all phases of hikes and other outdoor activities: discovery, planning, doing, and sharing. • 2m+ monthly users • Unusual traffic pattern (weekend and holidays) • Small engineering team - multiple roles On weekends and holidays we can see up to 10x of our baseline traffic.
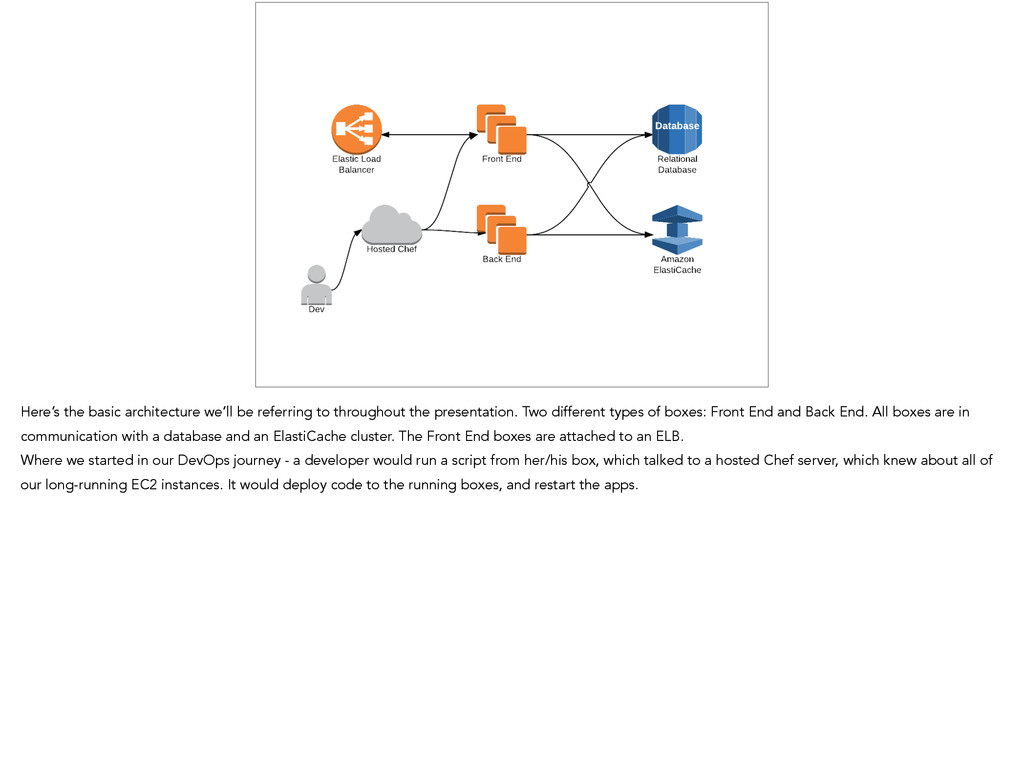
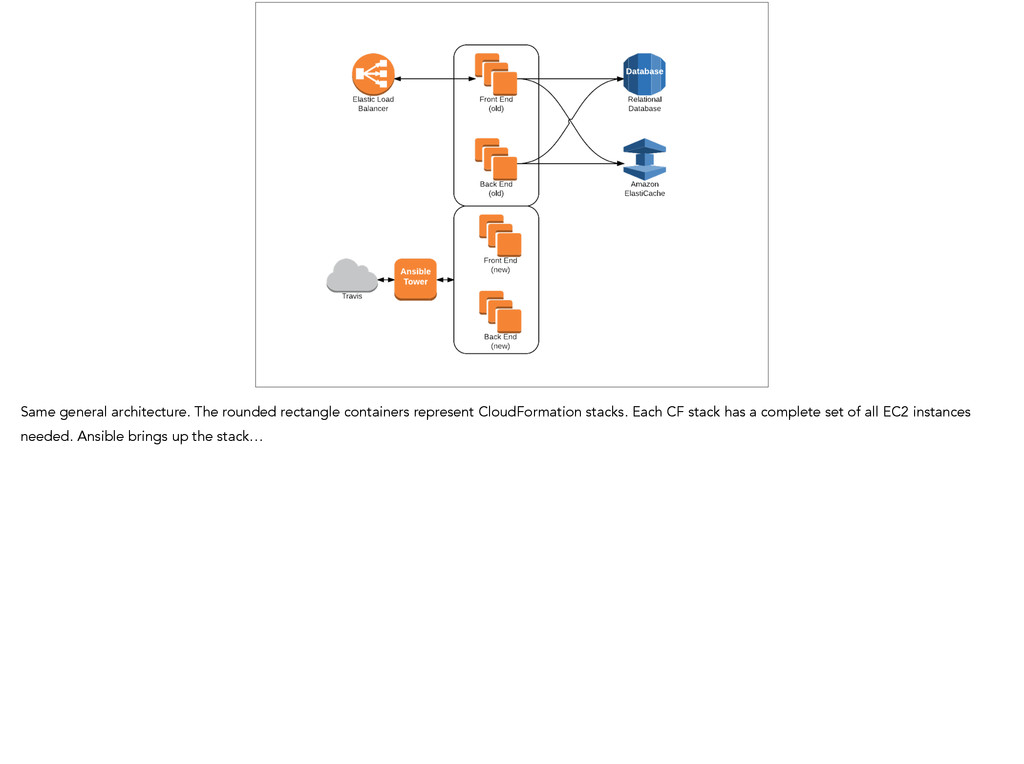
presentation. Two different types of boxes: Front End and Back End. All boxes are in communication with a database and an ElastiCache cluster. The Front End boxes are attached to an ELB. Where we started in our DevOps journey - a developer would run a script from her/his box, which talked to a hosted Chef server, which knew about all of our long-running EC2 instances. It would deploy code to the running boxes, and restart the apps.
