systems software engineering Dell, IBM, HP, Lucent Technologies • Expertise: AI infrastructure, cloud-native storage, and high-performance computing, Linux kernel, device drivers, and distributed storage systems. • Creator of MAYASTOR Early software-defined storage platform for iSCSI/FC SAN in 2007. • Founder of Zettalane Systems Cloud-native storage with ZFS and NVMe-oF 70% cost savings vs traditional cloud storage.
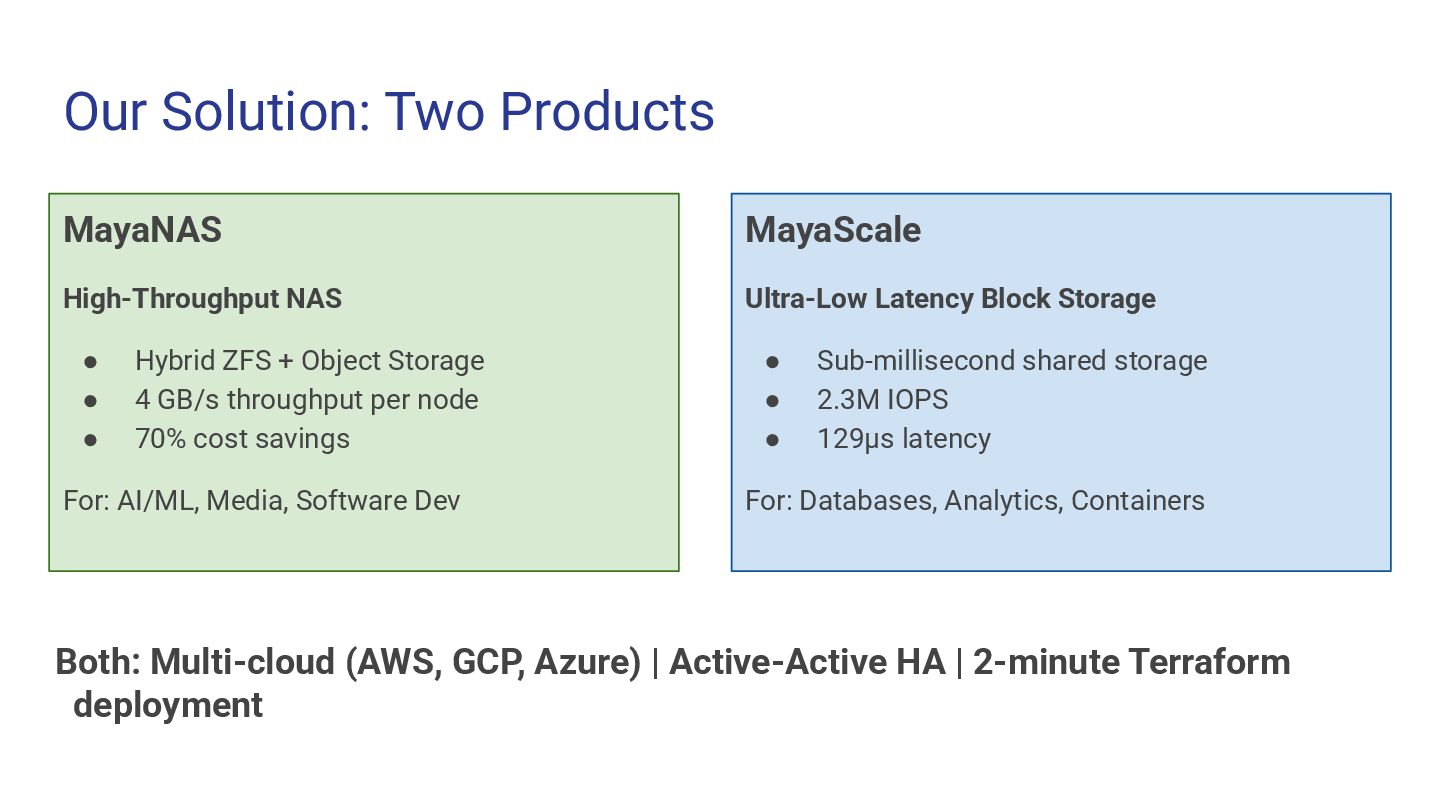
to use, affordable, scalable and highly reliable solutions using Object storage and