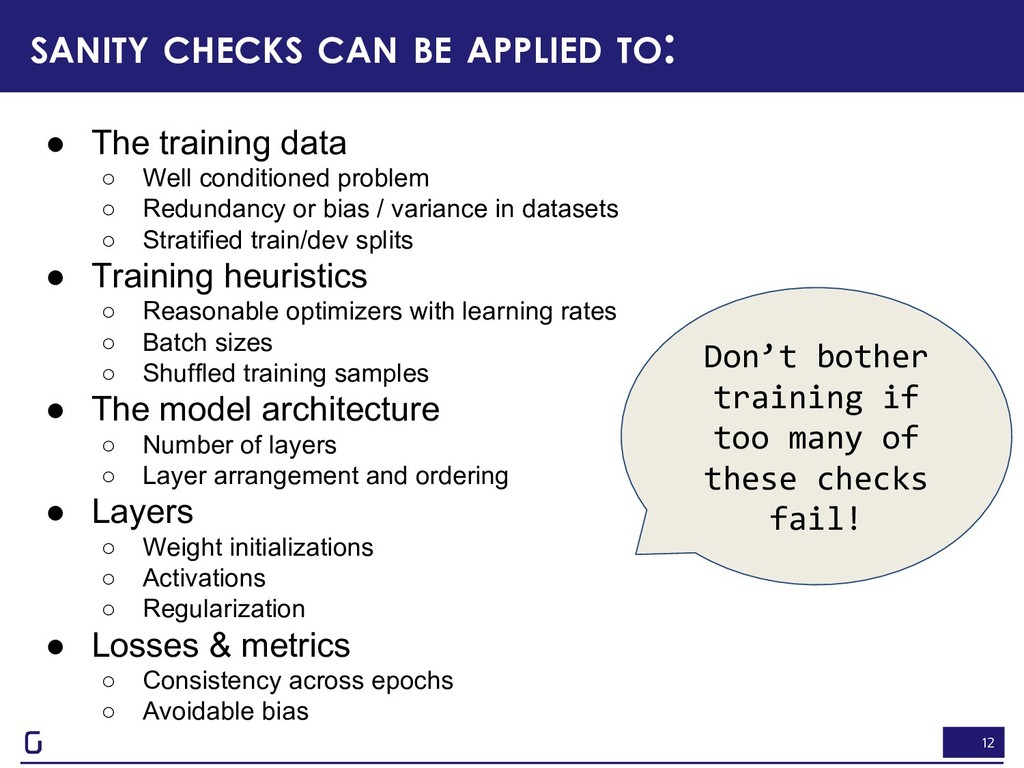
data ◦ Well conditioned problem ◦ Redundancy or bias / variance in datasets ◦ Stratified train/dev splits • Training heuristics ◦ Reasonable optimizers with learning rates ◦ Batch sizes ◦ Shuffled training samples • The model architecture ◦ Number of layers ◦ Layer arrangement and ordering • Layers ◦ Weight initializations ◦ Activations ◦ Regularization • Losses & metrics ◦ Consistency across epochs ◦ Avoidable bias Don’t bother training if too many of these checks fail!
