Upgrade to Pro
— share decks privately, control downloads, hide ads and more …
Speaker Deck
Features
Speaker Deck
PRO
Sign in
Sign up for free
Search
Search
WaveNet & ApeX Deep Q-Network
Search
Sponsored
·
Your Podcast. Everywhere. Effortlessly.
Share. Educate. Inspire. Entertain. You do you. We'll handle the rest.
→
じんべえざめ
June 29, 2018
Research
1.1k
3
Share
Embed
Copy iframe code
Copy JS code
Copy link
Start on current slide
WaveNet & ApeX Deep Q-Network
RNN, LSTM, WaveNet, ApeX DQN
ご質問,ご指摘等はこちらへ。
@jinbeizame007
じんべえざめ
June 29, 2018
More Decks by じんべえざめ
See All by じんべえざめ
深層強化学習の最前線
jinbeizame007
31
18k
Other Decks in Research
See All in Research
明日から使える!研究効率化ツール入門
matsui_528
13
7.4k
論文紹介 "ReSim: Reliable World Simulation for Autonomous Driving"
kogo
0
690
コーディングエージェントとABNを再考
hf149
2
750
AIエージェント時代のLLM-jpモデルのあるべき姿
k141303
0
500
さくらインターネット研究所テックトーク2026春、研究開発Gr.25年度成果26年度方針
kikuzo
0
160
