Abstract
--------
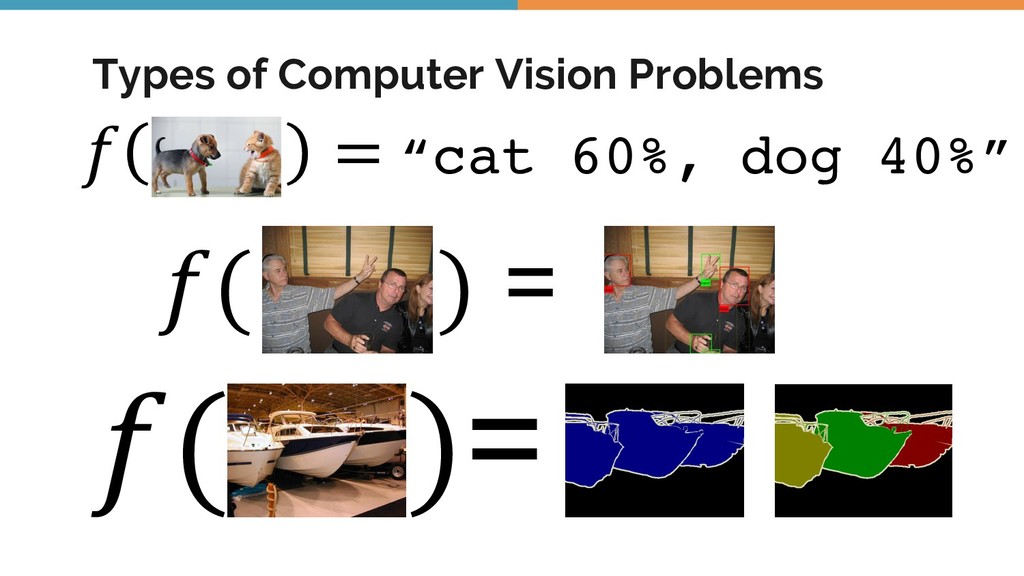
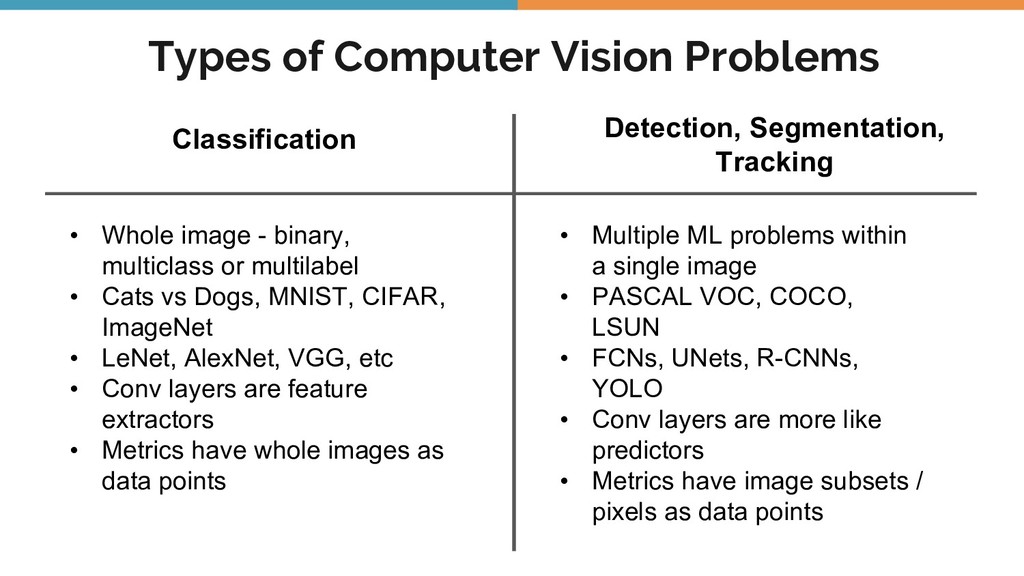
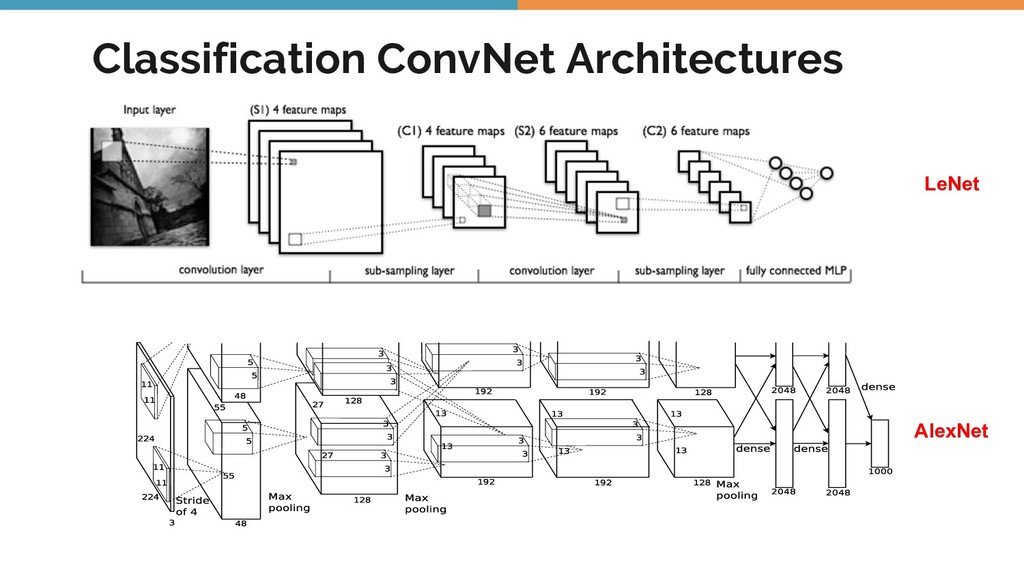
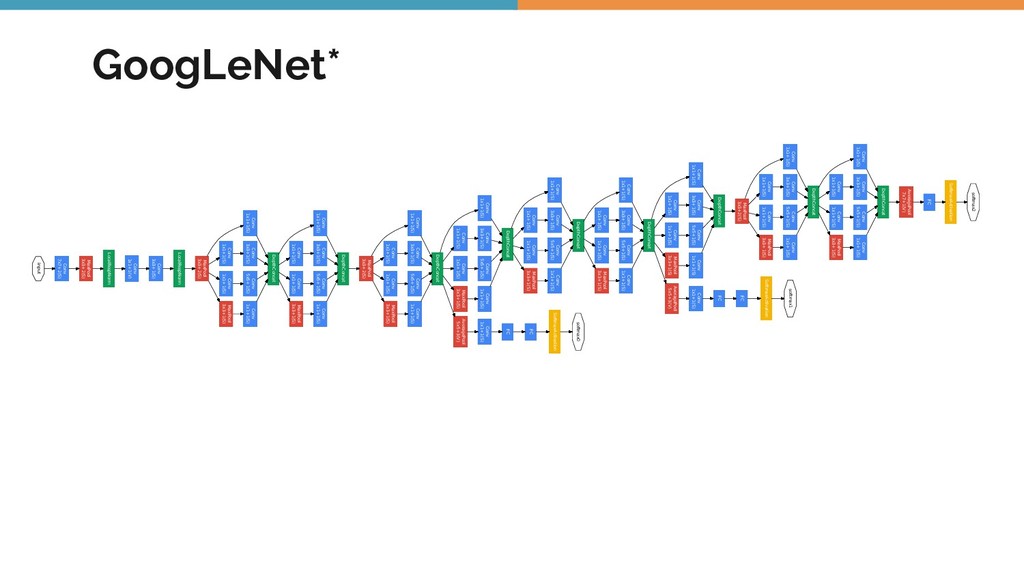
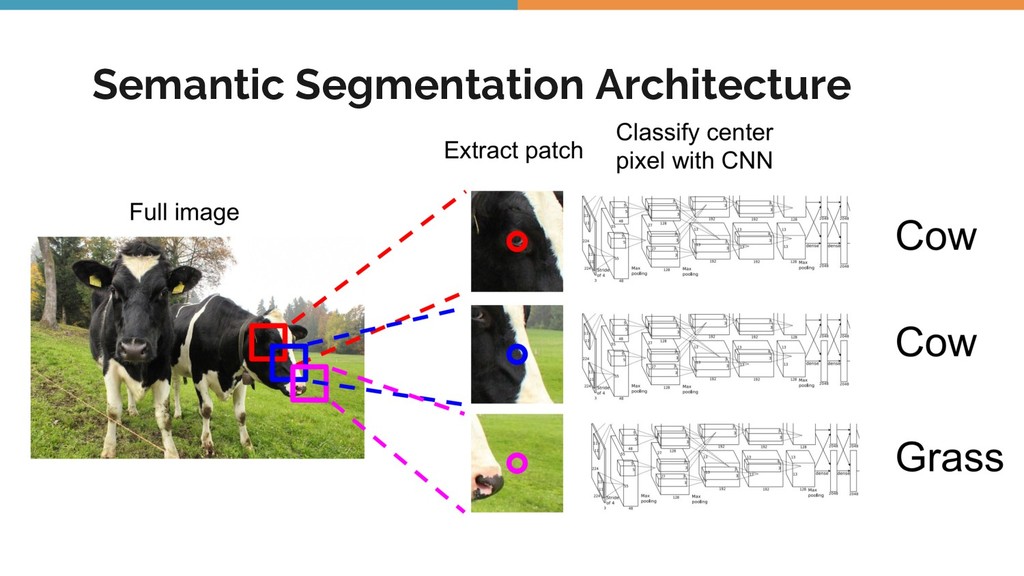
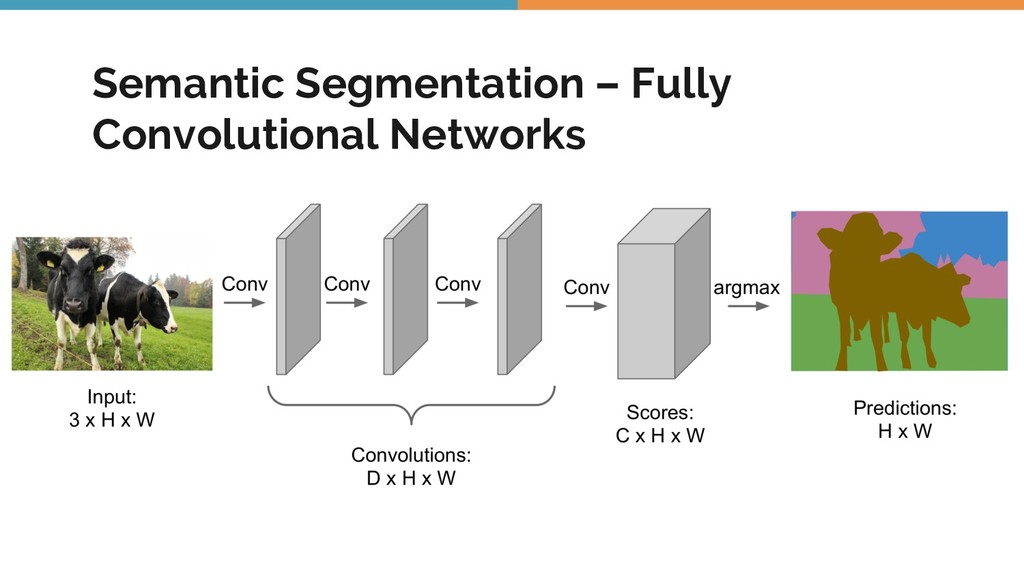
Object detection, tracking, semantic and instance segmentation are all staples of a computer vision system. This talk is an attempt to formalize the whole object detection problem from the ground up, with a focus on practical issues encountered when writing and deploying a deep learning model.
Proposal
--------
This talk is the result of my studies in the course of a couple of Kaggle competitions centered around segmentation. This was the first time I dealt with deep learning in a competitive setting. As I moved from sklearn to keras, the difference in how data is handled and models are trained was very noticeable. Beginning with the basics of object detection using simple image processing techniques, this talk will walk the audience through the practical intricacies of deep neural networks that perform object detection and classification. The talk focuses heavily on the data preprocessing, modeling and evaluation techniques rather than the theory, because of the latter there is no lack. As we see a spate of papers and preprints every day on deep learning and related techniques, being able to translate them into runnable Python code is becoming an increasingly useful skill.
