A remix of the RAPIDS 0.11 release deck targeted at the PyData Cardiff community.
All release decks
https://docs.rapids.ai/overview
Meetup
https://www.meetup.com/PyData-Cardiff-Meetup/events/268066478/
Abstract
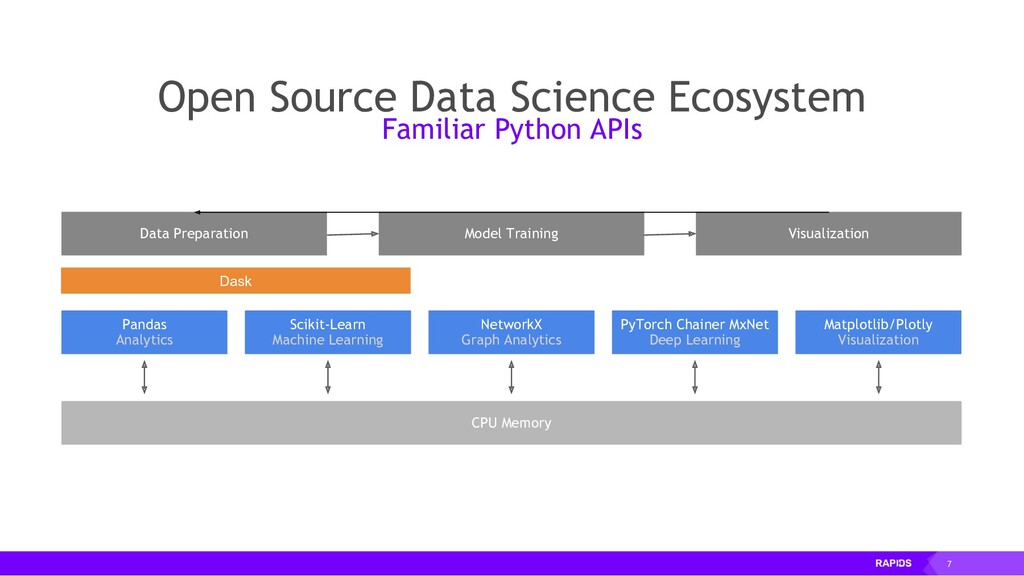
