collection of synthetic DNA probes attached to designated location, or spot, on a solid surface. The resulting "grid" of probes can hybridize to complementary "target" sequences derived from experimental samples to determine the expression level of specific mRNAs in a sample (http://bitesizebio.com/7206/introduction- to-dna-microarrays/) • Microarrays were a primary resource for differential expression analysis studies before the invention of RNA Sequencing ◦ The major problem with microarrays is that you have to know what you are looking for in these experiments, since you have to use probes that hybridize to known RNA reads - RNA Seq does not have this problem • However, there is a lot of free microarray data available for analysis online (on sites such as GEO and ArrayExpress) just waiting to be utilized, so it is important to know how to analyze such data for use in genetic differential expression analyses (ie. WGCNA) (http://bitesizebio.com/7206/introduction-to-dna-microarrays/)
– R is used to process the massive amounts of data acquired from microarray studies – This is the most efficient language in which to perform statistical analysis with microarray data • Helpful Introduction to R – http://rafalab.jhsph.edu/688/labs/lab1.pdf
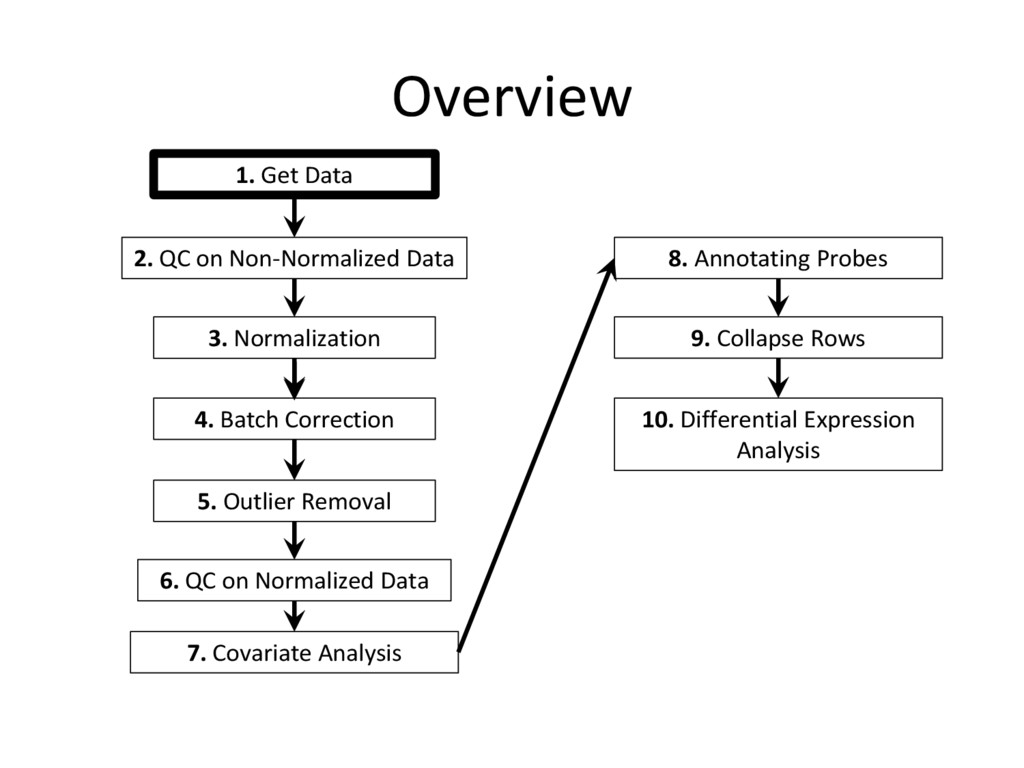
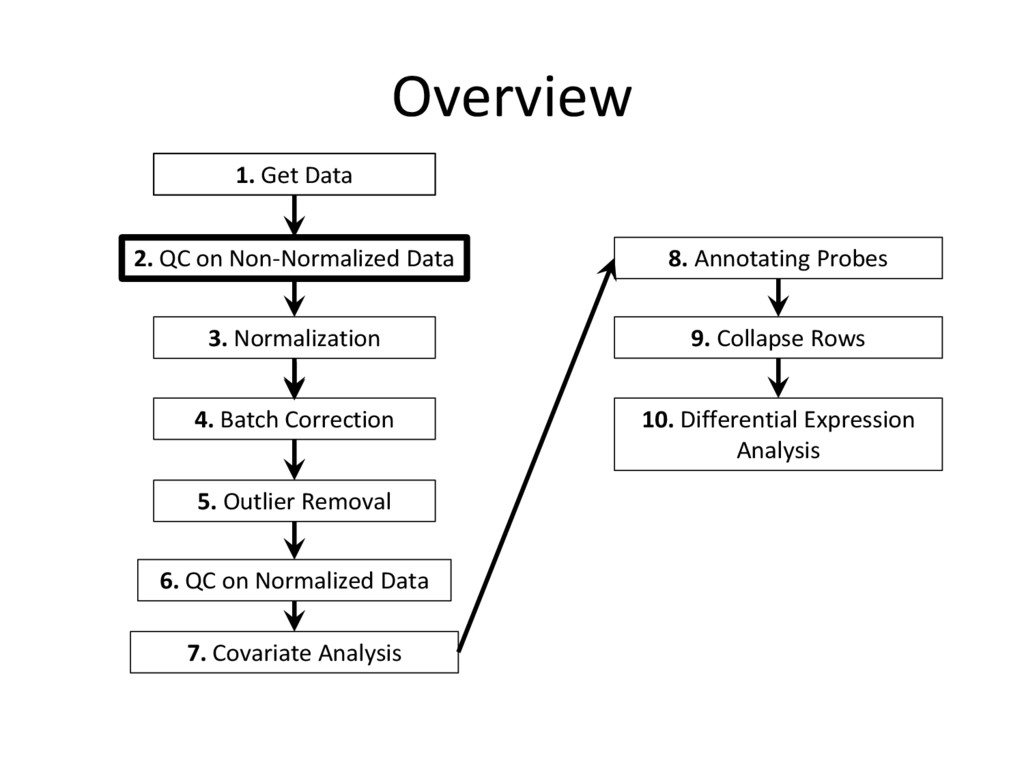
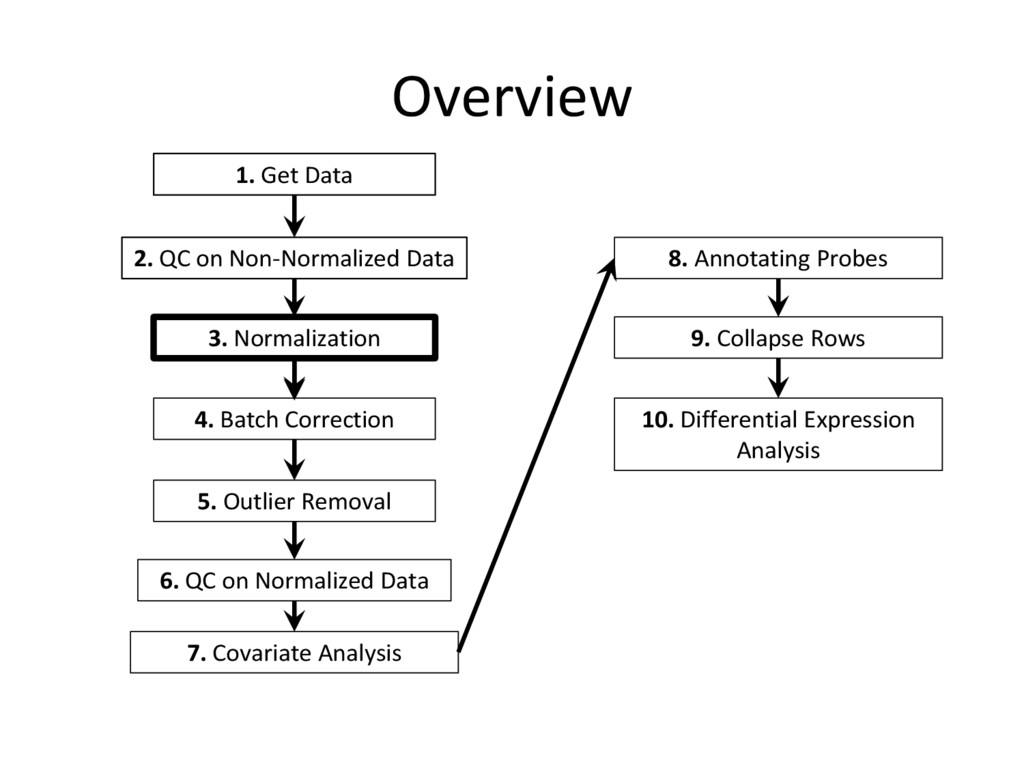
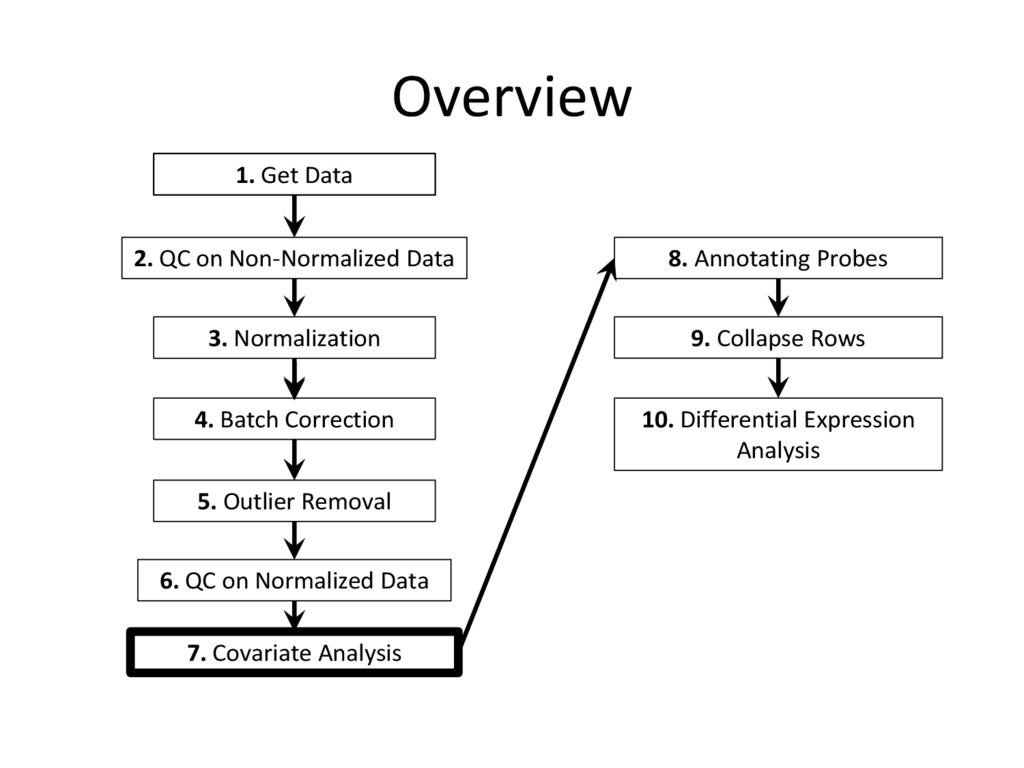
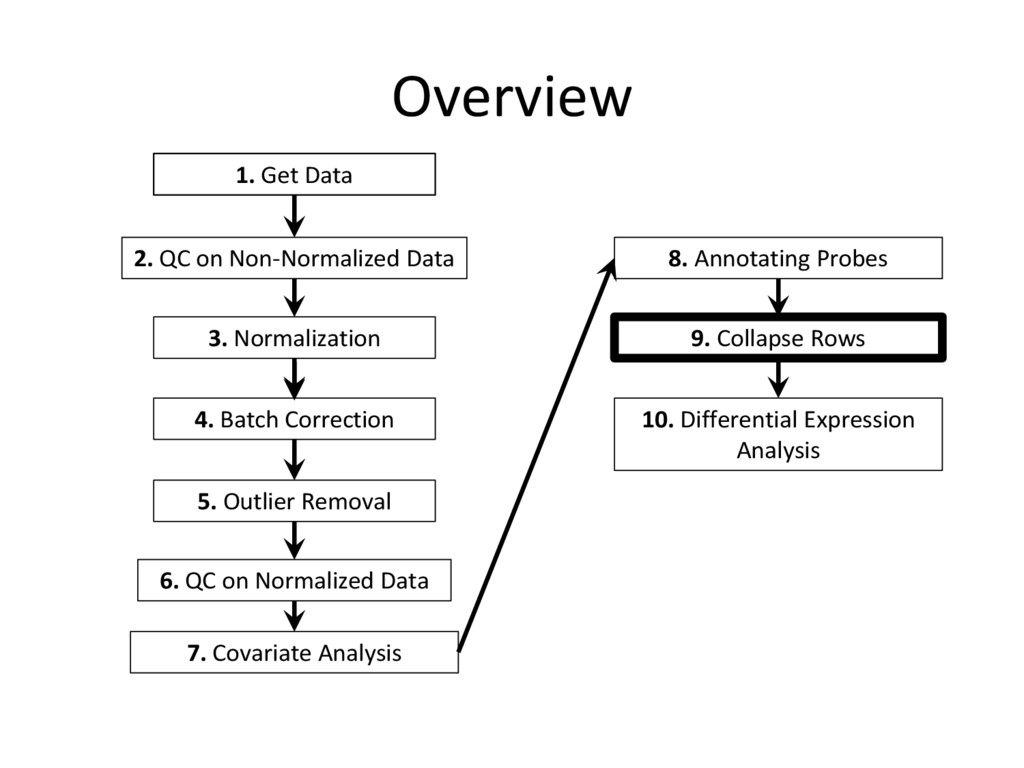
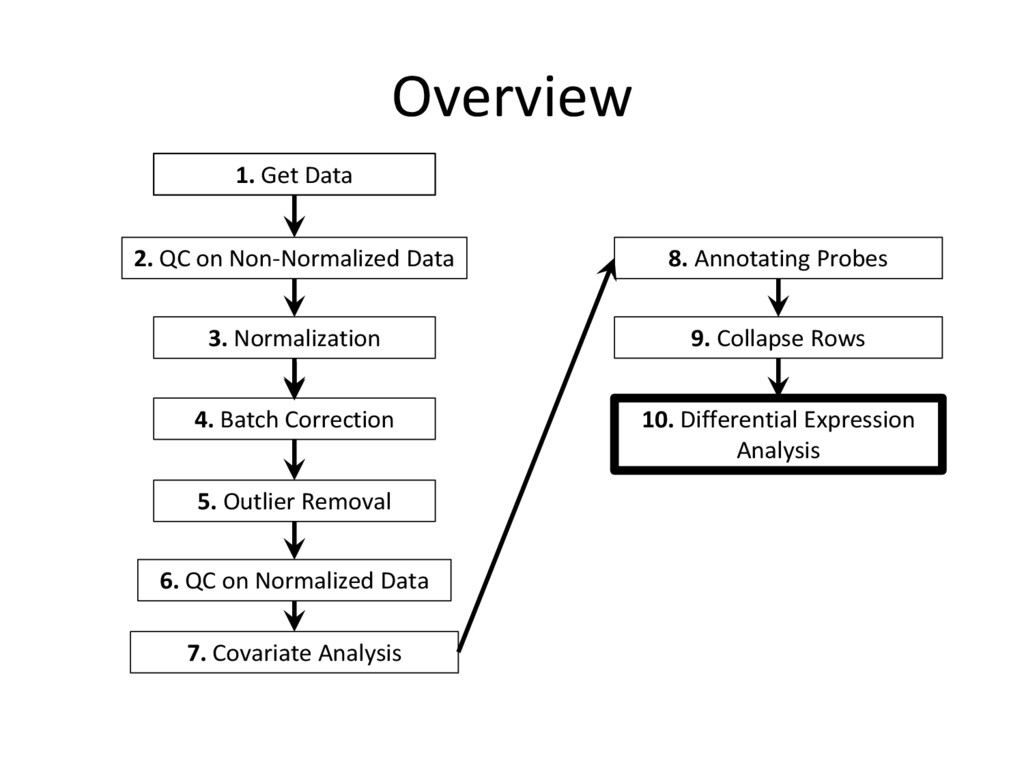
tutorial are needed for every microarray analysis (steps 8 and 9 are sometimes not required, if the data is given in terms of genes instead of probes), many