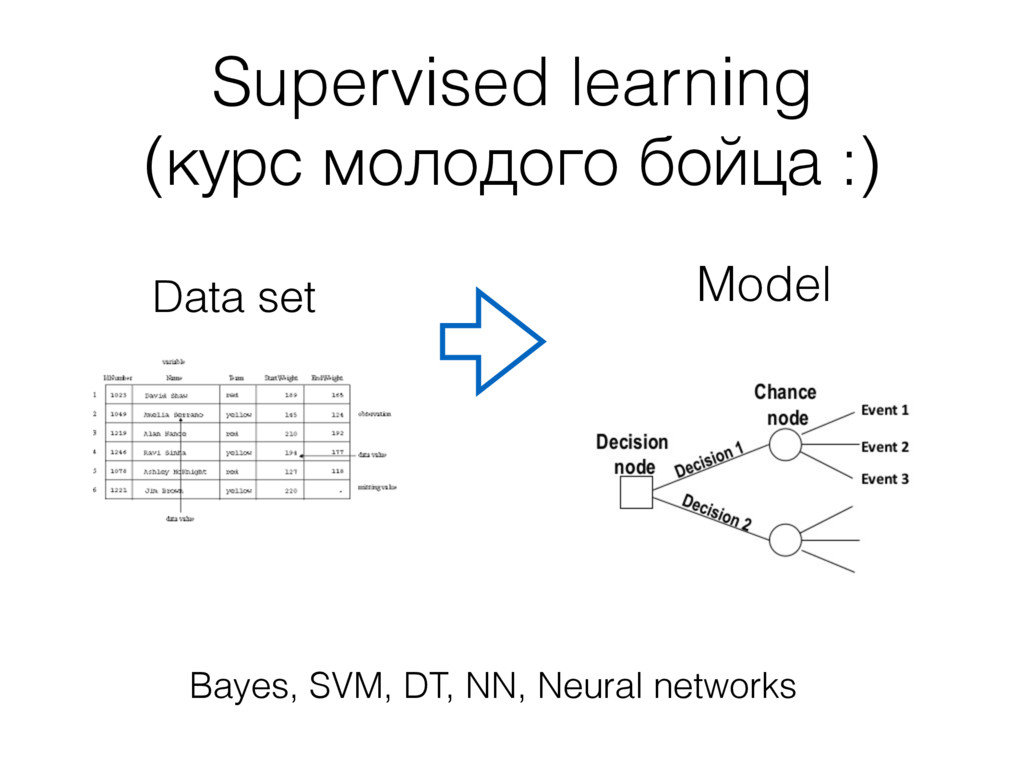
• 5 years at Yandex, search quality department: social and QA search, snippets. • 2 years at Avast! antivirus, research team: automatic false positive solving, large scale prediction of malicious download attempts. About myself 2
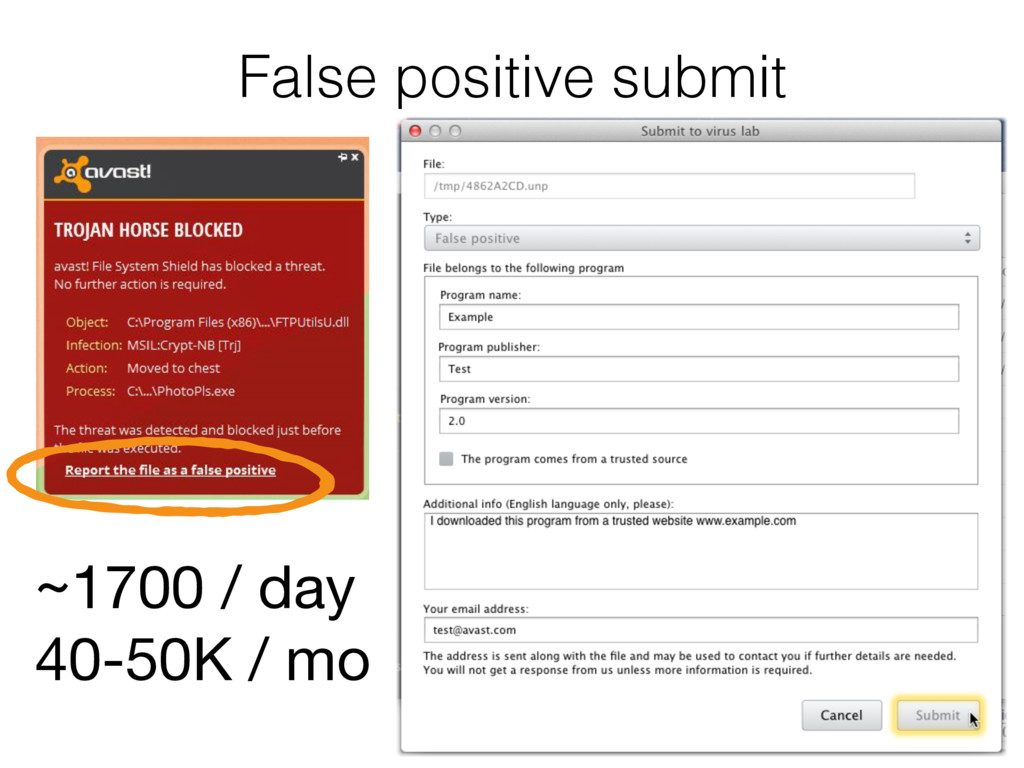
classified as malicious FP: malicious sample, classified as clean Neg TN: clean sample and classified as clean FN: clean file, but classified as malicious User by sending FP submit thinks that sample is clean.