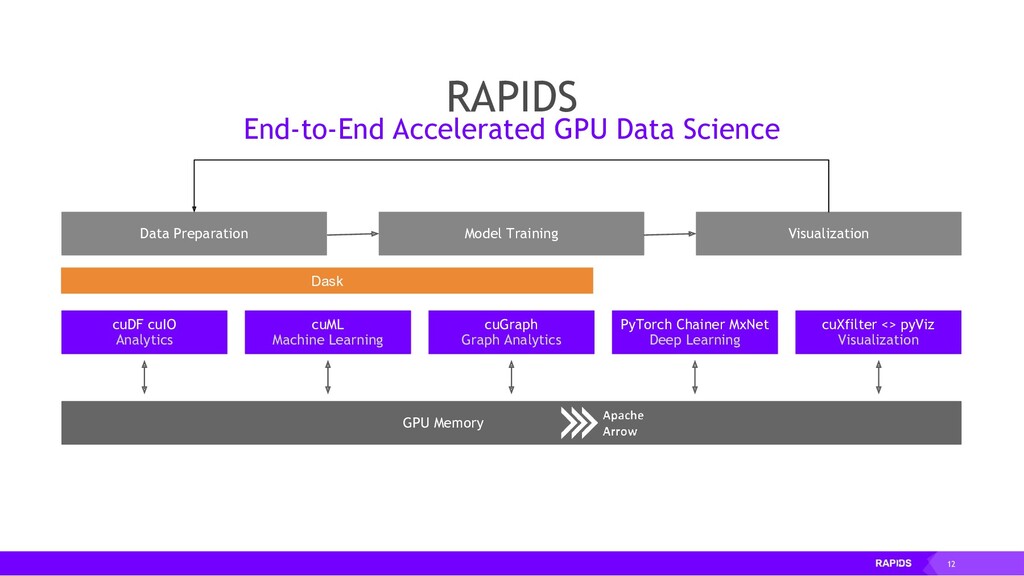
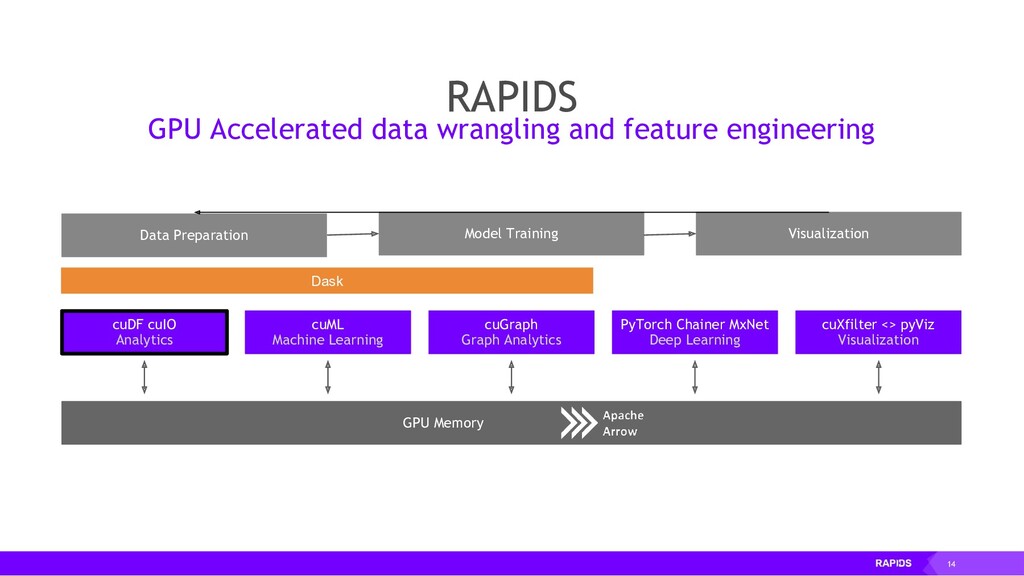
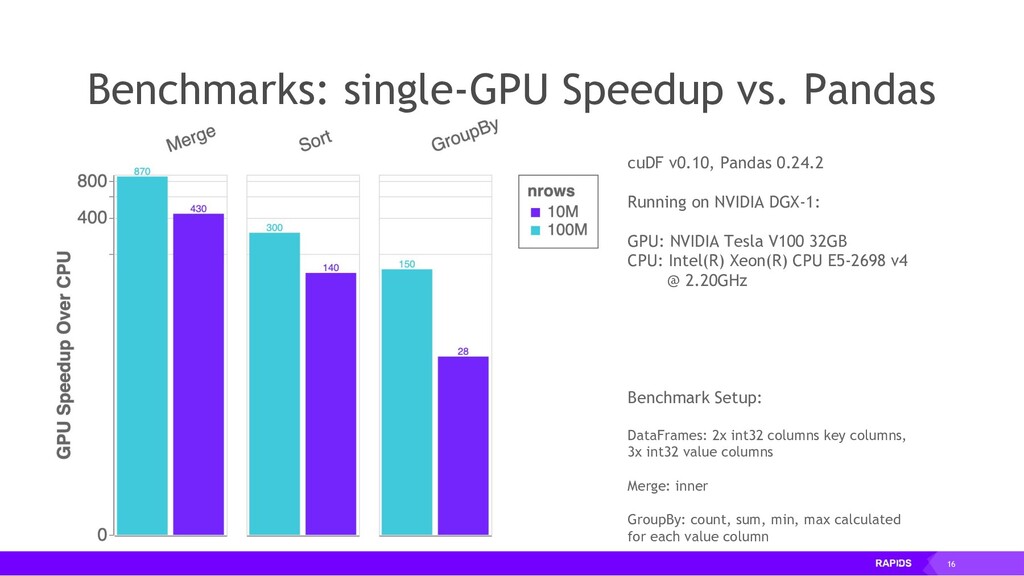
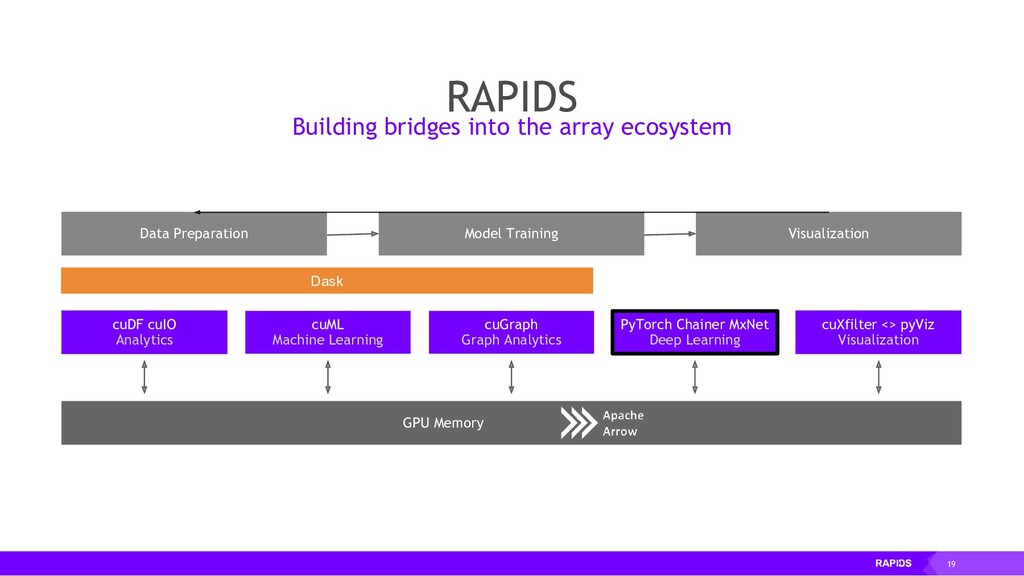
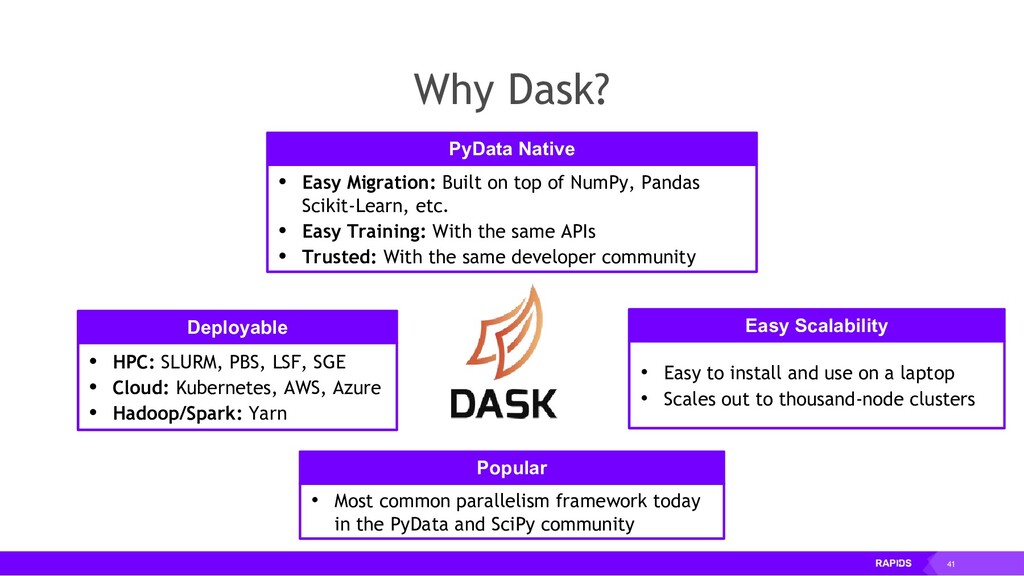
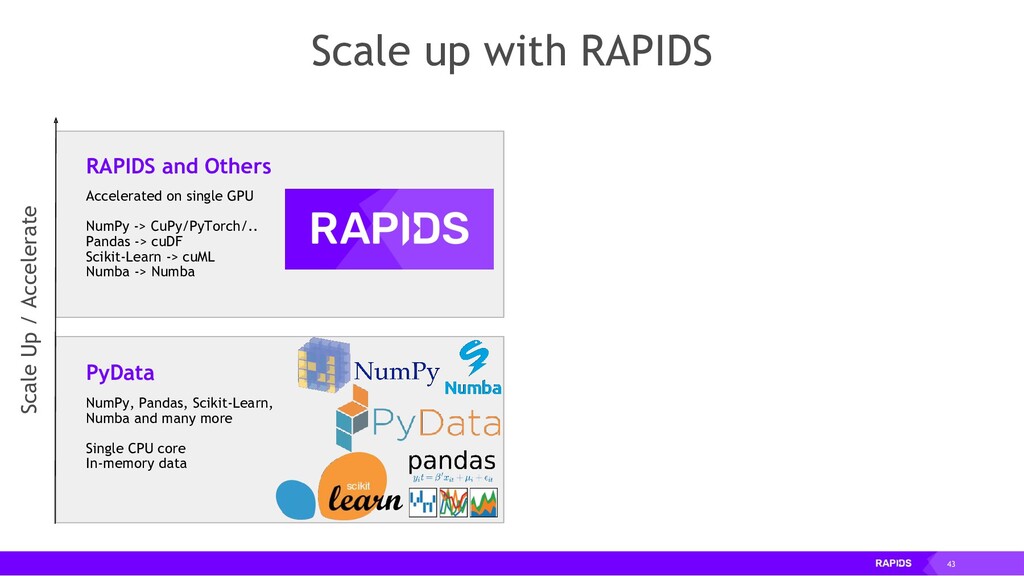
The RAPIDS suite of open source software libraries (https://rapids.ai/) allow you to run data science and analytics pipelines entirely on GPUs, but following familiar Python APIs including Numpy, Pandas and SciKit Learn.
