私達のチームでは、Amazon RedshiftやSnowflakeと「dbt」を用いたサーバレスなデータプラットフォームである「dbt-template」ソリューションと、コンサルティングサービスをご提供しております。
本日は、 「dbt-template」のAmazon Athena対応で得られた技術調査の結果と、テーブルフォーマット「Iceberg」と「dbt」対応について、ちょっぴりDiveDeepしたいと思います。
前半は、現在イチオシAmazon Athenaのテーブルフォーマット「Apache Iceberg」のご紹介、後半はdbtをAmazon Athenaに対応させるアダプタ「dbt-athena」を紹介します。
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
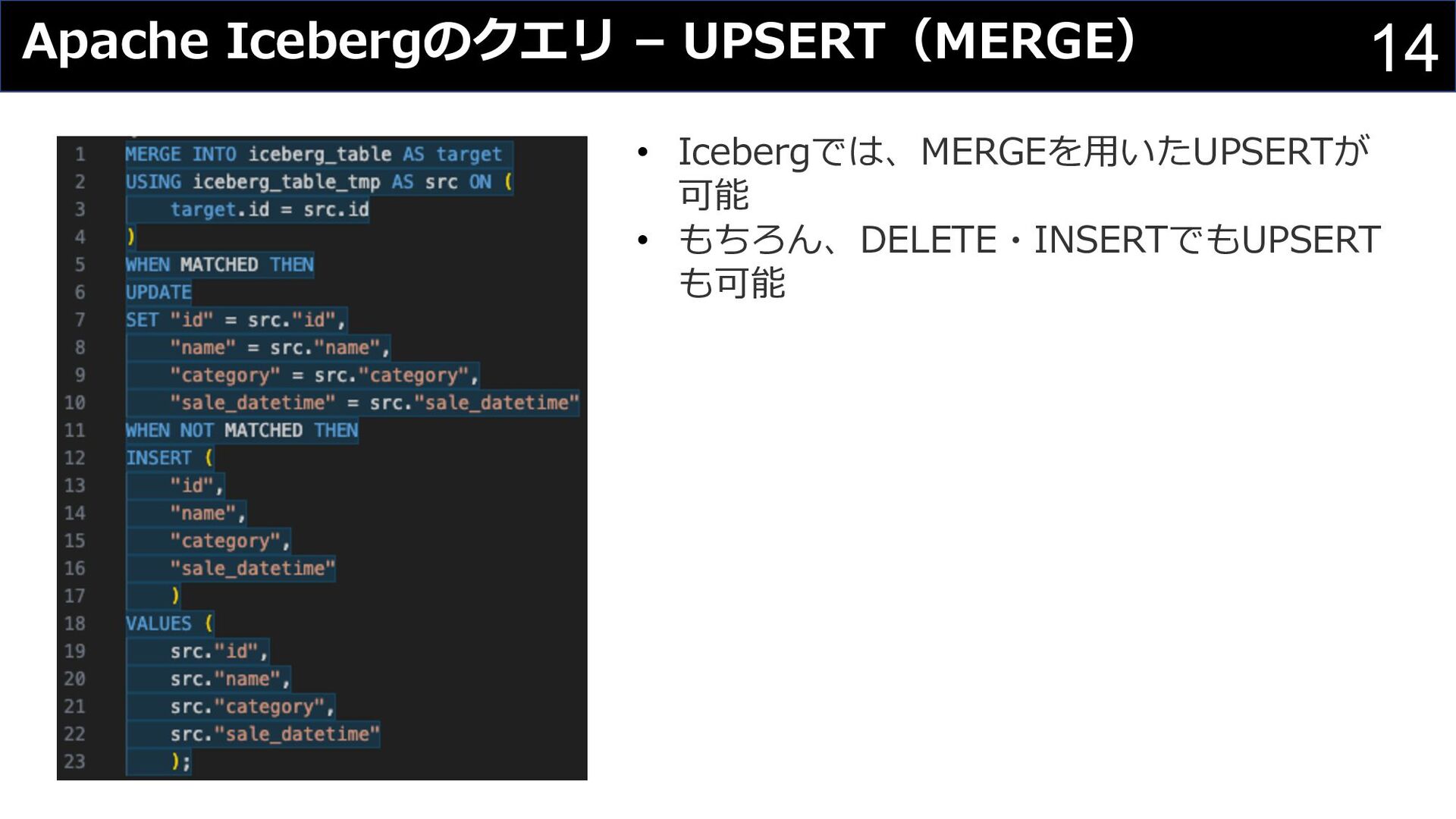{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
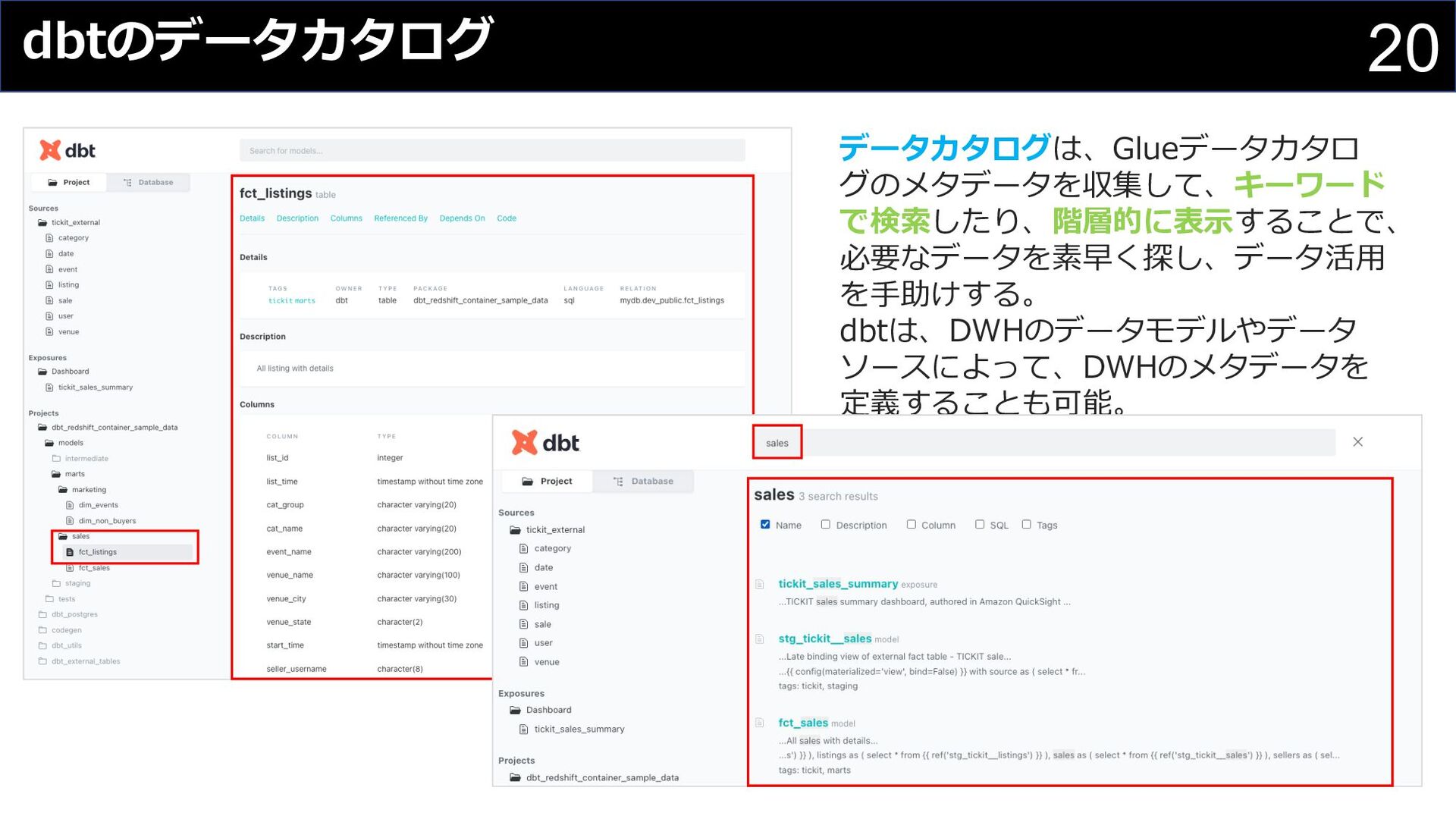{kind=link}