ephemeral NVMe storage. Our Approach: ✓ Easy to Use One-click deployment, infrastructure-as-code ✓ Cost-effective 70% cost savings vs traditional cloud storage ✓ Scalable From TBs to PBs with hybrid architecture ✓ Highly Reliable Active-Active HA, ZFS Snapshots with data integrity, multi-cloud
NAS Storage So Expensive? How do we get NAS (NFS/SMB) with object storage economics? How do we get NAS (NFS/SMB) with object storage economics? Block Storage (AWS EBS gp3): $0.08/GB/month 100 TB = $96,000/year Managed File (AWS EFS): $0.30/GB/month 100 TB = $360,000/year Beyond Cost - Performance Limitations: • Performance requires scale Advertised throughput only at 100TB+ • Per-client throughput bottleneck High aggregate, but individual clients starve • Legacy fan-out architecture One big pipe shared across many small connections
files • Metadata • Job parameters Needs: Low latency, high IOPS ↓ ZFS Special on NVMe LARGE DATA BLOCKS • Archives • Media files • Datasets, Results Needs: Low cost, high throughput ↓ Object Storage Example: HPC Job Scheduler (MathWorks-style) Phase 1: Config storm → Small file IOPS (NVMe) Phase 2: Job execution → Large sequential (Object) Same filesystem handles both - no data movement
• FUSE layer (slow) • Large IO gets split to 4KB • Single connection requests with limited concurrency • unable to exploit full potential of object storage objbacker.io • Native interface to kernel ZFS vdev • Vendor Go SDKs (S3, GCS, Blob) • Direct I/O to object storage • Extreme concurrent requests for full object storage bandwidth Why Object Storage for Large Sequential I/O? • It is the Cloud-native storage of choice • Higher bandwidth than EBS • Better reliability (11 9's durability) • Infinite scalability • Lower cost
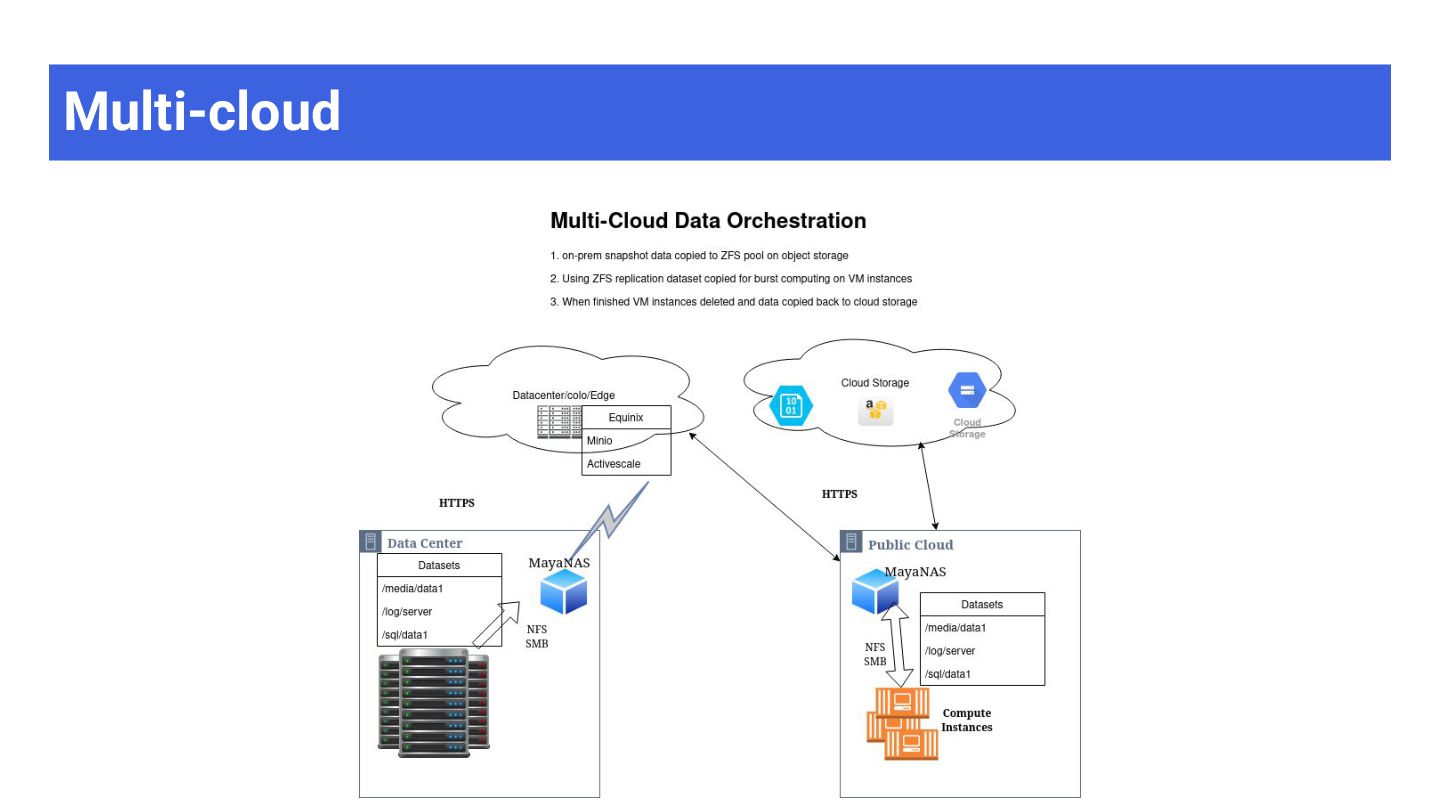
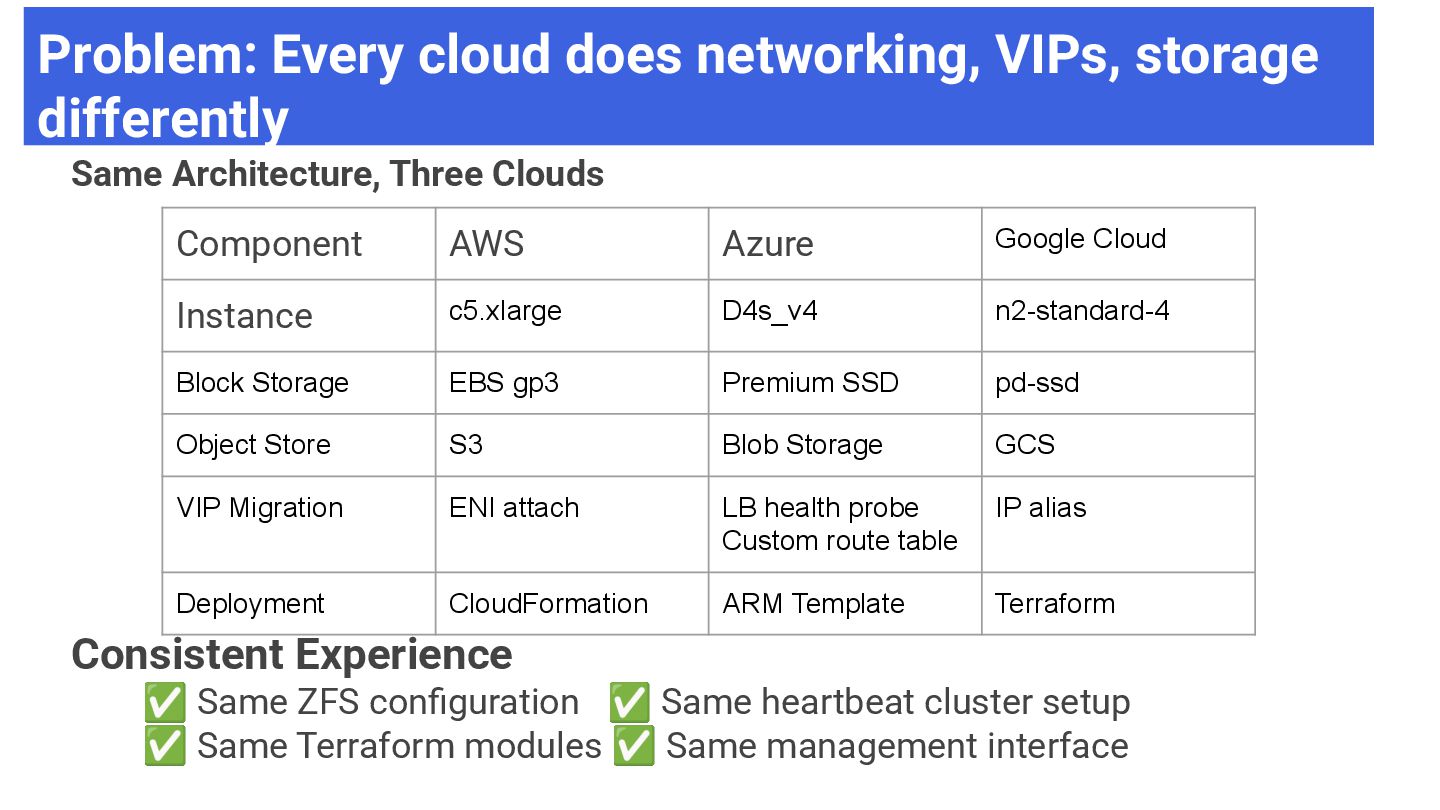
Three Clouds Consistent Experience ✅ Same ZFS configuration ✅ Same heartbeat cluster setup ✅ Same Terraform modules ✅ Same management interface Component AWS Azure Google Cloud Instance c5.xlarge D4s_v4 n2-standard-4 Block Storage EBS gp3 Premium SSD pd-ssd Object Store S3 Blob Storage GCS VIP Migration ENI attach LB health probe Custom route table IP alias Deployment CloudFormation ARM Template Terraform
