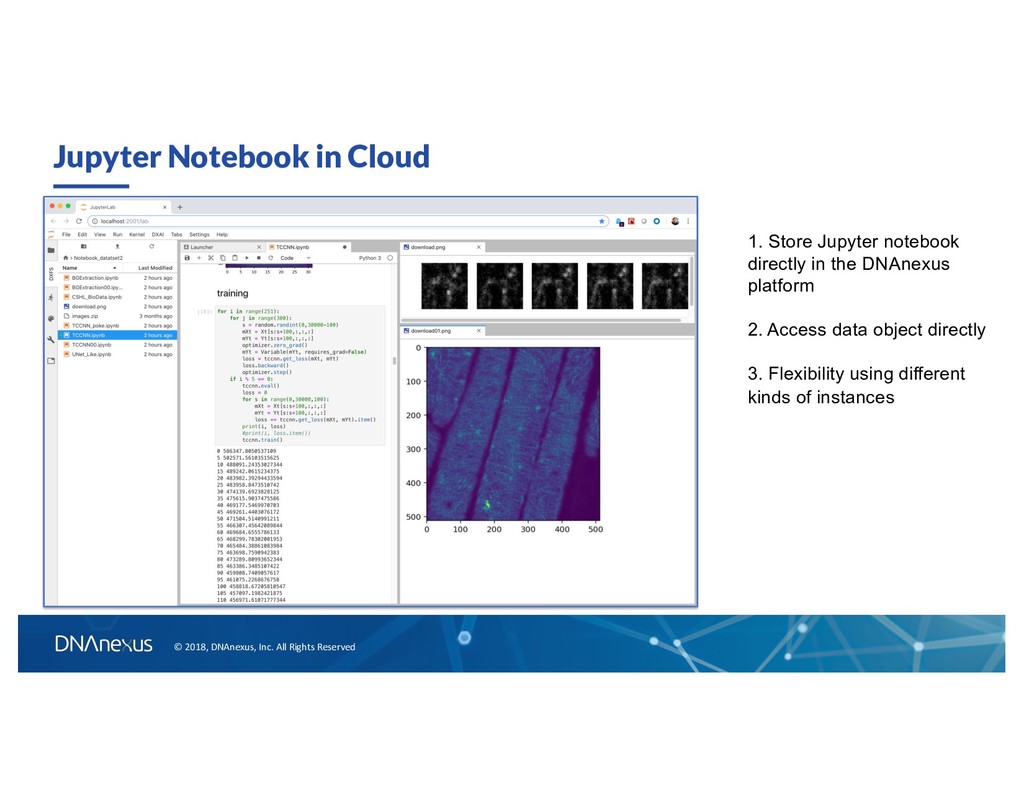
Different Time Scale for Time-lapse Image Sequences With A Deep CNN Nov 10 , 2018 Jason Chin (twitter: @infoecho)1, Andrew Carroll1,2, Xiaoran Xin3, Ying Gu3 1DNAnexus 2Current affiliation: Google Brain 3Biochemistry and Molecular Biology, Pennsylvania State University
Cellulose: - the single most abundant biopolymer on earth. - makes up