LLM の Attention 機構まとめ — 数式・計算量・メモリ
puwaer
8
2.2k
COFFEE-Japan PROJECT Impact Report(海ノ向こうコーヒー)
ontheslope
0
2k
多様なデータを許容し学習し続ける模倣学習 / Advanced Imitation Learning for VLA
prinlab
0
240
東京大学工学部計数工学科、計数工学特別講義の説明資料
kikuzo
0
550
討議:RACDA設立30周年記念都市交通フォーラム2026
trafficbrain
0
1k
量子コンピュータの紹介
oqtopus
0
360
COFFEE-Japan PROJECT Impact Report(Uminomukou Coffee)
ontheslope
0
230
Featured
See All Featured
Ten Tips & Tricks for a 🌱 transition
stuffmc
0
150
Leading Effective Engineering Teams in the AI Era
addyosmani
9
2.1k
How to Build an AI Search Optimization Roadmap - Criteria and Steps to Take #SEOIRL
aleyda
1
2.1k
Fantastic passwords and where to find them - at NoRuKo
philnash
52
3.8k
Faster Mobile Websites
deanohume
310
32k
RailsConf 2023
tenderlove
30
1.5k
The Anti-SEO Checklist Checklist. Pubcon Cyber Week
ryanjones
0
180
Building an army of robots
kneath
306
46k
Highjacked: Video Game Concept Design
rkendrick25
PRO
1
400