• Way over-provisioned • Except when it wasn’t 1. No need for manual deploys - use CI/CD as a layer of abstraction. Devs write code, they see code. 2. Many of you have encountered - things go wrong, weird state. Some boxes have new version, some have old, some incomplete? A mess. 3. And with just a set fleet of instances, we had to over-provision in order to handle our peak traffic.
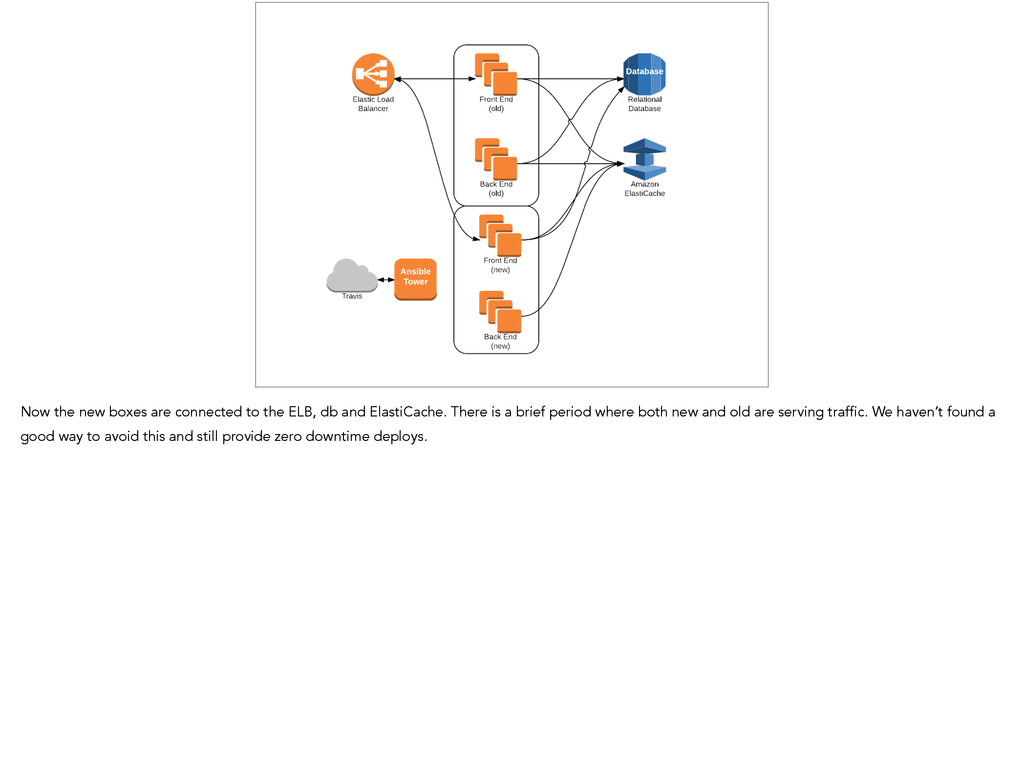
and ElastiCache. There is a brief period where both new and old are serving traffic. We haven’t found a good way to avoid this and still provide zero downtime deploys.
