Upgrade to Pro
— share decks privately, control downloads, hide ads and more …
Speaker Deck
Features
Speaker Deck
PRO
Sign in
Sign up for free
Search
Search
Amazon Athena で JSON・Parquet・Iceberg のデータを検索し、性...
Search
ShigeruOda
October 28, 2025
Technology
580
1
Share
Embed
Copy iframe code
Copy JS code
Copy link
Start on current slide
Amazon Athena で JSON・Parquet・Iceberg のデータを検索し、性能を比較してみた
https://jawsug-bgnr.connpass.com/event/369974/
ShigeruOda
October 28, 2025
More Decks by ShigeruOda
See All by ShigeruOda
JAWS-UG クラウド女子会×初心者支部 コラボ会 ~子連れ参加ウェルカム勉強会!
shigeruoda
0
100
AWS re:Invent 2025 Apache Iceberg Recap
shigeruoda
1
110
Amazon S3標準/ S3 Tables/S3 Express One Zoneを使ったログ分析
shigeruoda
6
970
CFP選定とタイムテーブル決めについて
shigeruoda
0
200
今年前半のAWSアップデートを振り返り
shigeruoda
0
160
#31 JAWS-UG主催 週刊AWSキャッチアップ (2024/5/6週)
shigeruoda
0
230
#30 JAWS-UG主催 週刊AWSキャッチアップ(2024/4/29週)
shigeruoda
0
190
#28 JAWS-UG主催 週刊AWSキャッチアップ(2024/4/15週)
shigeruoda
0
220
#27 JAWS-UG主催 週刊AWSキャッチアップ(2024/4/8週)
shigeruoda
0
280
Other Decks in Technology
See All in Technology
事業成長とAI活用を止めないデータ基盤アーキテクチャの設計思想
hiracky16
0
720
【公開用】AI_Dev_Ex2026_AI_登壇資料
matsuritechnologies
PRO
2
630
『モデル + ハーネス』で読み解く AIエージェント入門
oracle4engineer
PRO
2
200
キャリアLT会#3
beli68
2
270
Vポイント分析基盤におけるデータモデリング20年史
taromatsui_cccmkhd
4
770
AI工学特論: MLOps・継続的評価
asei
10
2.6k
AIツールを導入しても生産性はあがらない? カオナビが直面した 3つの壁と乗り越え方。/ Overcoming 3 Barriers to AI-Driven Productivity at kaonavi
kaonavi
0
310
AI時代の開発生産性を捉え直す — 経営と現場をつなぐ「開発組織のオブザーバビリティ」— / AI Dev Ex Conference 2026
tkyowa
1
1.6k
コンテナ・K8s研修【MIXI 26新卒技術研修】
mixi_engineers
PRO
1
250
Claude CodeとAmazon Bedrock AgentCoreでつくる、自分だけのAIアシスタント
ymae
0
110
OpenTelemetryにおけるGoのゼロコード・コンパイル時計装について #fukuokago
quiver
0
330
伝票作成AIエージェントを支える、LLMOpsとインフラの選択肢 / AICon2026_takeda
rakus_dev
0
300
Featured
See All Featured
A Tale of Four Properties
chriscoyier
163
24k
Color Theory Basics | Prateek | Gurzu
gurzu
0
400
The Straight Up "How To Draw Better" Workshop
denniskardys
239
140k
The Art of Delivering Value - GDevCon NA Keynote
reverentgeek
16
2k
