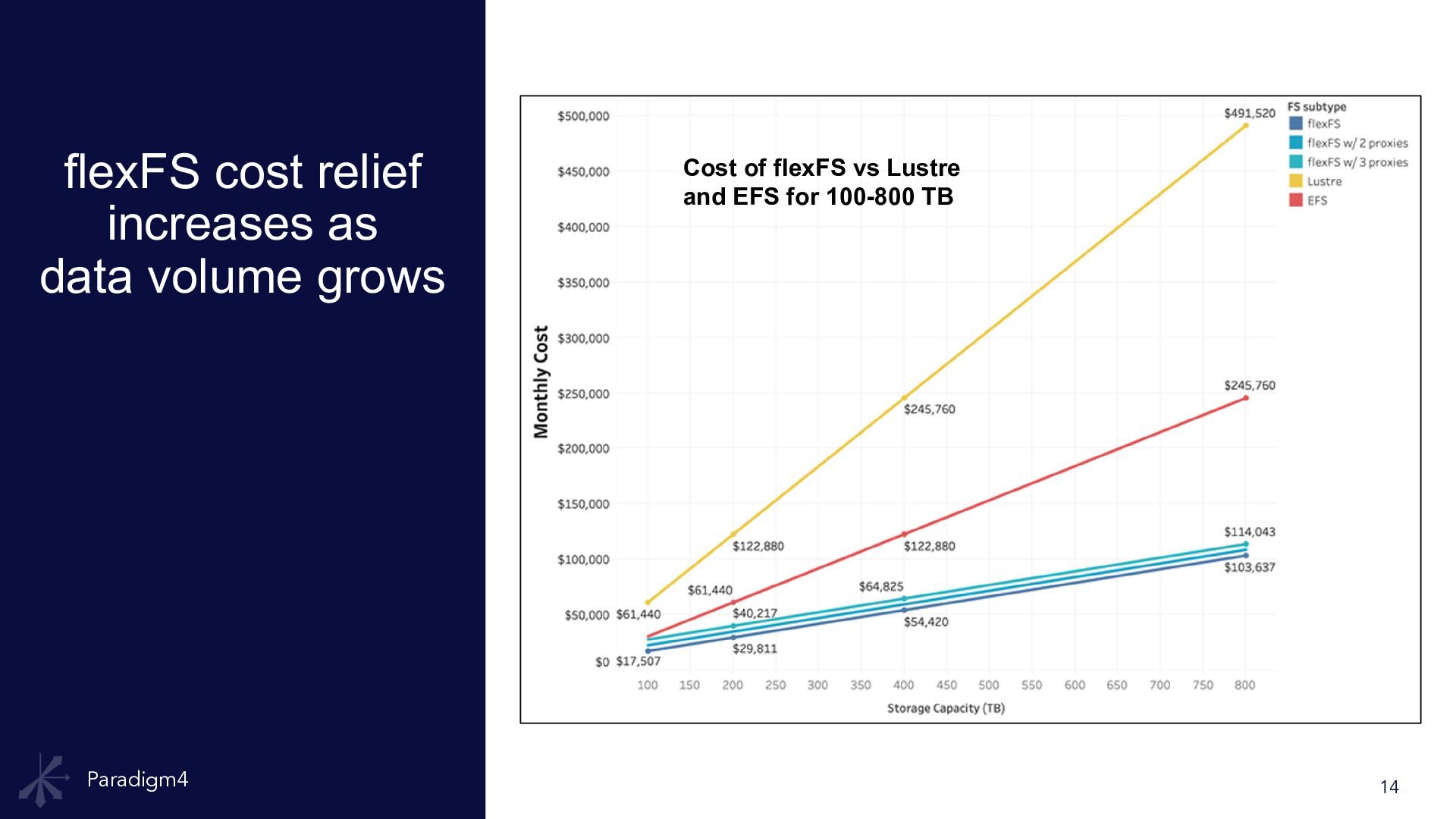
travel Point-in-time recovery at no added cost. AWS Backup for FSx = $0.047/GB-mo; EFS = $0.050/GB-mo. At 1.14 PB scale that's ~$32K/mo if done separately. 🌐 Native multi-AZ — zero transfer cost flexFS serves data across AZs transparently. EFS charges $0.01/GB cross-AZ. FSx Lustre is single-AZ by default. flexFS incurs no cross-AZ transfer charges. ↕ True elasticity — no over- provisioning flexFS grows and shrinks automatically; you pay for bytes used. FSx requires capacity in 2.4 TiB increments and cannot shrink — wasting $332K over 43 months. 🔐 Extended POSIX ACLs for clinical data setfacl/getfacl works uniformly across HPC, AWS Batch, Databricks, and REVEAL. EFS uses NFSv4 ACLs (complex). S3 has IAM/bucket policies only — no POSIX ACLs. ⚡ Proxy group shared caching Reference genomes (30+ GB) cached once across all compute nodes. FSx: each client warms its own cache independently. EFS: no client-side caching layer. 💻 All Linux flavors + macOS Single mount on Amazon Linux, Ubuntu, RHEL, and macOS via NFS re-export. FSx requires the Lustre kernel module — not available on macOS or non-Amazon Linux. 🔗 Single namespace across all services Same /flexfs path from HPC/SLURM, AWS Batch, Databricks, REVEAL, and HTTP. AWS stack requires separate NFS mounts, S3 URIs, and Lustre mounts per service type. 📉 Cost efficiency improves at scale flexFS effective rate fell from ~$90/TB- mo at 25 TB (2022) to ~$66/TB-mo at 1.14 PB (2026). EFS Standard stays flat at $307/TB-mo. FSx stays flat at $174/TB-mo.
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![26 26 26 Paradigm4 www.flexFS.io [email protected] Thank you](https://files.speakerdeck.com/presentations/3561614889f24a06a91879f36329556a/slide_25.jpg){kind=link}