of the specific instructions and code examples in this tutorial are geared towards affymetrix microarrays • For other platforms (illumina, nimblegen, etc.) you may need to find the relevant R commands to complete each step on your own – Google is an excellent resource for this! • Refer to the ‘Cleaning and Analyzing Raw Microarray Data for WGCNA’ document for specific code examples and more detailed explanations for all steps
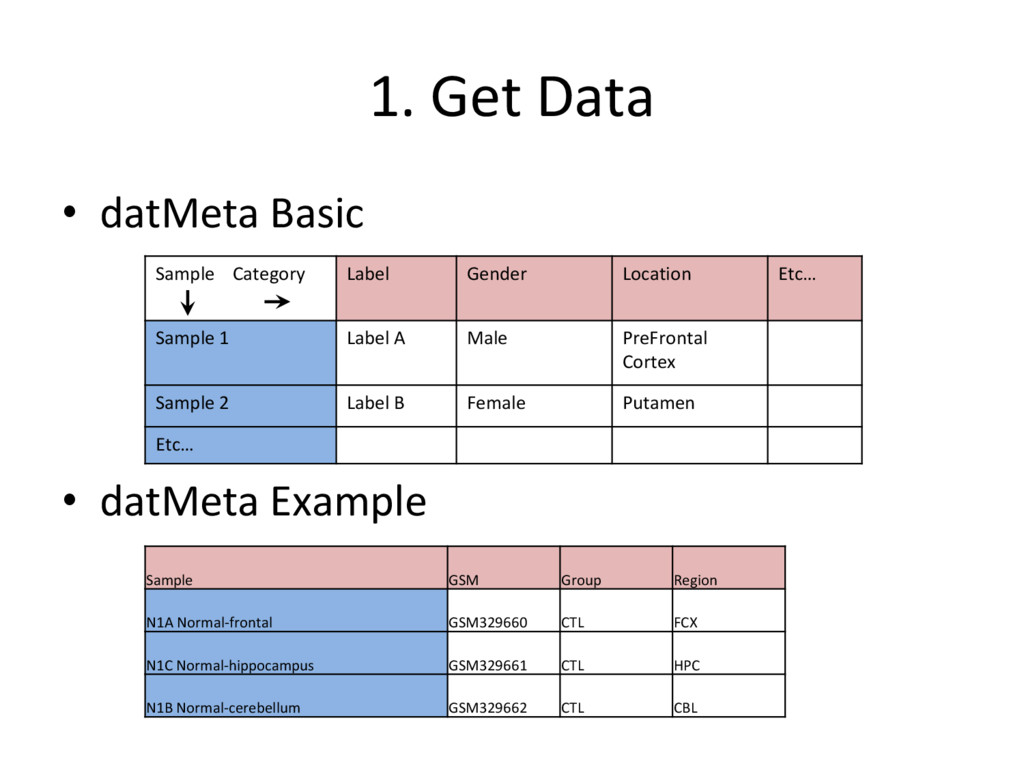
want to analyze – http://www.ncbi.nlm.nih.gov/geo/ – https://www.ebi.ac.uk/arrayexpress/ – Use a computer program such as 7-Zip to save microarray data as ‘.CEL’ files in a folder on your computer (for relevant microarrays, ie. affymetrix) • Create a datMeta excel spreadsheet with phenotypic data using obtained microarray data • For affymetrix arrays, Use “ReadAffy” function to extract – expression matrix (exprs) – phenotypic data (pData) – protocolData
