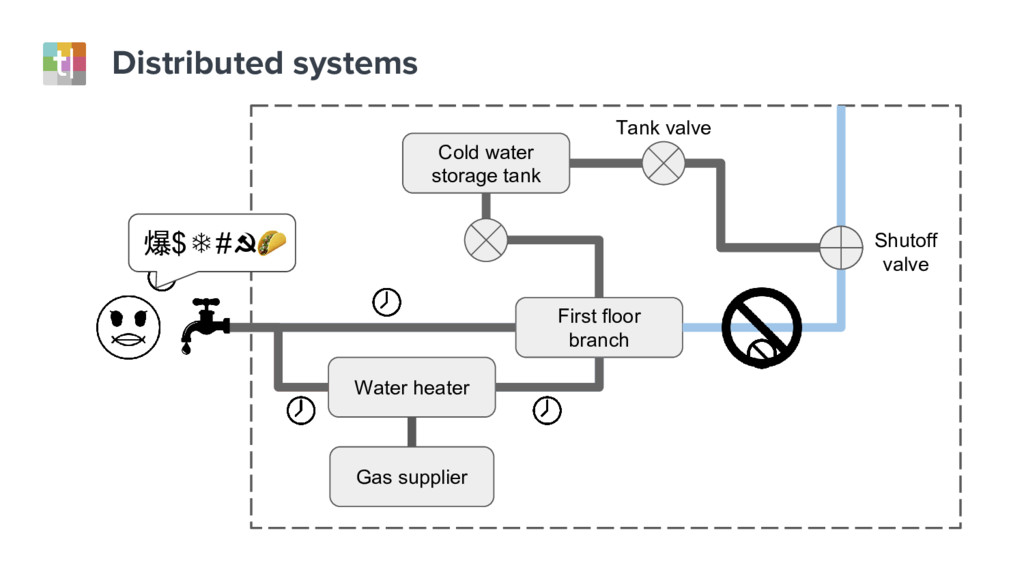
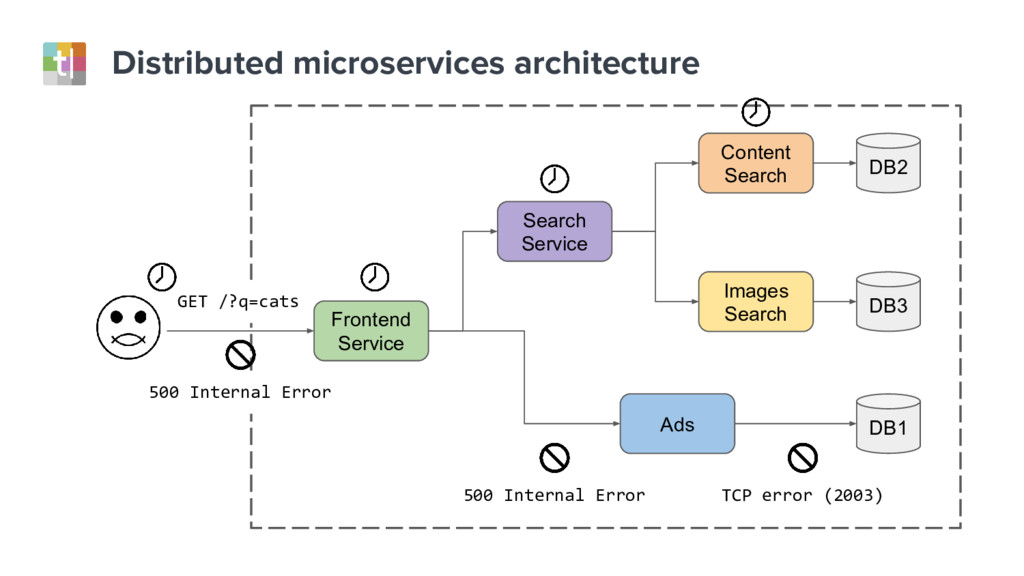
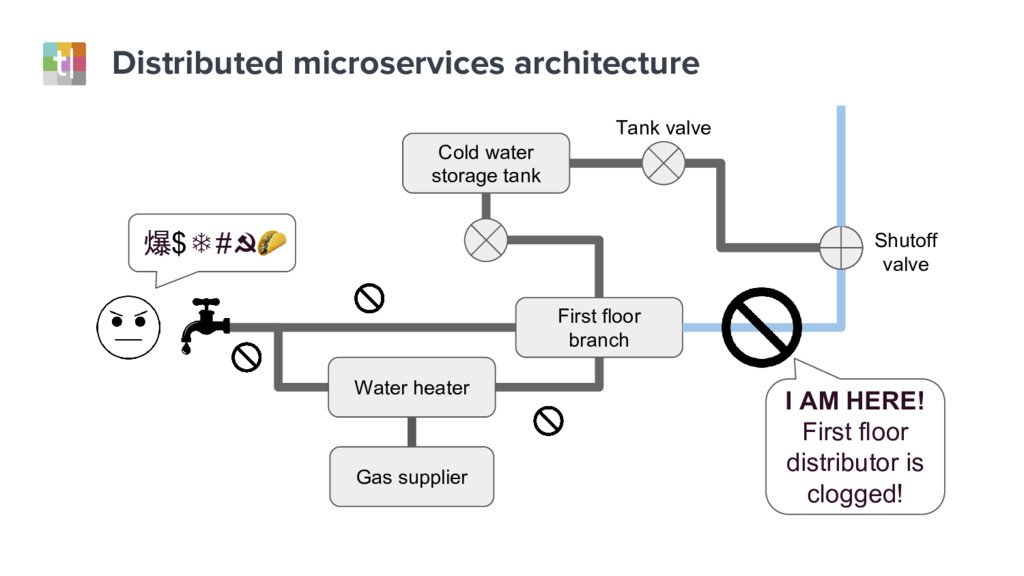
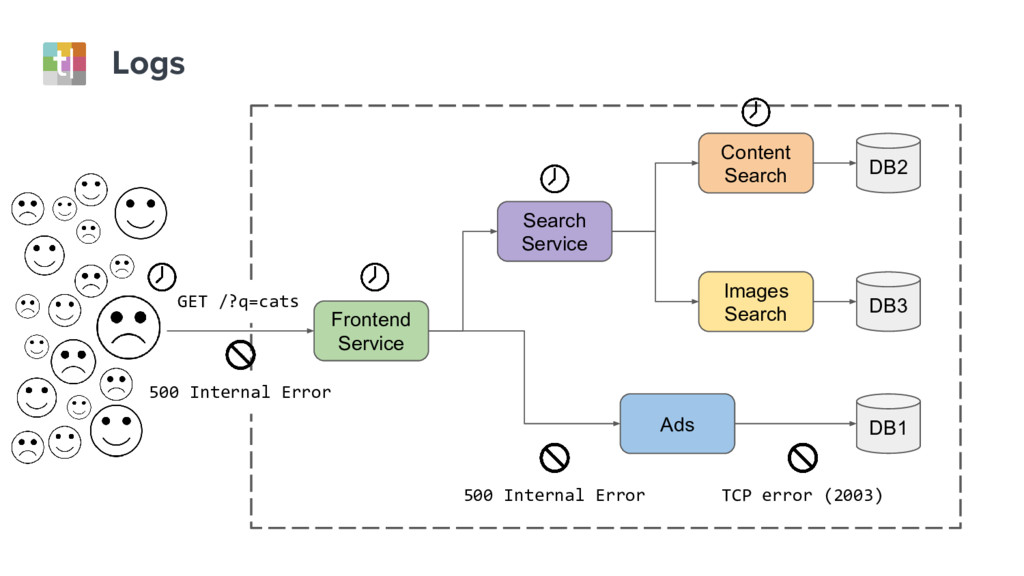
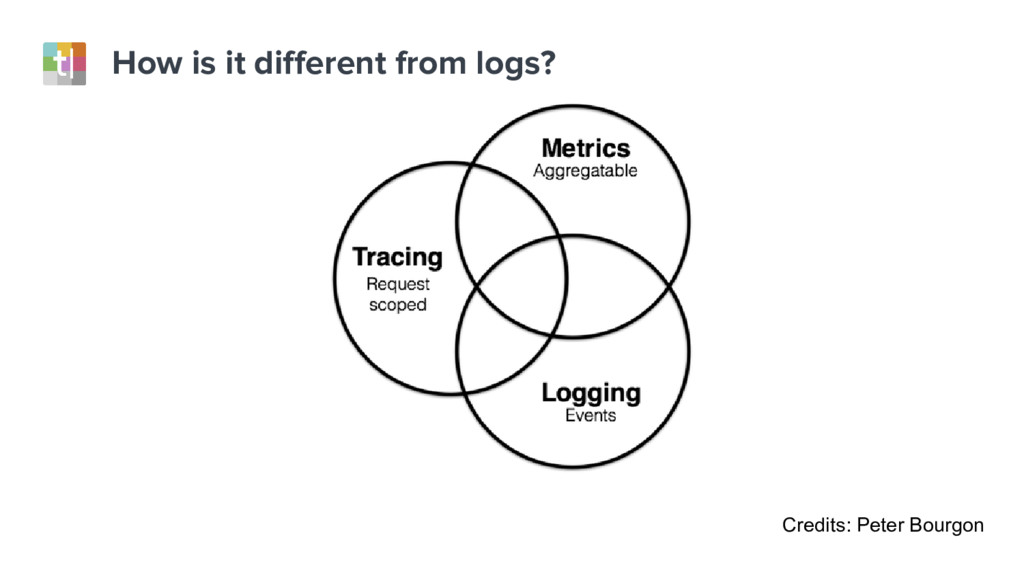
Understanding system failures traditionally starts with looking at a single component in isolation. However, this approach does not provide sufficient information with distributed services architectures. In these systems, end-user requests traverse dozens of components, and therefore a new approach is needed.