about 95 percent of paper and 90 percent of cotton - cellulose has also been considered as a major component of biofuels. - Understanding how cellulose is synthesized may allow us to optimize its use as a renewable energy source. https://news.psu.edu/story/141566/201 0/05/18/research/secrets-cellulose https://www.greencarcongress.com/2018/04/20180402- pennstate.html
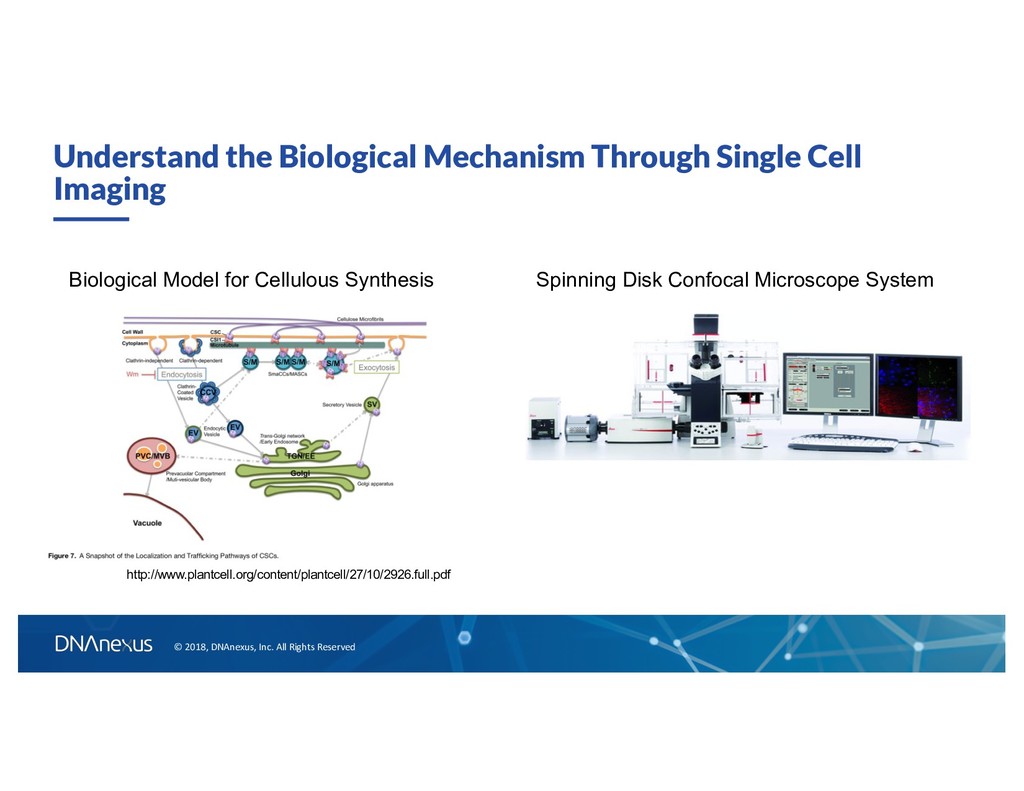
Mechanism Through Single Cell Imaging Spinning Disk Confocal Microscope System http://www.plantcell.org/content/plantcell/27/10/2926.full.pdf Biological Model for Cellulous Synthesis
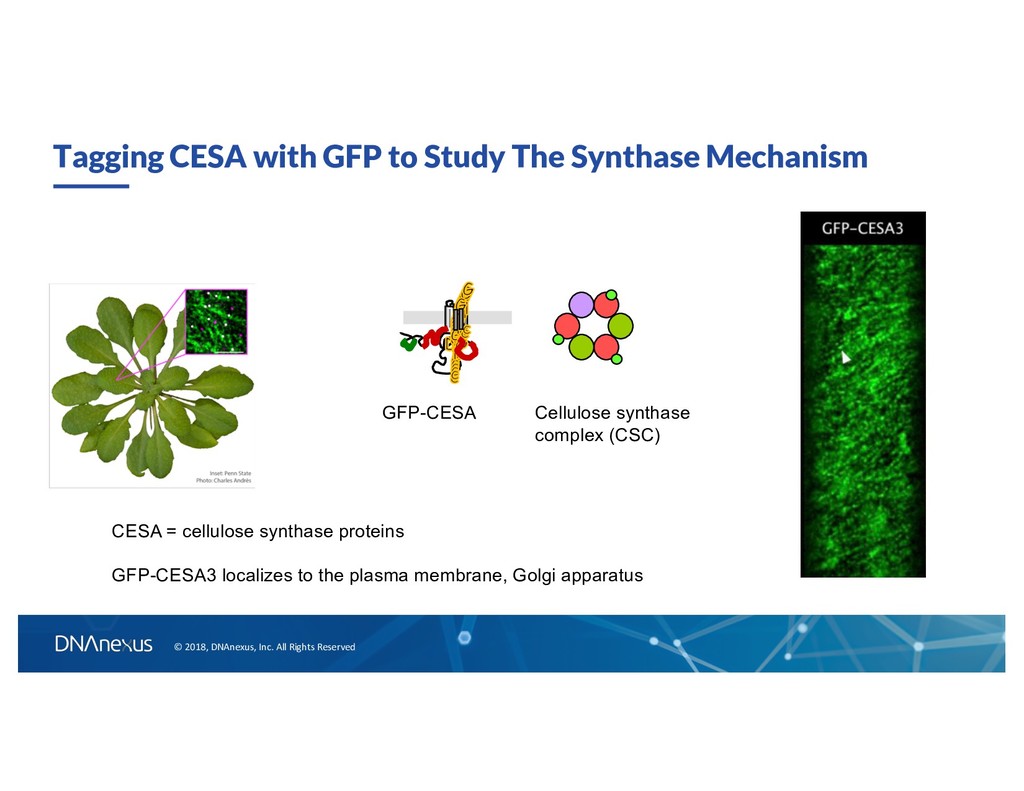
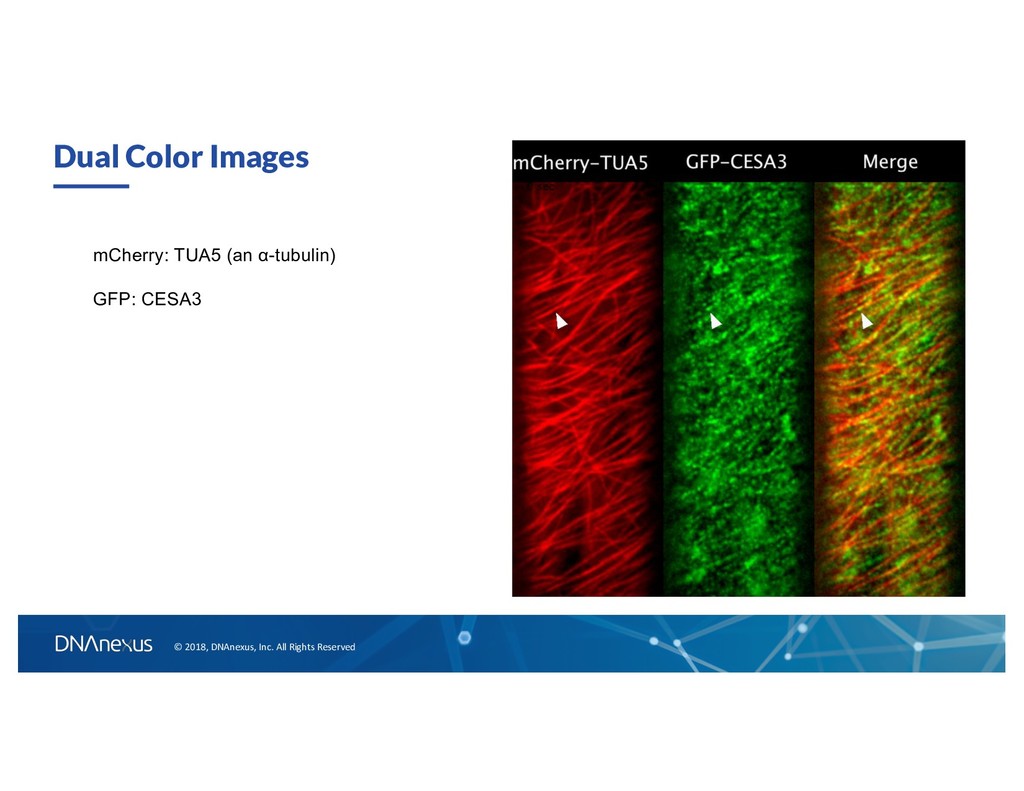
GFP to Study The Synthase Mechanism GFP-CESA Cellulose synthase complex (CSC) CESA = cellulose synthase proteins GFP-CESA3 localizes to the plasma membrane, Golgi apparatus
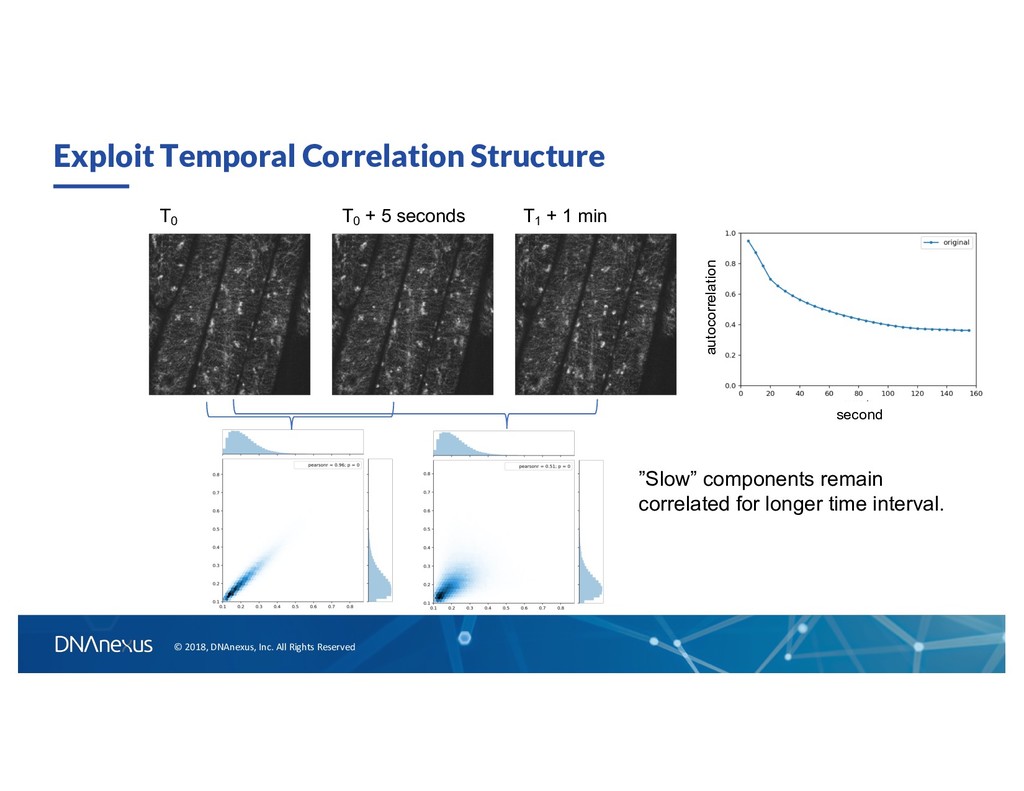
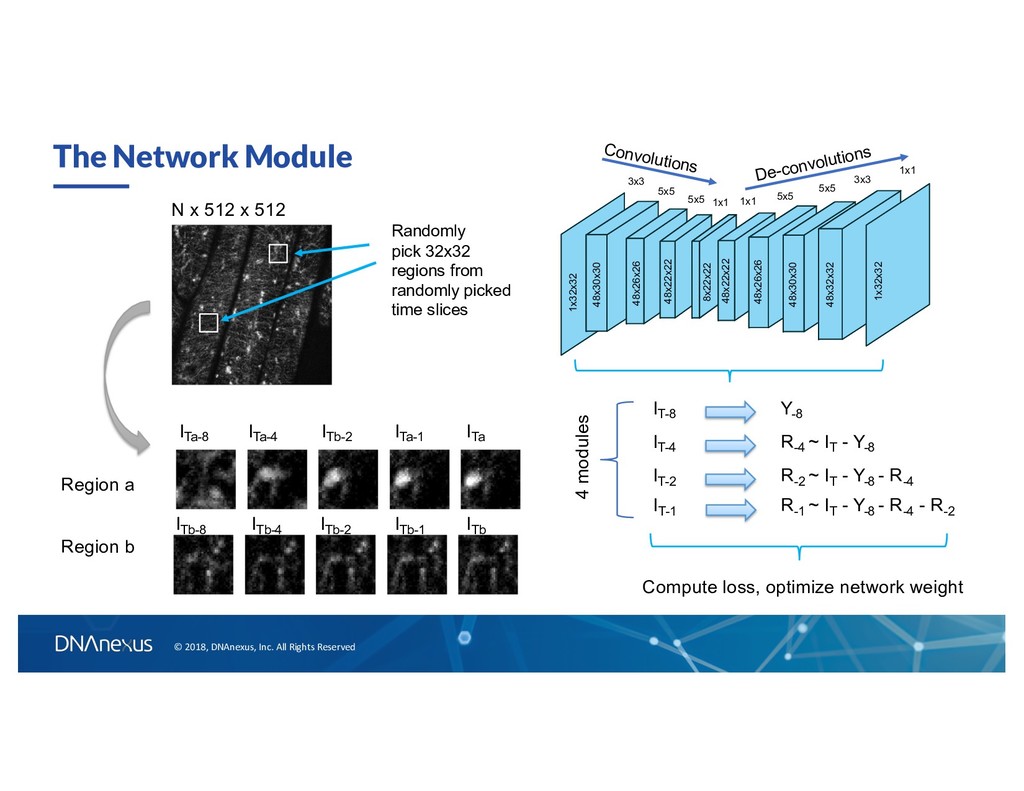
Different Spatial-Temporal “Features”? • Size • Brightness • Shape • Moving speed, etc. Can we exploit all these features “automatically” to sperate fast and slow components with a deep neural network architecture?