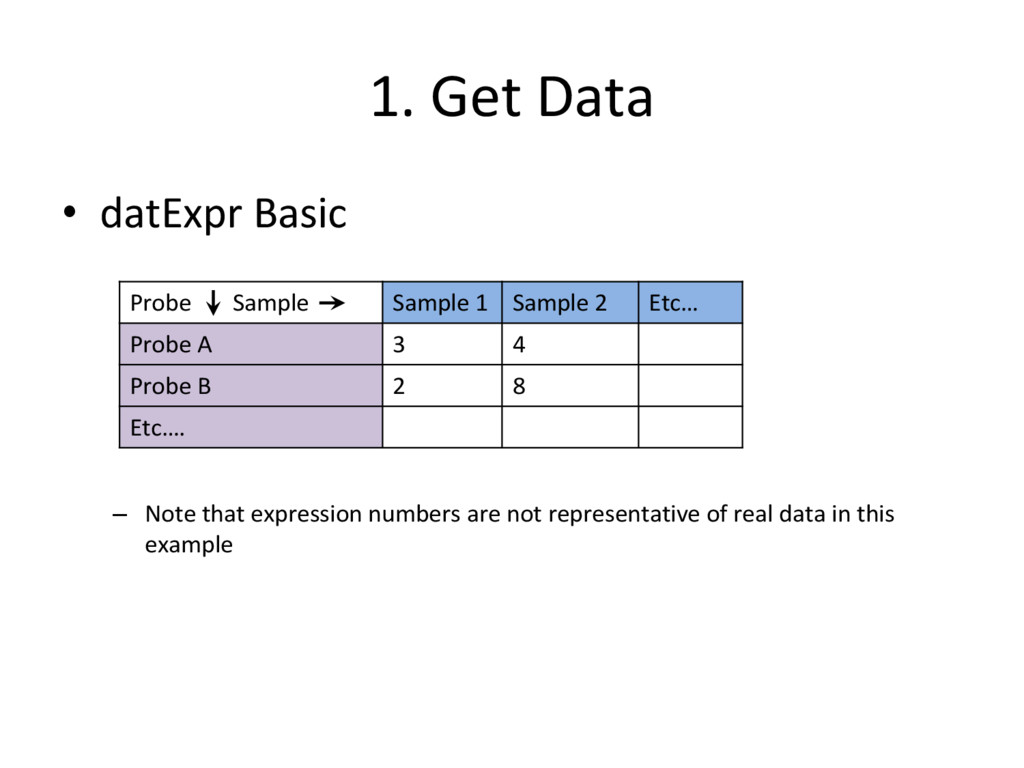
datasets to organize the microarray data – datMeta • To store ‘phenotypic’ data about each sample – datExpr • To store the expression of each probe (exprs) in the microarray for each sample • It is important to remember what the rows and columns represent in each dataset
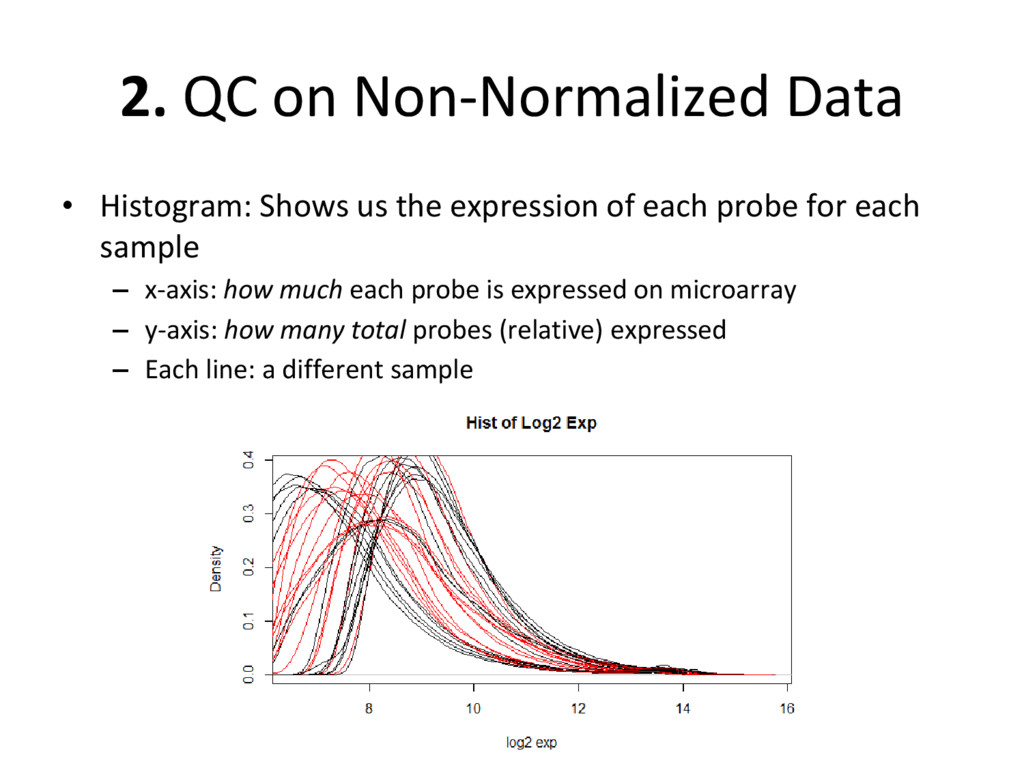
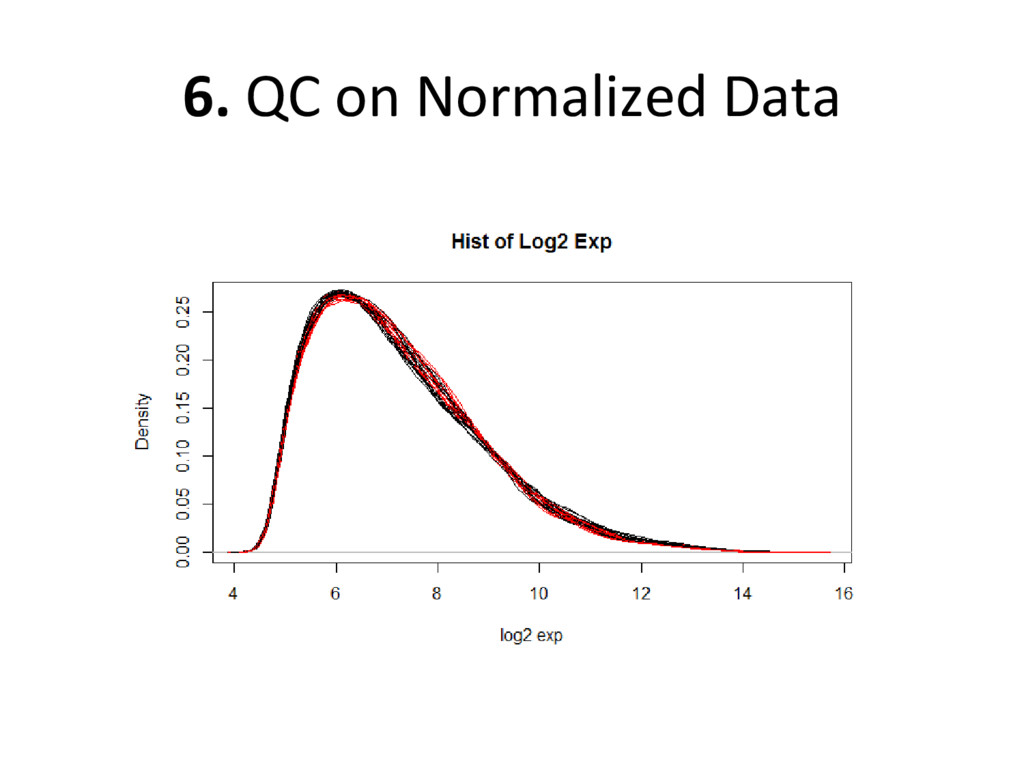
expression of each probe for each sample – x-axis: how much each probe is expressed on microarray – y-axis: how many total probes (relative) expressed – Each line: a different sample
that decreases the accuracy of our final data analysis • We identify these outliers with network connectivity based statistics, and then remove these outliers from the data