In this talk we’ll look at distributed tracing, which summarizes and contextualizes all sides of the story into a well-scoped and shared timeline. We’ll also look at distributed tracing tools, like Zipkin, which highlight the relationship between components, from the very top of the stack to the deepest aspects of the system.
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![[24/Oct/2017 13:50:07 +0000] “GET / HTTP/1.1” 200 … **0/13548” [24/Oct/2017](https://files.speakerdeck.com/presentations/52891036ae0a4f2eb673b0b6f0f6fcc1/slide_9.jpg){kind=link}
{kind=link}
{kind=link}
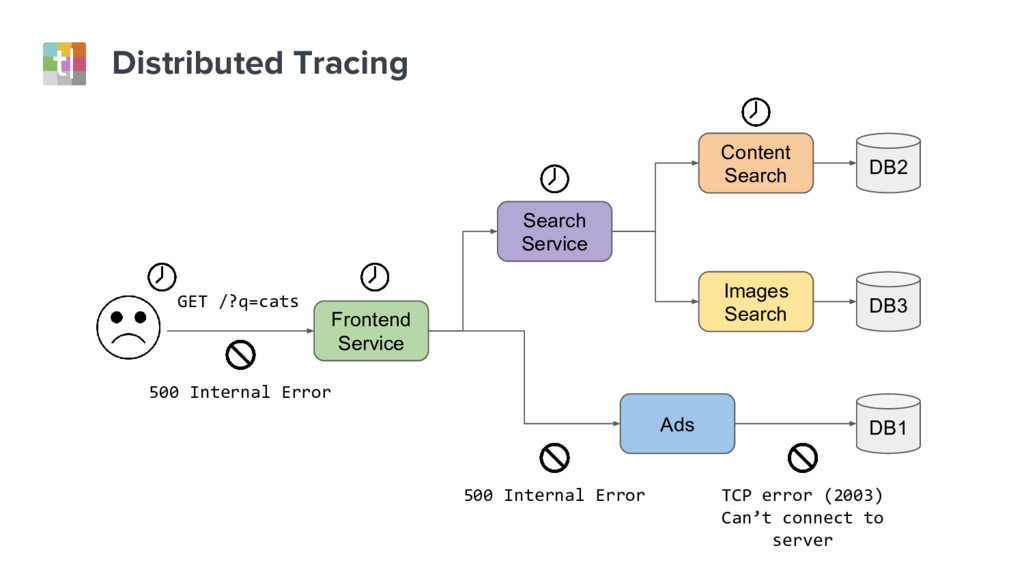{kind=link}
![[24/Oct/2017 13:50:07 +0000] “GET / HTTP/1.1” 200 … **0/13548” [24/Oct/2017](https://files.speakerdeck.com/presentations/52891036ae0a4f2eb673b0b6f0f6fcc1/slide_13.jpg){kind=link}
![Distributed Tracing FRONTEND SEARCH ADS CONTENT IMAGES Time [1508410470] error](https://files.speakerdeck.com/presentations/52891036ae0a4f2eb673b0b6f0f6fcc1/slide_14.jpg){kind=link}
{kind=link}
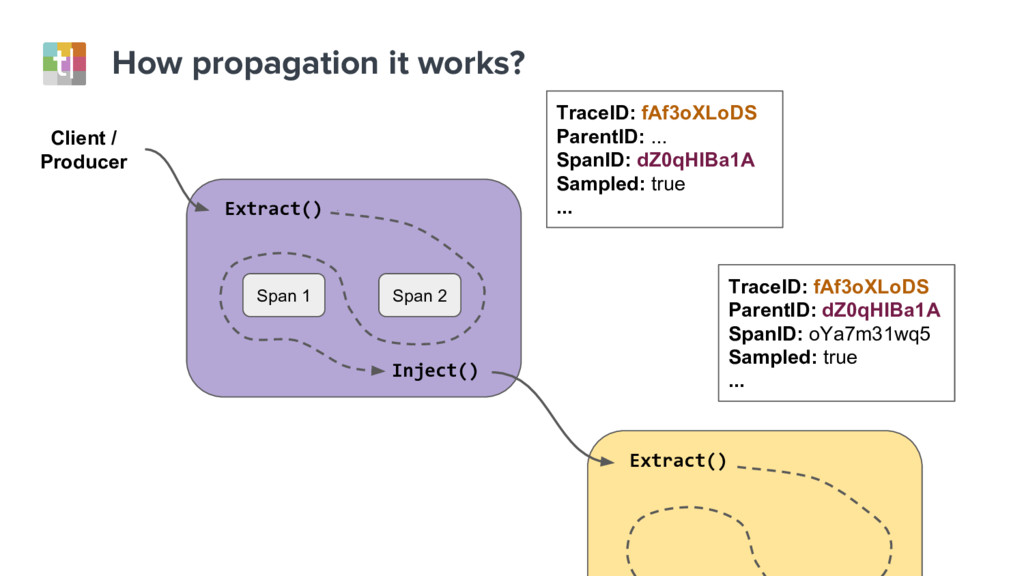{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