total=239, pr=96.0%, re=81.4% 2: fp=14 (0.0586), fn=3(0.0126), tp=124, tn=98, total=239, pr=97.0%, re=87.5% 3: fp=17 (0.0711), fn=5(0.0209), tp=136, tn=81, total=239, pr=94.2%, re=82.7% 4: fp=18 (0.0753), fn=5(0.0209), tp=129, tn=87, total=239, pr=94.6%, re=82.9% 5: fp=26 (0.1088), fn=11(0.0460), tp=111, tn=91, total=239, pr=89.2%, re=77.8% What do you want to know? How model performs by class? How many errors and of what type it makes? How resistant it is to sampling?
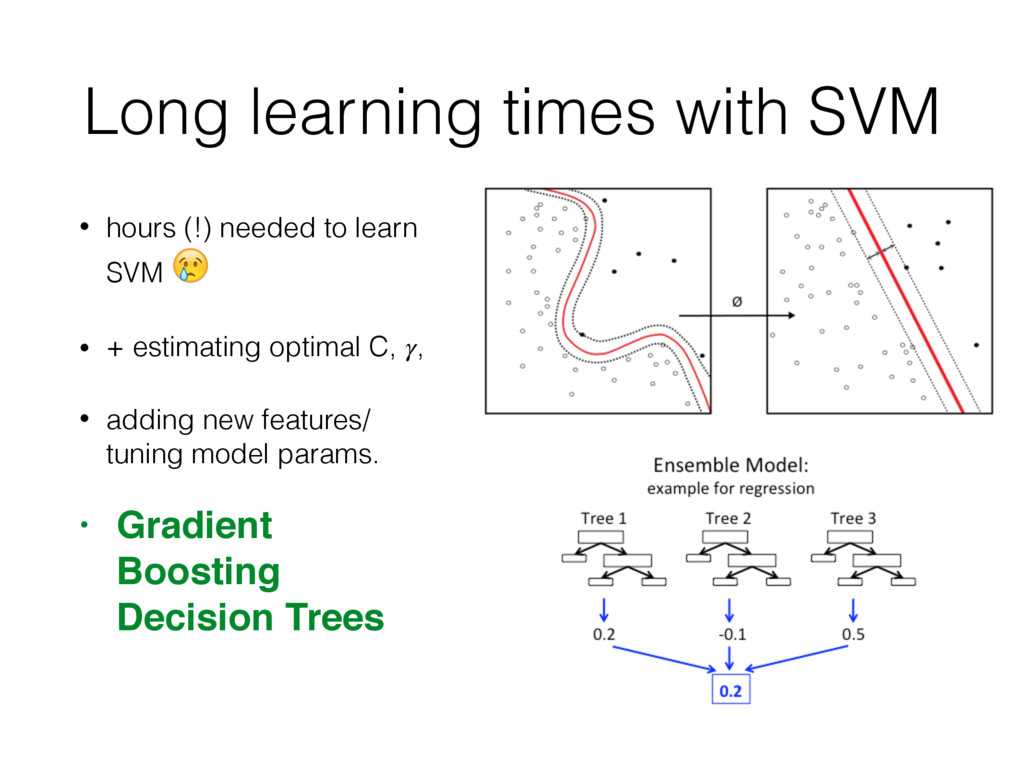
less. • Start with small, but reasonable size. • New data source? New signals ideas? If not - increase the training set. • We finished at 10K samples and 155 signals.
