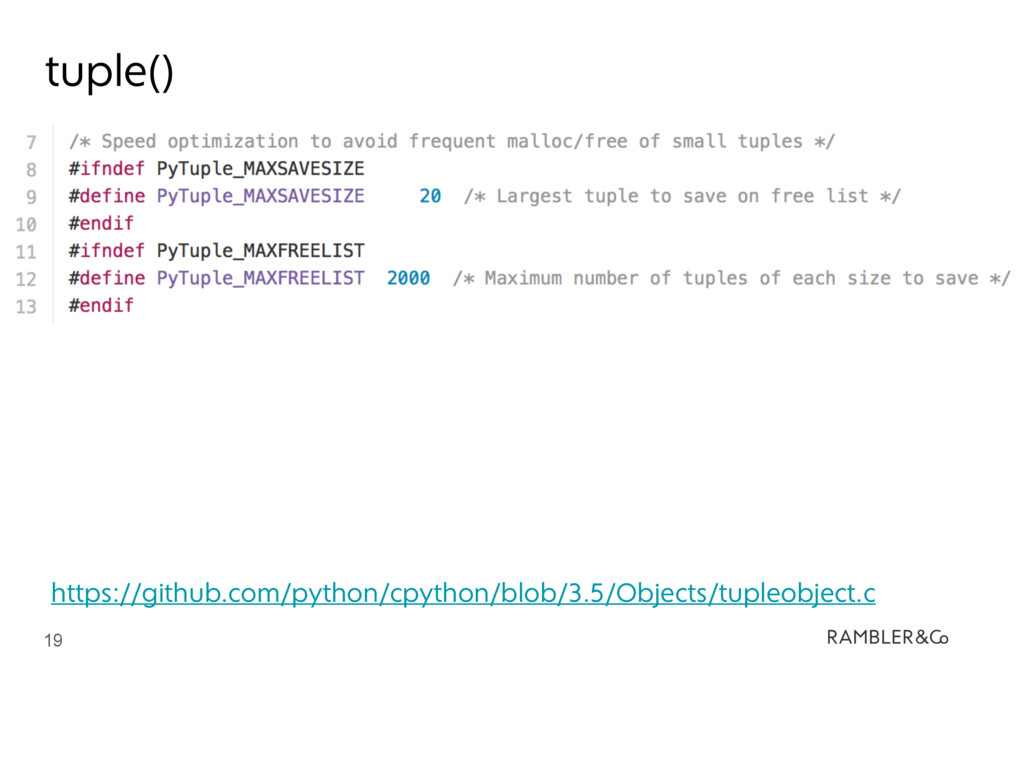
propose to change the internal representation of the String class from a UTF-16 char array to a byte array plus an encoding-flag field. The new String class will store characters encoded either as ISO-8859-1/ Latin-1 (one byte per character), or as UTF-16 (two bytes per character), based upon the contents of the string. The encoding flag will indicate which encoding is used. …. http://openjdk.java.net/jeps/254
Unicode strings: - compact ascii: … - compact: … - legacy string, not ready: … - legacy string, ready: … Compact strings use only one memory block (structure + characters), whereas legacy strings use one block for the structure and one block for characters. https://github.com/python/cpython/blob/3.5/Include/unicodeobject.h
interpreter is now about 7% faster due to optimized instruction decoding. Based on patch by Demur Rumed. •Issue #26647: Python interpreter now uses 16-bit wordcode instead of bytecode. Patch by Demur Rumed.