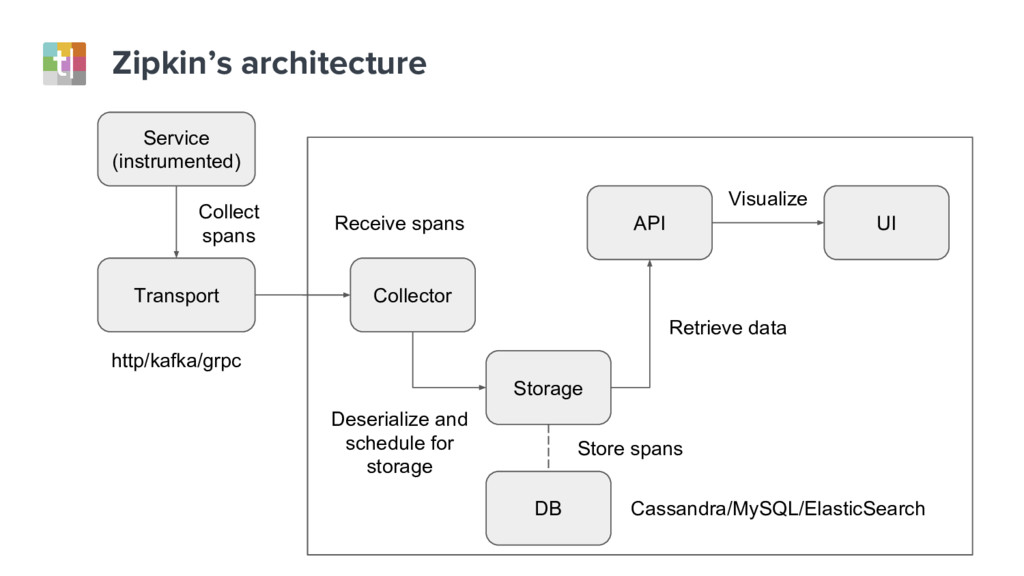{kind=link}
{kind=link}
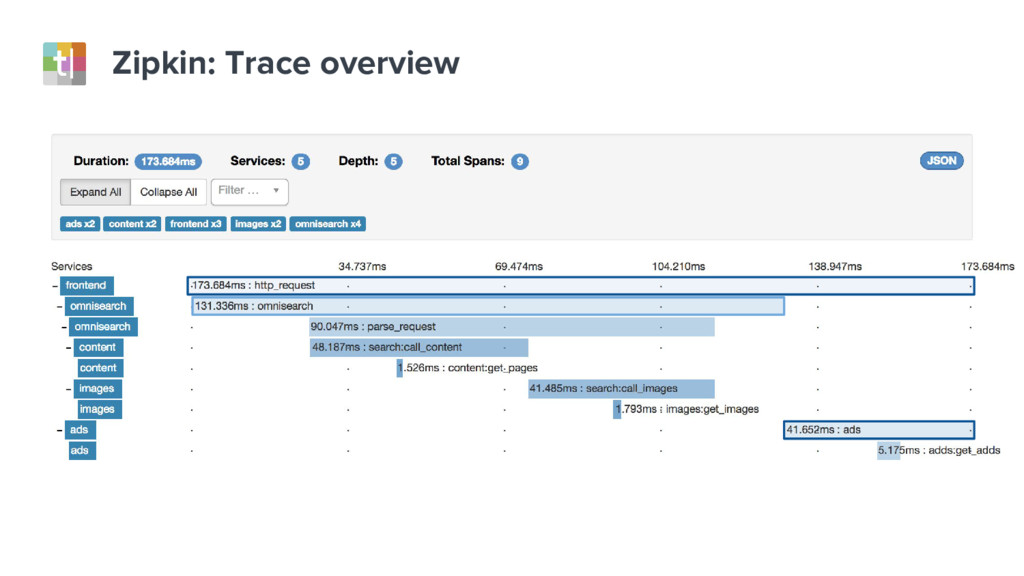{kind=link}
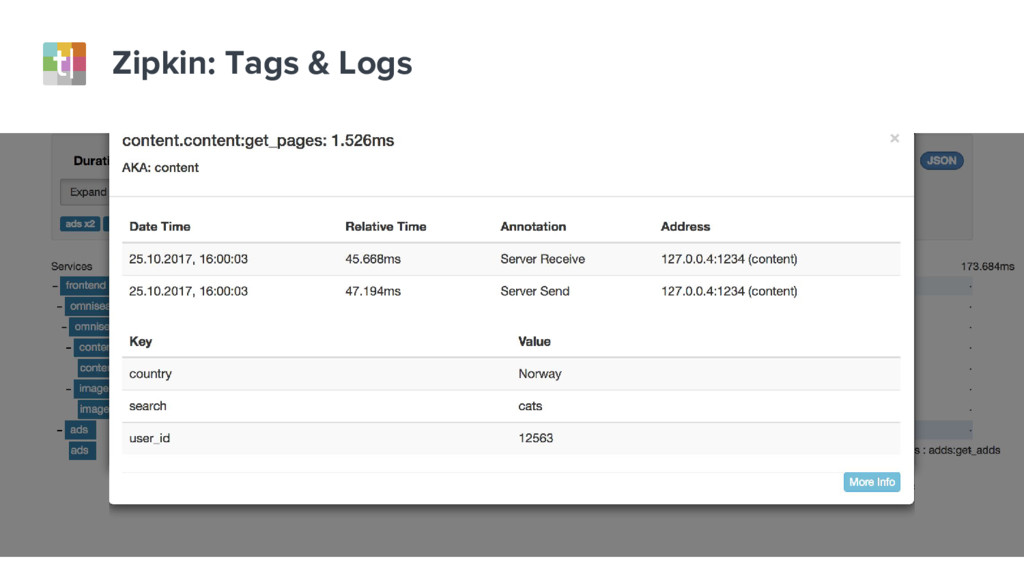{kind=link}
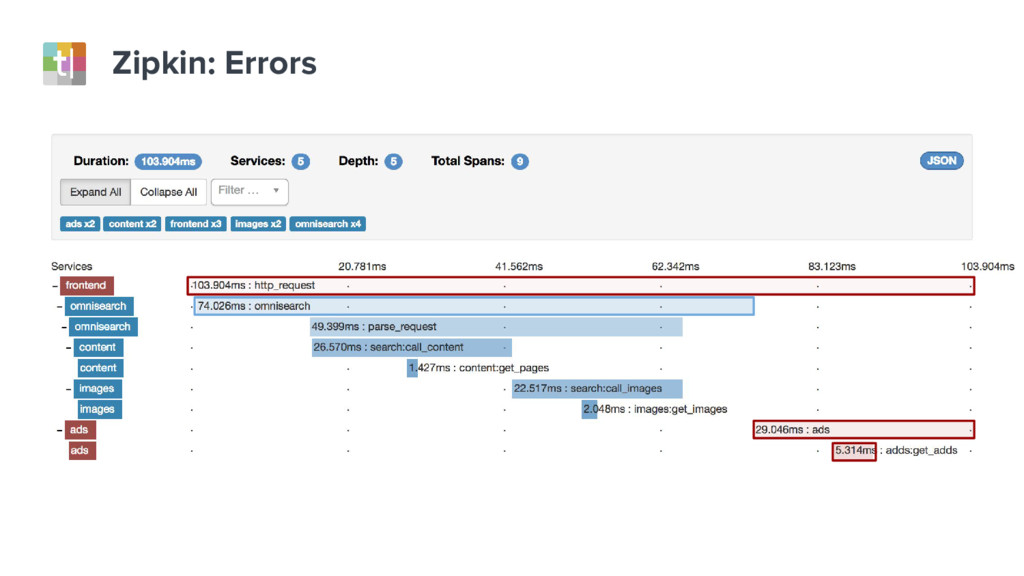{kind=link}
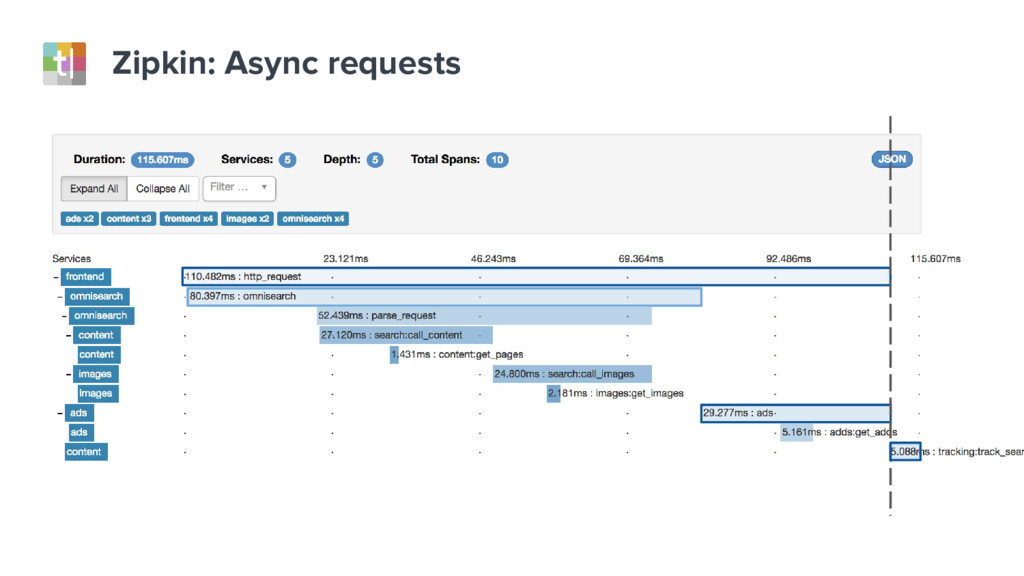{kind=link}
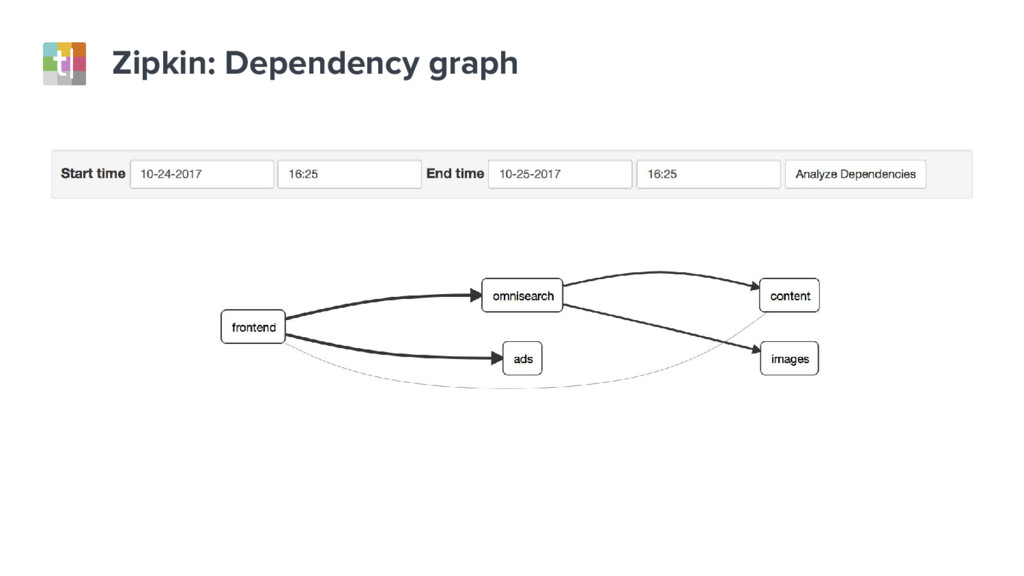{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}