Avoiding the “Bad Training, Faster” Trap in the Age of AI
tmiket
0
200
Code Reviewing Like a Champion
maltzj
528
40k
Technical Leadership for Architectural Decision Making
baasie
3
450
How Fast Is Fast Enough? [PerfNow 2025]
tammyeverts
3
660
Stop Working from a Prison Cell
hatefulcrawdad
274
21k
Testing 201, or: Great Expectations
jmmastey
46
8.2k
30 Presentation Tips
portentint
PRO
1
350
How to Align SEO within the Product Triangle To Get Buy-In & Support - #RIMC
aleyda
2
1.7k
Transcript
Amazon Athena で json、Parquet、Iceberg のデータ を検索し、性能比較してみた データ形式の進化と Iceberg の優位性 Amazon
Athena で json、Parquet、Iceberg のデータを検索し、性能比較してみた 2025/10/28 1
自己紹介 Name : Shigeru Oda Role : Product Infrastructure Technical
Lead at Sansan, Inc. Community : AWS Community Hero and Organizer of the JAWS-UG Beginners Branch Amazon Athena で json、Parquet、Iceberg のデータを検索し、性能比較してみた 2025/10/28 2
ゴール Apache Parquet/Apache Iceberg を利用する上で最適なパフォーマンスを得るため に、フォーマットについて説明とパフォーマンス比較の結果について説明します Amazon S3/Amazon Athena を利用することを前提としています
Amazon Athena で json、Parquet、Iceberg のデータを検索し、性能比較してみた 2025/10/28 3
元ネタ Amazon Athena で json、Parquet、Iceberg のデータを検索し、性能比較してみた 2025/10/28 4
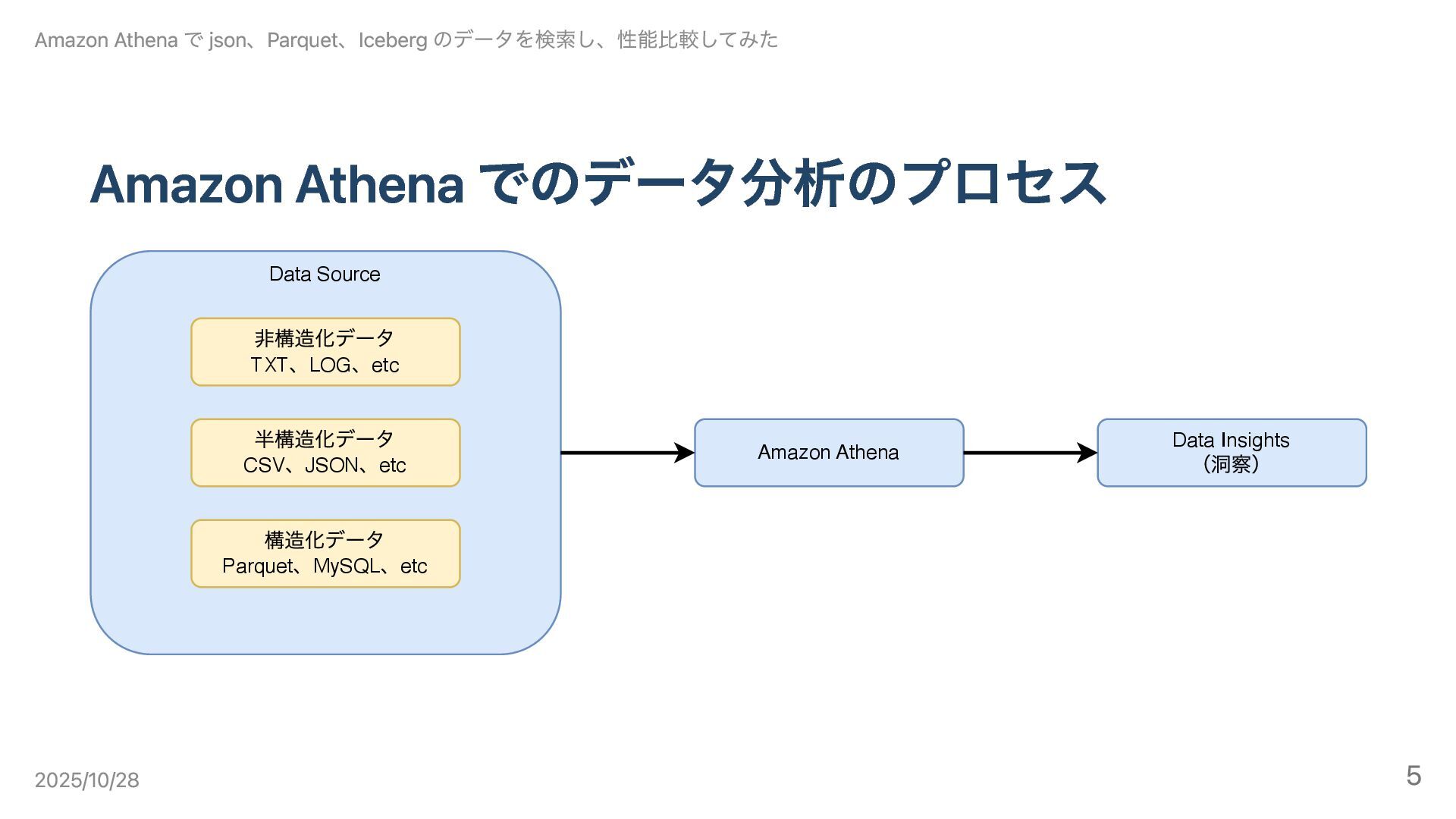
Amazon Athena でのデータ分析のプロセス Data Source ⾮構造化データ TXT 、LOG 、etc 半構造化データ
CSV 、JSON 、etc 構造化データ Parquet 、MySQL 、etc Amazon Athena Data Insights (洞察) Amazon Athena で json、Parquet、Iceberg のデータを検索し、性能比較してみた 2025/10/28 5
非構造化・半構造化・構造化データ 非構造化データ: TXT、LOG、etc 明確なスキーマや構造が定義されていないため、柔軟性は高いが、Athena で の処理コストが高い 半構造化データ: CSV、JSON、etc 部分的にスキーマが定義されており、構造化された形式でデータが格納され ているため、非構造化データより
Athena での処理コストが低い 構造化データ: Parquet、MySQL、etc 厳密にスキーマが定義されているため、Athena での処理コストが最も少な く、各データの要素がどこに配置されている位置が予測しやすい Amazon Athena で json、Parquet、Iceberg のデータを検索し、性能比較してみた 2025/10/28 6
ワークロードの種類 OLTP(Online Transaction Processing): トランザクション処理 行単位データの参照・更新・削除が大量に発生 日常的な業務処理(挿入、更新、削除など)を高速にリアルタイムで実行す ることに目的 OLAP(Online Analytical
Processing): 分析処理 列単位のデータの参照・集計が大量に発生 蓄積された大量のデータを集計・分析し、意思決定を支援することを目的 Parquet は OLAP 向けのデータ形式 Amazon Athena で json、Parquet、Iceberg のデータを検索し、性能比較してみた 2025/10/28 7