input, as a final test • «middle» values: (neg) 0.2 < X < 0.85 (pos) for ~2% • backends gone MAD! • judging of such samples was • add to training set (active learning)
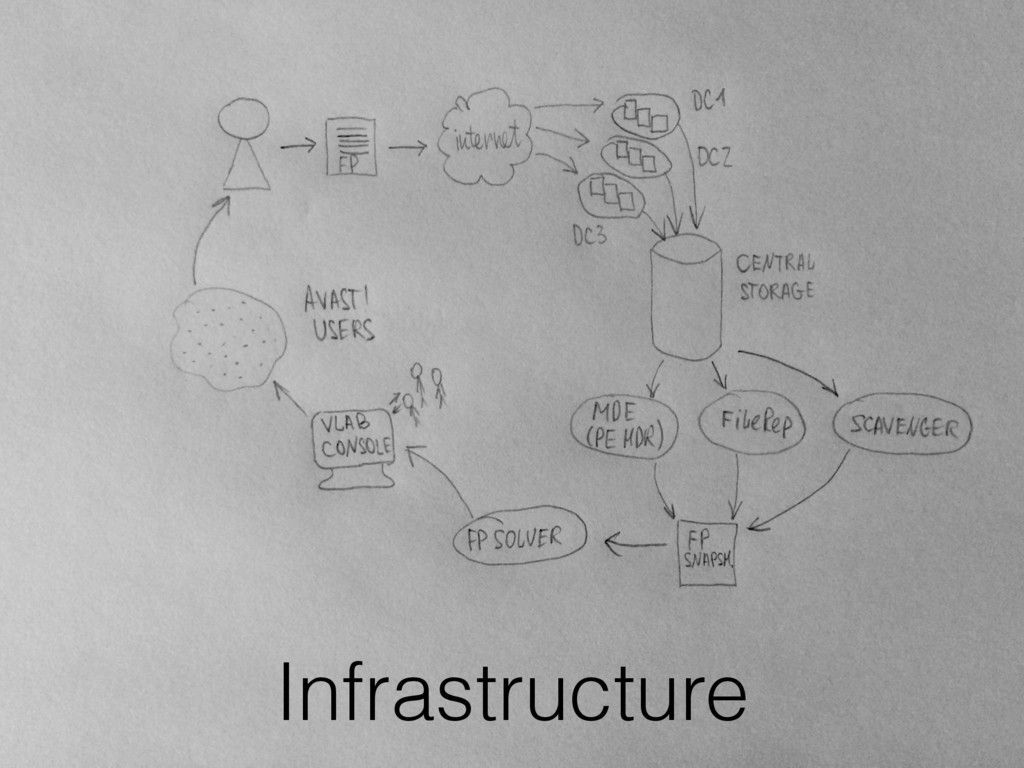
console: • UI with analyst and classifier grades, • Errors graphs by days. • Gradual process: • Analytics assistant: all decisions were being checked. • Post-check: next month. • Fully standalone operation, with monthly sample checks.
sets. • Continuous process, not a single-time model. • Infrastructure and periodical performance monitoring. • Using input stream for evaluation instead of test set. • Recovery process.
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![Владельцы файла, FileRep J. Horky, [email protected]](https://files.speakerdeck.com/presentations/b942b819171c47038fa06a901f873acc/slide_9.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![Questions? Thank you! Alexander Sibiryakov, [email protected]](https://files.speakerdeck.com/presentations/b942b819171c47038fa06a901f873acc/slide_33.jpg){kind=link}