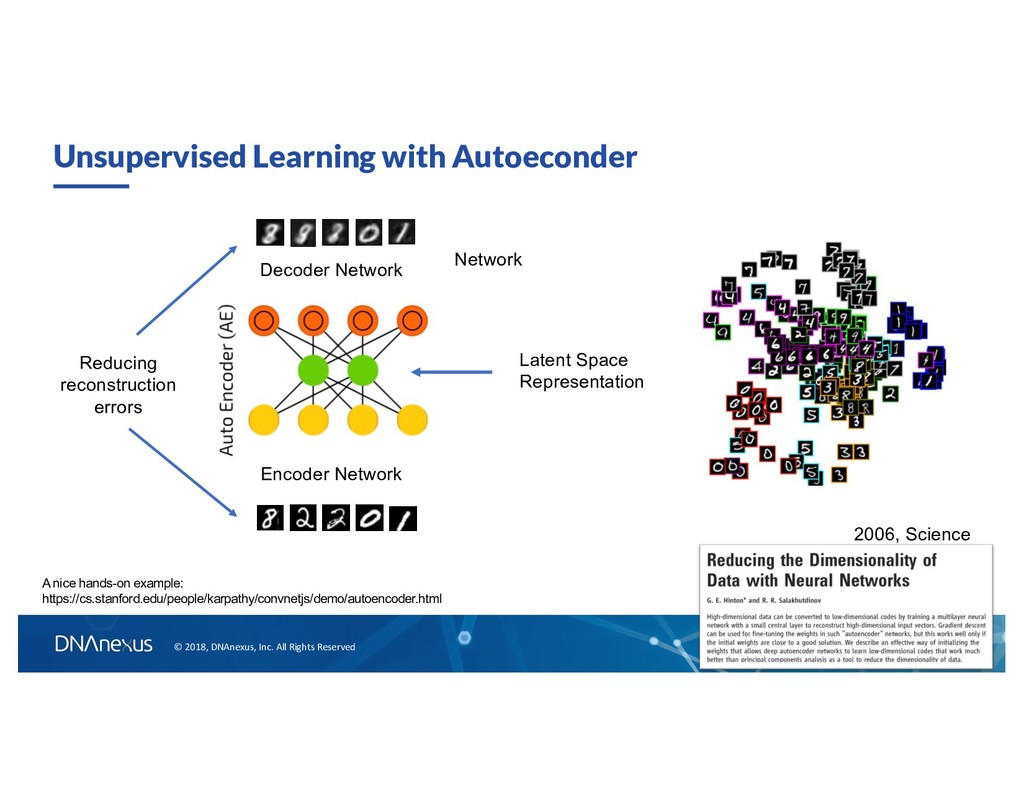
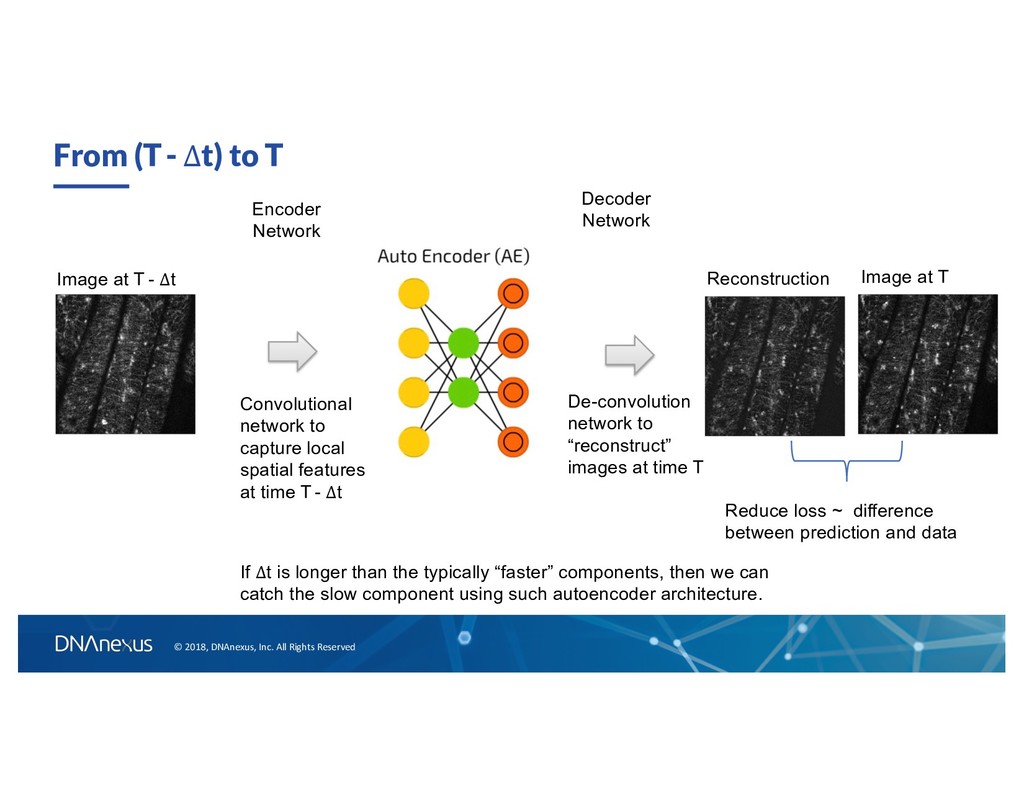
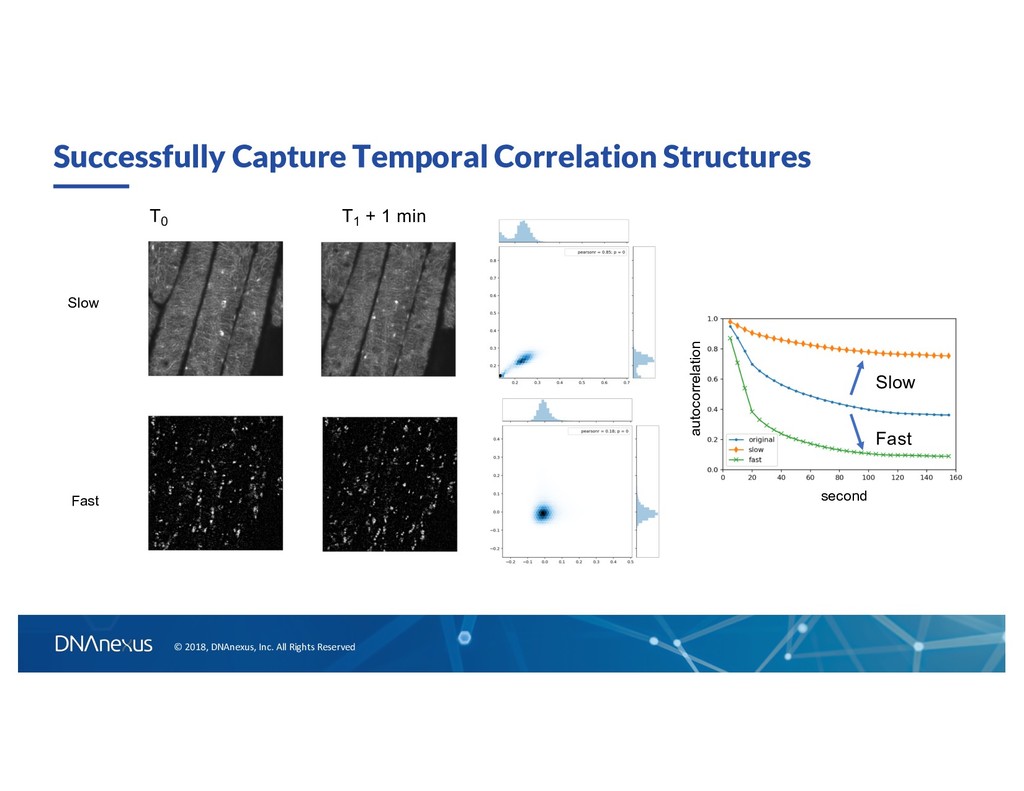
to T Encoder Network Decoder Network Image at T Image at T - ∆t If ∆t is longer than the typically “faster” components, then we can catch the slow component using such autoencoder architecture. Convolutional network to capture local spatial features at time T - ∆t De-convolution network to “reconstruct” images at time T Reconstruction Reduce loss ~ difference between prediction and data