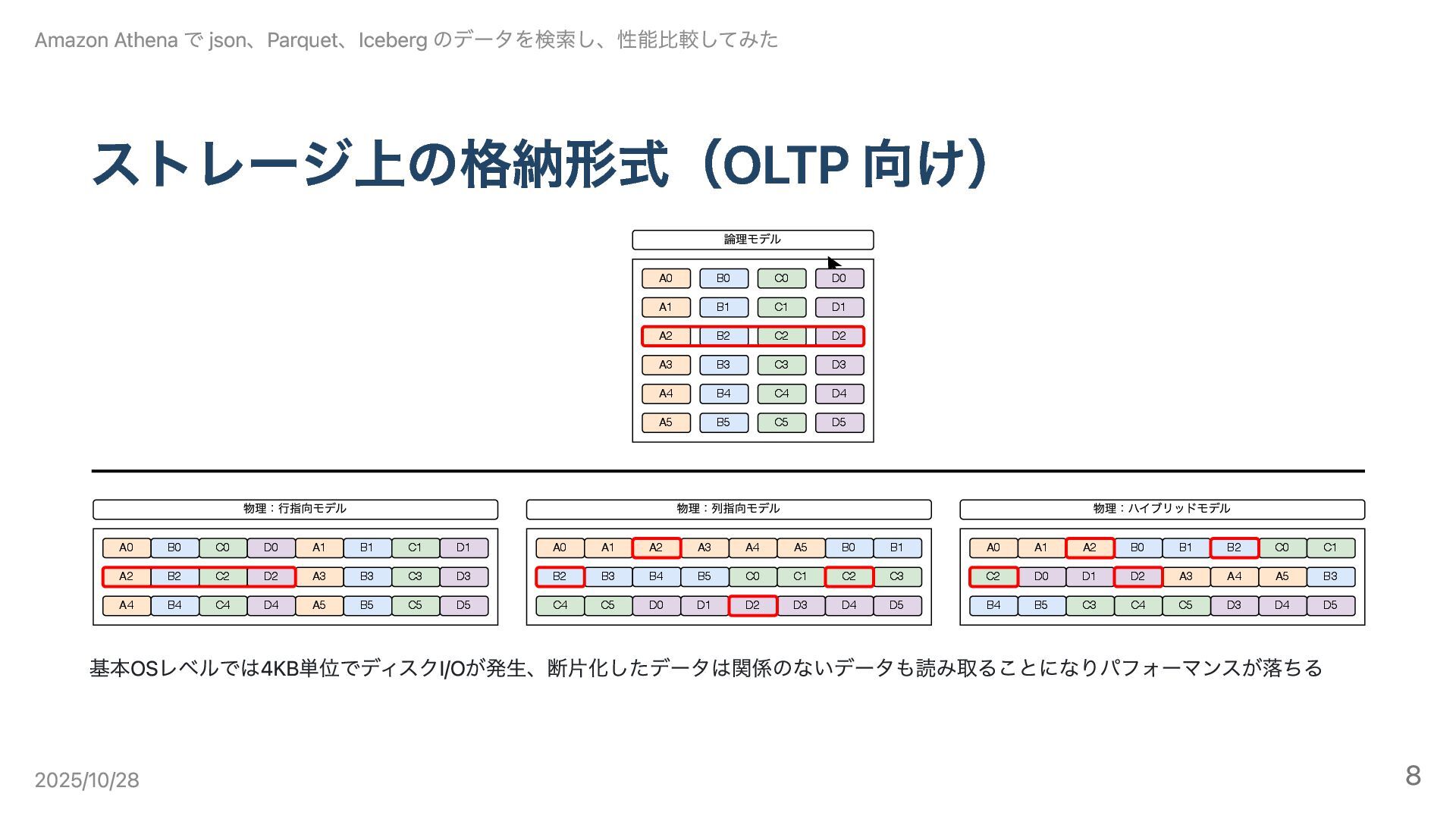
ストレージ上の格納形式(OLTP 向け) A0 B0 C0 D0 A1 B1 C1 D1
A2 B2 C2 D2 A3 B3 C3 D3 A4 B4 C4 D4 論理モデル A0 B0 C0 D0 A1 B1 C1 D1 A2 B2 C2 D2 A3 B3 C3 D3 A4 B4 C4 D4 A0 B0 C0 D0 A1 B1 C1 D1 A2 B2 C2 D2 A3 B3 C3 D3 A4 B4 C4 D4 A0 B0 C0 D0 A1 B1 C1 D1 A2 B2 C2 D2 A5 B5 C5 D5 A5 B5 C5 D5 D5 C5 B5 A5 A3 A4 A5 B3 B4 B5 D3 D4 D5 C4 C5 C3 物理:⾏指向モデル 物理:列指向モデル 物理:ハイブリッドモデル 基本OSレベルでは4KB単位でディスクI/Oが発生、断片化したデータは関係のないデータも読み取ることになりパフォーマンスが落ちる Amazon Athena で json、Parquet、Iceberg のデータを検索し、性能比較してみた 2025/10/28 8
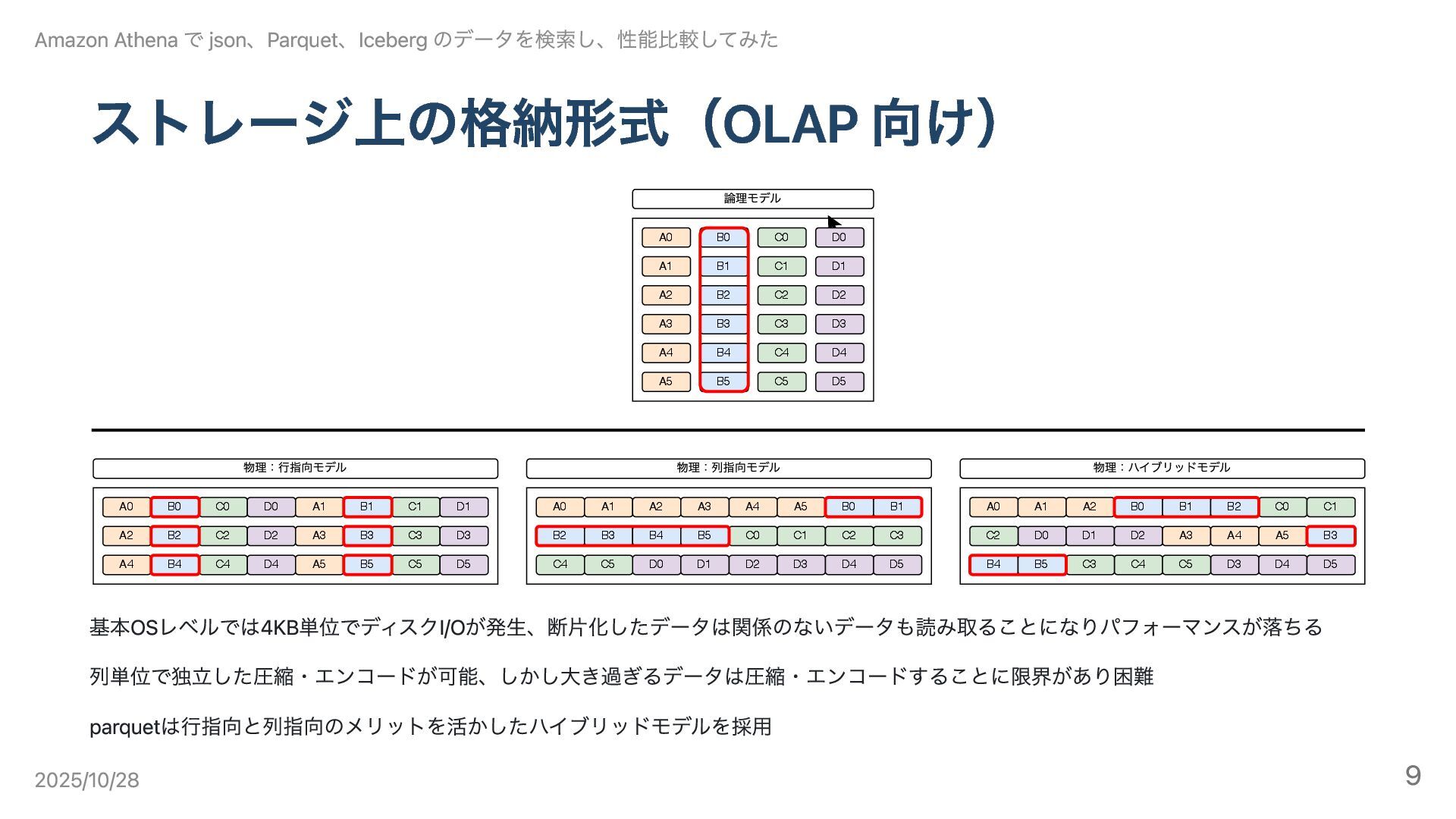
ストレージ上の格納形式(OLAP 向け) A0 B0 C0 D0 A1 B1 C1 D1
A2 B2 C2 D2 A3 B3 C3 D3 A4 B4 C4 D4 論理モデル A0 B0 C0 D0 A1 B1 C1 D1 A2 B2 C2 D2 A3 B3 C3 D3 A4 B4 C4 D4 A0 B0 C0 D0 A1 B1 C1 D1 A2 B2 C2 D2 A3 B3 C3 D3 A4 B4 C4 D4 A0 B0 C0 D0 A1 B1 C1 D1 A2 B2 C2 D2 A5 B5 C5 D5 A5 B5 C5 D5 D5 C5 B5 A5 A3 A4 A5 B3 B4 B5 D3 D4 D5 C4 C5 C3 物理:⾏指向モデル 物理:列指向モデル 物理:ハイブリッドモデル 基本OSレベルでは4KB単位でディスクI/Oが発生、断片化したデータは関係のないデータも読み取ることになりパフォーマンスが落ちる 列単位で独立した圧縮・エンコードが可能、しかし大き過ぎるデータは圧縮・エンコードすることに限界があり困難 parquetは行指向と列指向のメリットを活かしたハイブリッドモデルを採用 Amazon Athena で json、Parquet、Iceberg のデータを検索し、性能比較してみた 2025/10/28 9
Parquet File Format (model) Parquet File Magic Number(4bytes) : PAR1
RowGroup 0 (default : 128MB ) Column Chunk (col A) Column Chunk (col B) Column Chunk (col C) RowGroup 1 (default : 128MB ) RowGroup N (default : 128MB ) Footer MetaData Footer Length (4 bytes) Magic Number(4bytes) : PAR1 A0 B0 C0 D0 A1 B1 C1 D1 A2 B2 C2 D2 A3 A4 A5 B3 B4 B5 D3 D4 D5 C4 C5 C3 物理:ハイブリッドモデル Column Chunk (col D) Amazon Athena で json、Parquet、Iceberg のデータを検索し、性能比較してみた 2025/10/28 10
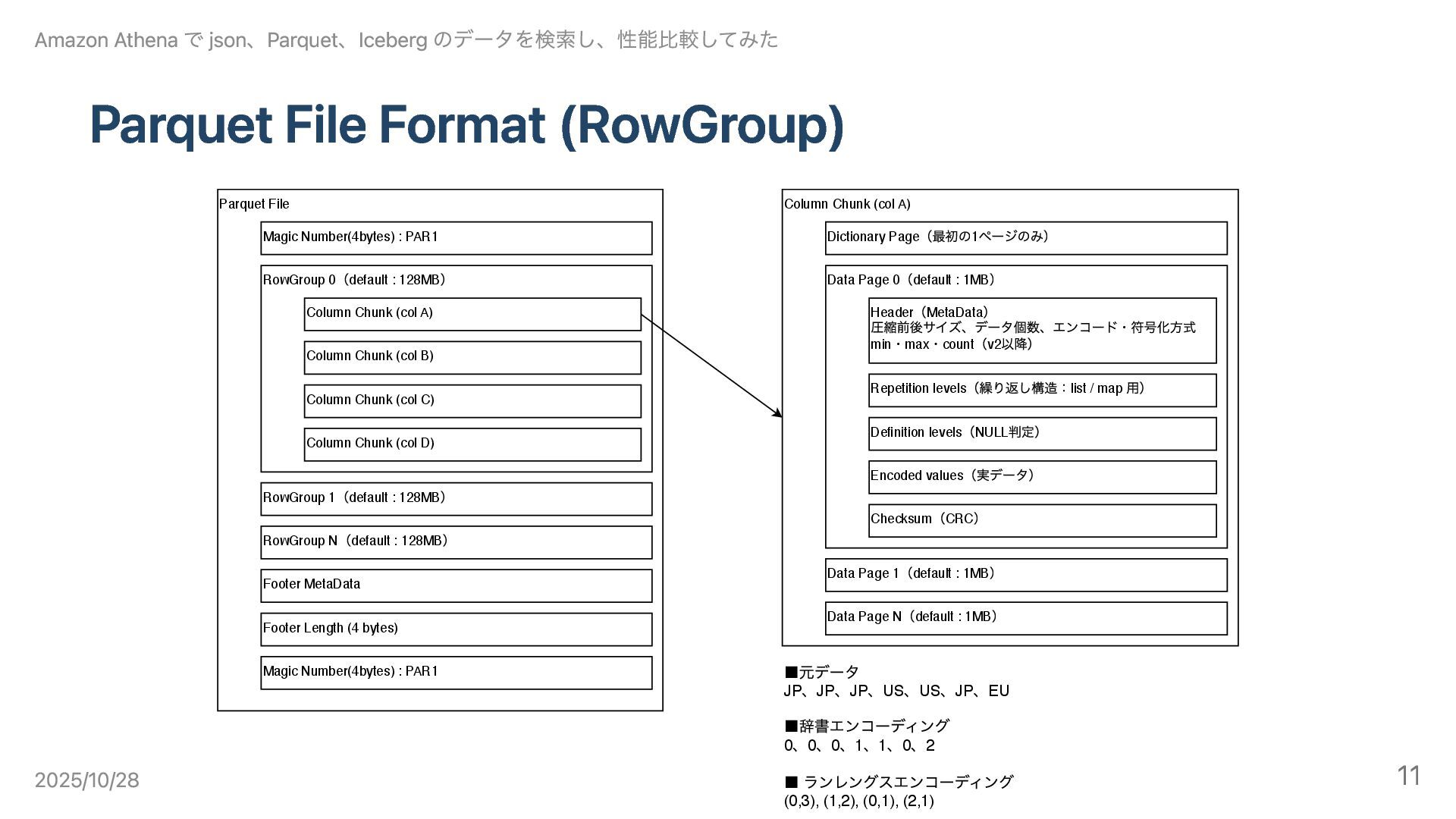
Parquet File Format (RowGroup) Parquet File Magic Number(4bytes) : PAR1
RowGroup 0 (default : 128MB ) Column Chunk (col A) Column Chunk (col B) Column Chunk (col C) RowGroup 1 (default : 128MB ) RowGroup N (default : 128MB ) Footer MetaData Footer Length (4 bytes) Magic Number(4bytes) : PAR1 Column Chunk (col D) Column Chunk (col A) Dictionary Page (最初の1 ページのみ) Data Page 0 (default : 1MB ) Repetition