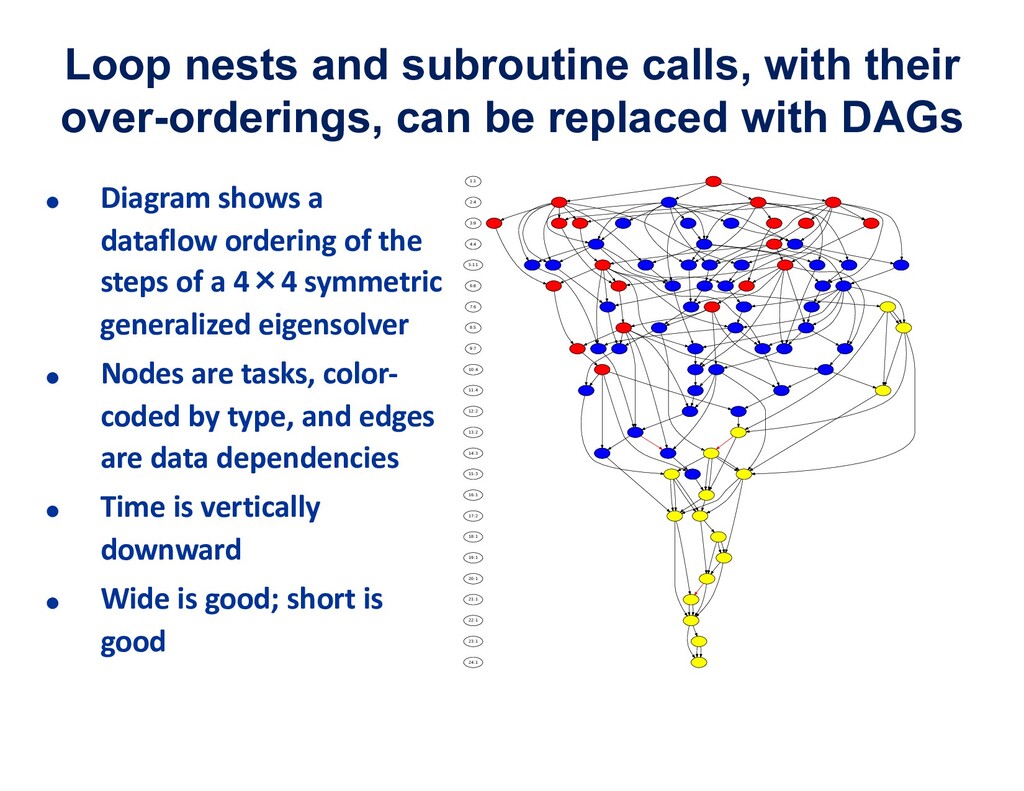{kind=link}
{kind=link}
![Key tool: hierarchical matrices • [Hackbusch, 1999] : off-diagonal blocks](https://files.speakerdeck.com/presentations/2b0d80daede741b89570f2929d9bea97/slide_64.jpg){kind=link}
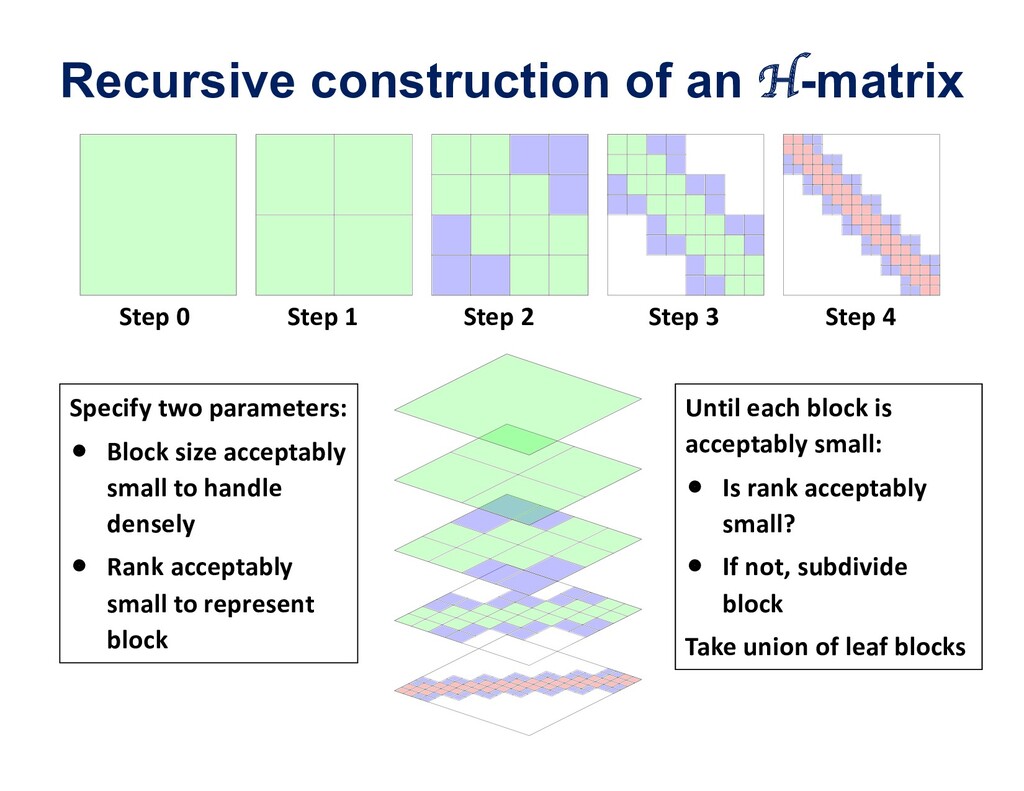{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![Thank you! [email protected]](https://files.speakerdeck.com/presentations/2b0d80daede741b89570f2929d9bea97/slide_75.jpg){kind=link}