Upgrade to Pro
— share decks privately, control downloads, hide ads and more …
Speaker Deck
Features
Speaker Deck
PRO
Sign in
Sign up for free
Search
Search
CSC570 Lecture 05
Search
Javier Gonzalez-Sanchez
PRO
April 16, 2023
Research
390
0
Share
Embed
Copy iframe code
Copy JS code
Copy link
Start on current slide
CSC570 Lecture 05
Applied Affective Computing
BCI Hands-on Lab
(202304)
Javier Gonzalez-Sanchez
PRO
April 16, 2023
More Decks by Javier Gonzalez-Sanchez
See All by Javier Gonzalez-Sanchez
CSC307 Lecture 21
javiergs
PRO
0
60
CSC307 Lecture 17
javiergs
PRO
0
330
CSC305 Lecture 18
javiergs
PRO
0
370
final project
javiergs
PRO
0
120
CSC305 Lecture 18
javiergs
PRO
0
94
CSC307_L17_mqtt.pdf
javiergs
PRO
0
61
UP Lecture 28
javiergs
PRO
0
59
CSC307_L99_TDD.pdf
javiergs
PRO
0
67
CSC307_L99_TDD.pdf
javiergs
PRO
0
63
Other Decks in Research
See All in Research
RS-Agent: Automating Remote Sensing Tasks through Intelligent Agent
satai
3
370
LLM Compute Infrastructure Overview
karakurist
2
1.5k
Dual Quadric表現を用いた動的物体追跡とRGB-D・IMU制約の密結合によるオドメトリ推定
nanoshimarobot
0
430
【ローカルAIに向き合う展示会vol.2】液体時間定数型モジュールを用いた オリジナルの双方向エンコーダーモデルNexteraBERT 推論速度向上検討並びにダウンストリーム評価
rikkabotan7
0
120
老舗ものづくり企業でリサーチが変革を起こすまで - 三菱重工DXの実践
skydats
0
220
【Zozo Research 技術共有会】三次元領域の現在と展望
mickey_0226
3
470
(SIGQS17) Frasco-VS:フラグメントに基づく薬剤候補化合物選抜の量子アニーリングによる実現
keisukeyanagisawa
PRO
0
160
シングルチャネルマルチトーカー音声認識の進展
ryomasumura
0
180
「行ける・行けない表」による地域公共交通の性能評価
bansousha
0
170
2026年版中小企業白書・小規模企業白書の概要
ozekinote
0
110
2026 東京科学大 情報通信系 研究室紹介 (すずかけ台)
icttitech
0
4.1k
Cross-Media Information Spaces and Architectures
signer
PRO
0
310
Featured
See All Featured
How To Stay Up To Date on Web Technology
chriscoyier
790
250k
Building Better People: How to give real-time feedback that sticks.
wjessup
370
20k
Easily Structure & Communicate Ideas using Wireframe
afnizarnur
194
17k
Automating Front-end Workflow
addyosmani
1370
210k
HTML-Aware ERB: The Path to Reactive Rendering @ RubyCon 2026, Rimini, Italy
marcoroth
2
320
[RailsConf 2023] Rails as a piece of cake
palkan
59
6.7k
Jess Joyce - The Pitfalls of Following Frameworks
techseoconnect
PRO
1
190
What does AI have to do with Human Rights?