10 Git Anti Patterns You Should be Aware of
lemiorhan
PRO
659
62k
Groundhog Day: Seeking Process in Gaming for Health
codingconduct
0
240
Code Review Best Practice
trishagee
74
20k
Transcript
WaveNet & Ape-X Deep Q-Network Google DeepMind 情報アーキテクチャ領域 三上研究室 M1
髙橋将文
自己紹介 1 ⚫ 三上研究室 M1 髙橋将文 ⚫ 研究分野: 人工生命 ・動機の創発,形態と制御の共進化
⚫ 趣味 ・深層強化学習,水族館・抹茶めぐり ⚫ 好きなDLライブラリ ・Chainer,PyTorch @jinbeizame007
おしながき 2 ⚫ 時系列データを扱うニューラルネットワーク ・Recurrent Neural Network ・Long Short Term
Memory ・WaveNet (Googleアシスタント搭載) ⚫ 深層強化学習 ・Ape-X Deep Q-Network (ICLR2018)
Recurrent Neural Network
時系列データって何? 3 時間の経過とともに変化するデータを, 時間の順序に従って整理したもの - 例)株価,音声,自然言語…
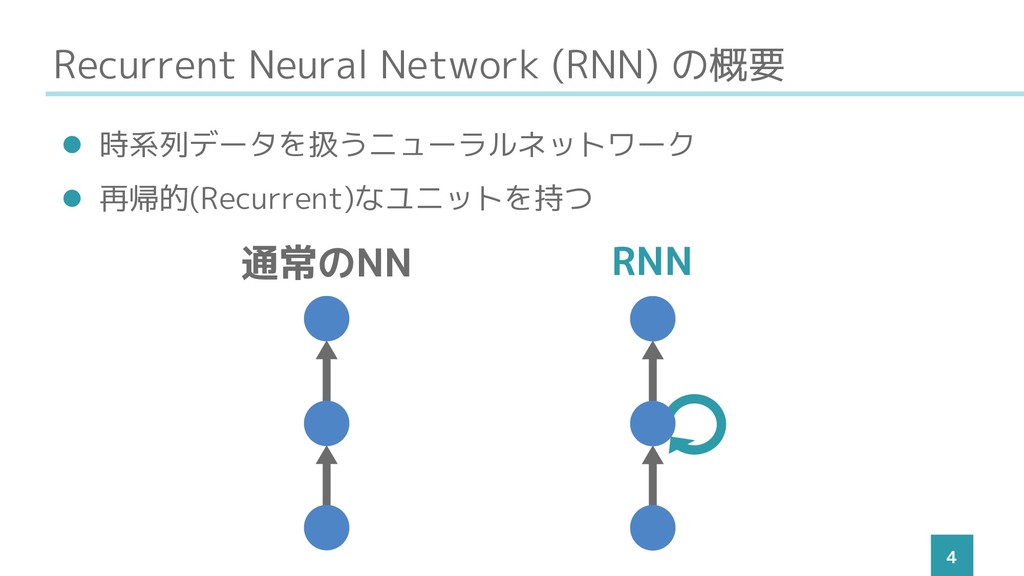
Recurrent Neural Network (RNN) の概要 4 ⚫ 時系列データを扱うニューラルネットワーク ⚫ 再帰的(Recurrent)なユニットを持つ
通常のNN RNN
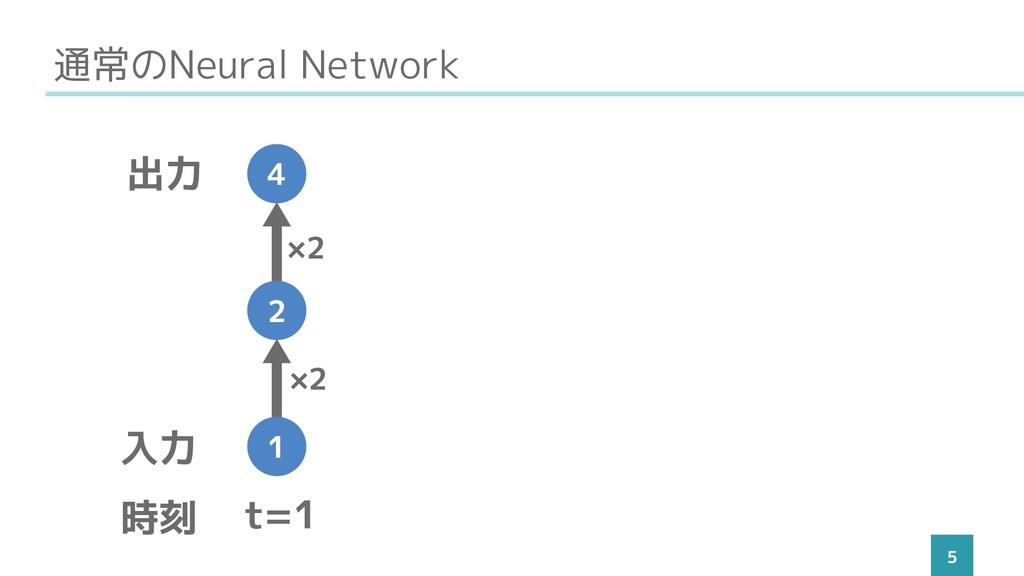
通常のNeural Network 5 t=1 入力 出力 時刻 1 2 4
×2 ×2
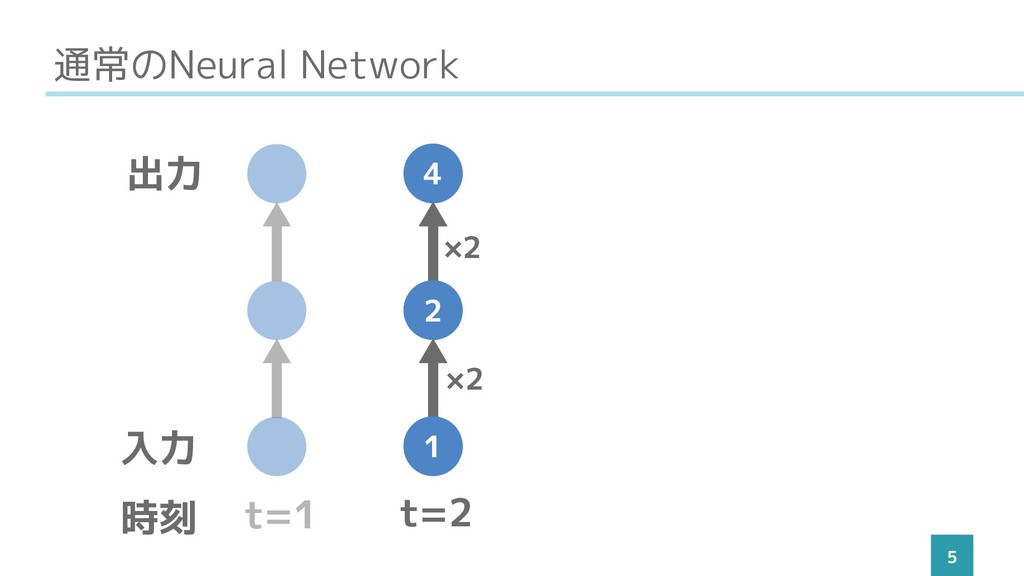
通常のNeural Network 5 t=1 t=2 入力 出力 時刻 1 2
