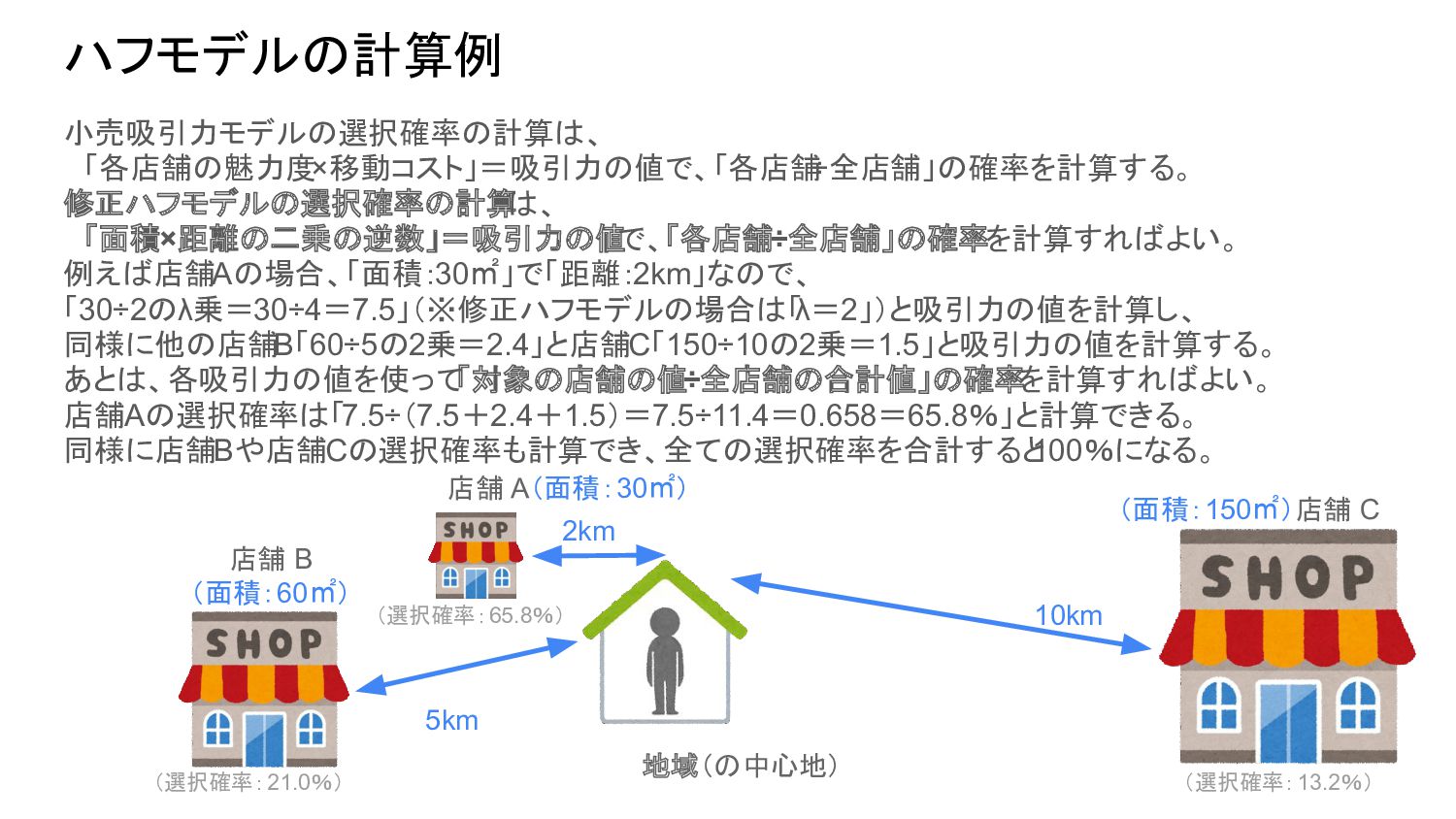
150.0, 2.0, 5.0, 10.0], [2, 190.0, 100.0, 80.0, 10.0, 10.0, 12.0], [3, 100.0, 100.0, 140.0, 17.0, 17.0, 4.0], [4, 140.0, 130.0, 180.0, 13.0, 5.0, 10.0], [5, 170.0, 200.0, 40.0, 12.0, 15.0, 15.0], [6, 50.0, 170.0, 120.0, 3.0, 6.0, 8.0] ], columns=['地域', '面積-店舗A', '面積-店舗B', '面積-店舗C', '距離-店舗A', '距離-店舗B', '距離-店舗C']) display(df) lambda_var = 2 # 修正ハフモデルの場合 gravity_a = df['面積-店舗A'] / (df['距離-店舗A'] ** lambda_var) gravity_b = df['面積-店舗B'] / (df['距離-店舗B'] ** lambda_var) gravity_c = df['面積-店舗C'] / (df['距離-店舗C'] ** lambda_var) # 店舗A/店舗B/店舗Cの選択確率を計算して出力する selection_probability_a = gravity_a / (gravity_a + gravity_b + gravity_c) selection_probability_b = gravity_b / (gravity_a + gravity_b + gravity_c) selection_probability_c = gravity_c / (gravity_a + gravity_b + gravity_c) print(selection_probability_a) print(selection_probability_b) print(selection_probability_c) ハフモデルの「選択確率」計算のPythonコード例 各店舗の吸引力 (=「面積×距離のλ乗の逆数」) 「地域1(インデックス:0)」の選択確率は、 店舗A:65.8%、店舗B:21.0%、店舗C:13.2% 選択確率(=各吸引力の値を使って 「各店舗÷全店舗」の確率を計算)
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}