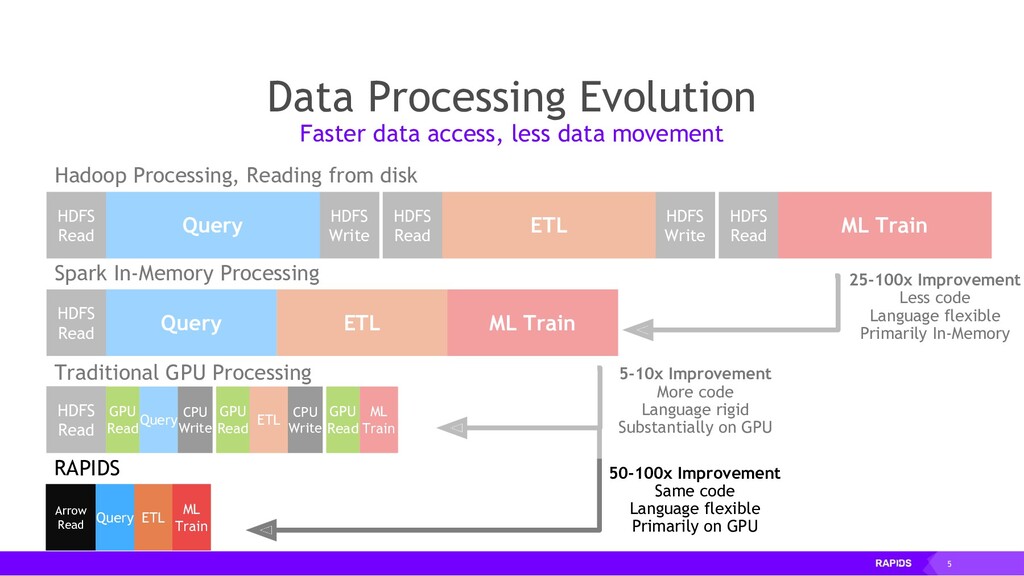
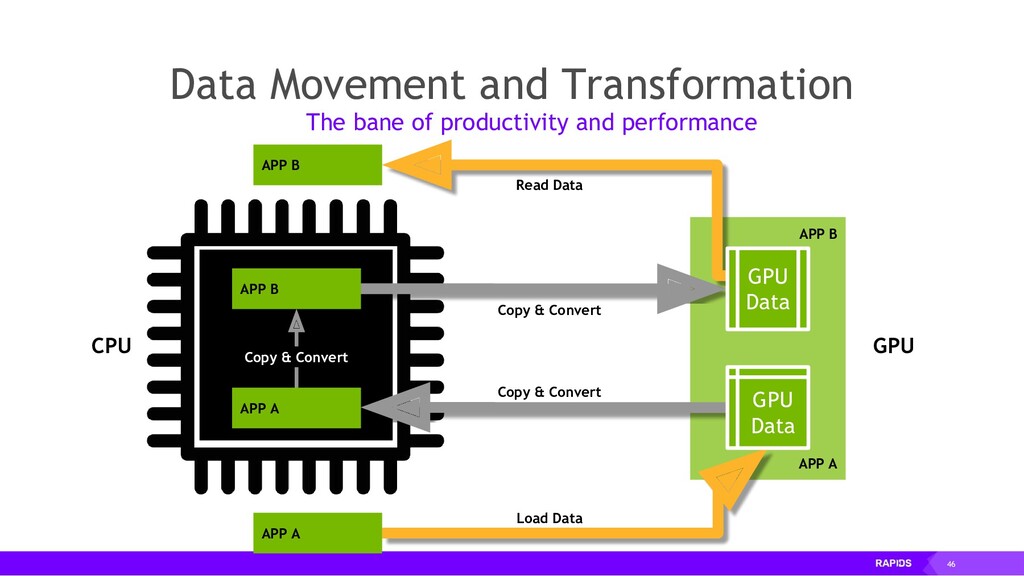
RAPIDS relies on NVIDIA® CUDA® primitives for low-level compute optimization, but exposes that GPU parallelism and high-bandwidth memory speed through user-friendly Python interfaces.