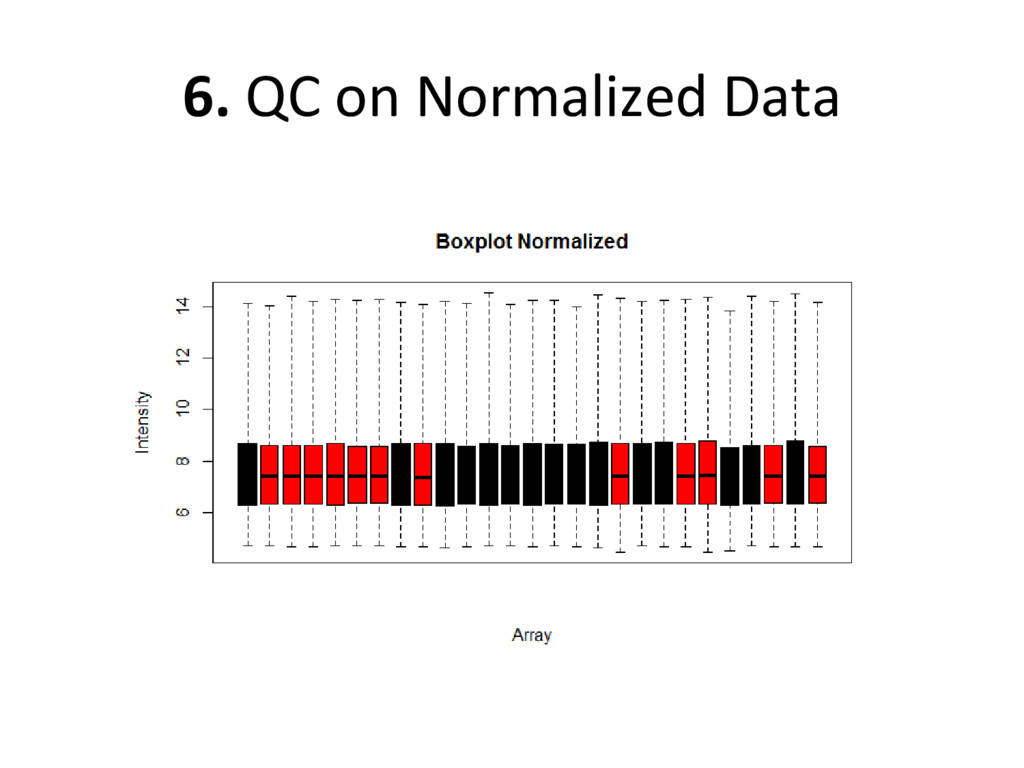
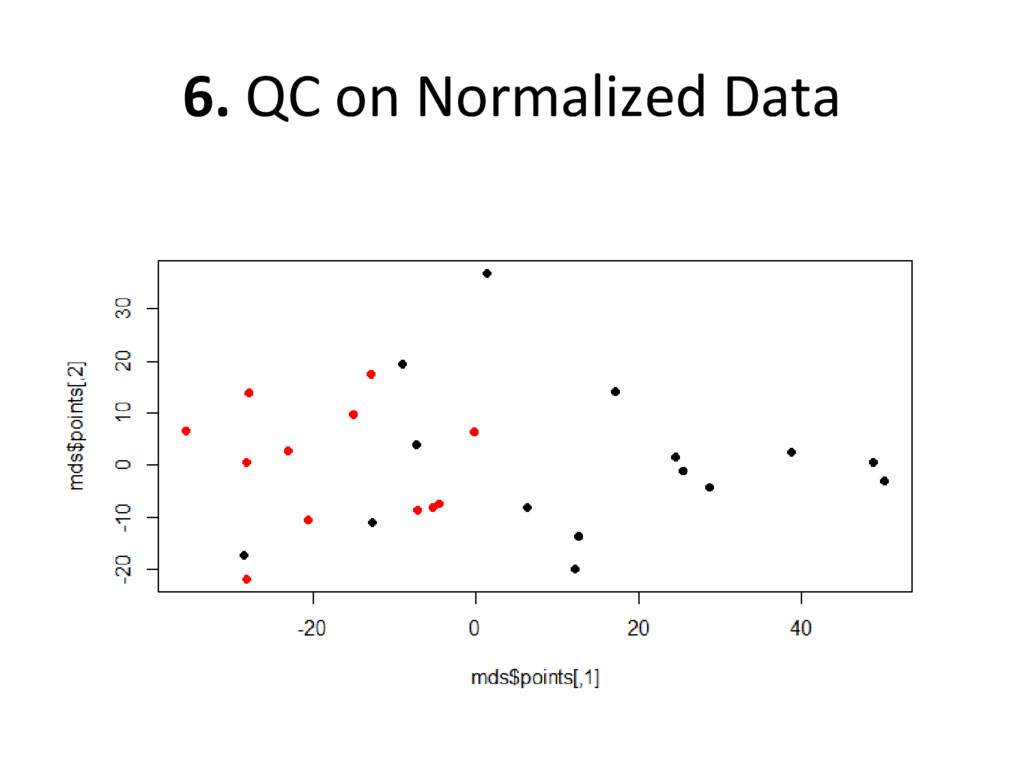
on normalized, batch corrected, and outlier removed data to see if we have accurately removed experimental error – Box plot: are the medians/means of the data about the same? – Histogram: do the lines overlap more strongly than before? – MDS plot: do control and diseased samples separate more from each other? • If you answered ‘yes’ to each of these, you have correctly removed error from your data
technical covariates are not confounded by group/disease state • We don’t want the other factors to be correlated • We want the p-value between disease state and factors such as age, gender, etc. to be greater than 0.05 • If this is not the case for one of your factors, then you need to remove the outlier data points