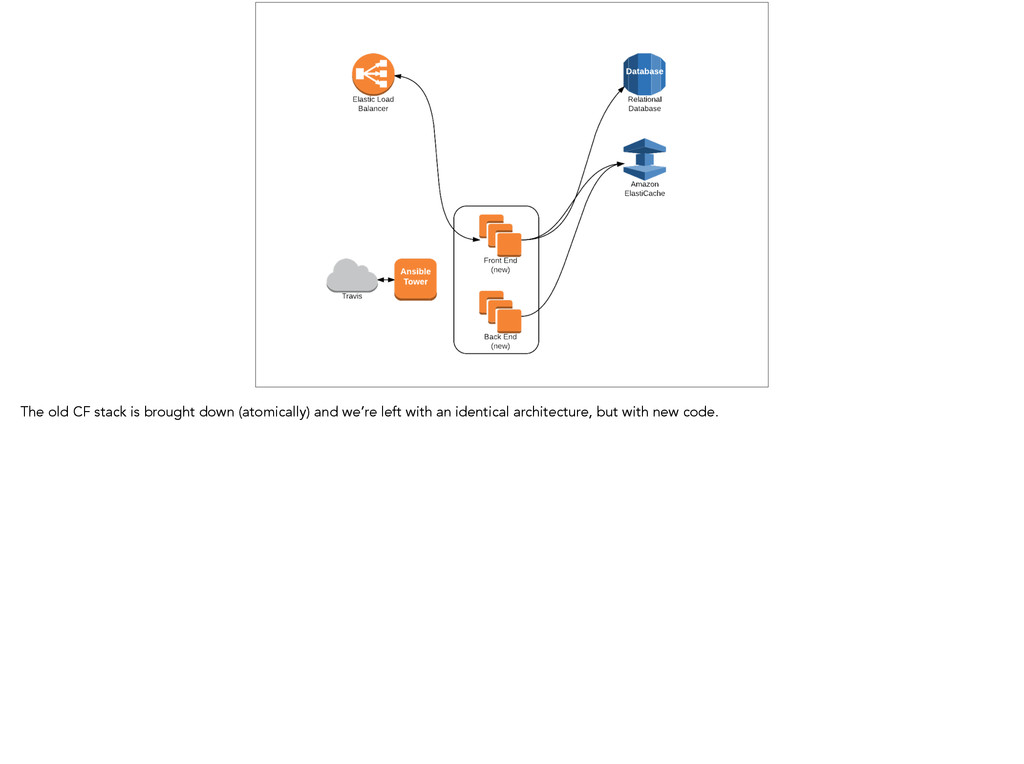
Blue-Green • No more over-provisioning for peak traffic Refactoring your app for a blue-green deploy will require you to remove state from your instances. Which is handy, because you also need that for autoscaling.
- how do we know when they should be configured? • How do we accommodate different roles for different boxes? asynchronous - on deploying, you create the asg, and as soon as the group is created, it’s “there.” but the individual boxes come up on their own time. also as new autoscaled instances come online during scaling out events, this is completely outside of whatever our original provisioning flow might be. And - how do we handle different types of boxes coming up? How do we do autoscaling and have these different boxes?
• Docker? (the containers still need to be provisioned - just passing the buck) The traditional route is by “baking” an AMI for each of your box types, and just using that AMI in your LaunchConfiguration. Aminator - outdated, limited to certain linux dists Packer - slow. The workflow is to spin up a box, provision it, image it. Docker - haven’t looked into it, but seems promising as an extra layer of abstraction / indirection between code and the infrastructure it’s running on
opencv - role: … … roles/common/meta/main.yml Using the “meta” folder of a role allows you to better match your roles to your mental model. It also allows for a level of indirection.