levels (繰り返し構造:list / map ⽤) Definition levels (NULL 判定) Encoded values (実データ) Checksum (CRC ) Header (MetaData ) 圧縮前後サイズ、データ個数、エンコード・符号化⽅式 min ・max ・count (v2 以降) Data Page 1 (default : 1MB ) Data Page N (default : 1MB ) ▪元データ JP 、JP 、JP 、US 、US 、JP 、EU ▪辞書エンコーディング 0 、0 、0 、1 、1 、0 、2 ▪ ランレングスエンコーディング (0,3), (1,2), (0,1), (2,1) Amazon Athena で json、Parquet、Iceberg のデータを検索し、性能比較してみた 2025/10/28 11
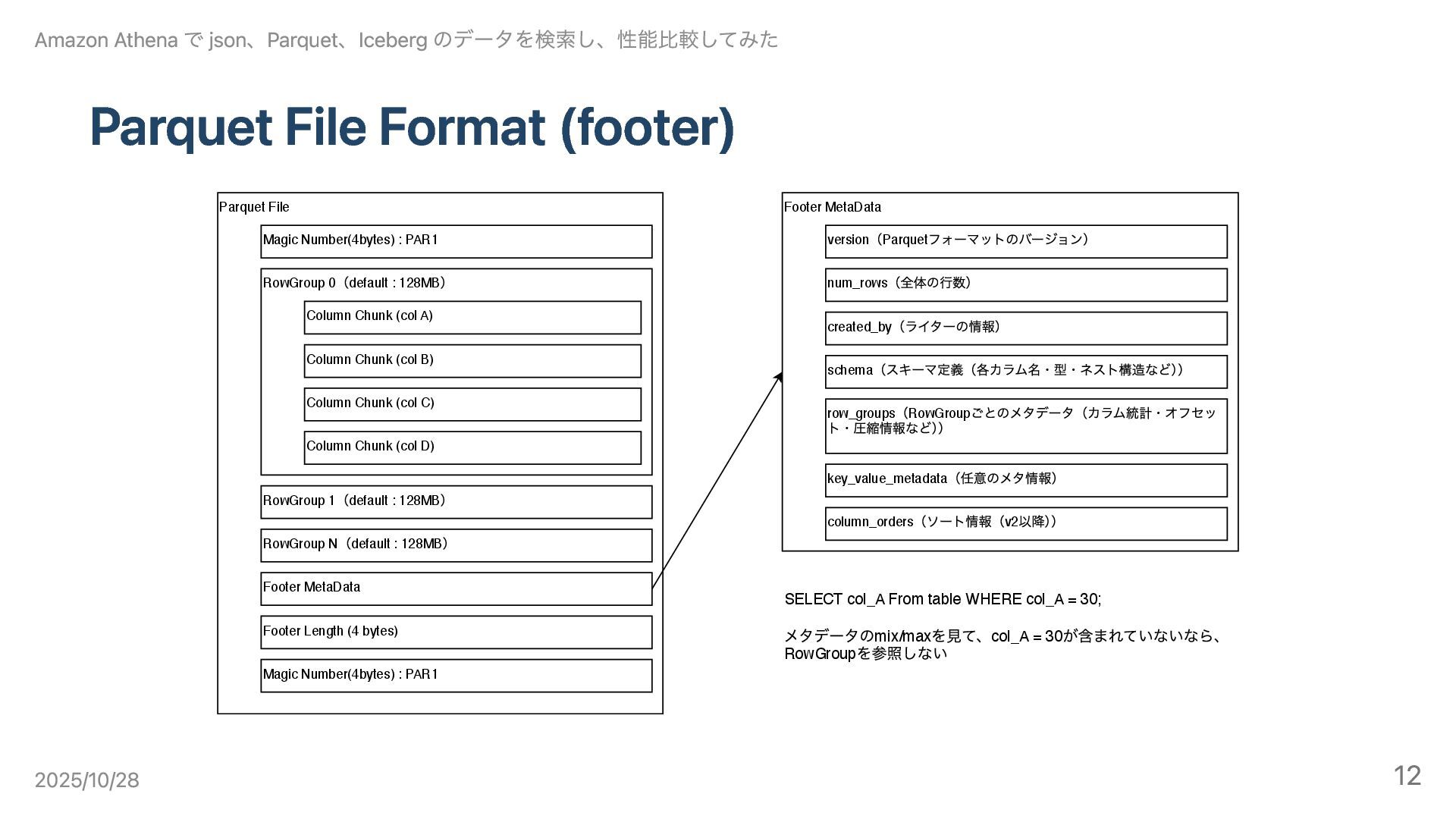
Parquet File Format (footer) Parquet File Magic Number(4bytes) : PAR1
RowGroup 0 (default : 128MB ) Column Chunk (col A) Column Chunk (col B) Column Chunk (col C) RowGroup 1 (default : 128MB ) RowGroup N (default : 128MB ) Footer MetaData Footer Length (4 bytes) Magic Number(4bytes) : PAR1 Column Chunk (col D) Footer MetaData version (Parquet フォーマットのバージョン) schema (スキーマ定義(各カラム名・型・ネスト構造など) ) row_groups (RowGroup ごとのメタデータ(カラム統計・オフセッ ト・圧縮情報など) ) key_value_metadata (任意のメタ情報) created_by (ライターの情報) column_orders (ソート情報(v2 以降) ) num_rows (全体の⾏数) SELECT col_A From table WHERE col_A = 30; メタデータのmix/max を⾒て、col_A = 30 が含まれていないなら、 RowGroup を参照しない Amazon Athena で json、Parquet、Iceberg のデータを検索し、性能比較してみた 2025/10/28 12
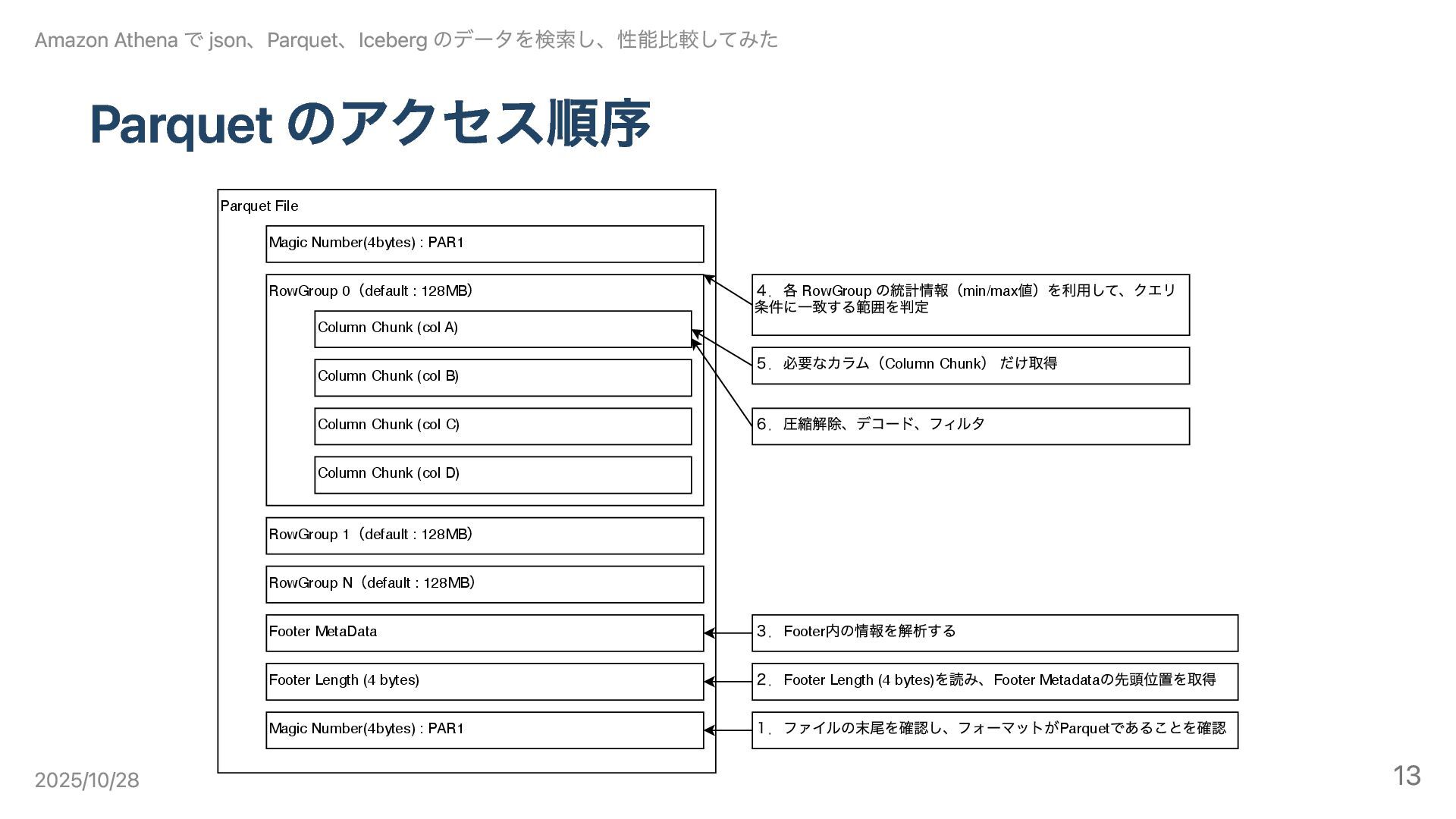
Parquet のアクセス順序 Parquet File Magic Number(4bytes) : PAR1 RowGroup 0
(default : 128MB ) Column Chunk (col A) Column Chunk (col B) Column Chunk (col C) RowGroup 1 (default : 128MB ) RowGroup N (default : 128MB ) Footer MetaData Footer Length (4 bytes) Magic Number(4bytes) : PAR1 Column Chunk (col D) 1.ファイルの末尾を確認し、フォーマットがParquet であることを確認 4.各 RowGroup の統計情報(min/max 値)を利⽤して、クエリ 条件に⼀致する範囲を判定 5.必要なカラム(Column Chunk ) だけ取得 6.圧縮解除、デコード、フィルタ 2.Footer Length (4 bytes) を読み、Footer Metadata の先頭位置を取得 3.Footer 内の情報を解析する Amazon Athena で json、Parquet、Iceberg のデータを検索し、性能比較してみた 2025/10/28 13
ファイル数が増加した場合の課題 Amazon S3 Amazon Athena 30 30 30 30 30
30 SELECT col_A From table WHERE col_A = 30 AND yyyy = 2025; Amazon S3 30 30 30 30 ↑2025 年↑ ↑2024 年↑ ↑2023 年↑ 30 Amazon Athena で json、Parquet、Iceberg のデータを検索し、性能比較してみた 2025/10/28 14
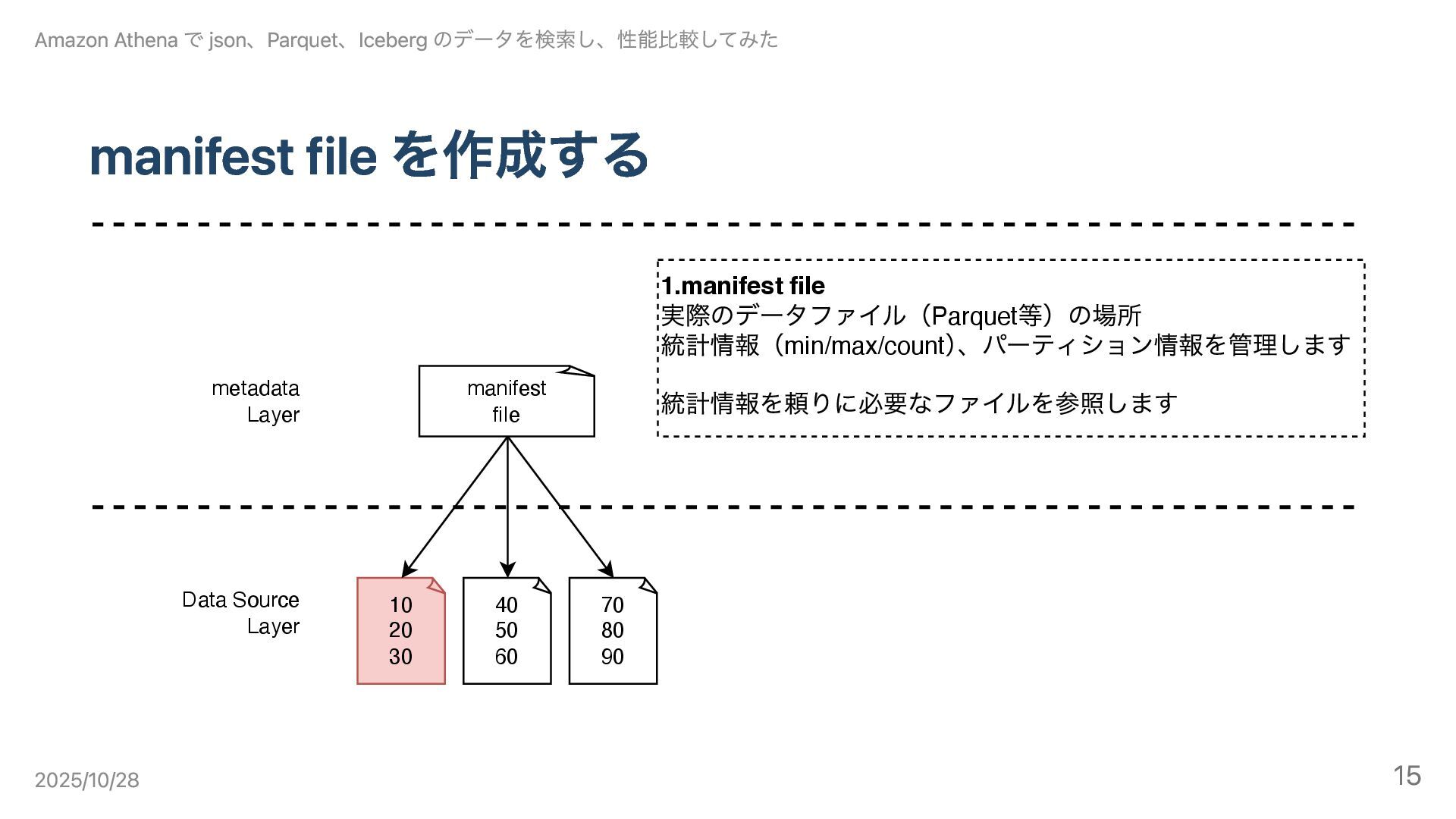