axbom
PRO
1
2.2k
Abbi's Birthday
coloredviolet
3
8.6k
Making the Leap to Tech Lead
cromwellryan
135
10k
The Straight Up "How To Draw Better" Workshop
denniskardys
239
140k
GraphQLとの向き合い方2022年版
quramy
50
15k
Transcript
Dr. Javier Gonzalez-Sanchez
[email protected]
www.javiergs.info o ffi ce: 14 -227
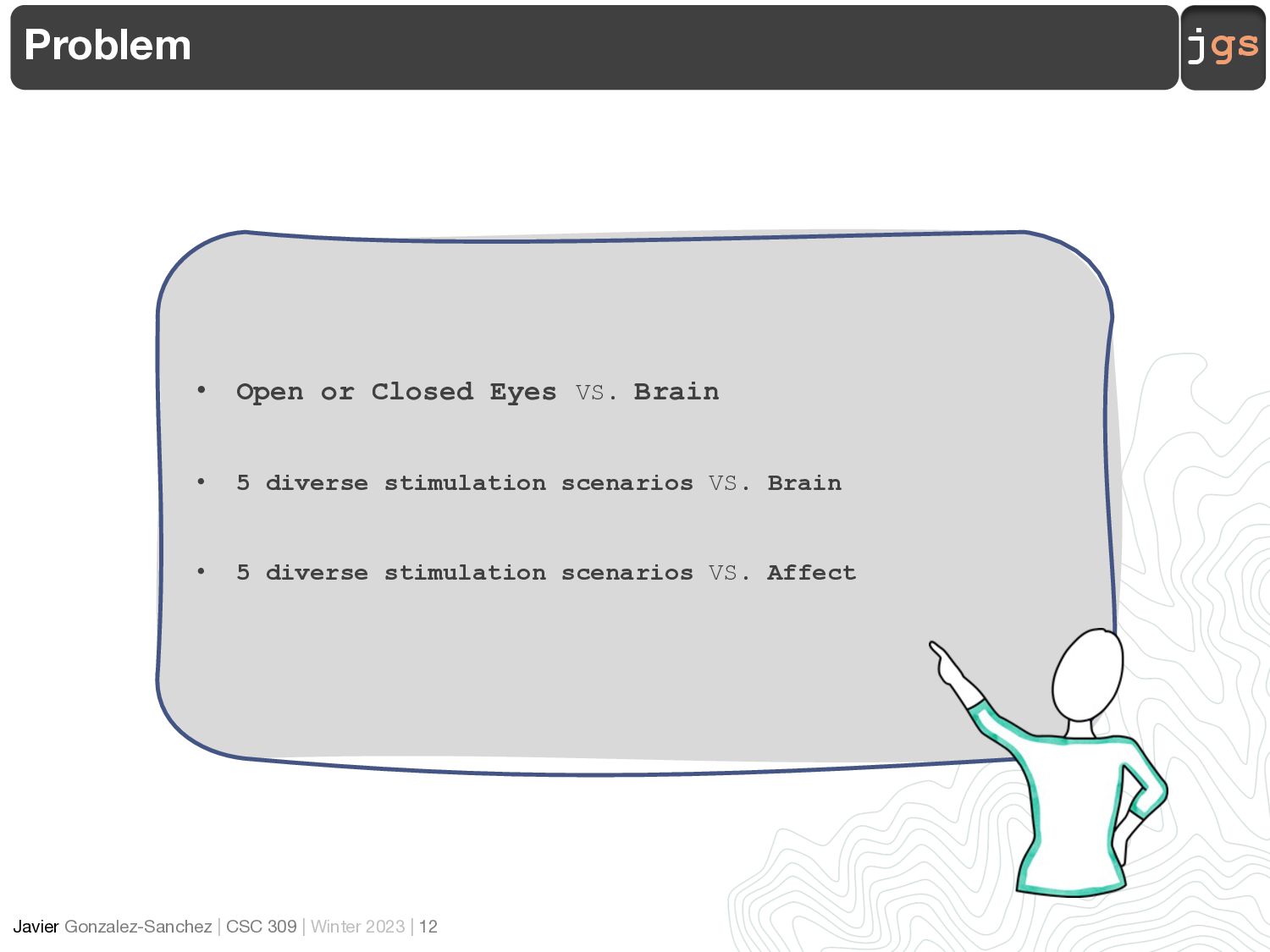