• Keep track of metrics across experiments • Efficient hyperparameter grid search • Searching for models • Transfer Learning - you might already have a model for a given problem, only trained on a different dataset
• Like an IDE, organize models into projects • Each project has experiments • An experiment consists of a single training / validation session, contains ◦ Configuration of the model used ◦ Basic statistics on the training / validation data like number of features, samples, etc ◦ Error curves ◦ Metadata like datetime, path to the related files, etc • A “check” system (like PEP8) which warns the user at different stages of the project about various inconsistencies in the model • A simple search engine for models • A grid search manager - DRY when doing hyperparameter search • A verbose logger that logs all events in all projects
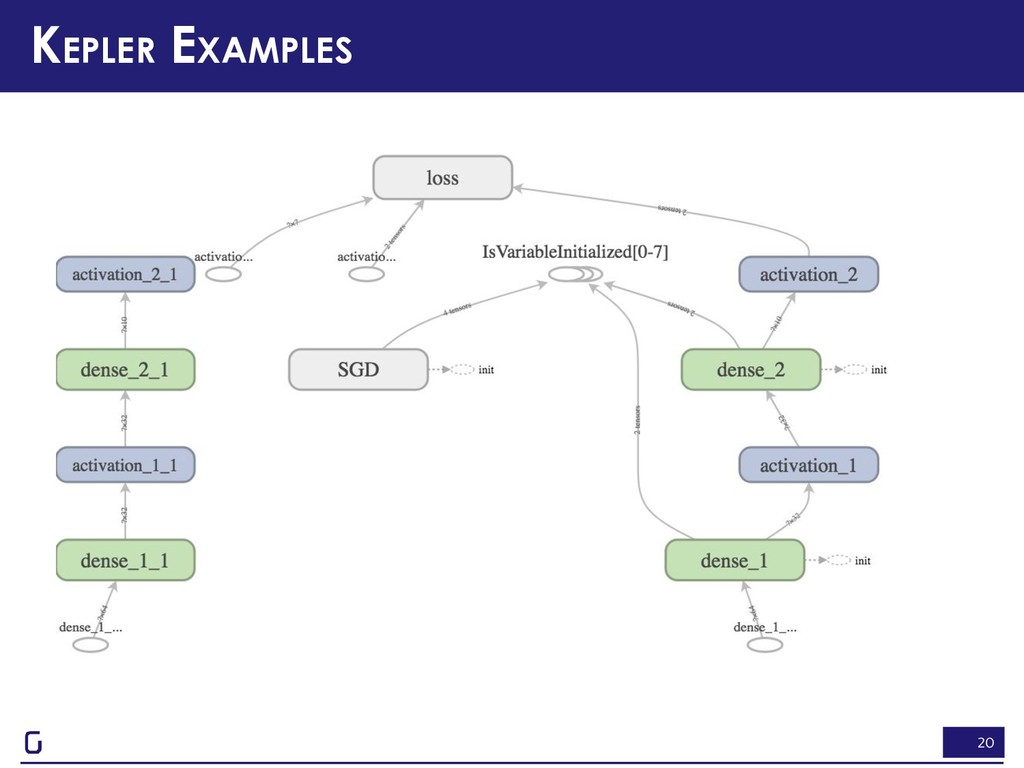
digits = load_digits() X = digits['data'] y = keras.utils.to_categorical(digits['target']) model = keras.models.Sequential([ keras.layers.Dense(32, input_shape=(64,)), keras.layers.Activation('sigmoid'), keras.layers.Dense(10), keras.layers.Activation('sigmoid') ]) model.compile(loss='categorical_crossentropy', optimizer=keras.optimizers.SGD()) $ kepler init Welcome to Kepler! $ ipython >>> from model import * >>> from kepler import ModelInspector >>> with ModelInspector(model=model) as mi: ... mi.fit(X, y, epochs=5) KEPLER EXAMPLES
>>> from kepler import ModelInspector >>> with ModelInspector(model=model) as mi: ... mi.fit(X, y, epochs=5) ... There are 1 models similar to this one. Would you like to see their graphs? [Y/n] : y Enter location for saving graphs [~/.kepler/models/tf_logs]: >>> Graphs written to /Users/jaidevd/.kepler/models/tf_logs Please point Tensorboard to /Users/jaidevd/.kepler/models/tf_logs Continue training? [Y/n] : n >>> exit() $ tensorboard --logdir ~/.kepler/models/tf_logs TensorBoard 1.12.0 at http://localhost:6006 (Press CTRL+C to quit)
far, supports only Keras with a Tensorflow backend • Models are guaranteed remain untouched • Well tested but not well documented :-( • Beta release scheduled for Q2 2019 • Bug reports & pull requests welcome!
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![23 THANK YOU! /@jaidevd /@jaidevd [email protected]](https://files.speakerdeck.com/presentations/705314939e6940768c3474926f4ce086/slide_22.jpg){kind=link}