within the problem factor from your data-set, as they introduce confounding error that is not controlled for in the experiment
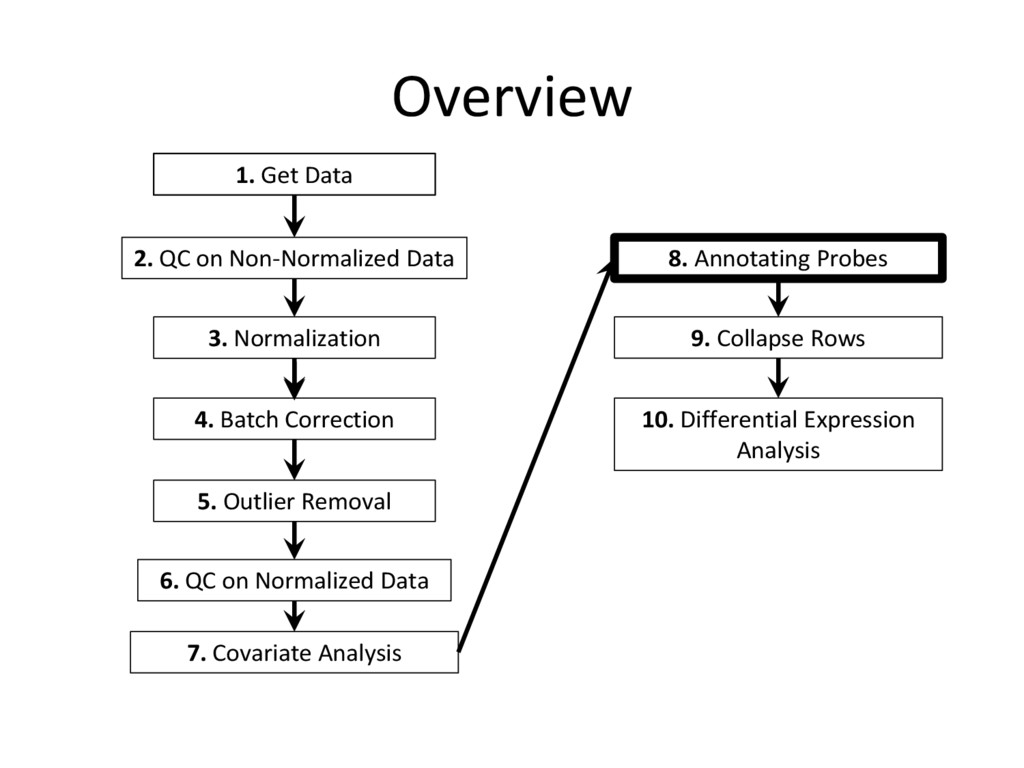
but we still need to determine which genes our microarray probes tagged, and then align this ‘geneDat’ with our ‘datExpr’ • We use bioMart to re-annotate probes with ensembl gene IDs based on the most recent species genome knowledge • Be sure that your geneDat and datExpr have the same probes in the same order before making the rownames of datExpr your gene IDs
step from our prior Normalization • We update the probe/gene matching data with the latest discoveries in genetics • We then re-order geneDat to match the new, collapsed ordering of datExpr
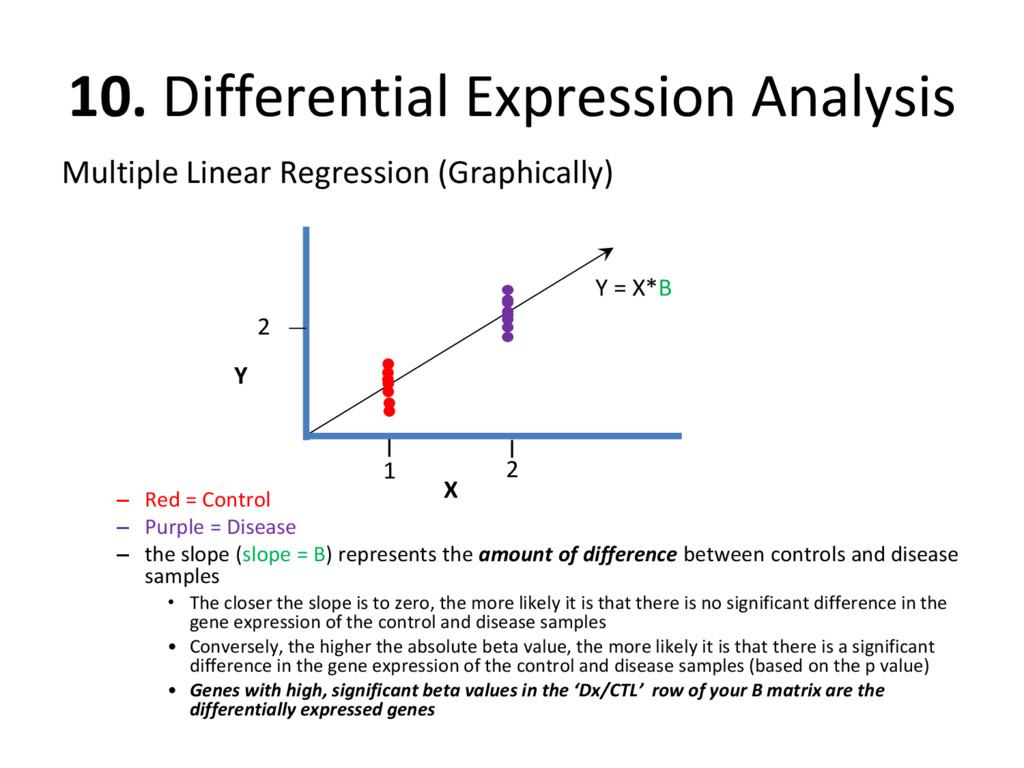