4 ×2 ×2 1 2 4
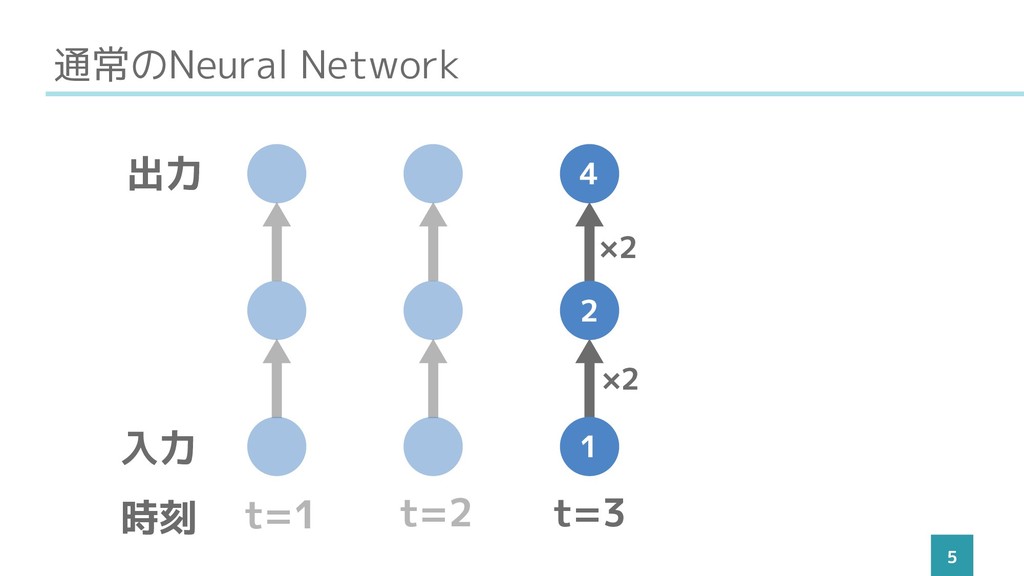
通常のNeural Network 5 t=1 t=2 t=3 入力 出力 時刻 1
2 4 ×2 ×2
通常のNeural Network 5 t=1 t=2 t=3 t=4 入力 出力 時刻
1 2 4 ×2 ×2
通常のNeural Network 5 t=1 t=2 t=3 t=4 入力 出力 時刻
1 2 4 ×2 ×2 1 2 4 ×2 ×2 1 2 4 ×2 ×2 1 2 4 ×2 ×2
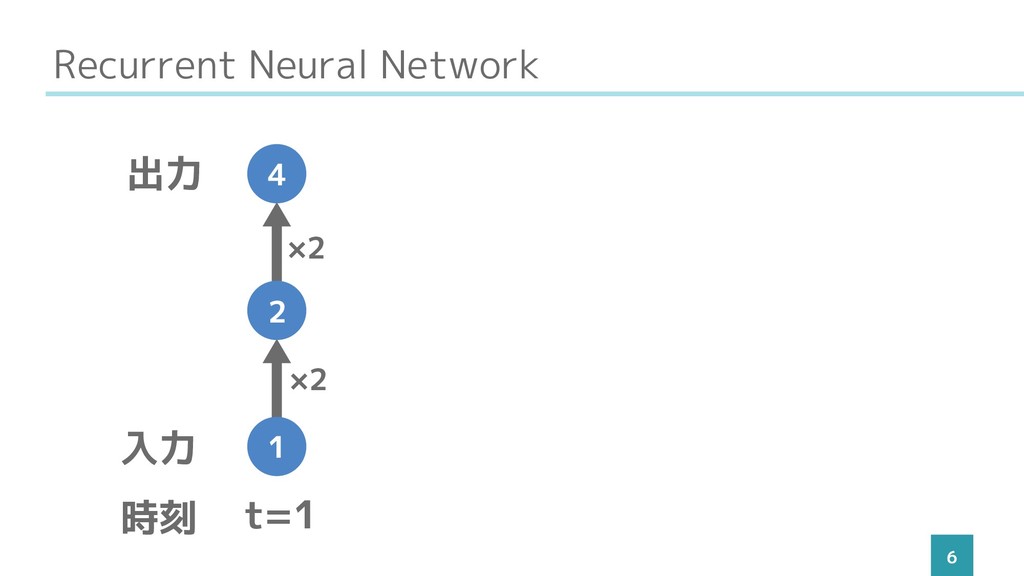
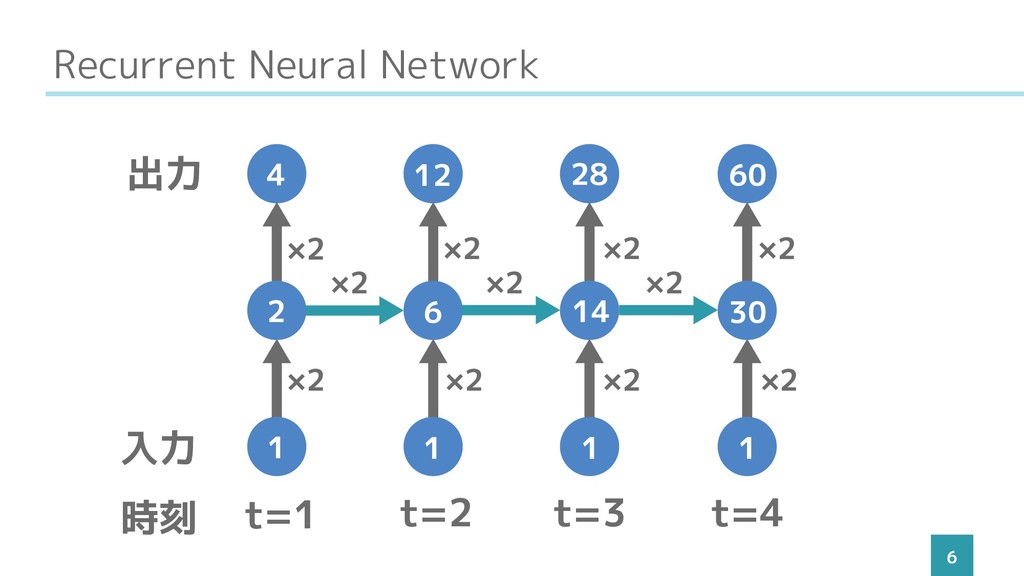
Recurrent Neural Network 6 t=1 入力 出力 時刻 1 2
4 ×2 ×2
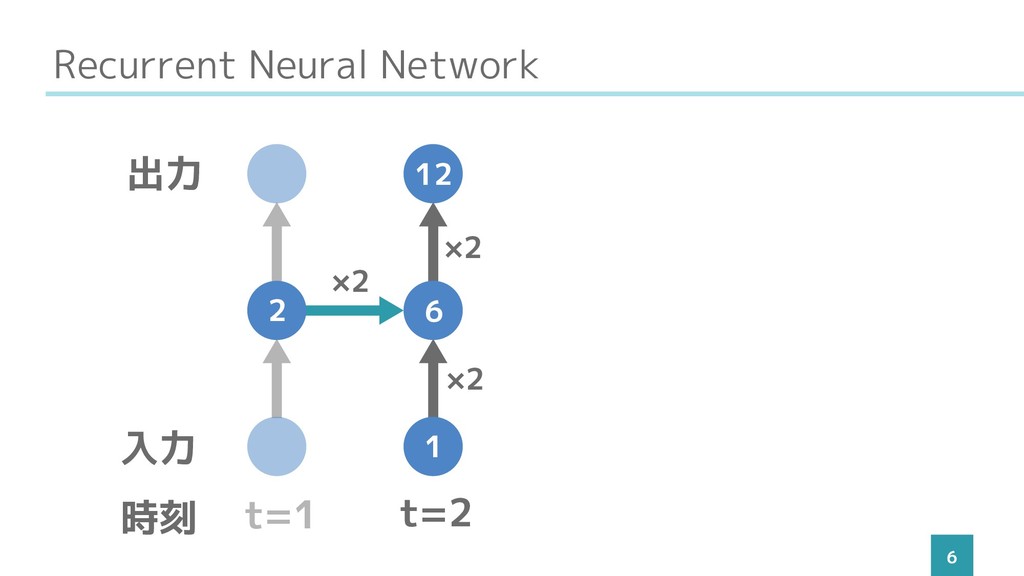
Recurrent Neural Network 6 t=1 t=2 入力 出力 時刻 1
6 12 ×2 ×2 ×2 2
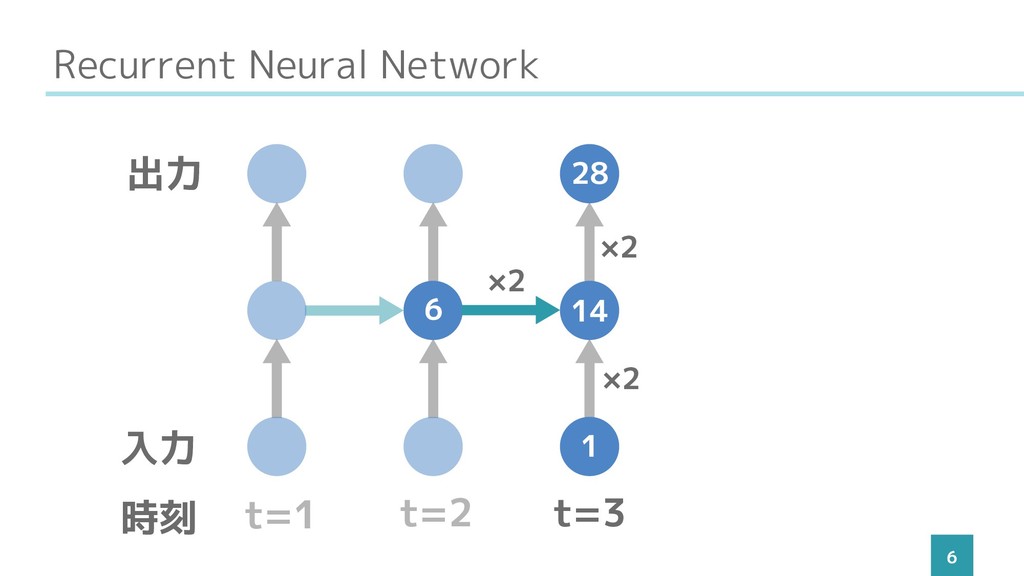
Recurrent Neural Network 6 t=1 t=2 t=3 入力 出力 時刻
1 14 28 ×2 ×2 ×2 6
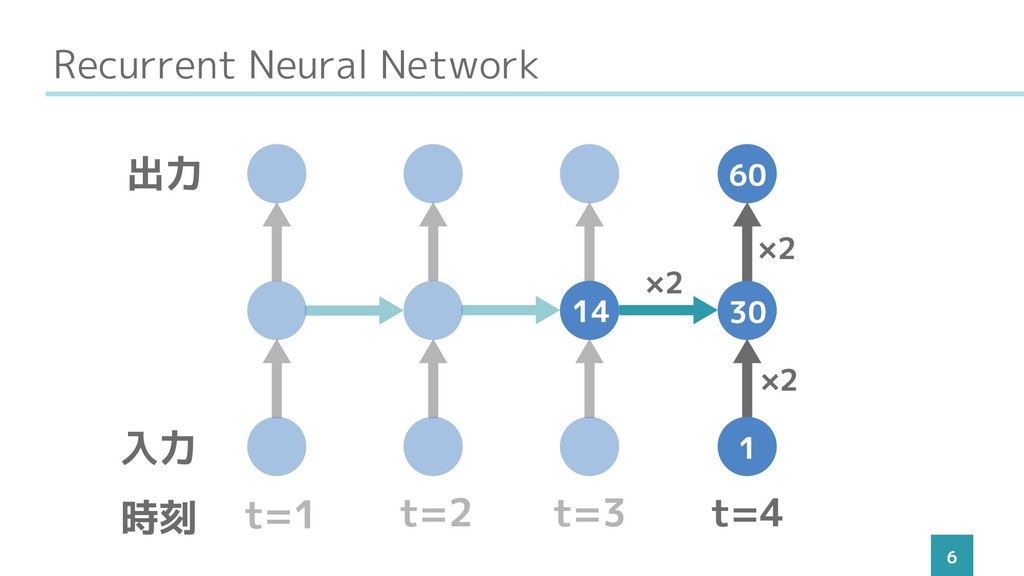
Recurrent Neural Network 6 t=1 t=2 t=3 t=4 入力 出力
時刻 1 30 60 ×2 ×2 ×2 14
Recurrent Neural Network 6 t=1 t=2 t=3 t=4 入力 出力
時刻 1 30 60 ×2 ×2 ×2 14 1 6 12 ×2 ×2 ×2 2 4 1 1 28 ×2 ×2 ×2 ×2 ×2
Long Short Term Memory
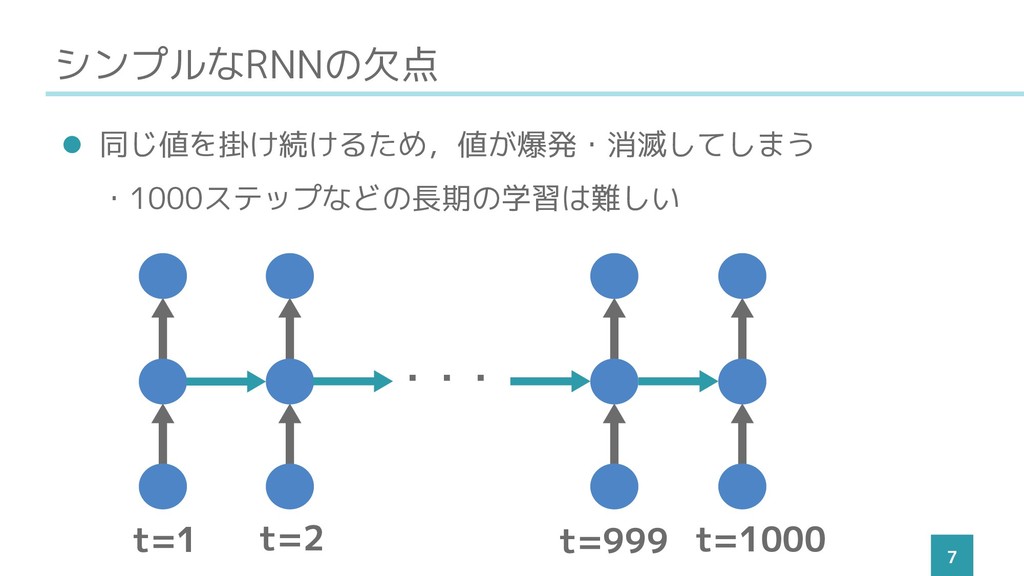