name: Set up deploy user hosts: new_box roles: - base_packages - deploy_user - name: configure for role hosts: new_box remote_user: deploy vars: ansible_ssh_private_key_file: *LOCAL PATH* roles: - common playbook
job to provision the stack using cloudformation (from Travis, or whatever) • “Bake” needed info into LaunchConfigs and ASGs at this point. • Two places where we need to put info: EC2 Metadata Tags, and the ansible facts dir! • “UserData” script will run a script on startup
: [ {"Key" : “AnsibleRole", "Value" : “FrontEnd", "PropagateAtLaunch" : "true"}, {"Key" : “Environment", "Value" : {"Ref" : “DeployEnvironment"}, "PropagateAtLaunch" : “true"}, {"Key" : “SomethingASGSpecific", "Value" : “foo”, "PropagateAtLaunch" : “false”}], … } In declaring ASGs in a cloudformation, you can tag the ASG and declare whether or not the tag should be passed on to its instances Notice here that we are putting tags on the instances that identify the role it will be playing and the environment that it belongs in
are available to Ansible tasks running on the machine • Bake on during CloudFormation provisioning using LaunchConfiguration metadata /etc/ansible/facts.d/deploy_params.fact! {“git_commit”: “af7b666…”} playbook:! …! vars: commit: "{{ ansible_local.deploy_params.git_commit }}” … There is a magical location on boxes - the ansible facts.d directory. Any JSON or YAML files with the extension “.fact” will be read in by any Ansible plays running on that box (assuming you’re gathering facts). You can bake files onto autoscaled instances while provisioning via CloudFormation by putting the file info in the metadata of the LaunchConfig, and then running cf-init from the UserData startup script
launched via the callback API • This happens both during deployment AND during scale-out events • Have all your boxes call the same job, and let the information that you have now baked onto the boxes work their magic
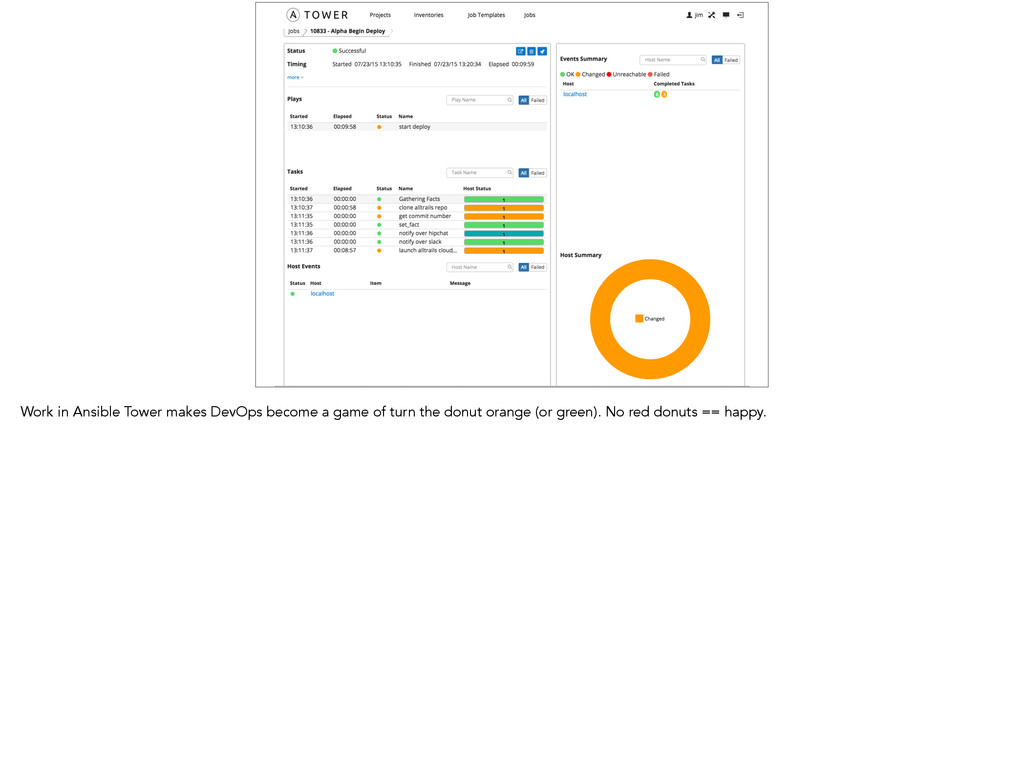
configured doesn’t need anything except sshd. • Ansible Tower offers a great “phone home” option - jobs can be kicked off via a REST API. • The only action we need to do on the box that needs to be configured is: curl <endpoint>
"tag_AnsibleRole_FrontEnd:&tag_Environment_{{ deploy_env }}” vars: db_host: "{{ ansible_local.deploy_params.db_host }}" roles: - front_end - name: "configure backend boxes for role" hosts: "tag_AnsibleRole_BackEnd:&tag_Environment_{{ deploy_env }}” vars: db_host: "{{ ansible_local.deploy_params.db_host }}” roles: - backend playbook this same playbook gets called by all boxes, but it will only run roles and tasks on the hosts that match the tags notice the roles called front_end and app_box - these utilize the meta dependencies similarly to the common role
unless it’s received the proper signals "FrontEndASG" : { "Type" : "AWS::AutoScaling::AutoScalingGroup", "CreationPolicy": { "ResourceSignal": { "Count": { "Fn::FindInMap" : [ "AsgDesiredSizes", “FrontEnd", {"Ref" : "DeployEnvironment"} ]}, "Timeout": "PT20M"}}, this way if something goes wrong, the job sitting up the new cloudformation will fail, and you’ll never tear down the old cloudformation
unless it’s received the proper signals cfn-signal --stack {{ cf_stack_name }} --resource {{ cf_resource_name }} --region us-west-1 this way if something goes wrong, the job sitting up the new cloudformation will fail, and you’ll never tear down the old cloudformation
up a web server, have it wait to make sure the all of the boxes in the front end ASG are returning 200s before moving on. - name: wait for site to start returning 200s local_action: uri args: url: "http://{{ ansible_ec2_public_hostname }}/" register: result until: result|success retries: 30 delay: 10 again, don’t tear down your old site until your new site is working!