manifest file を作成する 10 20 30 40 50 60 70
80 90 Data Source Layer metadata Layer manifest file 1.manifest file 実際のデータファイル(Parquet 等)の場所 統計情報(min/max/count ) 、パーティション情報を管理します 統計情報を頼りに必要なファイルを参照します Amazon Athena で json、Parquet、Iceberg のデータを検索し、性能比較してみた 2025/10/28 15
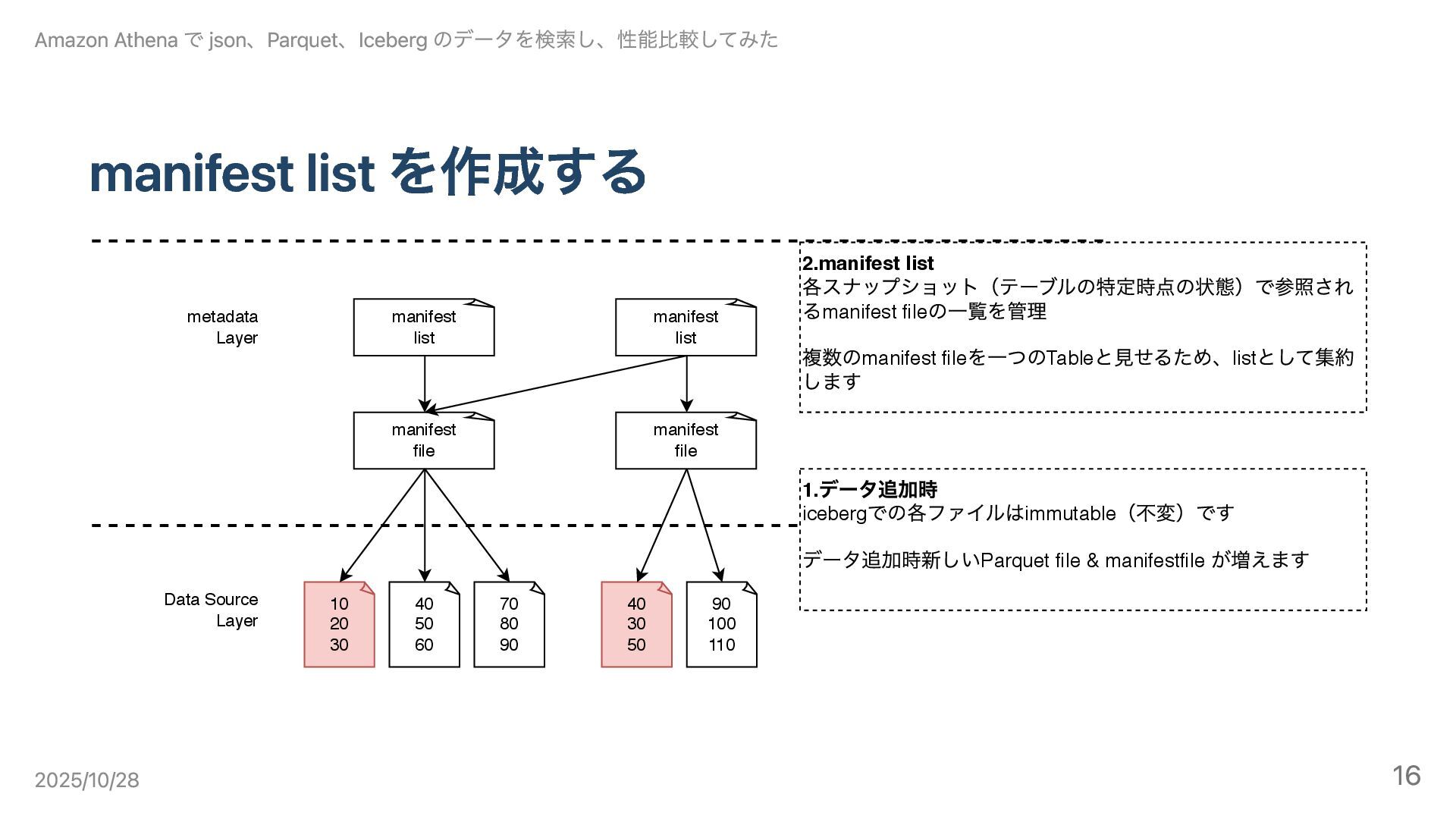
manifest list を作成する 10 20 30 40 50 60 70
80 90 Data Source Layer metadata Layer manifest file manifest file 40 30 50 90 100 110 1. データ追加時 iceberg での各ファイルはimmutable (不変)です データ追加時新しいParquet file & manifestfile が増えます manifest list 2.manifest list 各スナップショット(テーブルの特定時点の状態)で参照され るmanifest file の⼀覧を管理 複数のmanifest file を⼀つのTable と⾒せるため、list として集約 します manifest list Amazon Athena で json、Parquet、Iceberg のデータを検索し、性能比較してみた 2025/10/28 16
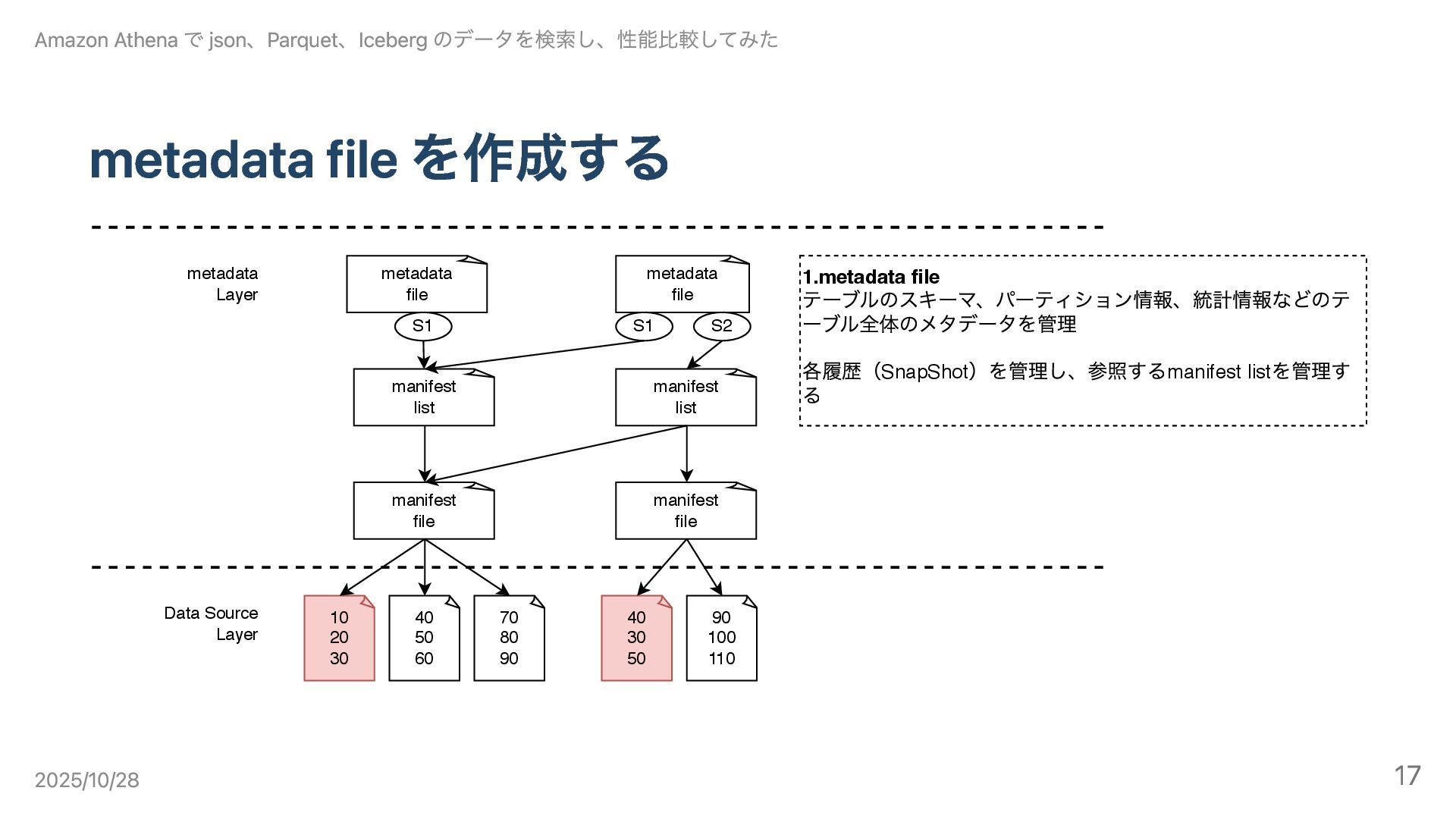
metadata file を作成する 10 20 30 40 50 60 70
80 90 Data Source Layer metadata Layer manifest file manifest file 40 30 50 90 100 110 manifest list 1.metadata file テーブルのスキーマ、パーティション情報、統計情報などのテ ーブル全体のメタデータを管理 各履歴(SnapShot )を管理し、参照するmanifest list を管理す る manifest list metadata file S1 metadata file S1 S2 Amazon Athena で json、Parquet、Iceberg のデータを検索し、性能比較してみた 2025/10/28 17
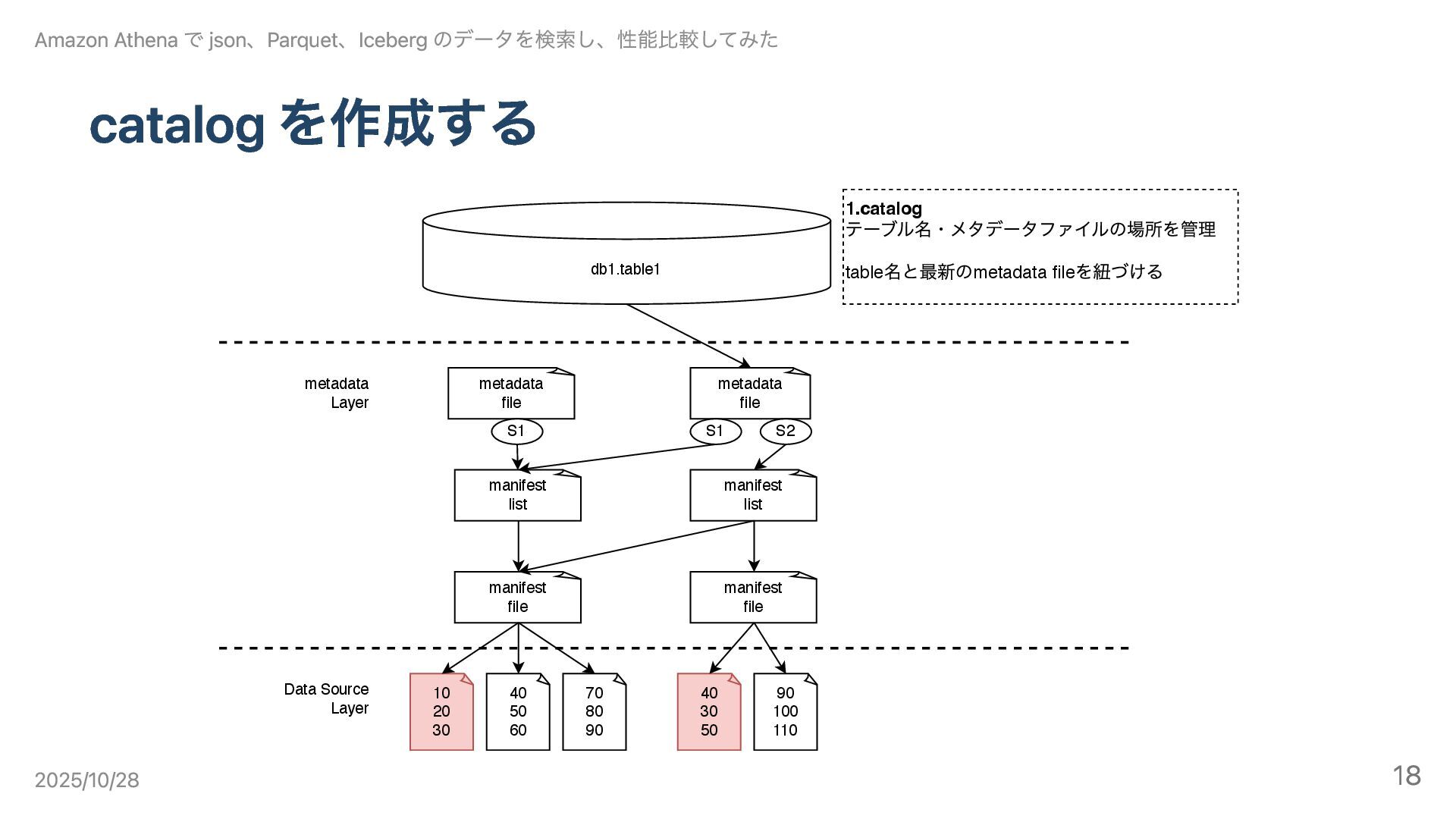
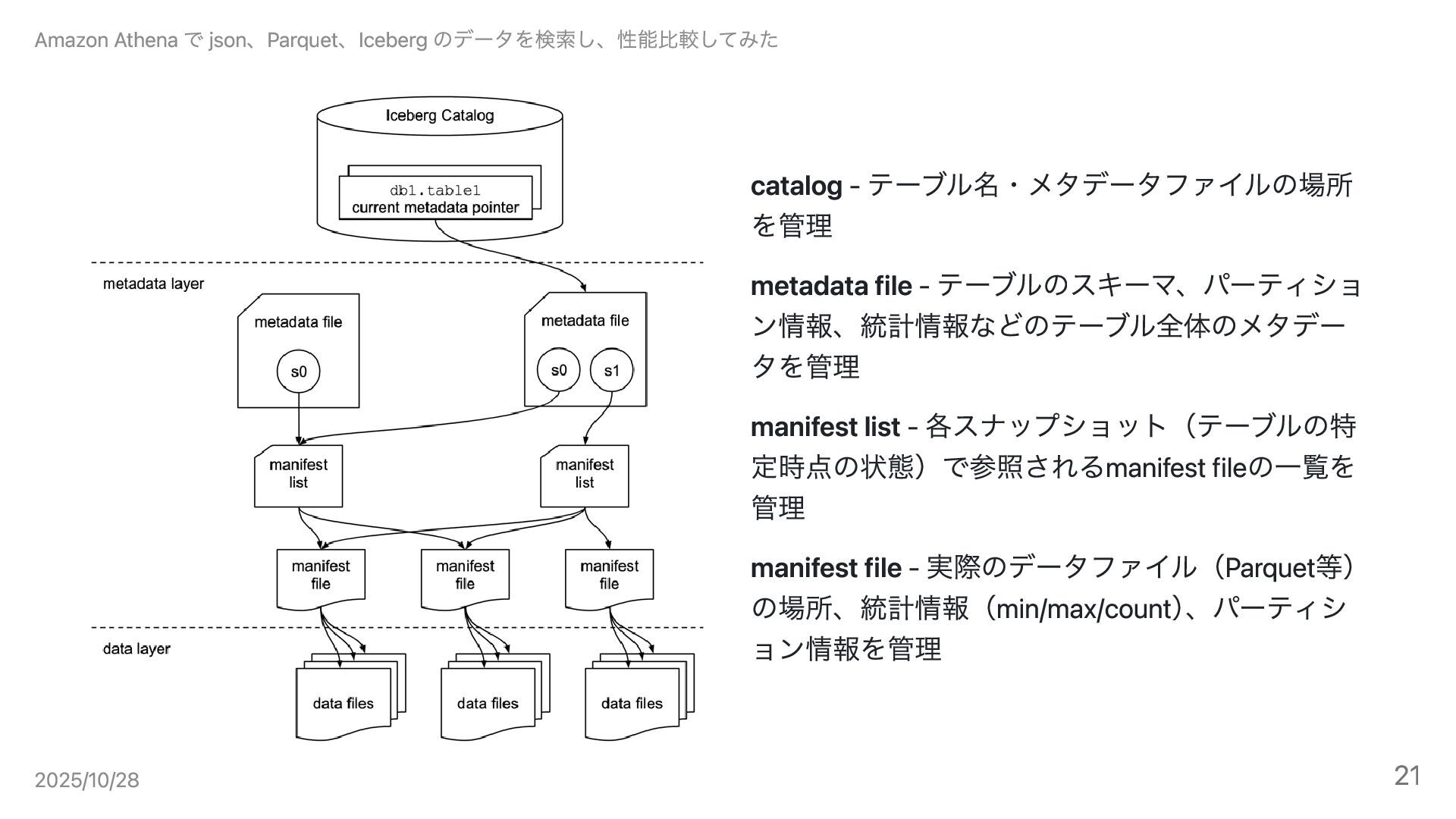
catalog を作成する 10 20 30 40 50 60 70 80
90 Data Source Layer metadata Layer manifest file manifest file 40 30 50 90 100 110 manifest list 1.catalog テーブル名・メタデータファイルの場所を管理 table 名と最新のmetadata file を紐づける manifest list metadata file S1 metadata file S1 S2 db1.table1 Amazon Athena で json、Parquet、Iceberg のデータを検索し、性能比較してみた 2025/10/28 18
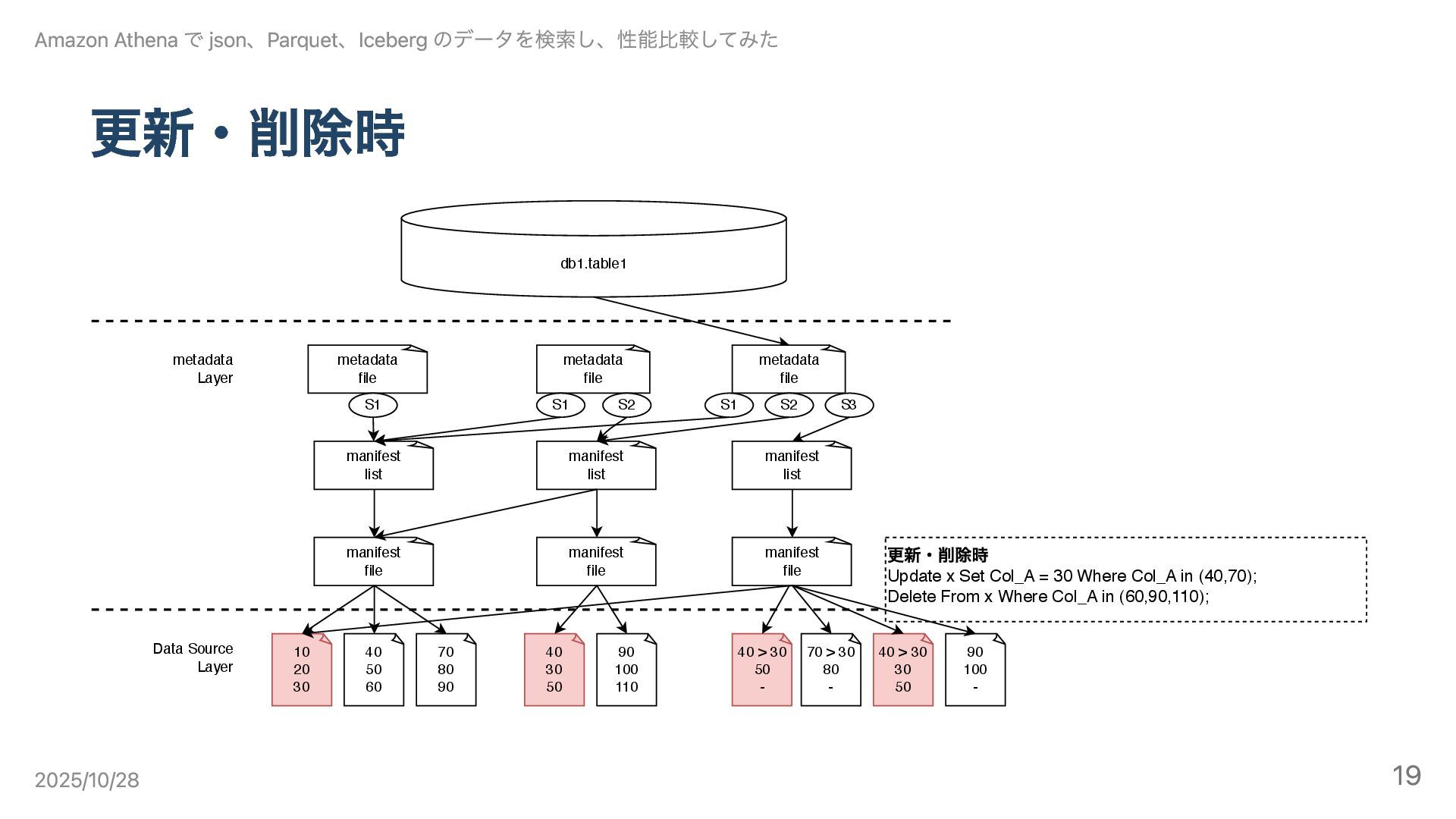
更新・削除時 10 20 30 40 50 60 70 80 90
Data Source Layer metadata Layer manifest file manifest file 40 30 50 90 100 110 manifest list manifest list metadata file S1 metadata file S1 S2 db1.table1 metadata file S1 S2 S3 manifest list manifest file 更新・削除時 Update x Set Col_A = 30 Where Col_A in (40,70); Delete From x Where Col_A in (60,90,110); 40 > 30 50 - 70 > 30 80 - 40 > 30 30 50 90 100 - Amazon Athena で json、Parquet、Iceberg のデータを検索し、性能比較してみた 2025/10/28 19