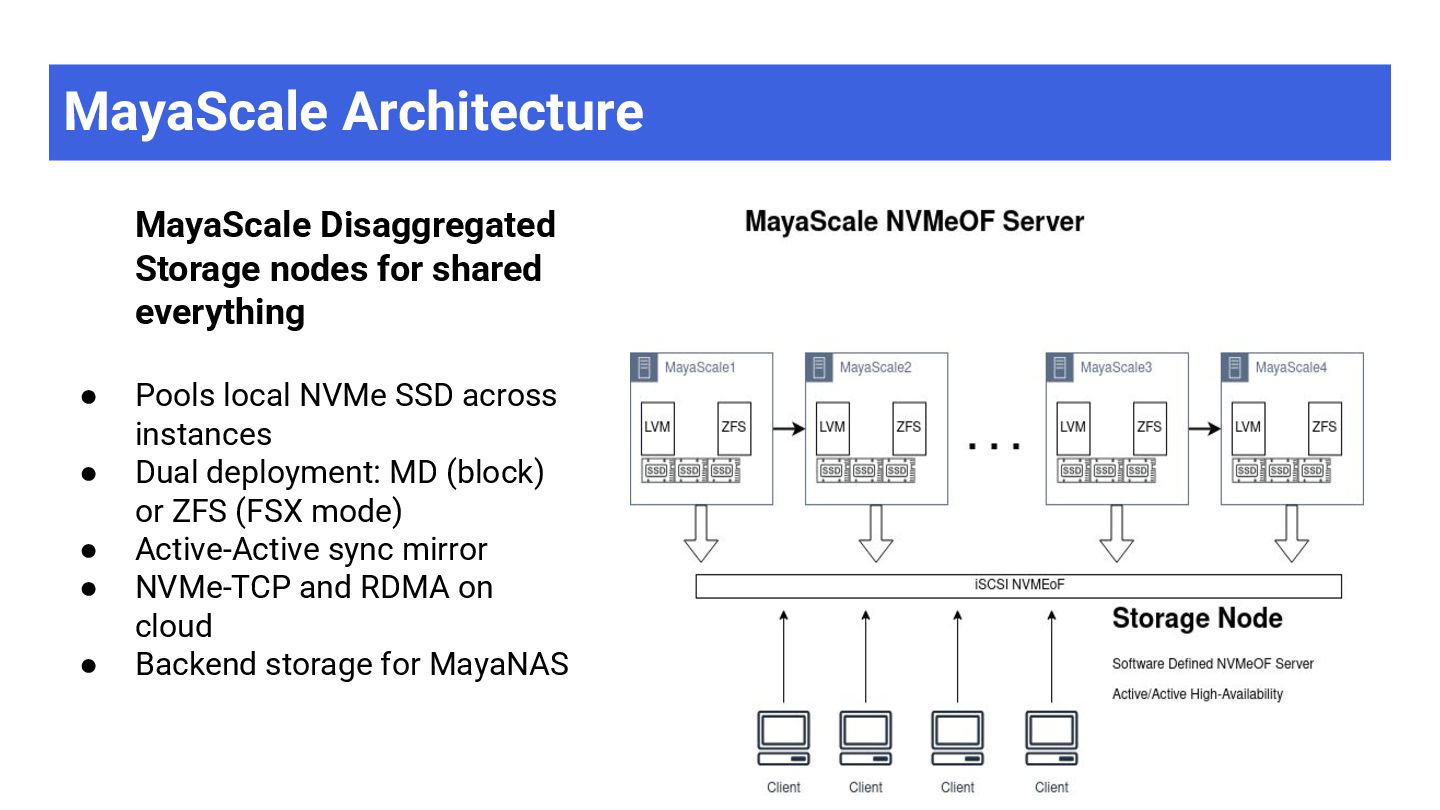
Pools local NVMe SSD across instances • Dual deployment: MD (block) or ZFS (FSX mode) • Active-Active sync mirror • NVMe-TCP and RDMA on cloud • Backend storage for MayaNAS
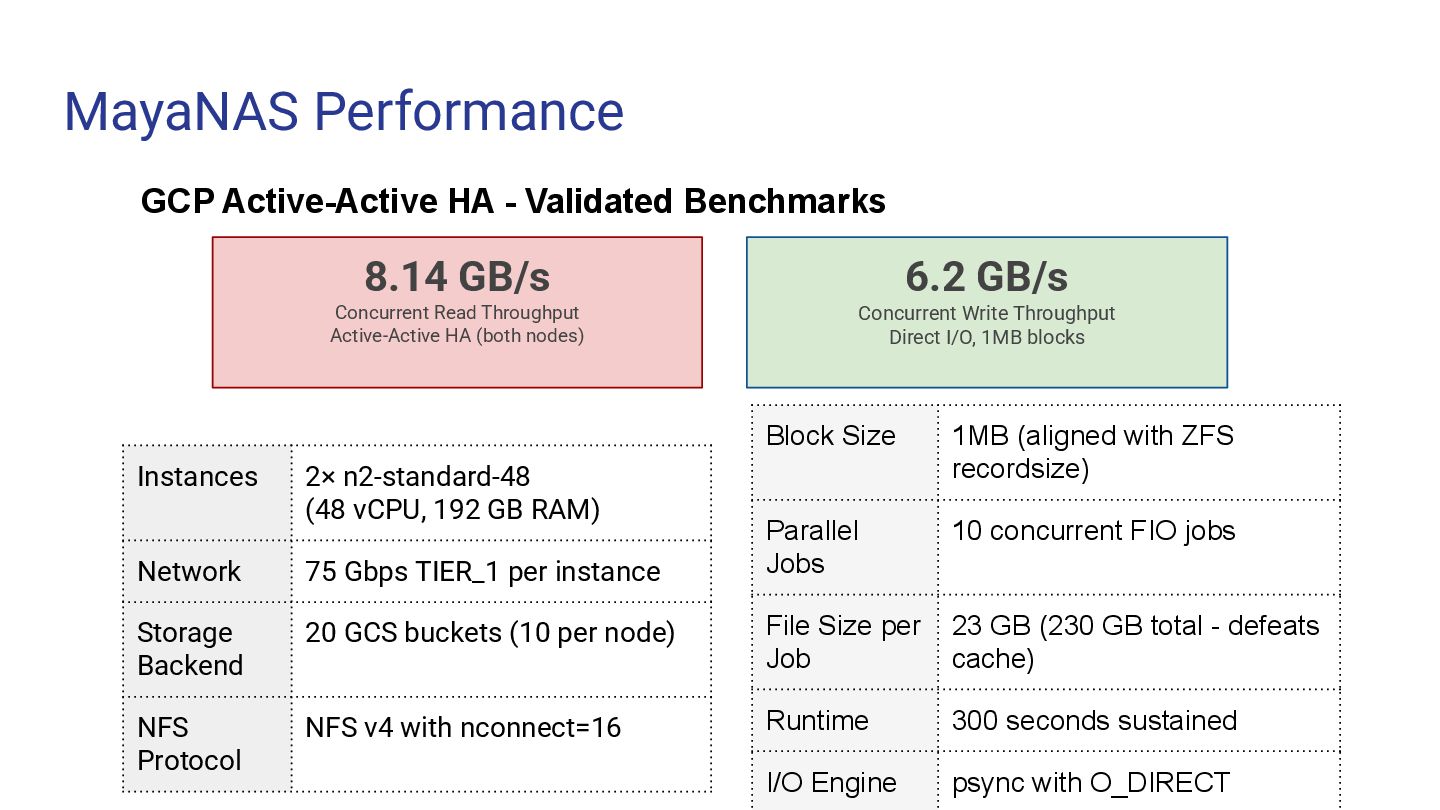
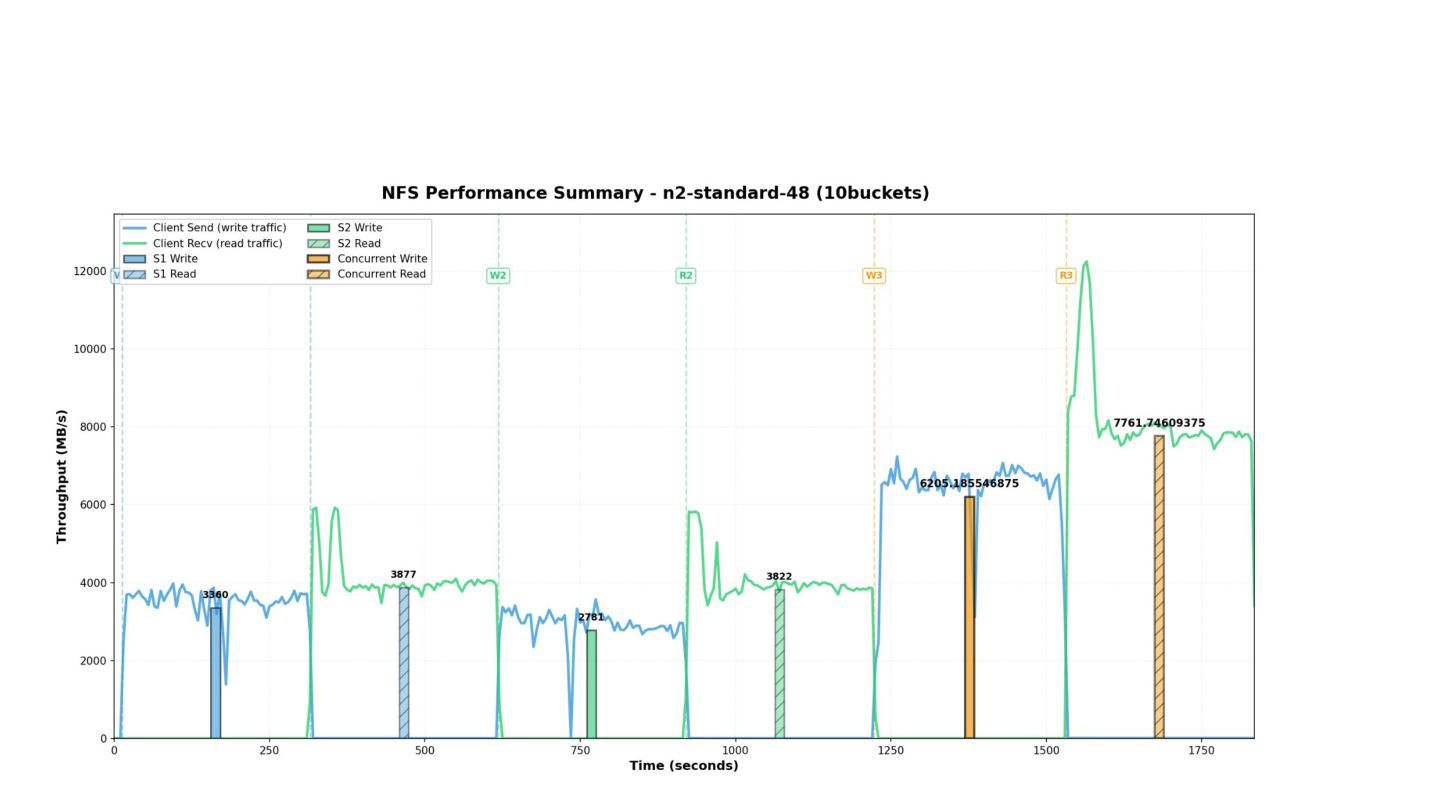
Deploy HA cluster Auto-configure — NFS exports, HA mirroring, VIP mount -t nfs — Mount from client Run benchmark — FIO sequential read/write terraform destroy — Clean teardown From zero to production storage in minutes