This talk is _not_ about Kaggle itself. Success in such competitions depends on a lot more than simply the ability to write and train a good model - often, the difference between winning and losing is made by increasing the third or fourth decimal place. But, as Richard Hamming said in his lecture [**You and Your Research**](http://www.cs.virginia.edu/~robins/YouAndYourResearch.html),
> Great contributions are rarely done by adding another decimal place.
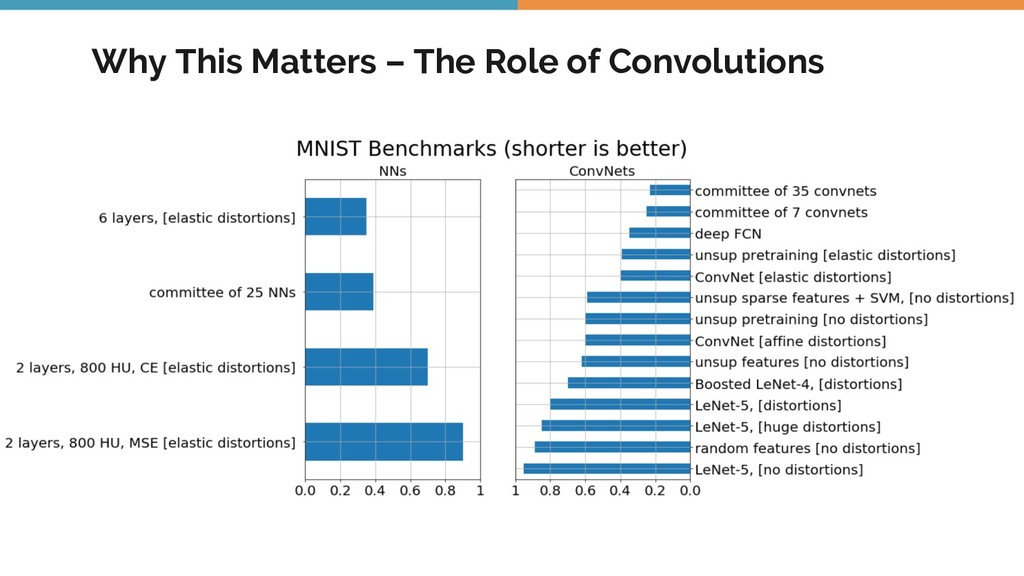
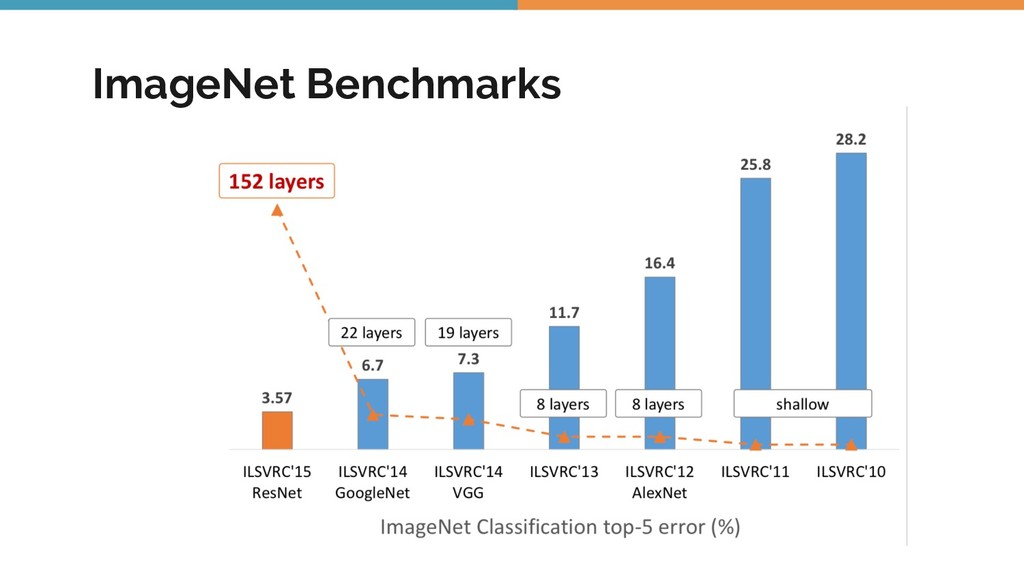
As I went from studying the classic textbooks in computer vision, before the days of deep learning, to the more contemporary and cutting edge work, I realized that I was producing ML models of a widely varying nature. Each of them had their pros and cons. Even though some of them performed relatively poorly on the evaluation data, they had other advantages like model simplicity, requiring less data and being faster to train.