CSC 570 Current Topics in Computer Science Applied Affective Computing Lecture 05. BCI Hands-on Lab
Previously …
Let Us Get Some Data 3
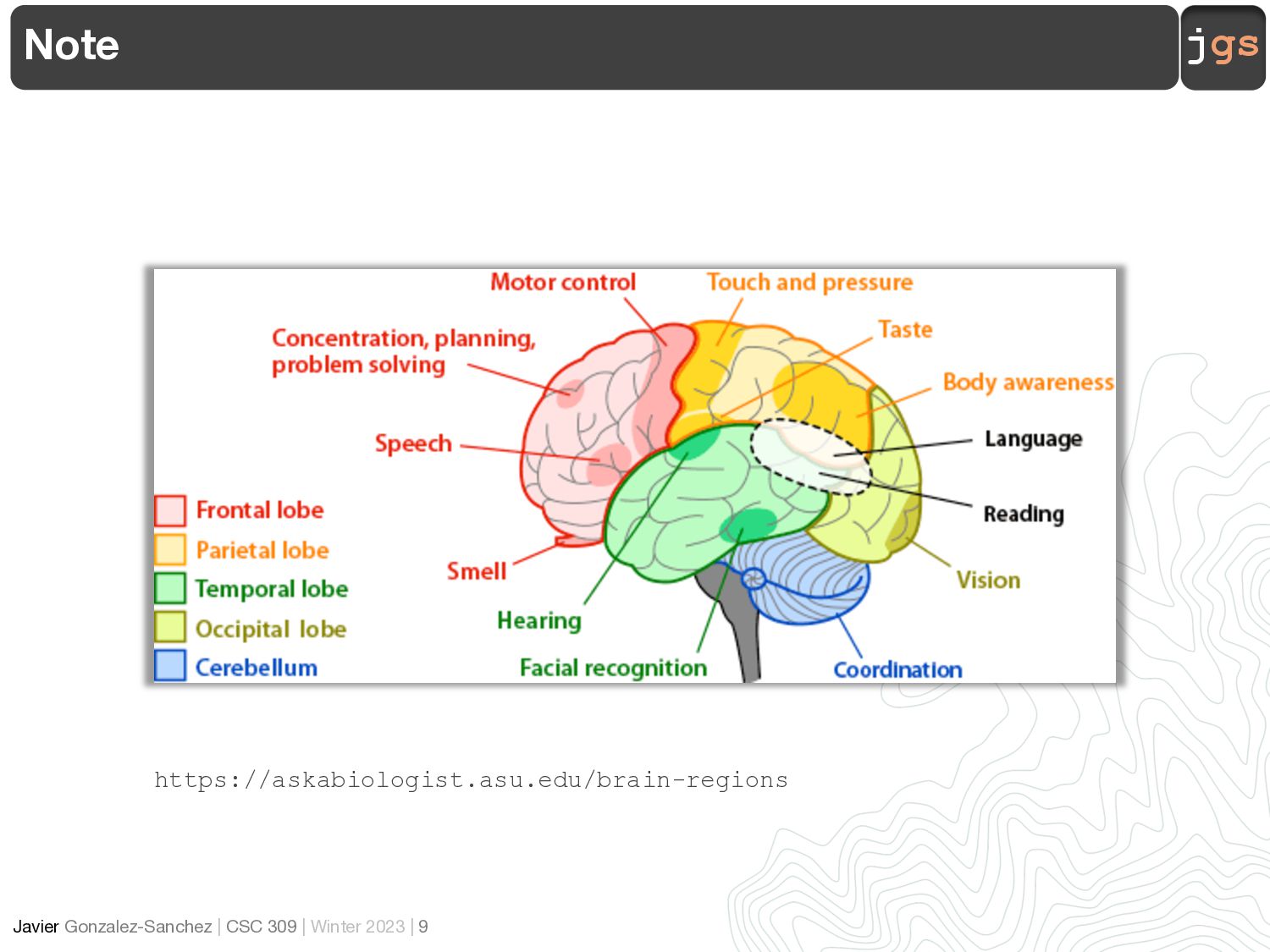
Brain 4 https://askabiologist.asu.edu/brain-regions
None
Emotiv Insight 6
Set Up
Emotiv 8
Emotiv 9
Emotiv 10
None
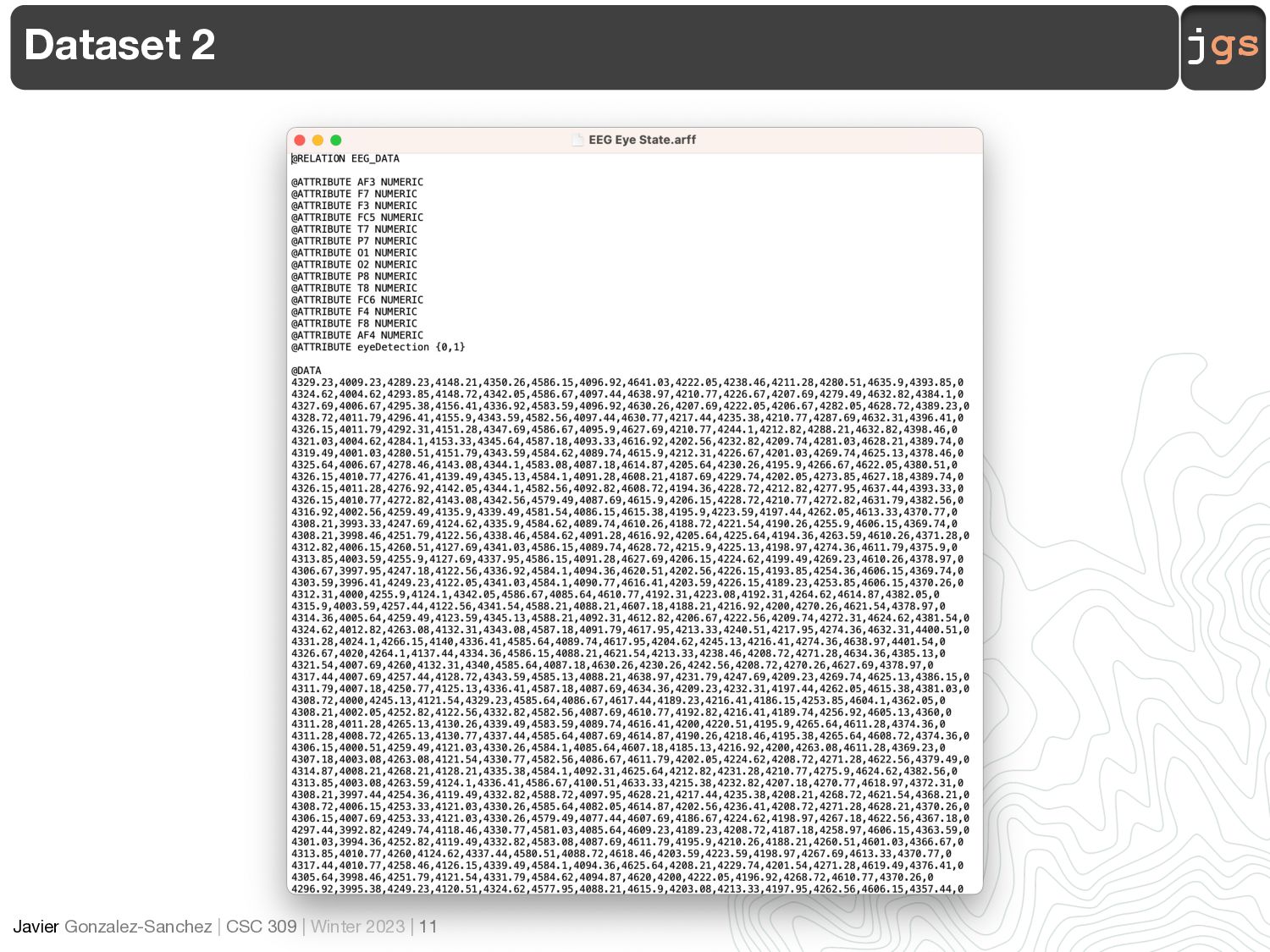
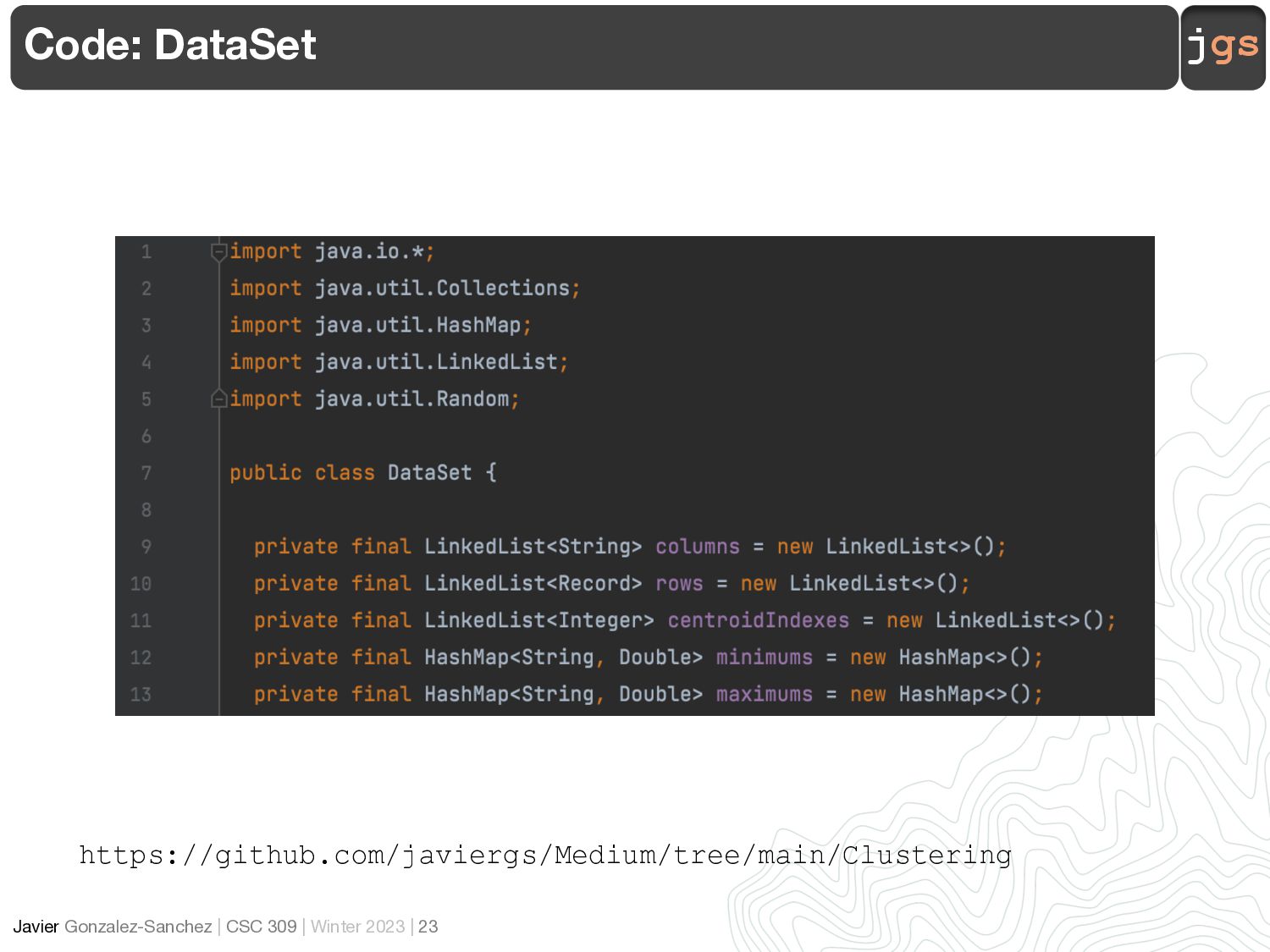
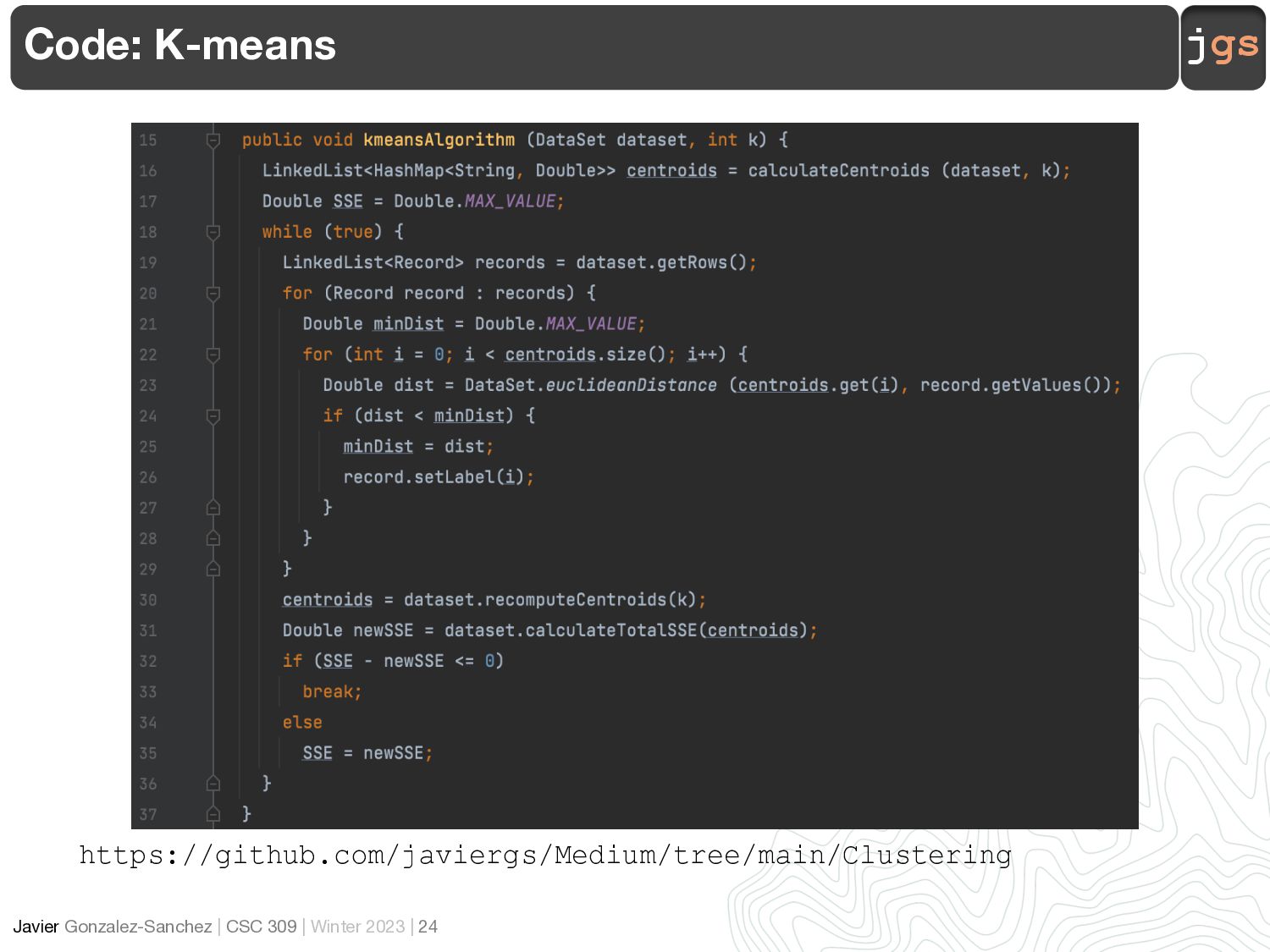
