engineers cope with complexity • Incidents are the entry point for learning, but not in the way(s) you might think. • What this means for you, and potential directions you might take
•Postmortems as re-calibration •Blameless v. sanctionless after-action actions •Controlling the costs of coordination •Visualizations during anomaly management •Strange Loops •Dark Debt
“monitoring” tools Adding stuff to the running system Getting stuff ready to be part of the running system architectural & structural framing keeping track of what “the system” is doing code repositories macro descriptions testing/validation suites code code stuff meta rules scripts, rules, etc. test cases code generating tools testing tools deploy tools organization/ encapsulation tools “monitoring” tools externally sourced code (e.g. DB) results the using world delivery technology stack internally sourced code results The Work Is Done Here Your Product Or Service The Stuff You Build and Maintain With
“monitoring” tools Adding stuff to the running system Getting stuff ready to be part of the running system architectural & structural framing keeping track of what “the system” is doing code repositories macro descriptions testing/validation suites code code stuff meta rules scripts, rules, etc. test cases code generating tools testing tools deploy tools organization/ encapsulation tools “monitoring” tools externally sourced code (e.g. DB) results the using world delivery technology stack internally sourced code results
“monitoring” Why is it doing that? hat needs to change? What does it mean? How should this work? What’s it doing? What does it mean? What is happening? What should be happening What does it mean? Adding stuff to the running system Getting stuff ready to be part of the running system architectural & structural framing keeping track of what “the system” is doing go purp ris cogn act intera spe ges cli sig represe What matters. Why what matters matters. code deploy organization/ encapsulation “monitoring” Why is it doing that? hat needs to change? What does it mean? How should this work? What’s it doing? What does it mean? What is happening? What should be happening What does it mean? Adding stuff to the running system Getting stuff ready to be part of the running system architectural & structural framing keeping track of what “the system” is doing go purp ris cogn act intera spe ges cli sig represe observing inferring anticipating planning troubleshooting diagnosing correcting modifying reacting
“monitoring” tools Adding stuff to the running system Getting stuff ready to be part of the running system architectural & structural framing keeping track of what “the system” is doing code repositories macro descriptions testing/validation suites code code stuff meta rules scripts, rules, etc. test cases code generating tools testing tools deploy tools organization/ encapsulation tools “monitoring” tools externally sourced code (e.g. DB) results the using world delivery technology stack internally sourced code results Time …and things are changing here things are changing here…
specific place and time • All incidents are surprises - they show us where our understanding isn’t accurate • Incidents can have many influences on an organization, most of them invisible without digging for them deliberately
abnormal watch this thing - examine other things - realize whatever is happening — it’s getting worse figure out what to do about it attempt to repair confirm it’s actually fixed
which it is come up with three plausible explanations for what’s happening (a, b, and c) oops, wait, no — it’s “b” (pretty sure) confident that it’s “c” - start working on fixing “c” working on “b” assess if the “c” fix caused any other issues confirm it’s actually stable
out who to call for help, contact them, bring them up to speed figure out what to do, settle on doing X do X realize that doing X made things worse, figure out the fix is Y clean up damage done by doing X do Y
watch this thing - examine other things - realize whatever is happening — it’s getting worse figure out what to do about it attempt to repair confirm it’s actually fixed notice something is going critical test hypotheses, work out which it is come up with three plausible explanations for what’s happening (a, b, and c) oops, wait, no — it’s “b” (pretty sure) confident that it’s “c” - start working on fixing “c” working on “b” assess if the “c” fix caused any other issues confirm it’s actually stable do Y OMG this is serious confirm it’s actually stable figure out who to call for help, contact them, bring them up to speed figure out what to do, settle on doing X do X realize that doing X made things worse, figure out the fix is Y clean up damage done by doing X
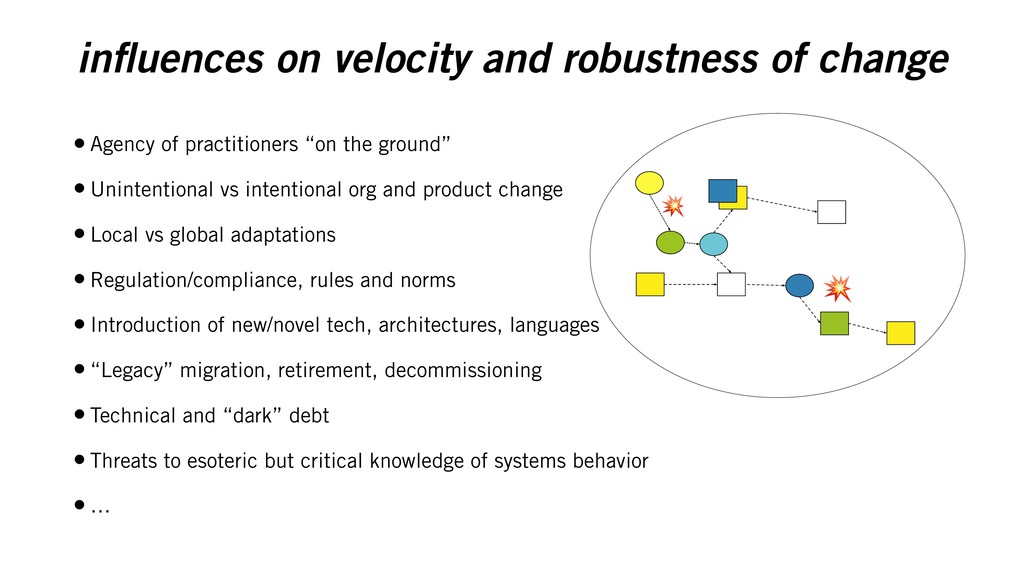
practitioners “on the ground” • Unintentional vs intentional org and product change • Local vs global adaptations • Regulation/compliance, rules and norms • Introduction of new/novel tech, architectures, languages • “Legacy” migration, retirement, decommissioning • Technical and “dark” debt • Threats to esoteric but critical knowledge of systems behavior • … ! !
shallow metrics (TTR, frequency, severity, etc.) as critically valuable data. People’s experiences represent the critical data. • Collect the questions being asked in your post-incident review meetings. Are some better than others? What makes a good question? A bad question? • Levels of “severity” != levels of terror/confusion/struggling for engineers. Find the shape of how these are different.
different domain expertise explain to each other what is familiar and important to watch for during an incident? • Are there any sources of data about the systems (logs, graphs, etc.) that people regularly dismiss or are suspicious of? • How do people improvise new tools to help them understand what is happening? • How do people assess when they need to call for help? • How does a new person in a team learn the nuances of systems behavior that isn’t documented? • What do the elder/veteran engineers know about their systems that others don’t? What esoteric knowledge do they have, and how did they get it? • What tricks do people or teams use to understand how otherwise opaque 3rd party services are behaving? • Are there specific types of problems (or particular systems) that trigger engineers to call for assistance from other teams, and others that don’t? consider topics such as these
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}