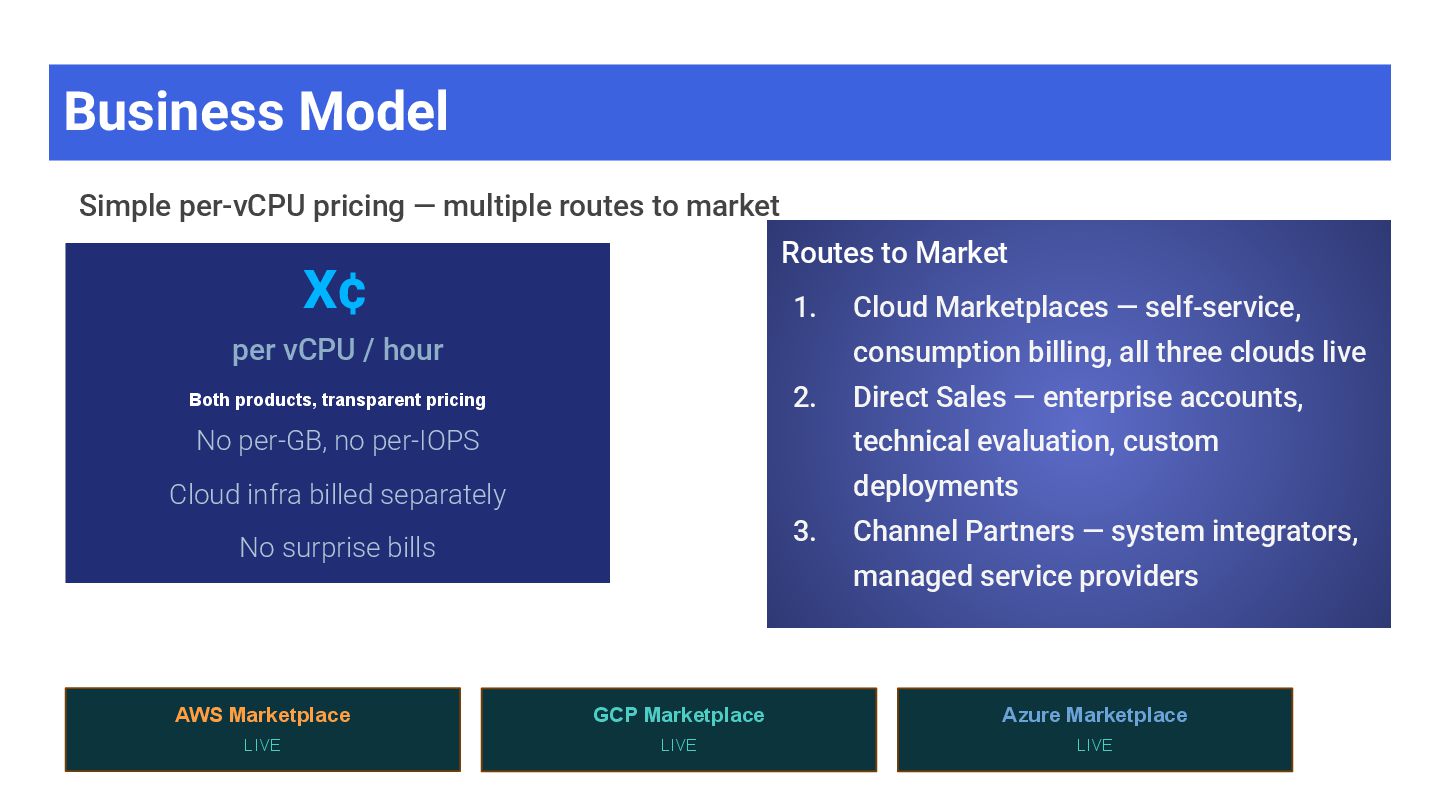
X¢ per vCPU / hour Both products, transparent pricing No per-GB, no per-IOPS Cloud infra billed separately No surprise bills Routes to Market 1. Cloud Marketplaces — self-service, consumption billing, all three clouds live 2. Direct Sales — enterprise accounts, technical evaluation, custom deployments 3. Channel Partners — system integrators, managed service providers AWS Marketplace LIVE GCP Marketplace LIVE Azure Marketplace LIVE
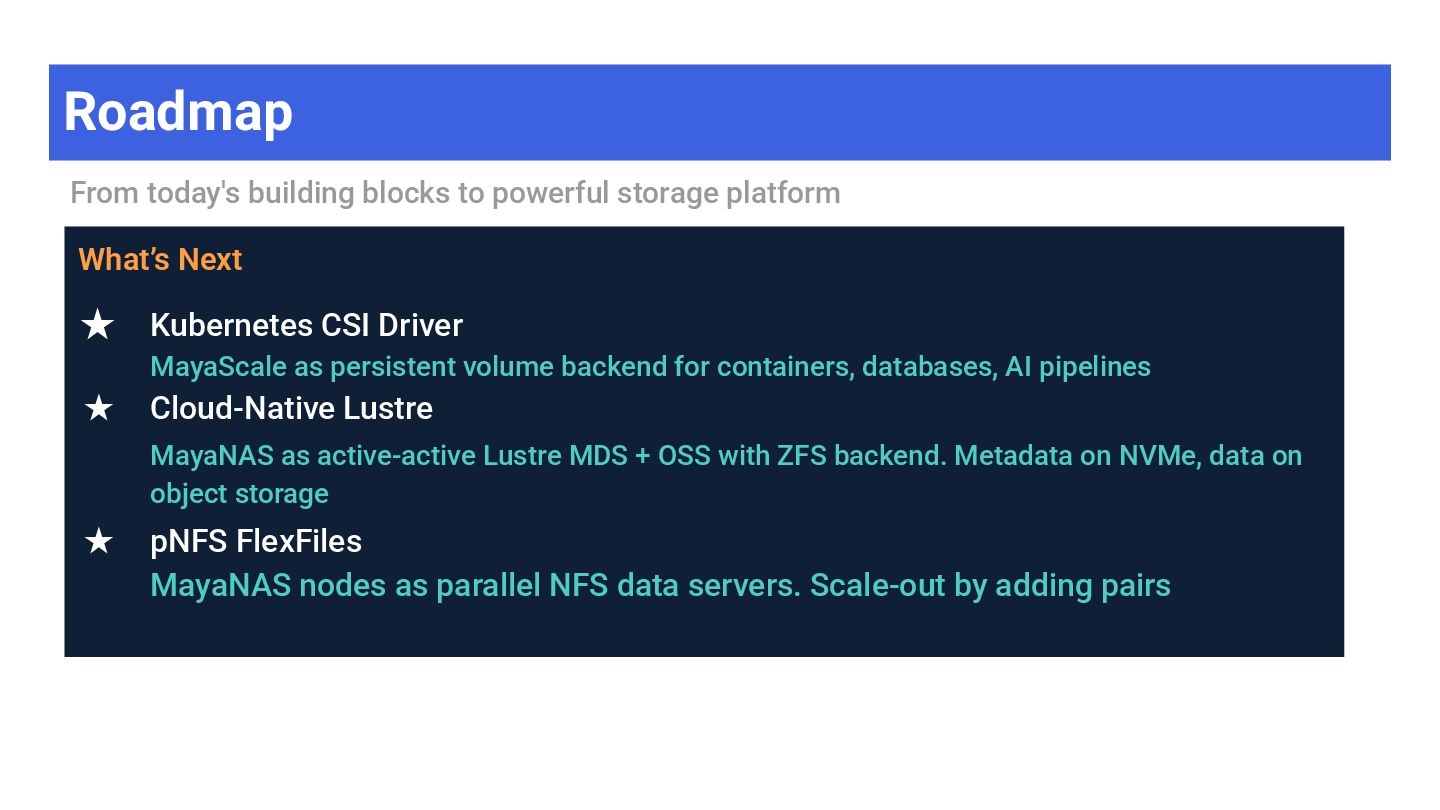
Next ★ Kubernetes CSI Driver MayaScale as persistent volume backend for containers, databases, AI pipelines ★ Cloud-Native Lustre MayaNAS as active-active Lustre MDS + OSS with ZFS backend. Metadata on NVMe, data on object storage ★ pNFS FlexFiles MayaNAS nodes as parallel NFS data servers. Scale-out by adding pairs
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![Thank You ZETTALANE SYSTEMS [email protected] www.zettalane.com ONE PLATFORM · ANY](https://files.speakerdeck.com/presentations/7451a6c8a1cf426fad716db6ca7e46b4/slide_20.jpg){kind=link}