Speaker: Gereon Kaiping , University of Leiden
Title: Some Assembly Required: From sounds to histories in 8 steps using mostly off-the-shelf tools.
Abstract: Phylogenetic methods are gaining traction in linguistics, but have so far been quite inaccessible to linguists:
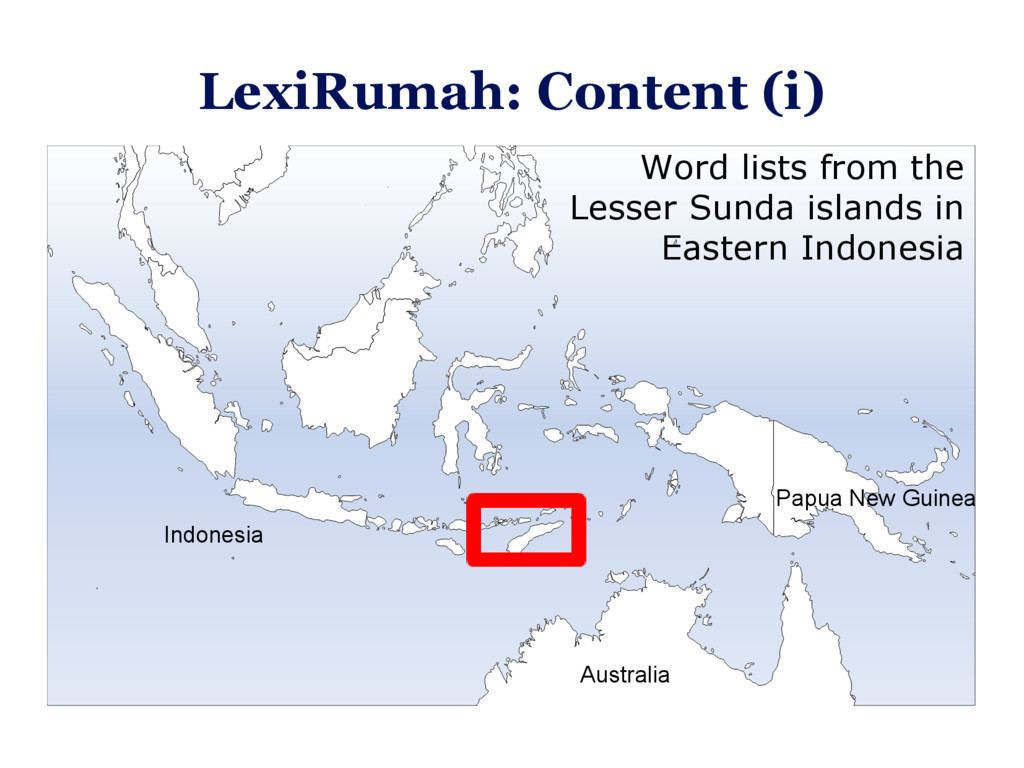
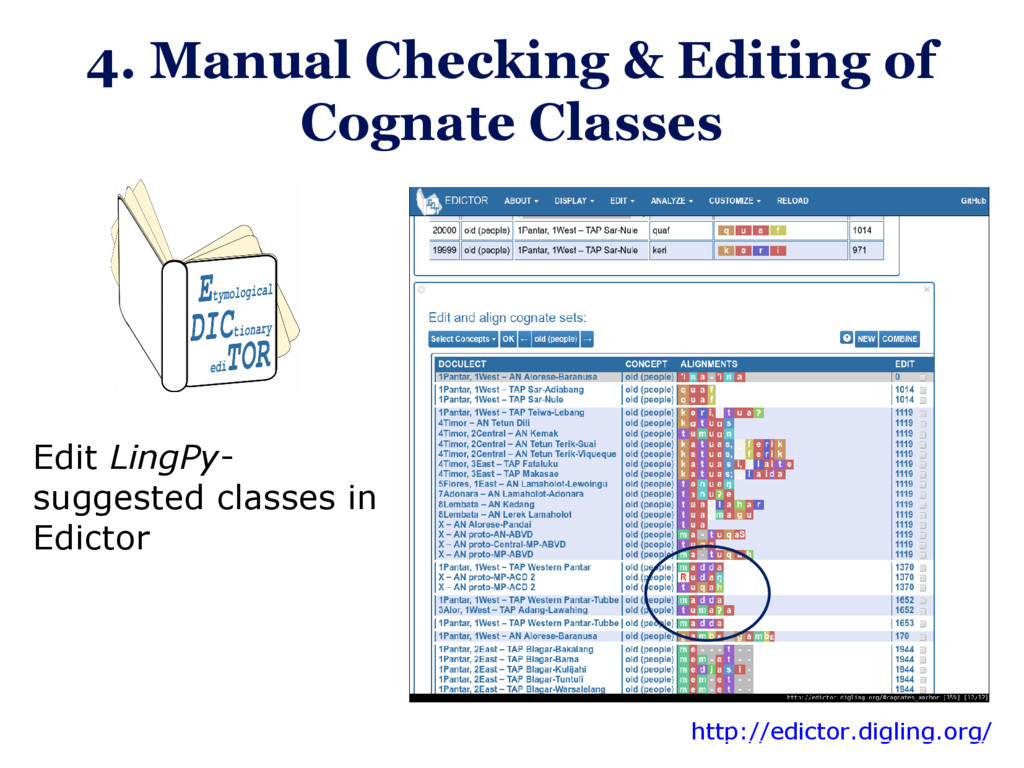
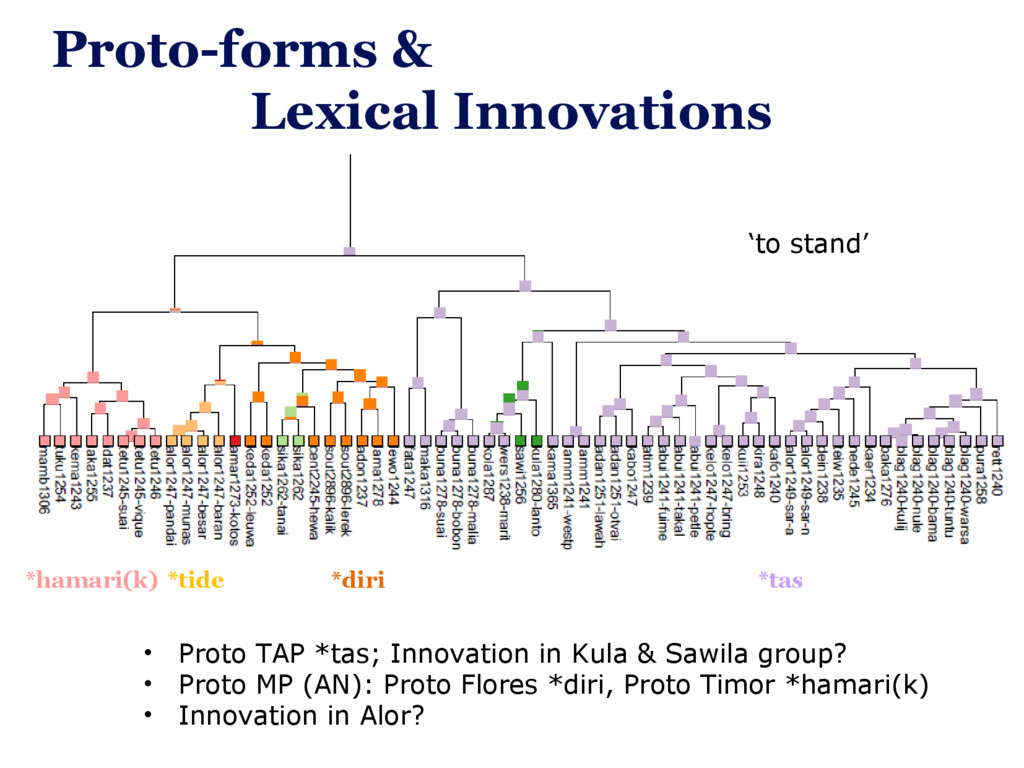
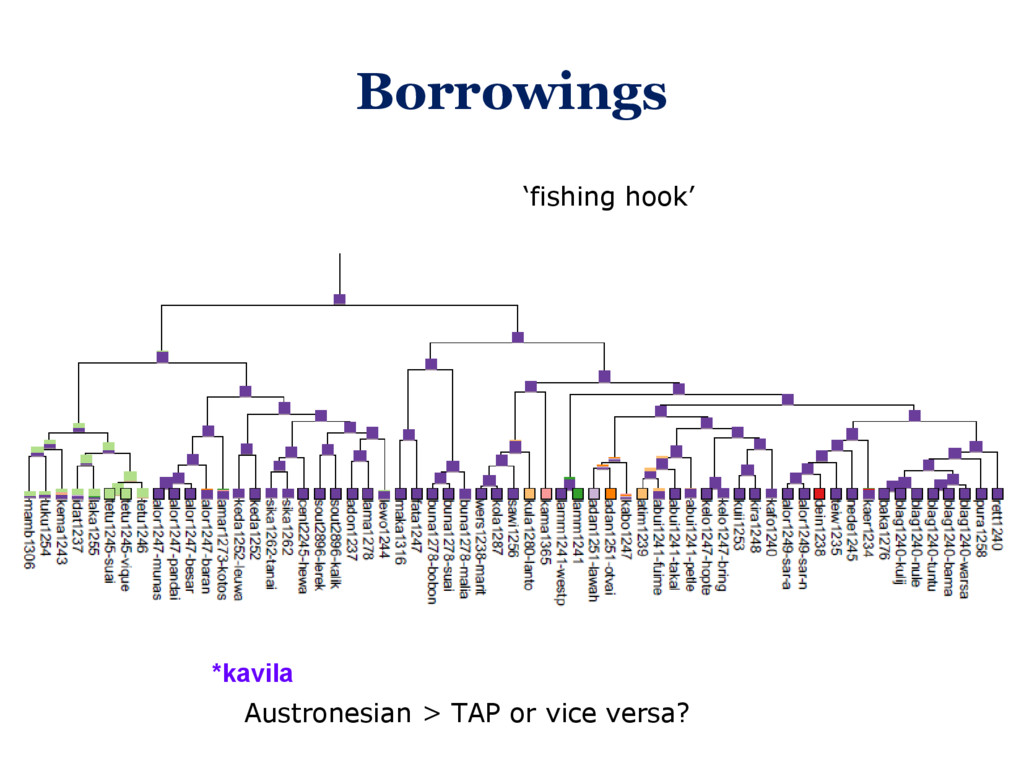
The core tools doing the tree construction – whether they be heuristic or Bayesian – often come from bioinformatics, and their inputs (eg. Nexus files) and outputs (eg. Newick trees without explicit reconstruction) conform to biological, not linguistic standards – or they are ad-hoc written for a specific datasets. However, this situation is changing: In this talk, I will present a collection of tools, most of which are published elsewhere, that together go the full way from linguistic fieldwork via public cross-linguistic linked databases and Bayesian inference tools to plots of phylogenetic trees with ancestral state reconstruction. I will describe both emerging standards in quantitative historical linguistics that make this process easier, and specific challenges that arose in the construction of this tool chain. The talk will conclude with the discussion of some results from the reconstructed word-meaning correspondences in the Lesser Sunda region of Indonesia, and how they feed back into improving our data and understanding of the local language history.