断片化・再ソート対策 AWS Glue データカタログが Apache Iceberg テーブルの自動コンパクションをサポ ートするようになった 新機能: sort
コンパクションと z-order コンパクションで Amazon S3 内での Apache Iceberg クエリパフォーマンスを向上 Amazon Athena で json、Parquet、Iceberg のデータを検索し、性能比較してみた 2025/10/28 20
catalog - テーブル名・メタデータファイルの場所 を管理 metadata file - テーブルのスキーマ、パーティショ ン情報、統計情報などのテーブル全体のメタデー タを管理
manifest list - 各スナップショット(テーブルの特 定時点の状態)で参照されるmanifest fileの一覧を 管理 manifest file - 実際のデータファイル(Parquet等) の場所、統計情報(min/max/count) 、パーティシ ョン情報を管理 Amazon Athena で json、Parquet、Iceberg のデータを検索し、性能比較してみた 2025/10/28 21
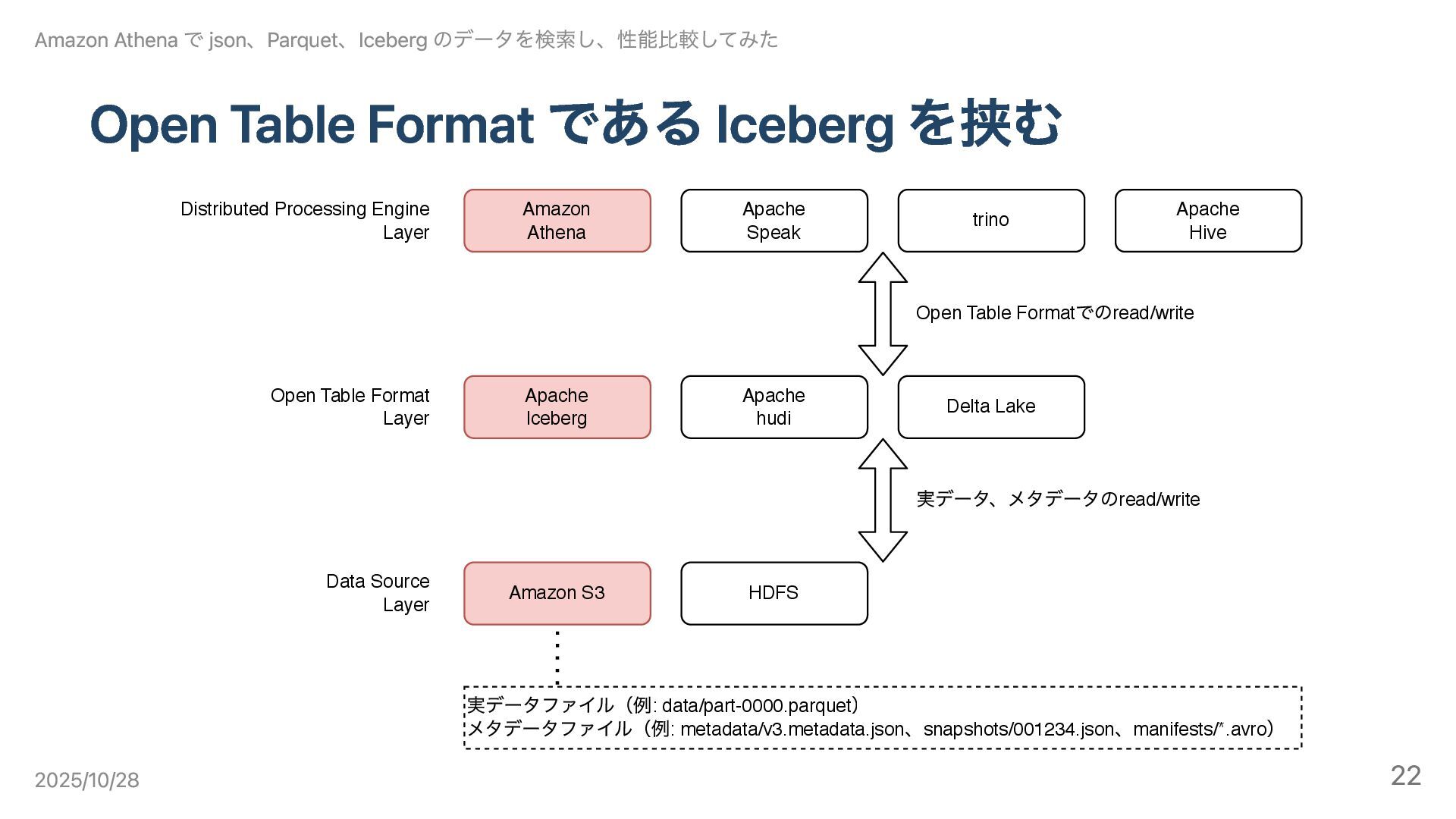
Open Table Format である Iceberg を挟む Distributed Processing Engine Layer
Open Table Format Layer Data Source Layer Amazon S3 Apache Iceberg Amazon Athena HDFS Apache hudi Delta Lake Apache Speak trino Apache Hive 実データファイル(例: data/part-0000.parquet ) メタデータファイル(例: metadata/v3.metadata.json 、snapshots/001234.json 、manifests/*.avro ) 実データ、メタデータのread/write Open Table Format でのread/write Amazon Athena で json、Parquet、Iceberg のデータを検索し、性能比較してみた 2025/10/28 22
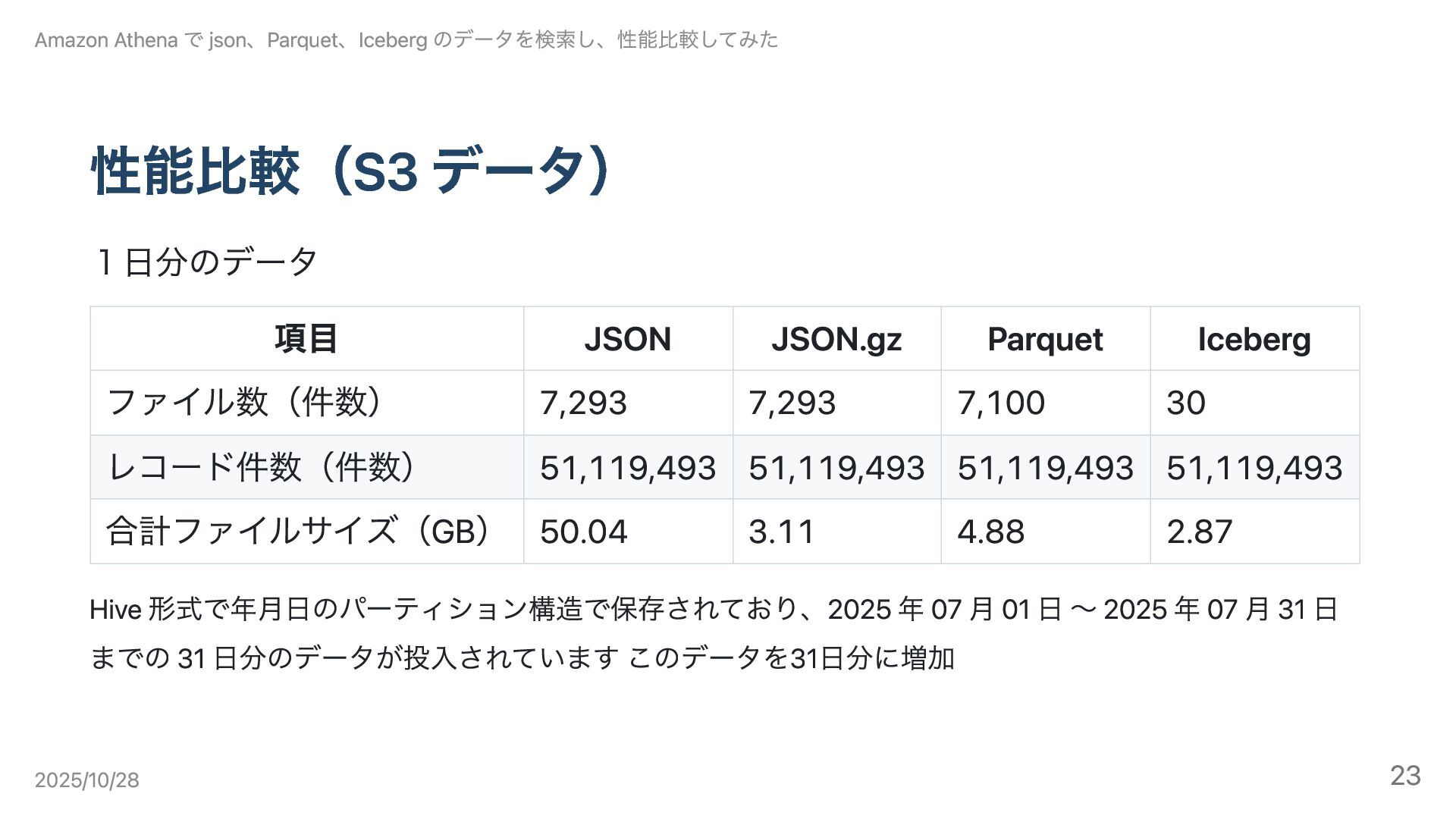
性能比較(S3 データ) 1日分のデータ 項目 JSON JSON.gz Parquet Iceberg ファイル数(件数) 7,293
7,293 7,100 30 レコード件数(件数) 51,119,493 51,119,493 51,119,493 51,119,493 合計ファイルサイズ(GB) 50.04 3.11 4.88 2.87 Hive 形式で年月日のパーティション構造で保存されており、2025 年 07 月 01 日 〜 2025 年 07 月 31 日 までの 31 日分のデータが投入されています このデータを31日分に増加 Amazon Athena で json、Parquet、Iceberg のデータを検索し、性能比較してみた 2025/10/28 23
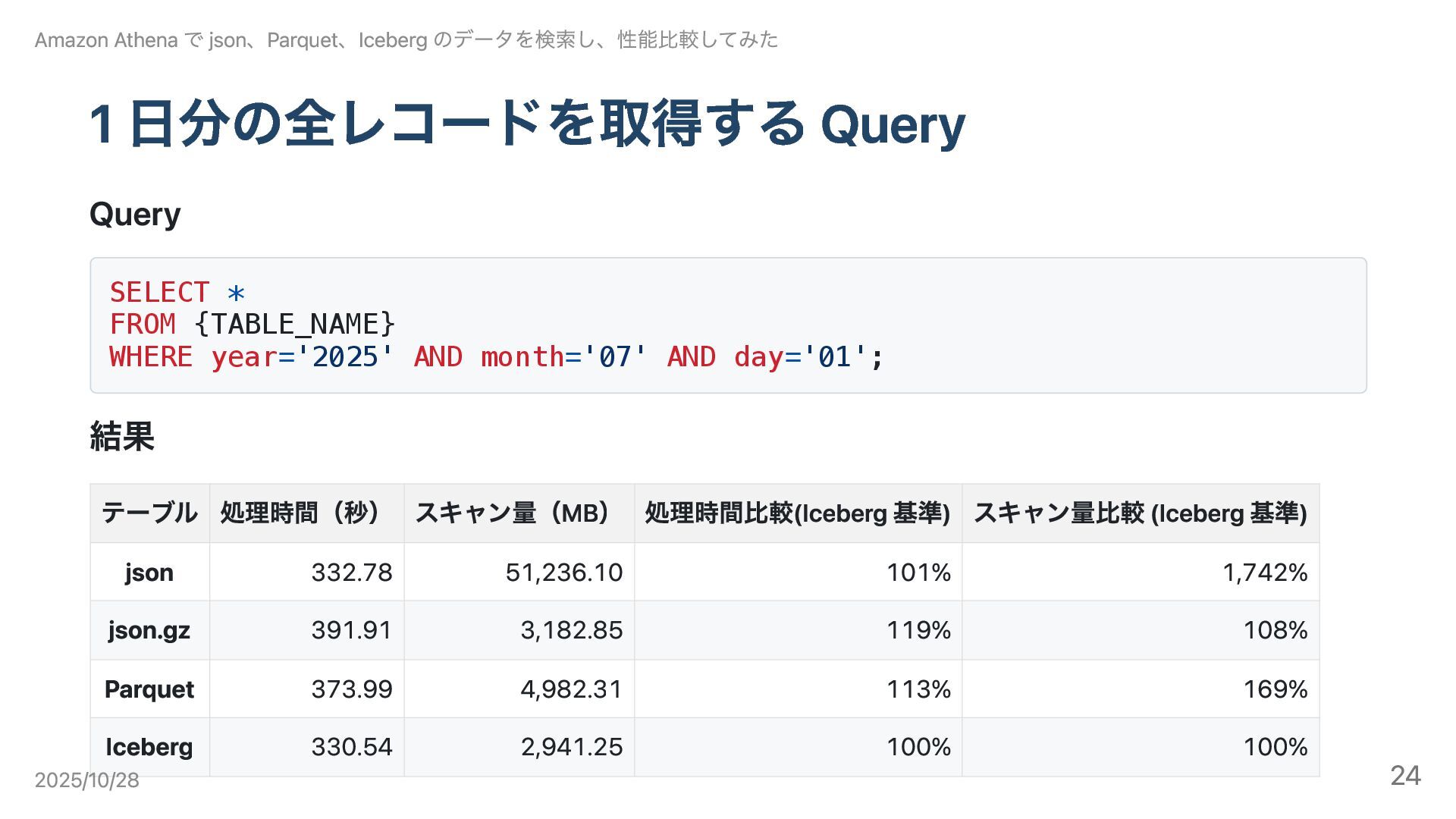
1 日分の全レコードを取得する Query Query SELECT * FROM {TABLE_NAME} WHERE year='2025'
AND month='07' AND day='01'; 結果 Amazon Athena で json、Parquet、Iceberg のデータを検索し、性能比較してみた テーブル 処理時間(秒) スキャン量(MB) 処理時間比較(Iceberg 基準) スキャン量比較 (Iceberg 基準) json 332.78 51,236.10 101% 1,742% json.gz 391.91 3,182.85 119% 108% Parquet 373.99 4,982.31 113% 169% Iceberg 330.54 2,941.25 100% 100% 2025/10/28 24
結論 このクエリでは各形式間の差は小さく、主に圧縮方式とファイル数の違いが効く。 各データ形式の特徴 json: スキャン量が最大で処理効率が最も低い。 json.gz: 圧縮でスキャン量は削減されるが、非スプリッタブル圧縮により並列度が低下、CPU 負荷も増 えるため処理時間は長い。 Parquet:
列指向圧縮で効率的。ただし小さいファイルが多数生成されやすく、open/close オーバーヘッ ドやメタデータ処理が増える傾向。 Iceberg: 内部は Parquet だが、コンパクションで適正サイズに再編成されるため、Parquet よりスキャン 量が小さく安定。 Amazon Athena で json、Parquet、Iceberg のデータを検索し、性能比較してみた 2025/10/28 25
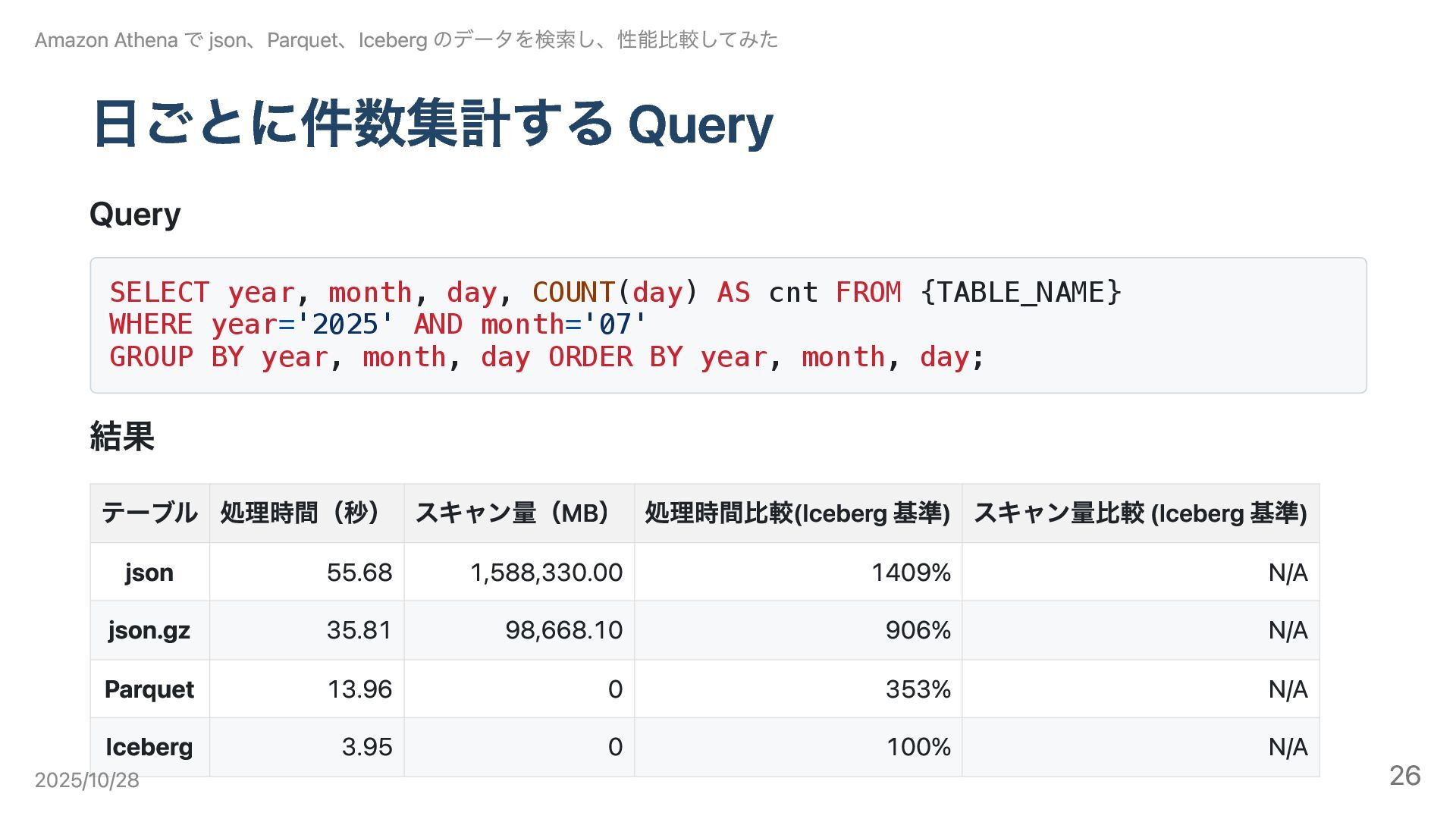
日ごとに件数集計する Query Query SELECT year, month, day, COUNT(day) AS cnt
FROM {TABLE_NAME} WHERE year='2025' AND month='07' GROUP BY year, month, day ORDER BY year, month, day; 結果 Amazon Athena で json、Parquet、Iceberg のデータを検索し、性能比較してみた テーブル 処理時間(秒) スキャン量(MB) 処理時間比較(Iceberg 基準) スキャン量比較 (Iceberg 基準) json 55.68 1,588,330.00 1409% N/A json.gz 35.81 98,668.10 906% N/A Parquet 13.96 0 353% N/A Iceberg 3.95 0 100% N/A 2025/10/28 26
結論 Iceberg のメタデータ最適化が最も効き、スキャン量ゼロで集計可能。 各データ形式の特徴 json: 行数統計が無いため全件走査。スキャン量・処理時間とも最大。 json.gz: 圧縮で転送量は削減されるが、全走査の必要があり CPU 負荷で遅い。
Parquet: 各ファイルのフッター統計で本体スキャンはゼロ。ただし多数のフッター参照が必要で Iceberg より遅い。 Iceberg: manifest/manifest list に統計が集約されており、最短時間で集計可能。 Amazon Athena で json、Parquet、Iceberg のデータを検索し、性能比較してみた 2025/10/28 27
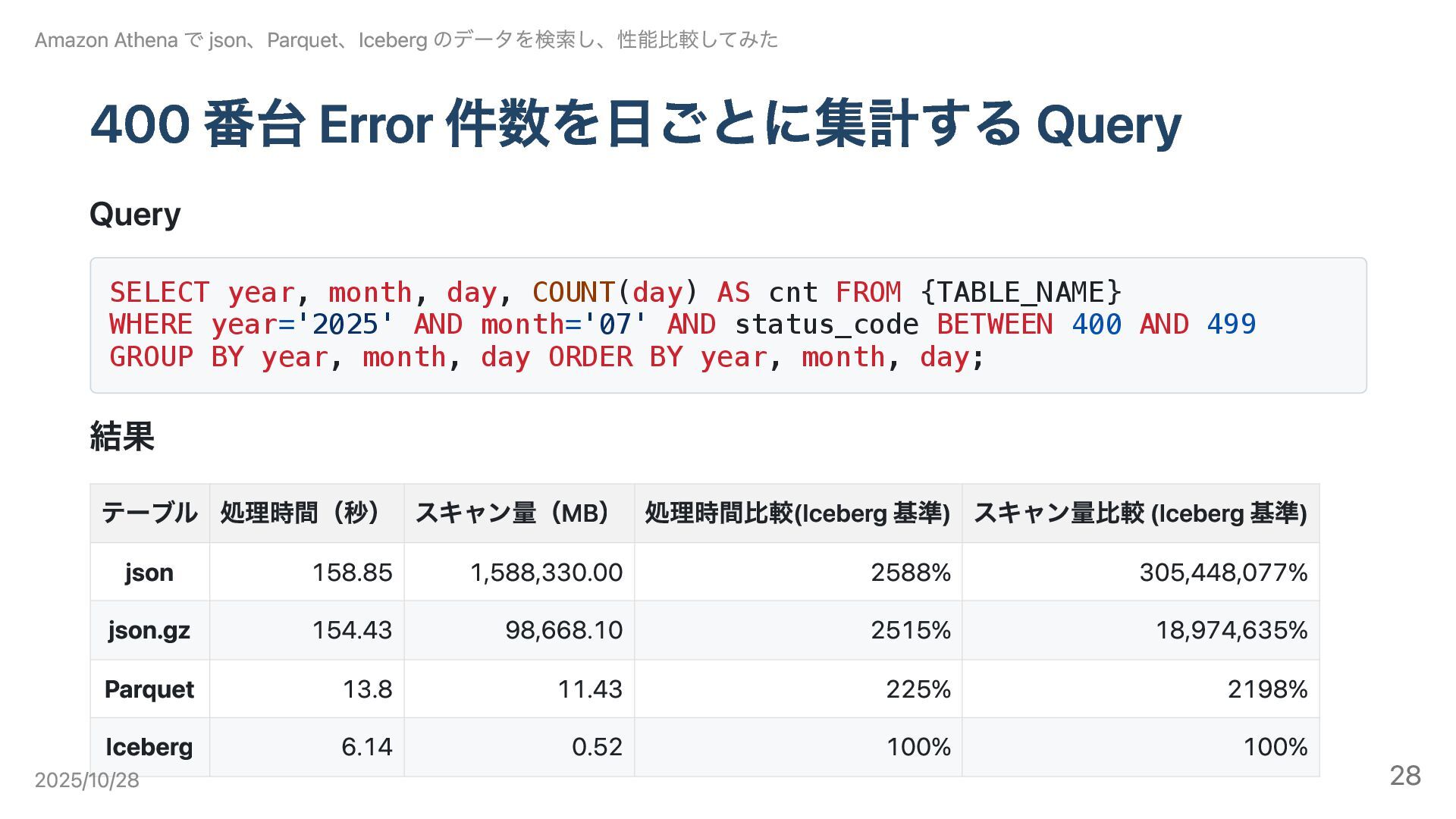
400 番台 Error 件数を日ごとに集計する Query Query SELECT year, month, day,
COUNT(day) AS cnt FROM {TABLE_NAME} WHERE year='2025' AND month='07' AND status_code BETWEEN 400 AND 499 GROUP BY year, month, day ORDER BY year, month, day; 結果 Amazon Athena で json、Parquet、Iceberg のデータを検索し、性能比較してみた テーブル 処理時間(秒) スキャン量(MB) 処理時間比較(Iceberg 基準) スキャン量比較 (Iceberg 基準) json 158.85 1,588,330.00 2588% 305,448,077% json.gz 154.43 98,668.10 2515% 18,974,635% Parquet 13.8 11.43 225% 2198% Iceberg 6.14 0.52 100% 100% 2025/10/28 28
結論 Iceberg が最も効率的に不要ファイルを pruning でき、処理時間が最短。 各データ形式の特徴 json: 統計が無いため全件走査。スキャン量・処理時間とも最大。 json.gz: json
と同様に全件走査が必要。圧縮により転送量は減るが CPU 負荷で遅い。 Parquet: ファイルフッターの min/max により pruning は可能。ただし統計が分散しておりオーバーヘッ ドが残る。 Iceberg: manifest に集中管理された統計により高精度 pruning が可能。本体 I/O を最小化。 Amazon Athena で json、Parquet、Iceberg のデータを検索し、性能比較してみた 2025/10/28 29
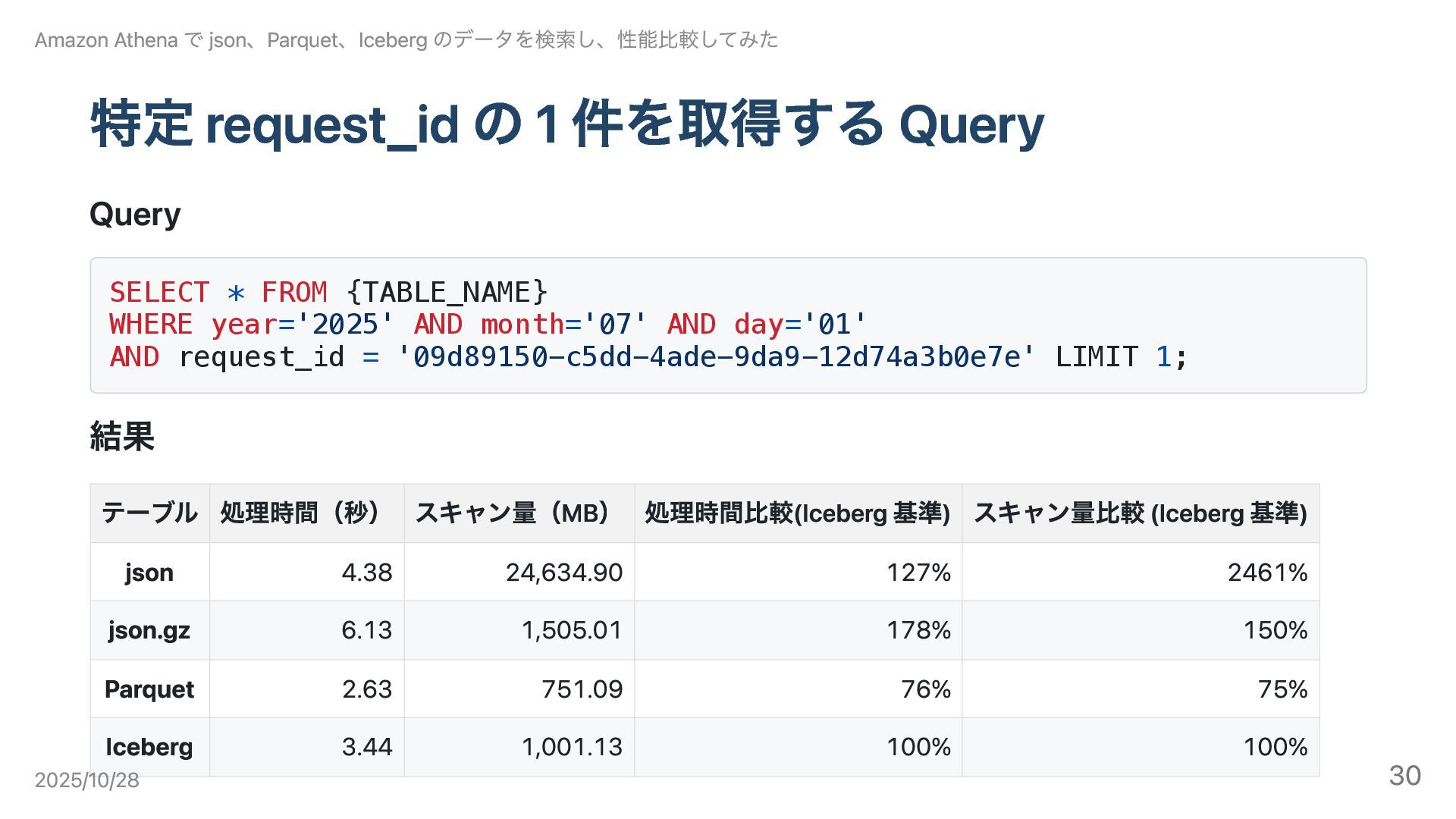
特定 request_id の 1 件を取得する Query Query SELECT * FROM