Dataset
Files 13 <date> _AFFECT.txt <date> _DEVICE.txt <date> _EEG.txt <date> _FACE.txt
<date> _PAD.txt
None
DEVICE | Battery 15 * The headset uses Bluetooth or
BLE, which periodically spikes power usage:
None
AFFECT | we need to remove outliers (noise) 17
None
None
(+++) Engagement 🙂🫀🕹 (+--) Starting Agreement Docility 🙂 👾 (++-)
Excitement Interest 🙂🫀👾
👀 👨🏫
FACE | Action Eyes 22
FACE | Upper Face 23 😖 😟
FACE | Lower Face 24
None
None
Questions 27
CSC 570 Applied Affective Computing Javier Gonzalez-Sanchez, Ph.D.
[email protected]
Spring
2025 Copyright. These slides can only be used as study material for the class CSC 570 at Cal Poly. They cannot be distributed or used for another purpose.
![Dr. Javier Gonzalez-Sanchez [email protected] www.javiergs.info o ffi ce: 14 -227](https://files.speakerdeck.com/presentations/90aa5a5a72b74299a469ffc55240167a/slide_0.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![CSC 570 Applied Affective Computing Javier Gonzalez-Sanchez, Ph.D. [email protected] Spring](https://files.speakerdeck.com/presentations/90aa5a5a72b74299a469ffc55240167a/slide_27.jpg){kind=link}