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![BEASTling model description # -*- coding: utf-8 -*- [admin] basename](https://files.speakerdeck.com/presentations/4c4094b2926d488989a036d86e8f230f/slide_12.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
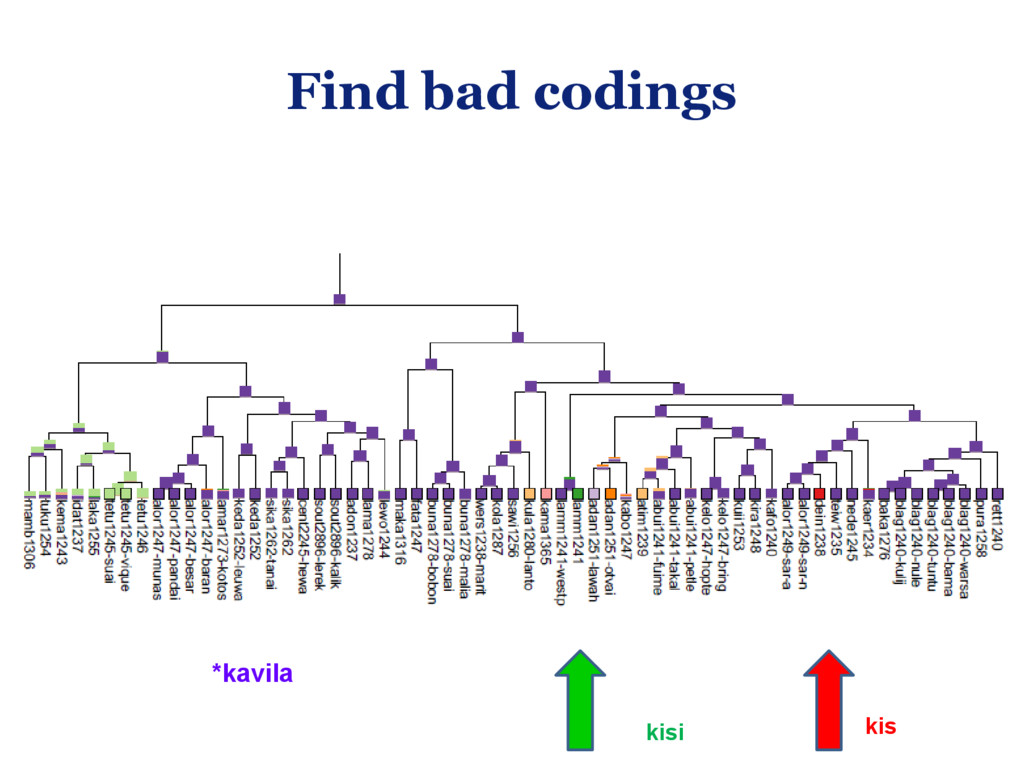{kind=link}
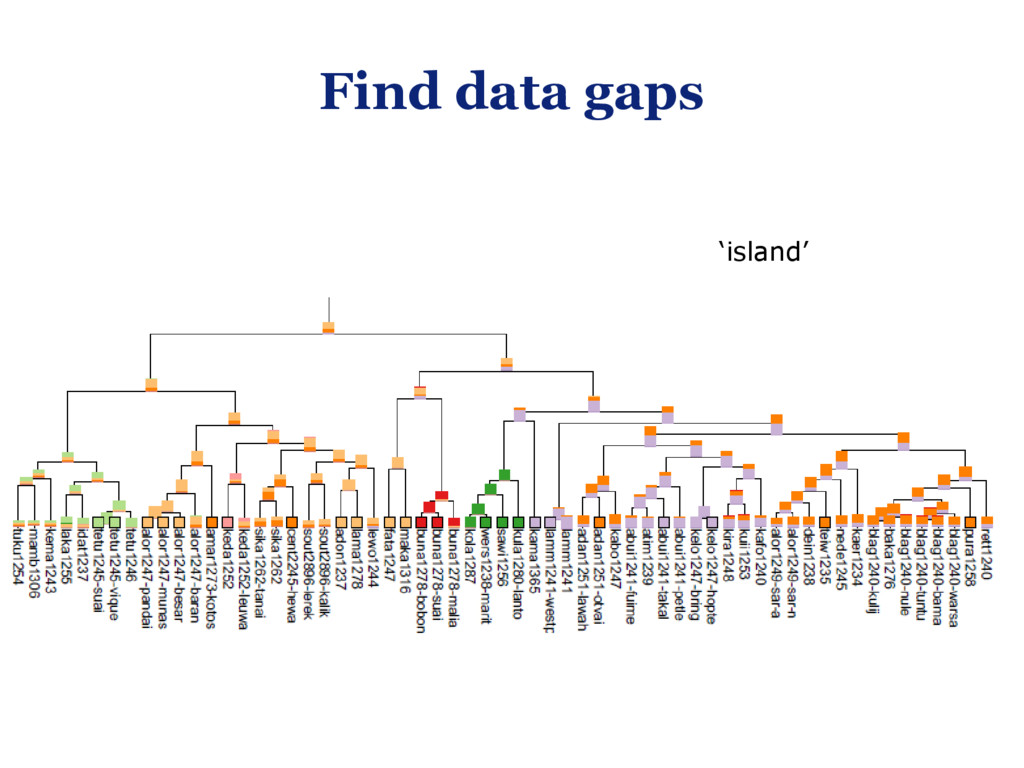{kind=link}
{kind=link}
{kind=link}
{kind=link}