regression to determine how similar/different the gene expression of our disease samples is to the gene expression of our control samples • It is important to isolate the effect that disease status has on the expression of each gene, thus we create a ‘B’ matrix full of ‘beta values’ which isolates the effect that each datMeta trait has on the datExpr value for each gene across all samples Y = X*B + Error t(datExpr) = (model matrix)*(beta values) + Error
our ‘X’ values, or the numerical values of our datMeta – n samples, m traits for each sample, p probes – The model matrix is an (n x m) matrix – “String” variables are given the value ‘1’ or ‘0’ – The first column is made up of 1’s, to allow for the axis intercept term 1 X1,1 … X1,m 1 X2,1 … X2,m 1 X3,1 … X3,m … … … … 1 Xn,1 … Xn,m
B is a least squares approximation such that Y = X*B + error – n samples, m traits for each sample, p probes – Thus, B0 (the first row of B) is the intercept term – B is an (m x p) matrix B0,1 B0,2 … B0,p B1,1 B1,2 … X1,p B2,1 B2,2 … X2,p … … … … Bm,1 Bm,2 … Xm,p
= Control – Purple = Disease – the slope (slope = B) represents the amount of difference between controls and disease samples • The closer the slope is to zero, the more likely it is that there is no significant difference in the gene expression of the control and disease samples • Conversely, the higher the absolute beta value, the more likely it is that there is a significant difference in the gene expression of the control and disease samples (based on the p value) • Genes with high, significant beta values in the ‘Dx/CTL’ row of your B matrix are the differentially expressed genes Y X 2 Y = X*B 1 2
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}