to an SNS topic, and use Lambda to subscribe and post to your chat API of choice. "NotificationConfigurations" : [ {"NotificationTypes" : [ "autoscaling:EC2_INSTANCE_LAUNCH", "autoscaling:EC2_INSTANCE_LAUNCH_ERROR", "autoscaling:EC2_INSTANCE_TERMINATE", "autoscaling:EC2_INSTANCE_TERMINATE_ERROR"], "TopicARN" : <SNS ARN> }]
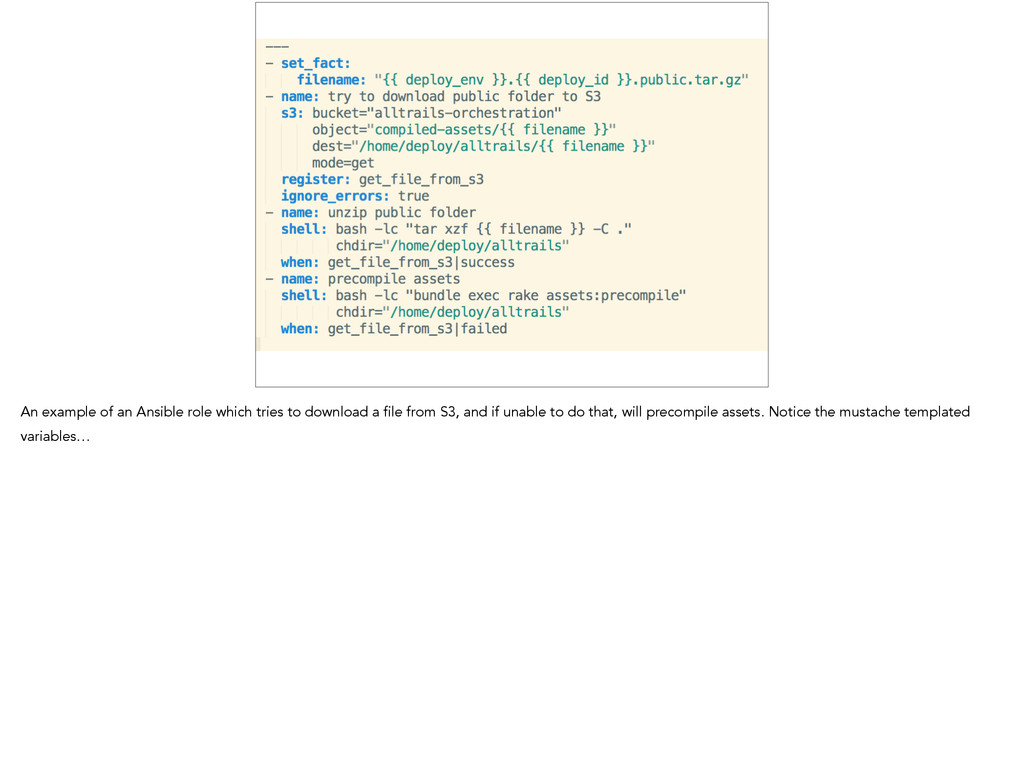
long time, have your CI system spin up a box and precompile while the tests are running. • When it’s done, it can upload to a known place in S3, and from then on, any box that needs the assets can just download them, rather than having to precompile
{kind=link}
![Me: [email protected] • Programmer for artists and musicians • Previous](https://files.speakerdeck.com/presentations/c7b1f1ddba5c4e41b9d0a899b4f0ad3a/slide_1.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![Thanks! Questions? • [email protected] • [email protected] • http://alltrails.com](https://files.speakerdeck.com/presentations/c7b1f1ddba5c4e41b9d0a899b4f0ad3a/slide_48.jpg){kind=link}