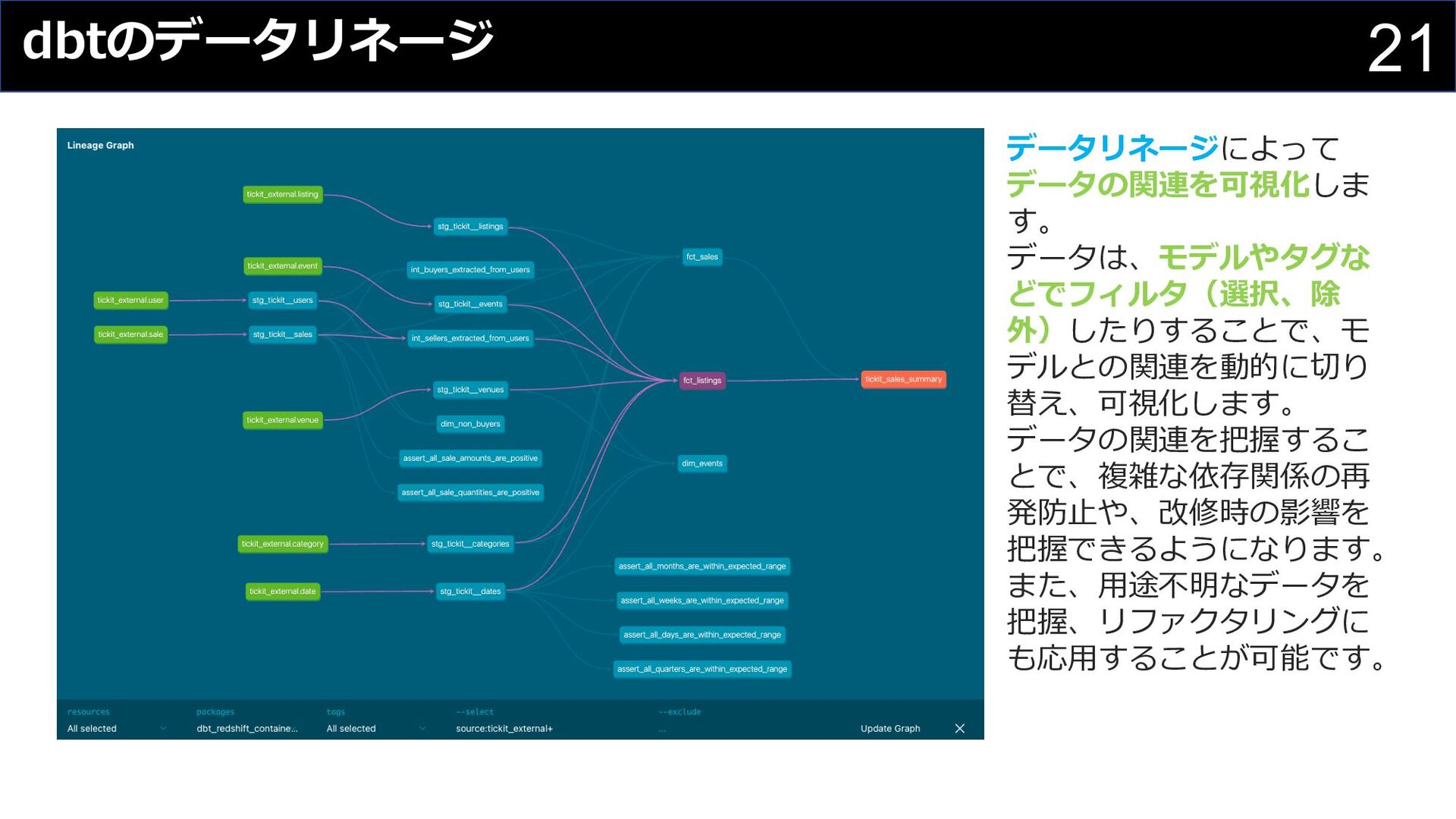{kind=link}
{kind=link}
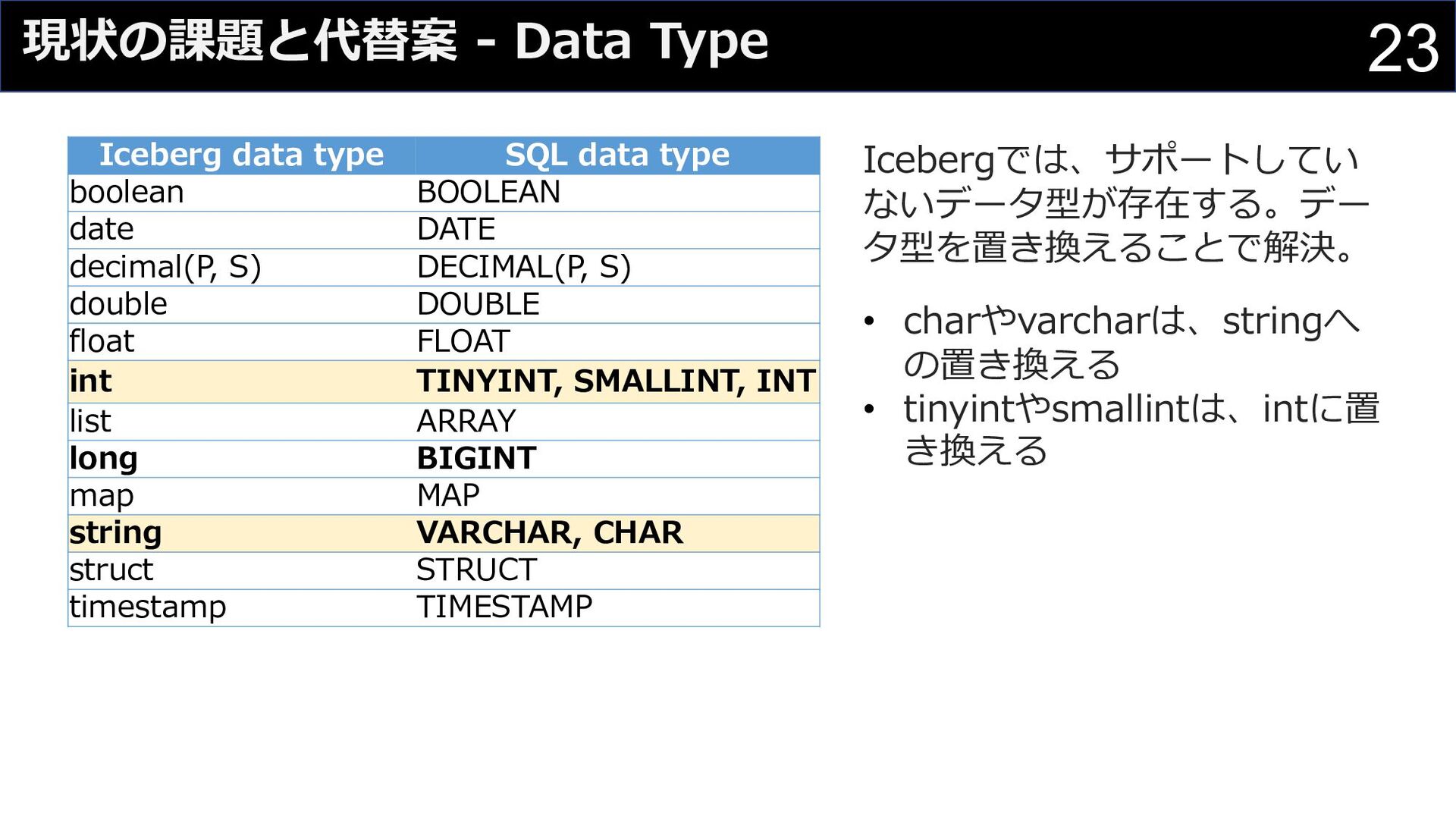{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}