This talk is all about navigating this entire landscape under different settings of data and computational resources.
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
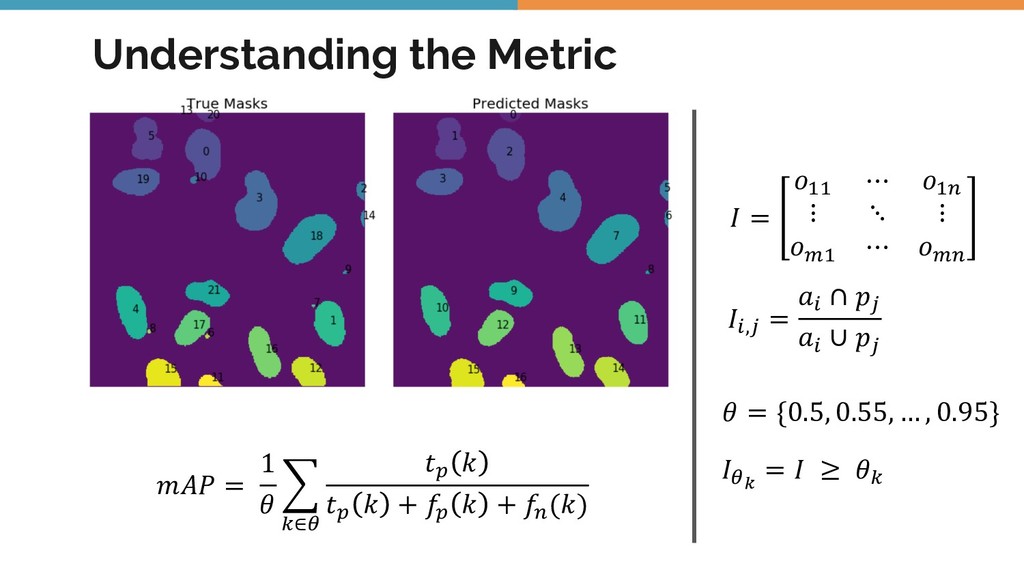{kind=link}
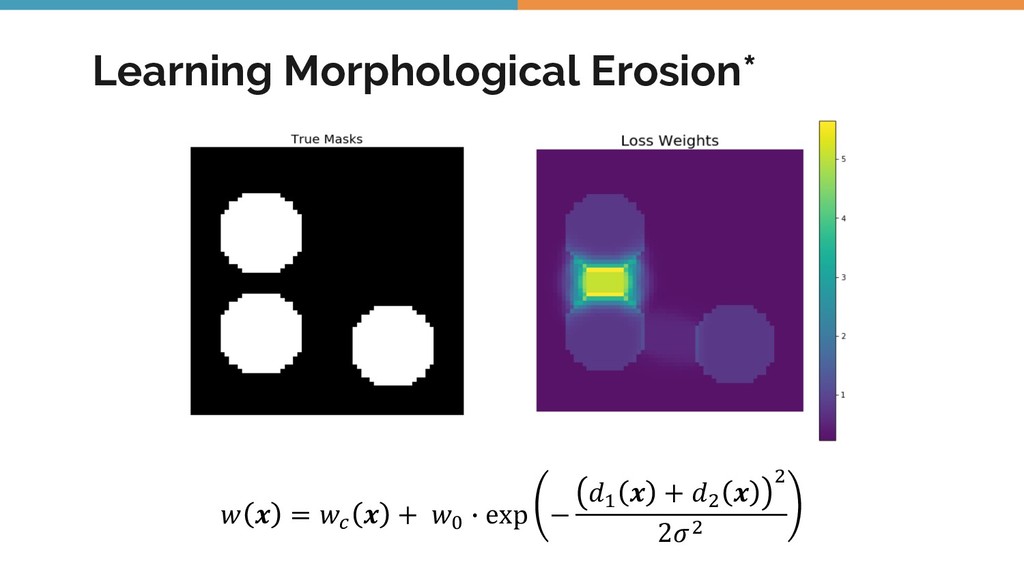{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}