シンプルなRNNの欠点 7 ⚫ 同じ値を掛け続けるため,値が爆発・消滅してしまう ・1000ステップなどの長期の学習は難しい t=1 t=2 t=999 t=1000 ・・・
Long Short Team Memory (LSTM) の概要 8 ⚫ 長期・短期記憶が出来るRNN ⚫
通常のユニットの代わりにLSTM Blockを持つ RNN LSTM LSTM Block
入力ゲート メモリ 出力ゲート 忘却ゲート LSTM Blockの概要 9 ⚫ メモリ,忘却ゲート,入力ゲート,出力ゲートを持つ ⚫
忘却ゲート ・必要無い情報はメモリから削除 ⚫ 入力ゲート ・必要な情報だけメモリに記憶 ⚫ 出力ゲート ・必要な情報だけメモリから出力
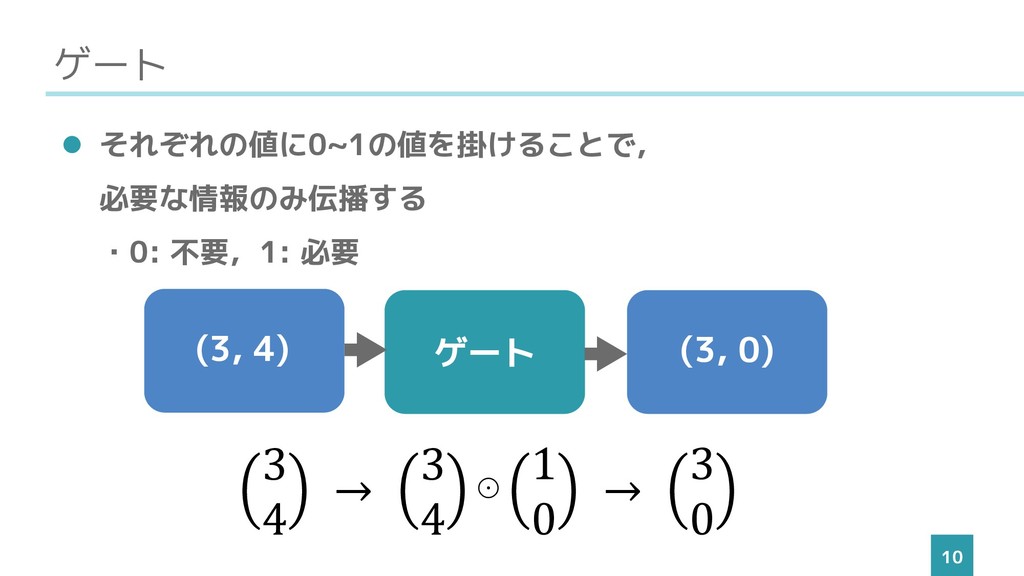
入力ゲート ゲート 10 ⚫ それぞれの値に0~1の値を掛けることで, 必要な情報のみ伝播する ・0: 不要,1: 必要 ゲート
3 4 → 3 4 ⊙ 1 0 → 3 0 (3, 4) (3, 0)
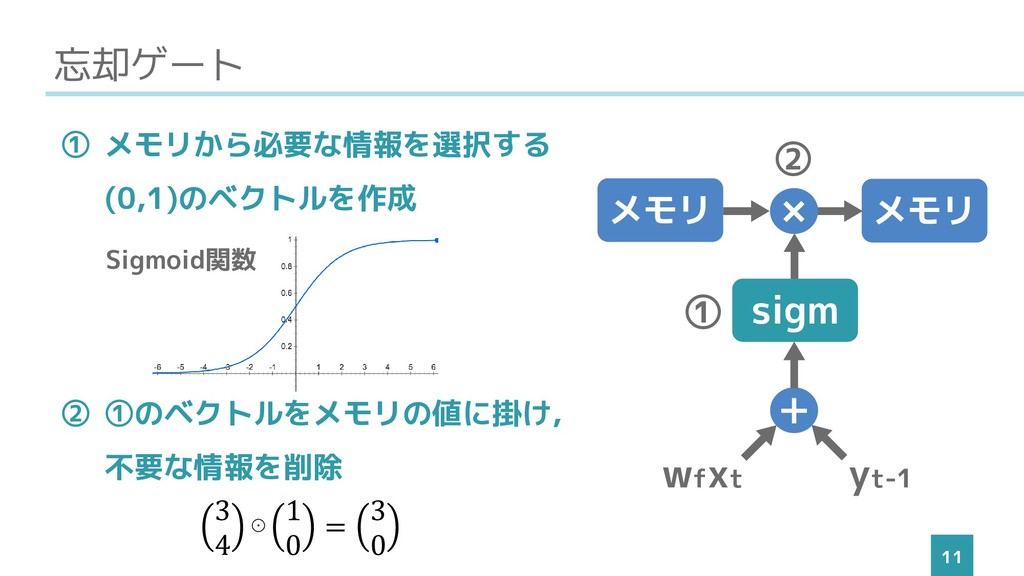
忘却ゲート 11 ① メモリから必要な情報を選択する (0,1)のベクトルを作成 ② ➀のベクトルをメモリの値に掛け, 不要な情報を削除 メモリ 出力ゲート
+ × sigm wfxt yt-1 メモリ メモリ ➀ ➁ 3 4 ⊙ 1 0 = 3 0 Sigmoid関数
入力ゲート 12 ① メモリに入力する候補を作成 入力*重みと前回の出力を足し, メモリに入力する候補を作成 ② ➀の中から入力する情報を選択 sigmoid関数を用いて, (0,1)のベクトルを作成
③ ➀と➁を掛け合わせ, 必要な情報だけ保存 メモリ 出力ゲート + + × tanh sigm wmxt yt-1 wixt yt-1 ➀ ➁ ③ メモリ
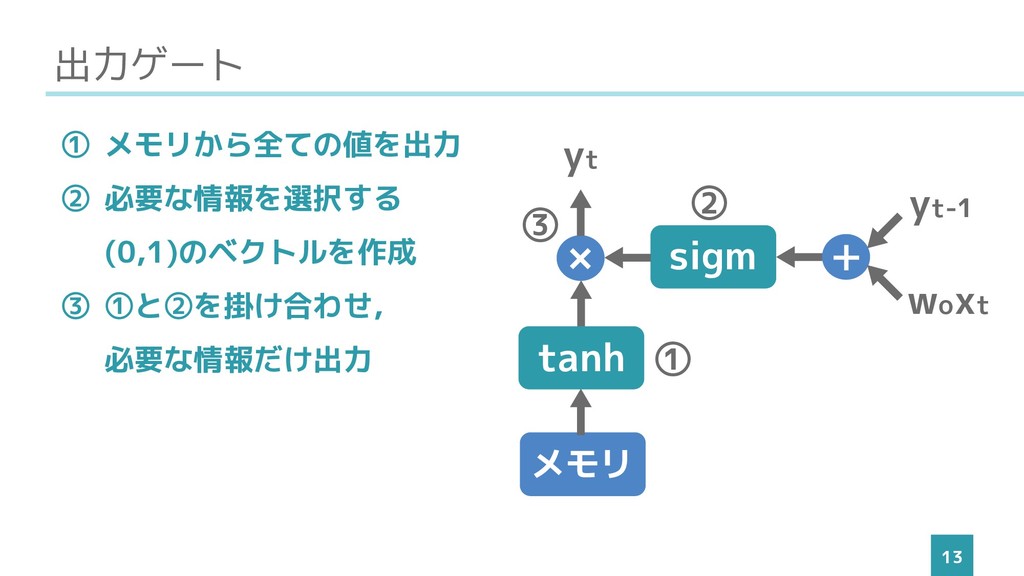
出力ゲート 13 ① メモリから全ての値を出力 ② 必要な情報を選択する (0,1)のベクトルを作成 ③ ➀と➁を掛け合わせ, 必要な情報だけ出力
