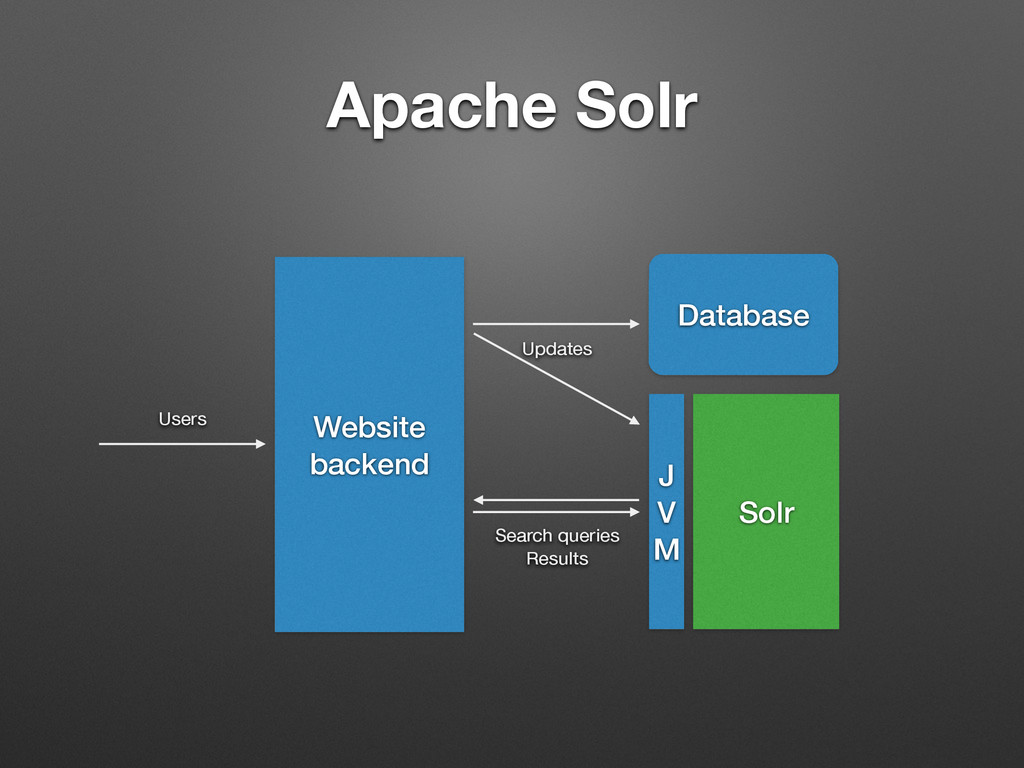
if configured properly • Compensates for human weirdness with language awareness • Does categorisation of results (faceting) • Can find similar documents
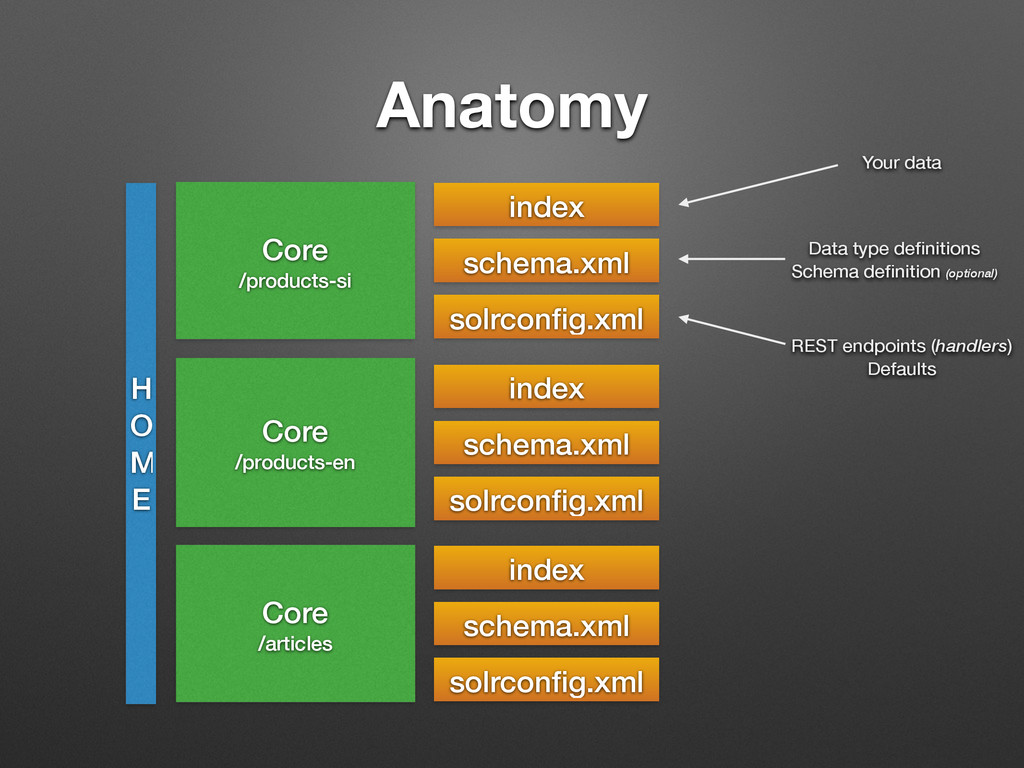
/articles index schema.xml solrconfig.xml index schema.xml solrconfig.xml index schema.xml solrconfig.xml Your data Data type definitions Schema definition (optional) REST endpoints (handlers) Defaults
Defines how language gets processed - <analyzer> / <query> • Fields (columns) and their types - <fields> • Defines which data is kept • See NewsBuddy/solr/config/schema.xml Your CREATE TABLES
default parameters so you don’t have to send them with each request • Here you • Set field importance • Enable highlighting, faceting, more-like-this and other functionality • Customise other search parameters • See NewsBuddy/solr/config/solrconfig.xml Your search defaults
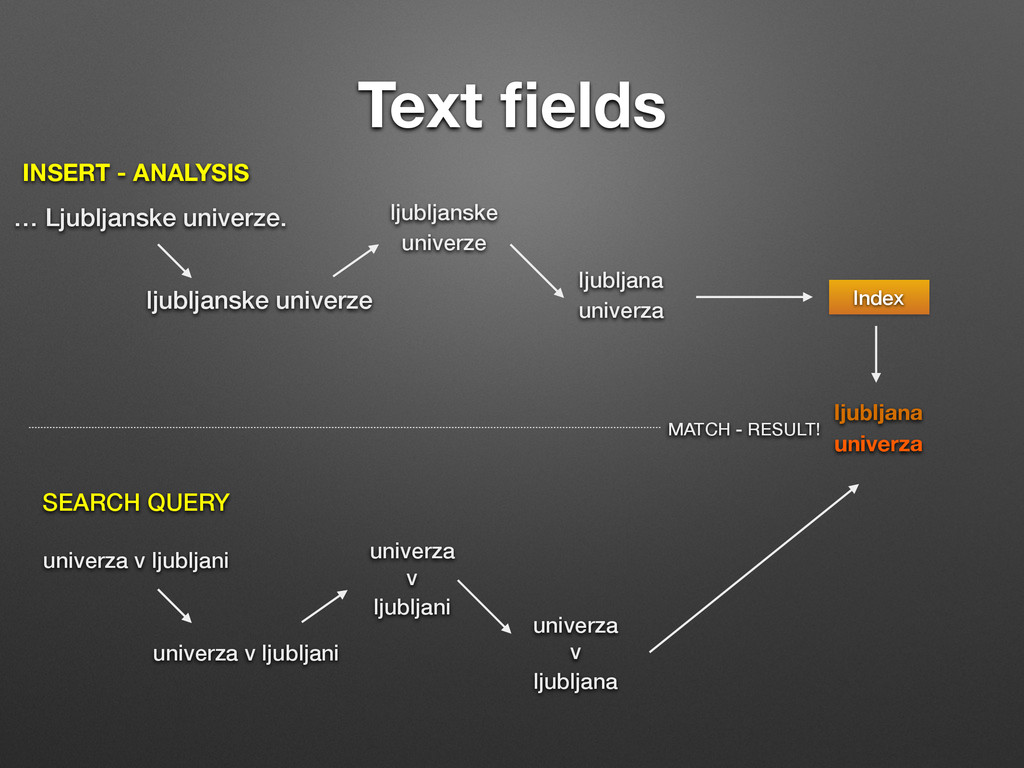
ljubljanske univerze ljubljana univerza Index univerza v ljubljani univerza v ljubljani univerza v ljubljana ljubljana univerza MATCH - RESULT! INSERT - ANALYSIS SEARCH QUERY
your language • Porter for English, Lemmagen for Slovene • More language tips at wiki: https://cwiki.apache.org/confluence/display/solr/Language+Analysis
want to make it case insensitive use LowerCaseFilterFactory • If you want to boost correct case, generate lower AND proper case tokens in analysis and at query time.
query time (e.g. DropBox -> Drop box so both “dropbox” and “drop box” match) • Clean HTML with HTMLStripCharFilterFactory • Collapse special characters to ASCII with ASCIIFoldingFilter (e.g. Sežana => Sezana so “Sezana” and “Sežana” will be hits) • More tools: https://cwiki.apache.org/confluence/display/solr/Filter+Descriptions https://cwiki.apache.org/confluence/display/solr/CharFilterFactories
your site • Pay special attention to queries with no results • Use SynonymFilterFactory to map common “wrong” words (e.g. “kitty” => “cat”, “aple” => “Apple”, …)
news search system https://bitbucket.org/mavrik/news-buddy • Solr lemmatizer for Slovenian, Serbian, Romanian, Bulgarian and some other languages https://bitbucket.org/mavrik/slovene_lemmatizer https://www.virag.si/2013/12/solr-slovenian- lemmatizer-updated/
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}