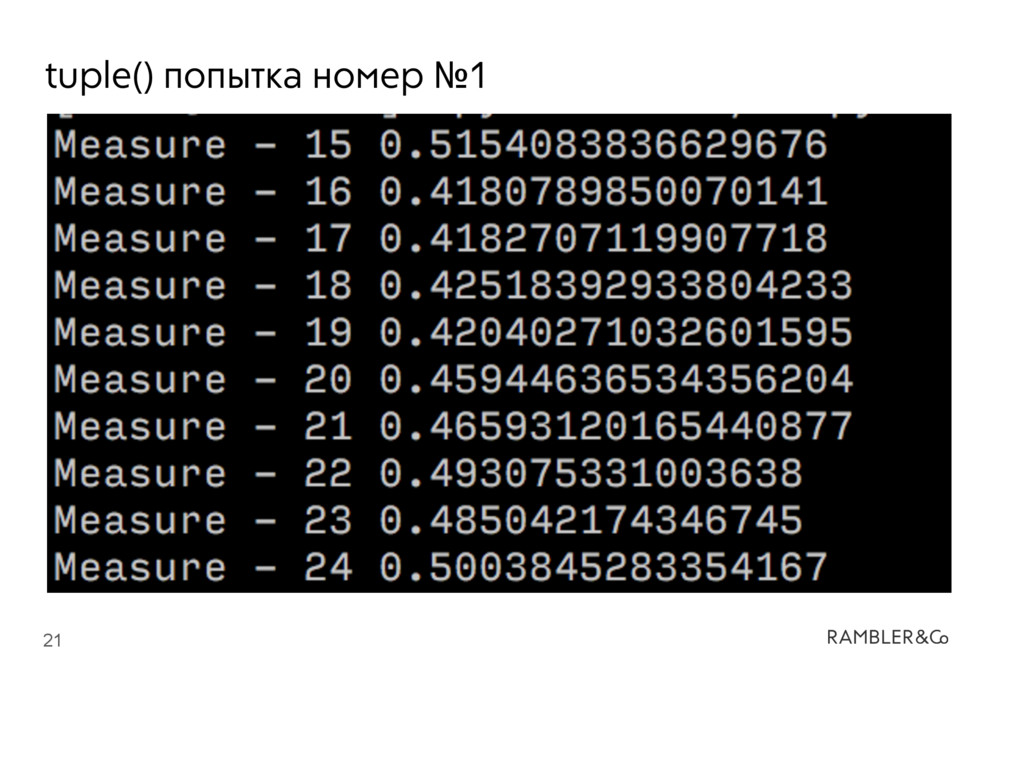
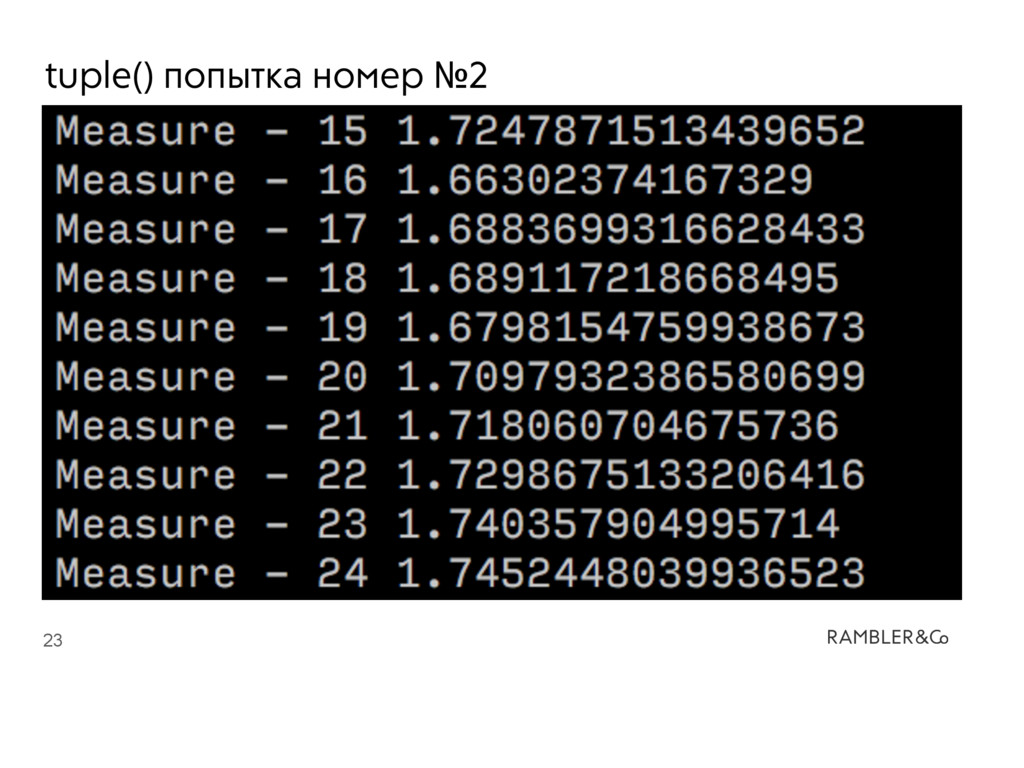
оптимизаций • Оптимизации ориентированы на “средний” случай • Возможность для дальнейших оптимизаций есть, над ними работают и они будут • Оптимизации могут мешать корректным замерам
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![0 in set([0]) 8](https://files.speakerdeck.com/presentations/752f0ec515c34cfb9906ef799261dcf0/slide_7.jpg){kind=link}
![0 in set([0]) 9](https://files.speakerdeck.com/presentations/752f0ec515c34cfb9906ef799261dcf0/slide_8.jpg){kind=link}
![0 in set([0]) 10](https://files.speakerdeck.com/presentations/752f0ec515c34cfb9906ef799261dcf0/slide_9.jpg){kind=link}