メモリ メモリ + × sigm woxt yt-1 ➁ ③ tanh ➀ yt
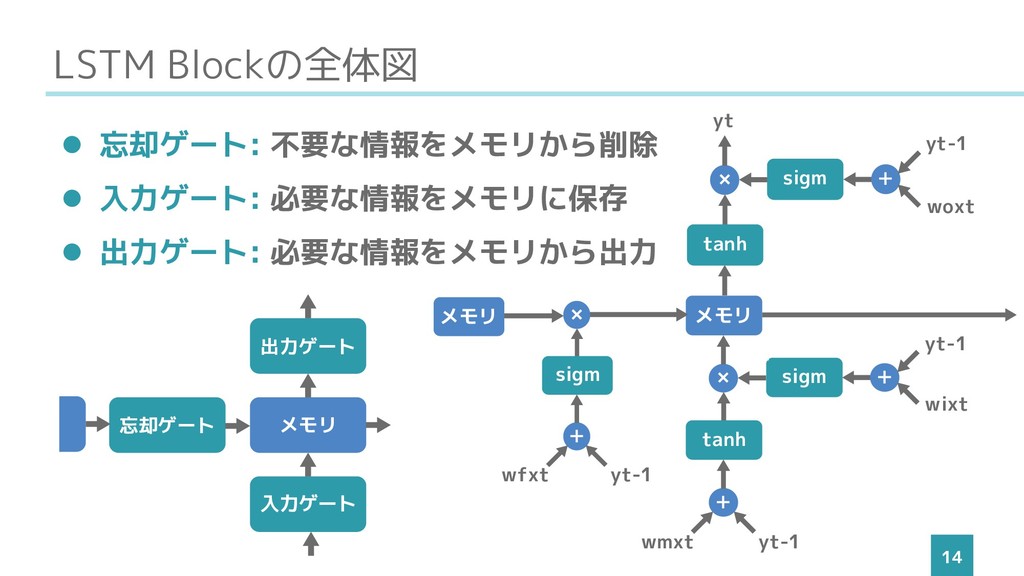
LSTM Blockの全体図 14 メモリ 出力ゲート + + × tanh sigm
wmxt yt-1 wixt yt-1 メモリ メモリ 出力ゲー ト + × sigm wfxt yt-1 メモリ メモリ + × sigm woxt yt-1 tanh yt 入力ゲート メモリ 出力ゲート 忘却ゲート ⚫ 忘却ゲート: 不要な情報をメモリから削除 ⚫ 入力ゲート: 必要な情報をメモリに保存 ⚫ 出力ゲート: 必要な情報をメモリから出力
WaveNet
WaveNetの概要 15 音声波形の生成モデル ⚫ 従来のText-To-Speech(TTS)手法と比較して 自然な音声を生成可能 ⚫ Googleアシスタントなどに搭載されている 出展:DeepMind「WaveNet: A
Generative Model for Raw Audio」
音声データの取り扱い 16 ⚫ 生の波形データはint16のため,取りうる値は65535通り ・予測が65535通りだと学習が大変... ⚫ μ-lowアルゴリズムを用いて256通りに量子化 = sign ln(1
+ ) ln(1 + ) −1 < < 1 = 255
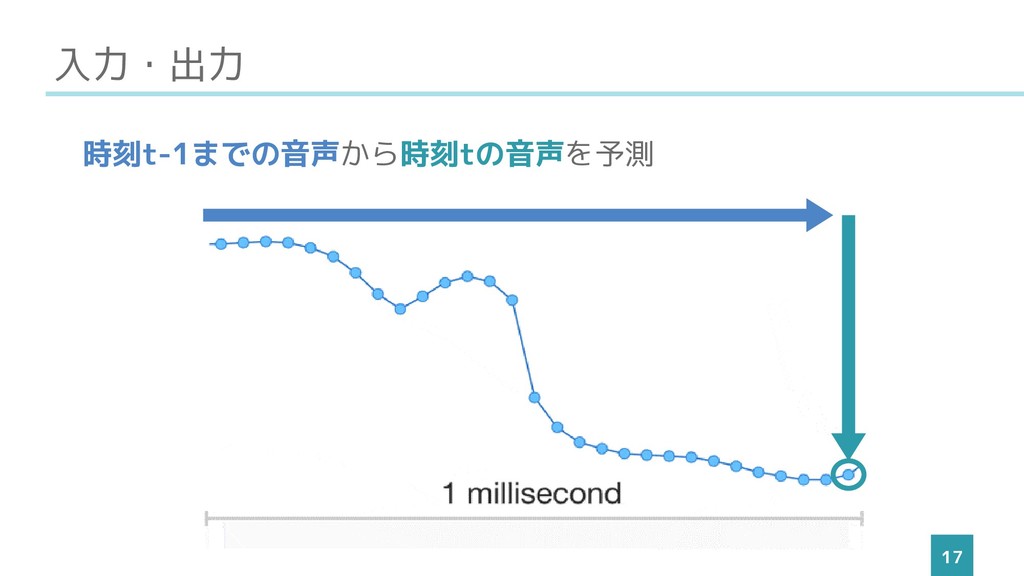
入力・出力 17 時刻t-1までの音声から時刻tの音声を予測
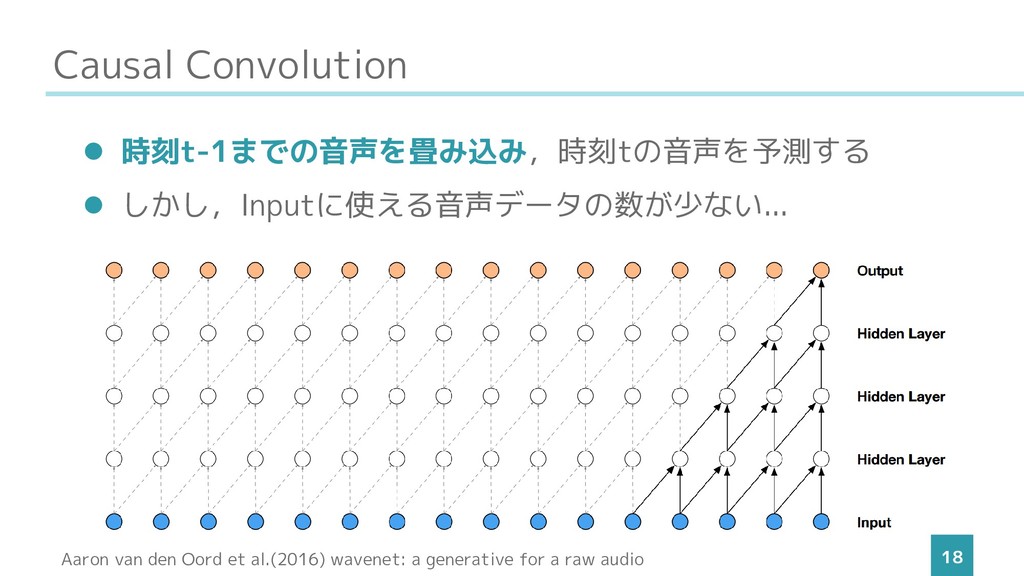
Causal Convolution 18 ⚫ 時刻t-1までの音声を畳み込み,時刻tの音声を予測する ⚫ しかし,Inputに使える音声データの数が少ない... Aaron van den
Oord et al.(2016) wavenet: a generative for a raw audio
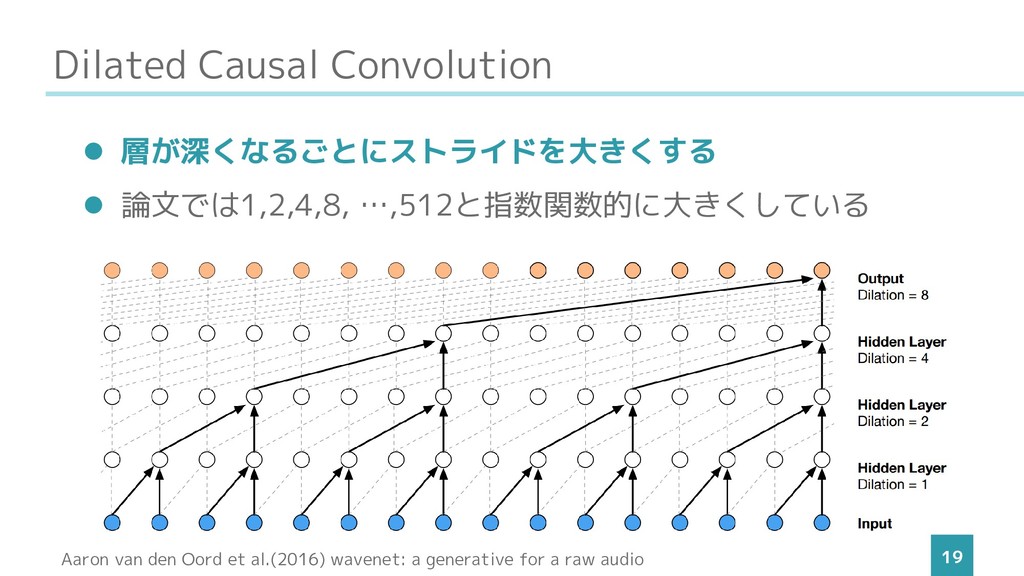
