x p matrix • p is large (often >> n) • OLS estimates are highly variable or unidentifiable • Variable selection methods remove unnecessary predictors from the model • Focus on automated approaches, rather than model building • Emphasis is often on prediction accuracy, though post-selection methods for inference exist y = X + ✏
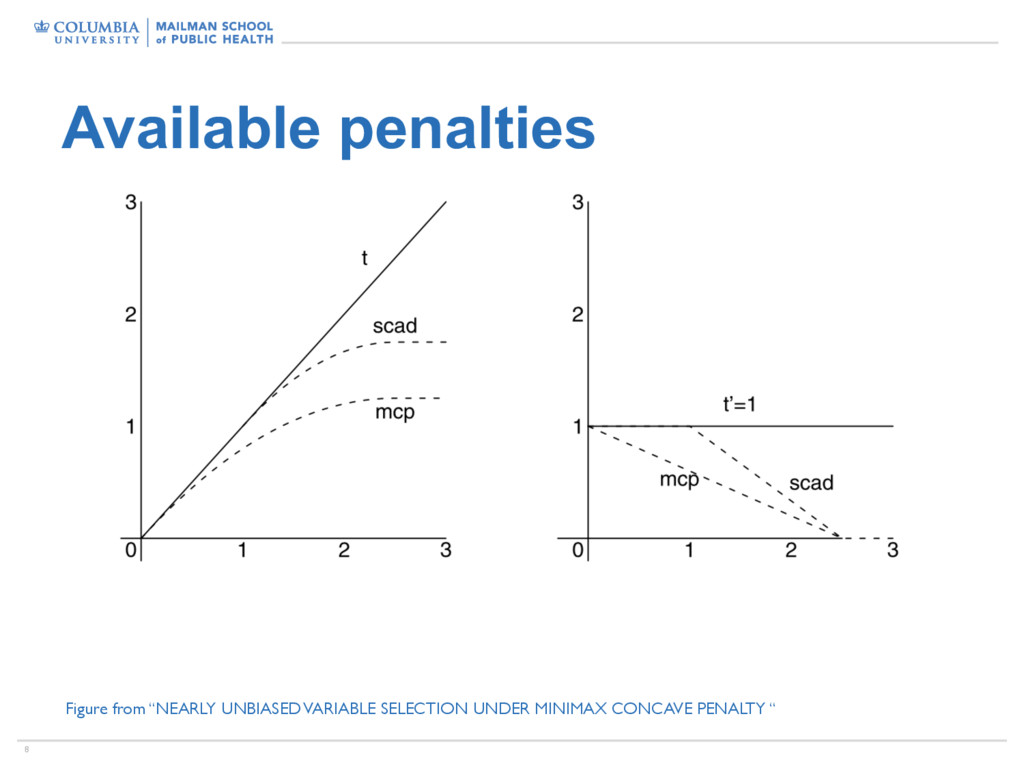
large coefficients are shrunk • Recent alternatives have sought to address this • Smoothly clipped absolute deviation penalty (SCAD) • Minimax concave penalty (MCP) • For example, solutions under SCAD penalty are
and Slab” approach • One narrow prior and one wide prior, with a latent binary indicator separating predictors between the two • Often the spike is a point-mass at zero, but recent work has used a narrow but continuous prior • Recently, shrinkage priors (e.g. Horseshoe prior; Dirichlet-Laplace prior) have become popular • Good computational and (sometimes) theoretical properties
individual covariates to zero • We’ll shortly see that shrinking groups of variables to zero is useful for our purposes today • To that end, group variable selection methods are needed: • Group versions of each major penalty exist (y X )T (y X ) + G X g=1 p (|| g ||)
passing, but not be a major emphasis of today’s material • Briefly, multiple penalties can be used in the same minimization problem: (y X )T (y X ) + p X k=1 p1, 1 (| k |) + p X k=1 p2, 2 (| k |)
via Nonconcave Penalized Likelihood and its Oracle Properties. JASA. • Zhang (2010). Nearly Unbiased Variable Selection Under Minimax Concave Penalty. Annals of Statistics. • Rockova and George (2014). EMVS: The EM Approach to Bayesian Variable Selection. JASA.
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}