![0 in set([0]) 11](https://files.speakerdeck.com/presentations/752f0ec515c34cfb9906ef799261dcf0/slide_10.jpg){kind=link}
![0 in set([0]) 12](https://files.speakerdeck.com/presentations/752f0ec515c34cfb9906ef799261dcf0/slide_11.jpg){kind=link}
![0 in set([0]) 13 (c) https://github.com/python/cpython/blob/3.5/Objects/setobject.c](https://files.speakerdeck.com/presentations/752f0ec515c34cfb9906ef799261dcf0/slide_12.jpg){kind=link}
![0 in set([0]) 14](https://files.speakerdeck.com/presentations/752f0ec515c34cfb9906ef799261dcf0/slide_13.jpg){kind=link}
![0 in set([0]) 15 (c) https://bugs.python.org/issue18771](https://files.speakerdeck.com/presentations/752f0ec515c34cfb9906ef799261dcf0/slide_14.jpg){kind=link}
![0 in set([0]) 16](https://files.speakerdeck.com/presentations/752f0ec515c34cfb9906ef799261dcf0/slide_15.jpg){kind=link}
![0 in set([0]) 17](https://files.speakerdeck.com/presentations/752f0ec515c34cfb9906ef799261dcf0/slide_16.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
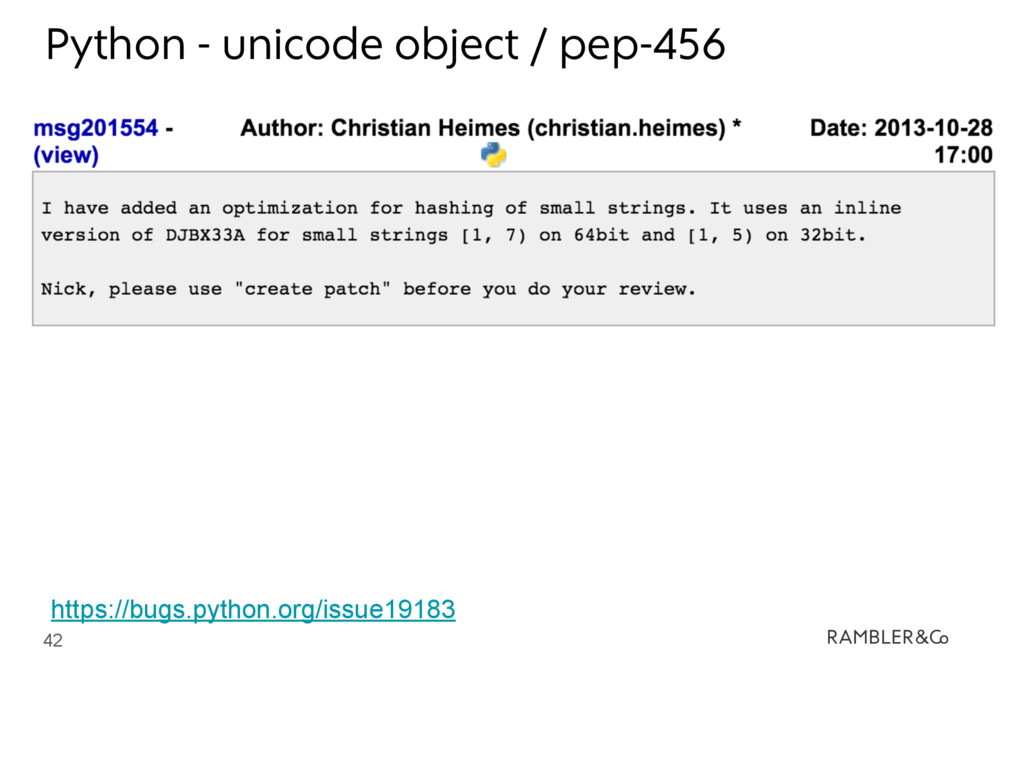{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
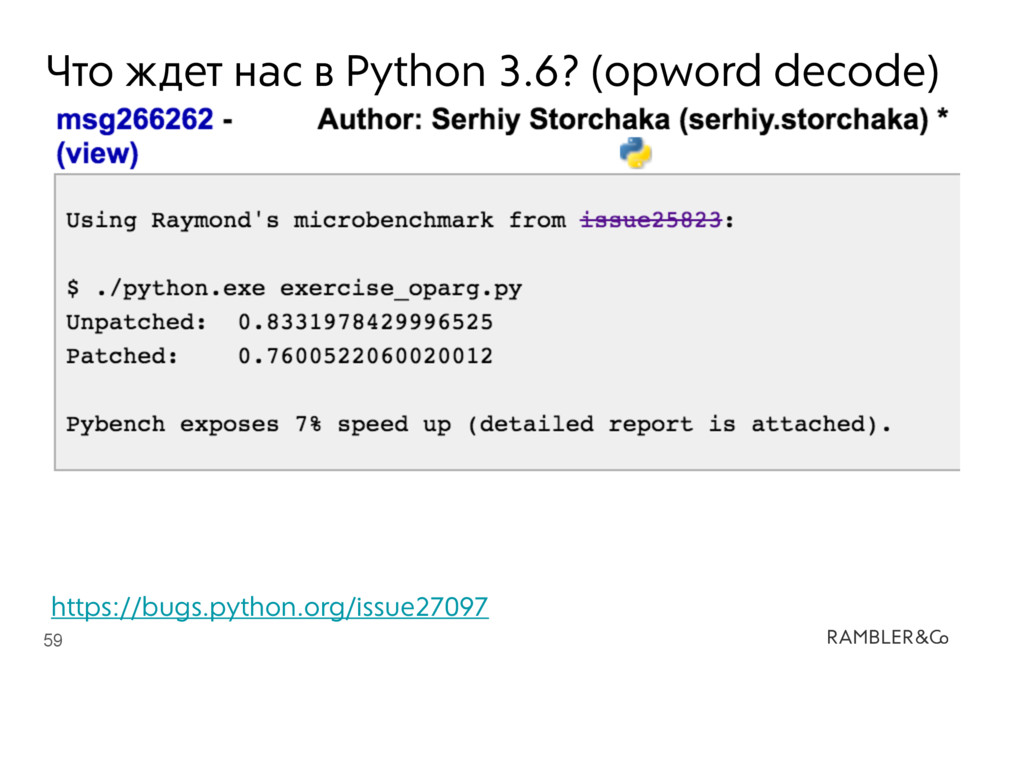{kind=link}
{kind=link}
![Вопросы? [email protected]](https://files.speakerdeck.com/presentations/752f0ec515c34cfb9906ef799261dcf0/slide_60.jpg){kind=link}