Dilated Causal Convolution 19 ⚫ 層が深くなるごとにストライドを大きくする ⚫ 論文では1,2,4,8, …,512と指数関数的に大きくしている Aaron
van den Oord et al.(2016) wavenet: a generative for a raw audio
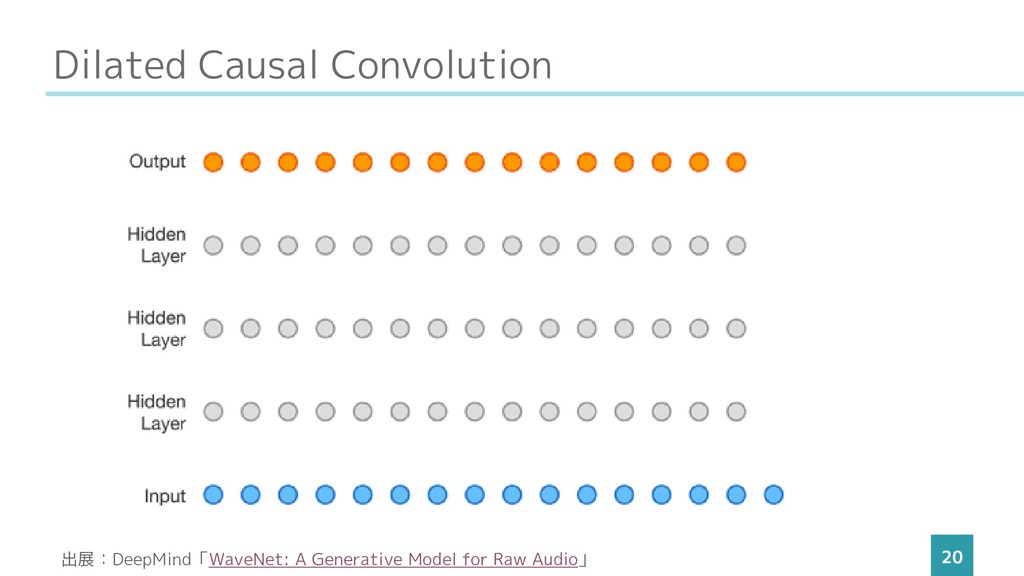
Dilated Causal Convolution 20 出展:DeepMind「WaveNet: A Generative Model for Raw
Audio」
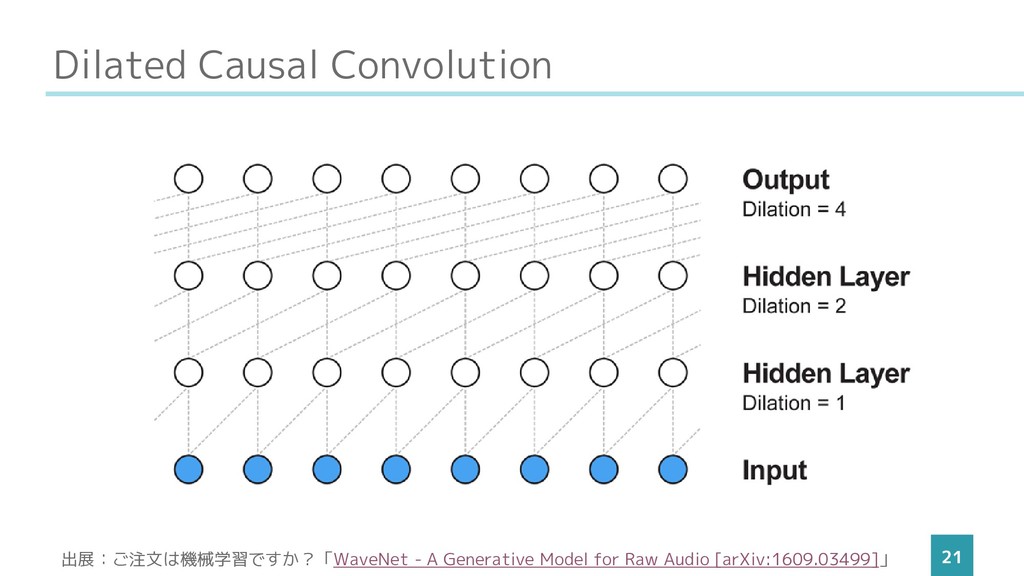
Dilated Causal Convolution 21 出展:ご注文は機械学習ですか?「WaveNet - A Generative Model for
Raw Audio [arXiv:1609.03499]」
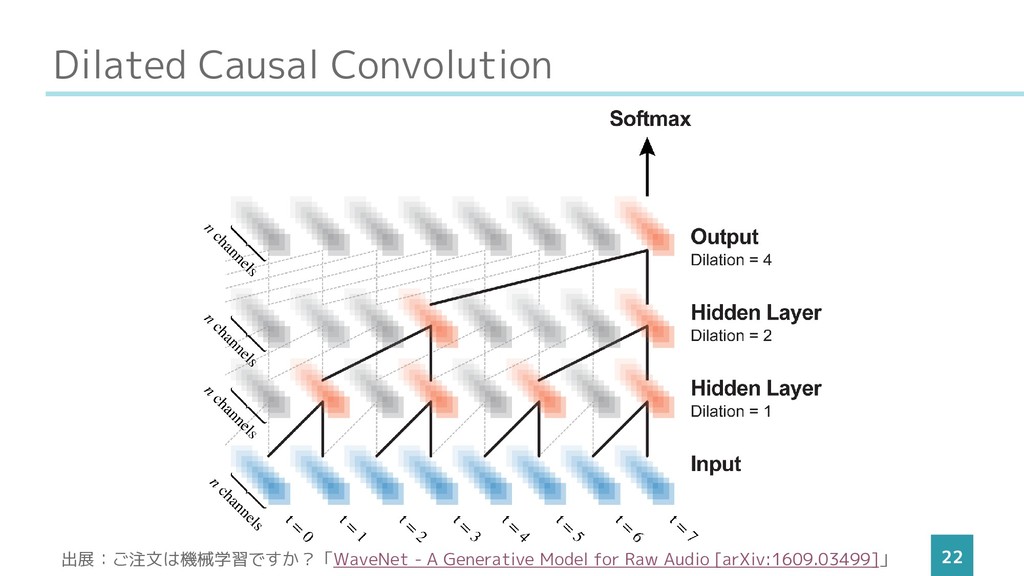
Dilated Causal Convolution 22 出展:ご注文は機械学習ですか?「WaveNet - A Generative Model for
Raw Audio [arXiv:1609.03499]」
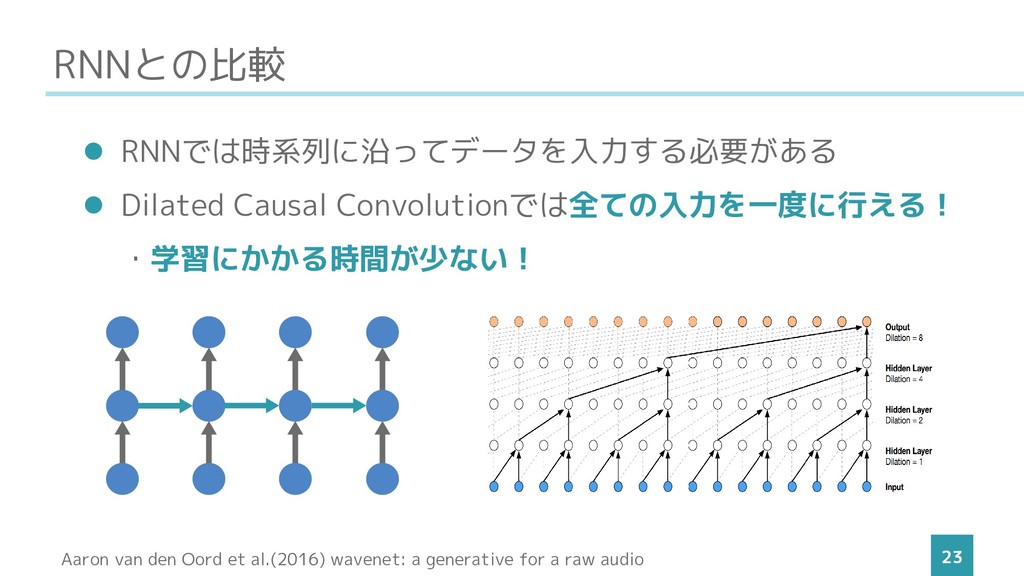
RNNとの比較 23 ⚫ RNNでは時系列に沿ってデータを入力する必要がある ⚫ Dilated Causal Convolutionでは全ての入力を一度に行える! ・学習にかかる時間が少ない! Aaron
van den Oord et al.(2016) wavenet: a generative for a raw audio
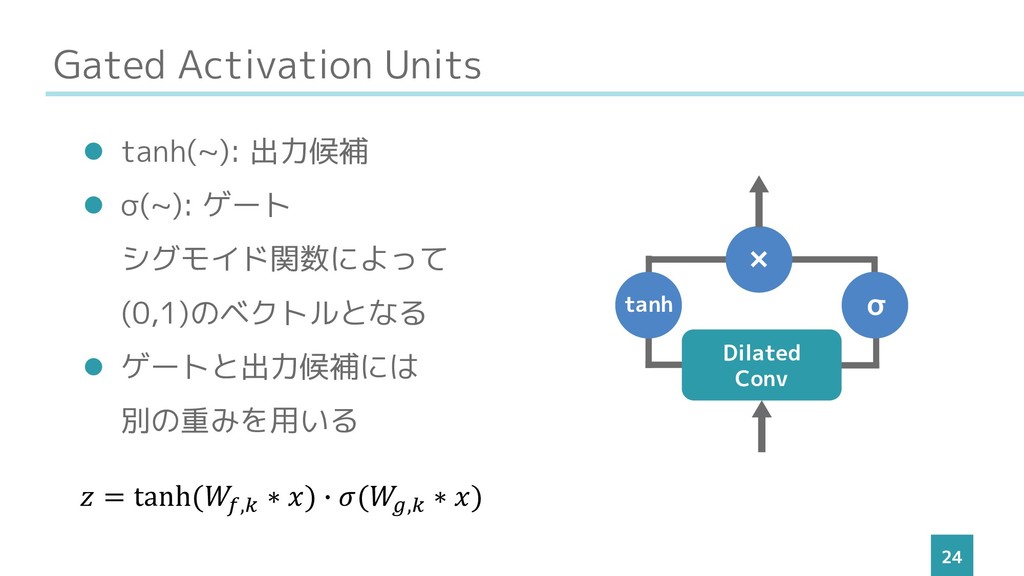
Gated Activation Units 24 ⚫ tanh(~): 出力候補 ⚫ σ(~): ゲート