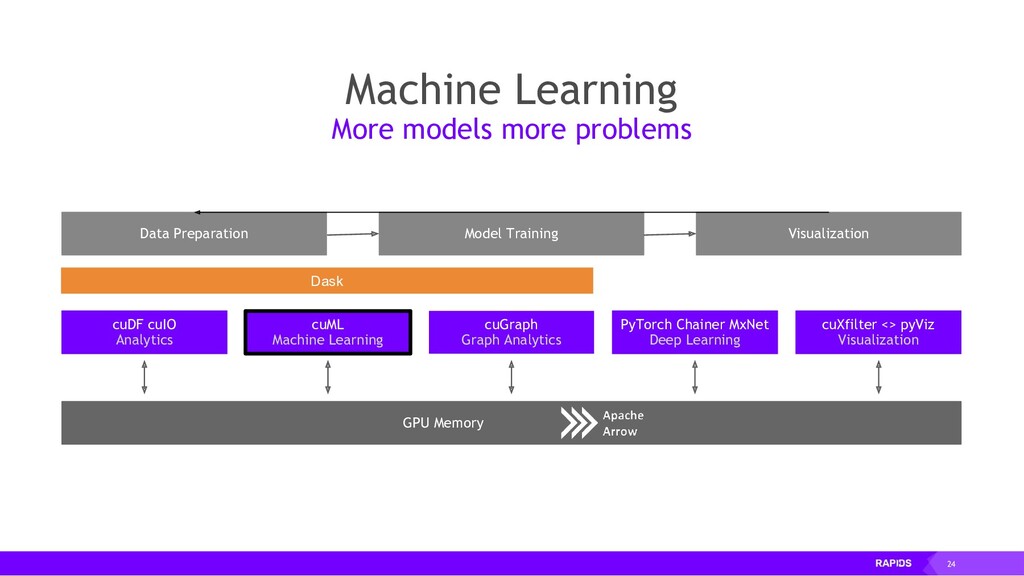
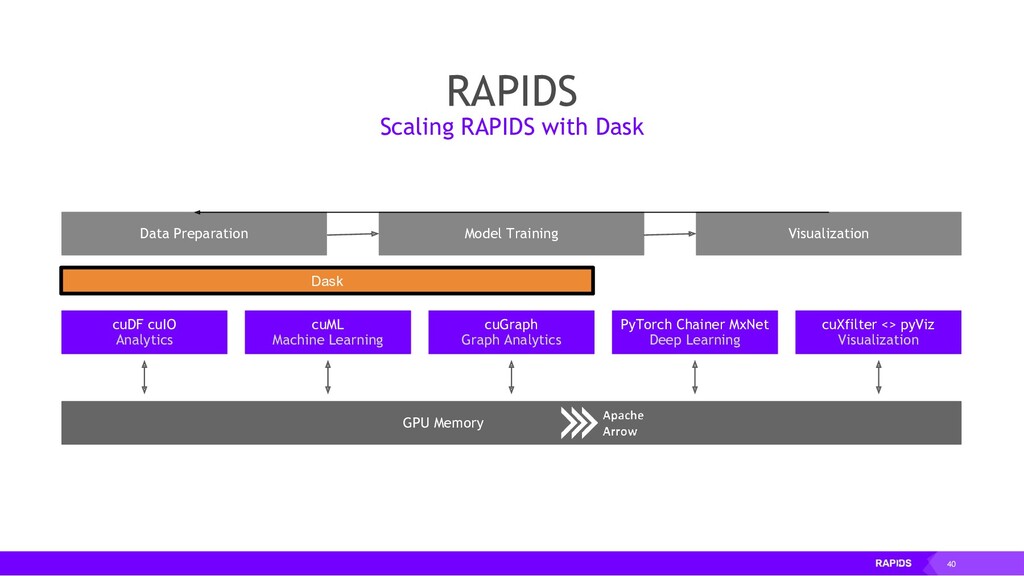
RAPIDS also focuses on common data preparation tasks for analytics and data science. This includes a familiar DataFrame API that integrates with a variety of machine learning algorithms for end-to-end pipeline accelerations without paying typical serialization costs. RAPIDS also includes support for multi-node, multi-GPU deployments, enabling vastly accelerated processing and training on much larger dataset sizes.
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![THANK YOU Jacob Tomlinson @_jacobtomlinson [email protected]](https://files.speakerdeck.com/presentations/59f0a5c182e04f7b876d61ed988672ec/slide_59.jpg){kind=link}