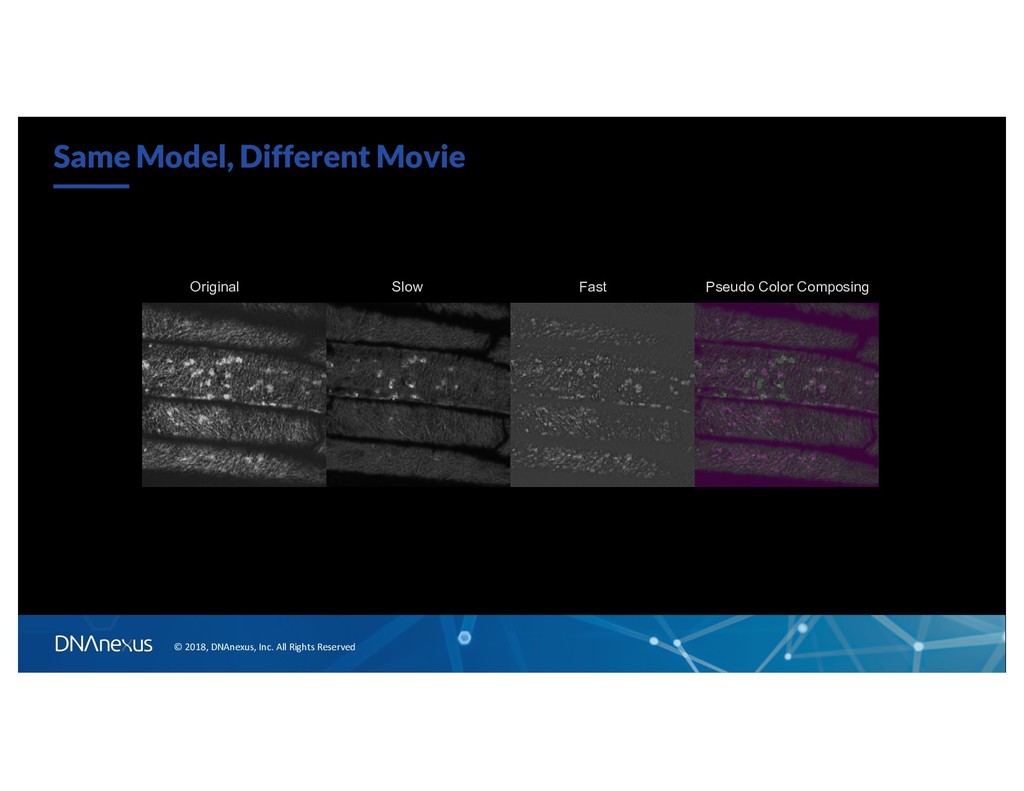
original Slow (stationary) Moving Video Prediction with Autoencoder Video Background Removal With Robust PCA https://sites.google.com/site/backgroundsubtraction/rece nt-background-modeling/background-modeling-via-rpca
deep neural network architecture that can “learn” spatiotemporal correlation structure to sperate movements for single cell images • More quantitative benchmarking will help to guide for better network architectures • Can we measure interesting important kinetic quantities simultaneously (for example, improve or incorporate particle tracking)? • Build models with some better constrains and/or priors, for example, modeling covariance structure using gaussian processes • + Supervised learning -> Super-resolution
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}