{TABLE_NAME} WHERE year='2025' AND month='07' AND day='01' AND request_id = '09d89150-c5dd-4ade-9da9-12d74a3b0e7e' LIMIT 1; 結果 Amazon Athena で json、Parquet、Iceberg のデータを検索し、性能比較してみた テーブル 処理時間(秒) スキャン量(MB) 処理時間比較(Iceberg 基準) スキャン量比較 (Iceberg 基準) json 4.38 24,634.90 127% 2461% json.gz 6.13 1,505.01 178% 150% Parquet 2.63 751.09 76% 75% Iceberg 3.44 1,001.13 100% 100% 2025/10/28 30
結論 Parquet の RowGroup 統計が効き最短、Iceberg はコンパクション影響でやや遅い。 各データ形式の特徴 json: 統計が無いため全件走査。 json.gz:
圧縮で転送量は減るが解凍 CPU がボトルネック。全走査が必要。 Parquet: RowGroup 単位の統計/ページスキップが効き、不要ブロックを避けられる。最短時間。 Iceberg: 内部は Parquet だが、コンパクションによりファイルが大きくなり、列統計だけでは十分に pruning できない場合がある。 Amazon Athena で json、Parquet、Iceberg のデータを検索し、性能比較してみた 2025/10/28 31
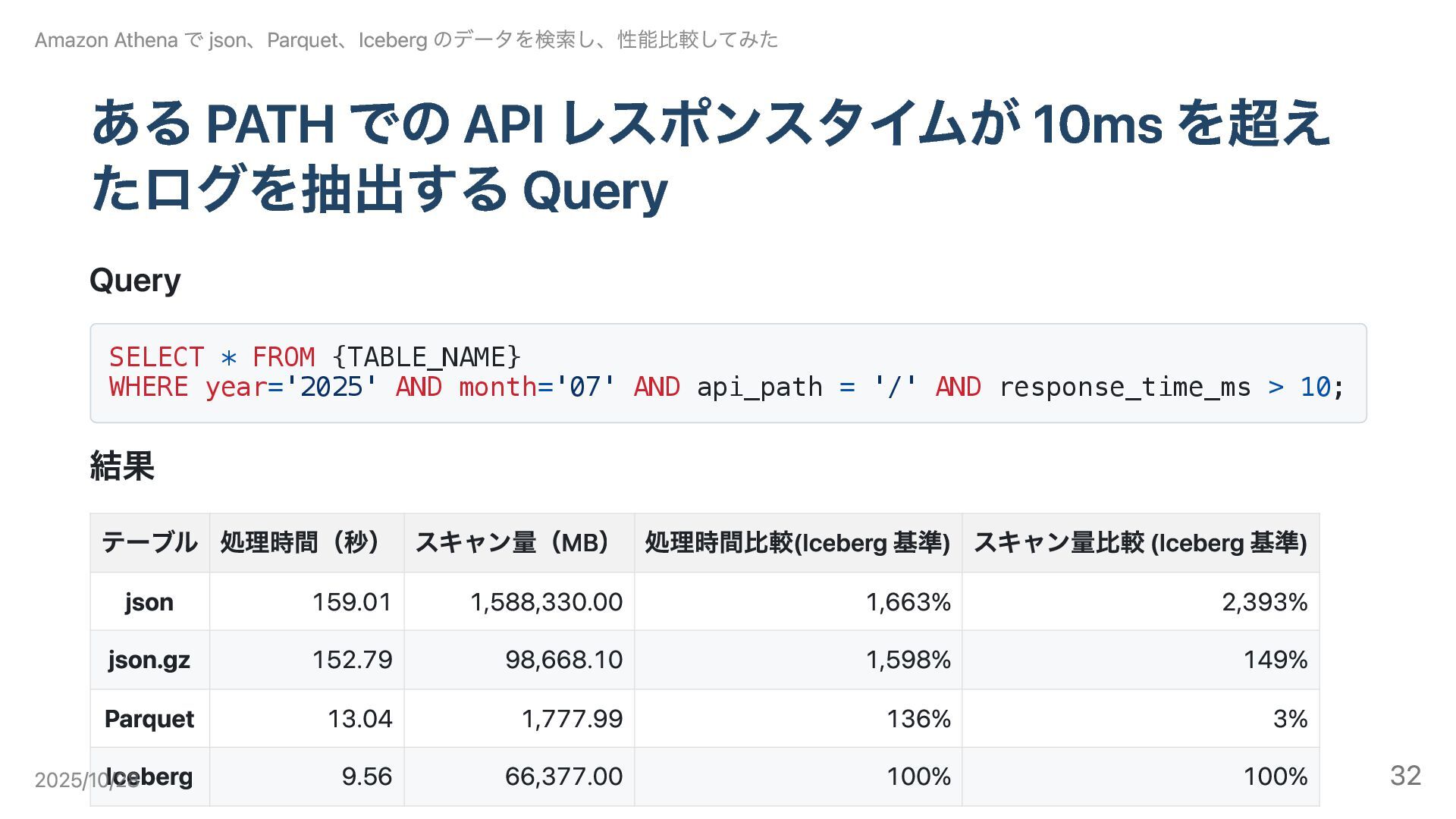
ある PATH での API レスポンスタイムが 10ms を超え たログを抽出する Query Query
SELECT * FROM {TABLE_NAME} WHERE year='2025' AND month='07' AND api_path = '/' AND response_time_ms > 10; 結果 Amazon Athena で json、Parquet、Iceberg のデータを検索し、性能比較してみた テーブル 処理時間(秒) スキャン量(MB) 処理時間比較(Iceberg 基準) スキャン量比較 (Iceberg 基準) json 159.01 1,588,330.00 1,663% 2,393% json.gz 152.79 98,668.10 1,598% 149% Parquet 13.04 1,777.99 136% 3% Iceberg 9.56 66,377.00 100% 100% 2025/10/28 32
結論 Iceberg: 最短時間、Parquet が最小スキャン量。json 系は全件走査で非効率。 各データ形式の特徴 json: 統計を持たず全走査。スキャン量最大(1,588,330MB) 、処理時間も最長(159s) 。
json.gz: 転送量は減るが、非スプリッタブル圧縮と解凍 CPU がボトルネックで依然長時間(152s) 。 Parquet: 行グループ統計で api_path・response_time_ms 条件を pruning。列投影も効きスキャン量は最 小。ただし小ファイル多数のオーバーヘッドで Iceberg より遅い。 Iceberg: manifest による計画段階 pruning +コンパクションで大ファイル化。RowGroup 統計が効きづら い分スキャン量は大きいが、連続読み込みで帯域を活かし処理時間は最短。 Amazon Athena で json、Parquet、Iceberg のデータを検索し、性能比較してみた 2025/10/28 33
性能まとめ json: 最も非効率。全件走査となり処理時間・スキャン量が最大。 json.gz: ストレージ効率は良いが、非スプリッタブル圧縮と CPU 負荷でクエリ性 能は低い。 Parquet: 列指向で効率的。RowGroup
統計やページスキップが効くが、小ファイル 多数問題に弱い。 Iceberg: Parquet を基盤としつつ、manifest/metadata に統計を集約。メタデータ最 適化により集計系クエリで最速。コンパクションにより安定性も高い。 Amazon Athena で json、Parquet、Iceberg のデータを検索し、性能比較してみた 2025/10/28 34
最後に 巨大な S3 データを“テーブル”として扱い、更新もできる次世代のデータフォーマット である iceberg に興味を持って頂ければ幸いです。 もし XX で使えそうとかあれば教えて頂けますと幸いです。
Amazon Athena で json、Parquet、Iceberg のデータを検索し、性能比較してみた 2025/10/28 35
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}