シグモイド関数によって (0,1)のベクトルとなる ⚫ ゲートと出力候補には 別の重みを用いる tanh σ Dilated Conv × = tanh(, ∗ ) ∙ (, ∗ )
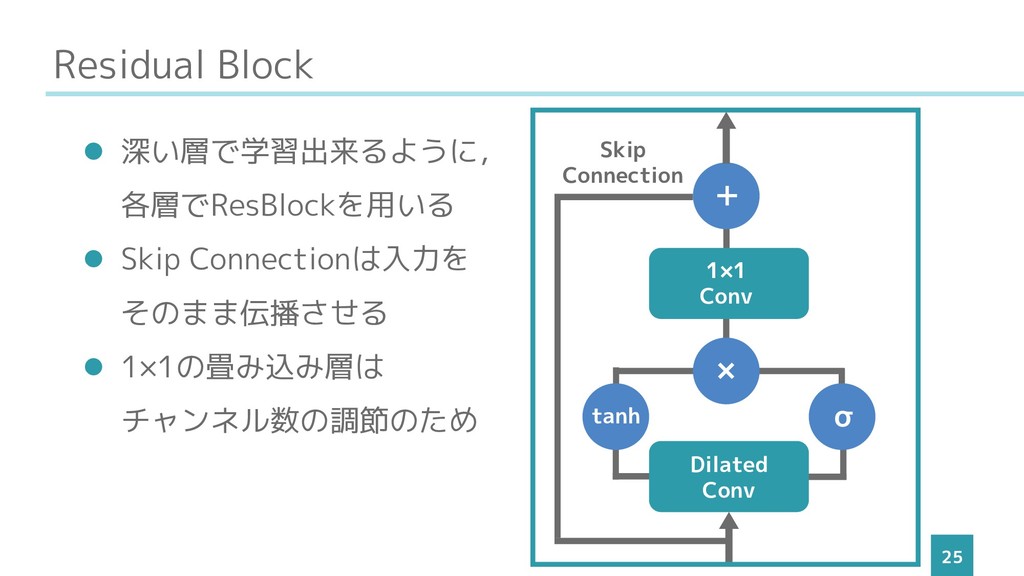
Residual Block 25 ⚫ 深い層で学習出来るように, 各層でResBlockを用いる ⚫ Skip Connectionは入力を そのまま伝播させる
⚫ 1×1の畳み込み層は チャンネル数の調節のため tanh σ Dilated Conv 1×1 Conv × + Skip Connection
WaveNetの応用 26 ⚫ 生成される音声の特徴hを入力に追加 ⚫ Global conditioning ・全ての時間で共通する特徴 ⚫ Local
conditioning ・局所的に用いる特徴 ← TTSはこっち(音節,単語etc) 波形データと同じように,新しい時系列に写像 = tanh(, ∗ + , ℎ) ∙ (, ∗ + , ℎ) = tanh(, ∗ + , (ℎ)) ∙ (, ∗ + , ℎ )
生成された音声 27 ⚫ English ・Current Best Non-WaveNet ・WaveNet ⚫ Japanese
・Current Best Non-WaveNet ・WaveNet
生成されたピアノの曲 28 ⚫ Piano
Ape-X Deep Q-Network
強化学習 29 ⚫ 環境で行動をし,報酬を得ることを繰り返す ⚫ 得る報酬を最大化する方策を学習 ・方策: 状態に対して行動を返す関数 行動 環境
B 報酬: ダメージ 状態: 画像 方策
方策 30 ⚫ 方策には価値関数を用いる ⚫ 価値関数: ある状態や,その状態での各行動の価値を求める関数 行動 環境 B
報酬: ダメージ 状態: 画像 A B 0.3 1.2 価値関数
深層強化学習 31 ⚫ 方策にニューラルネットワークを用いた強化学習 ⚫ 状態数が膨大であったり,連続値でも学習可能 行動 環境 B 報酬:
ダメージ 状態: 画像 A B 0.3 1.2
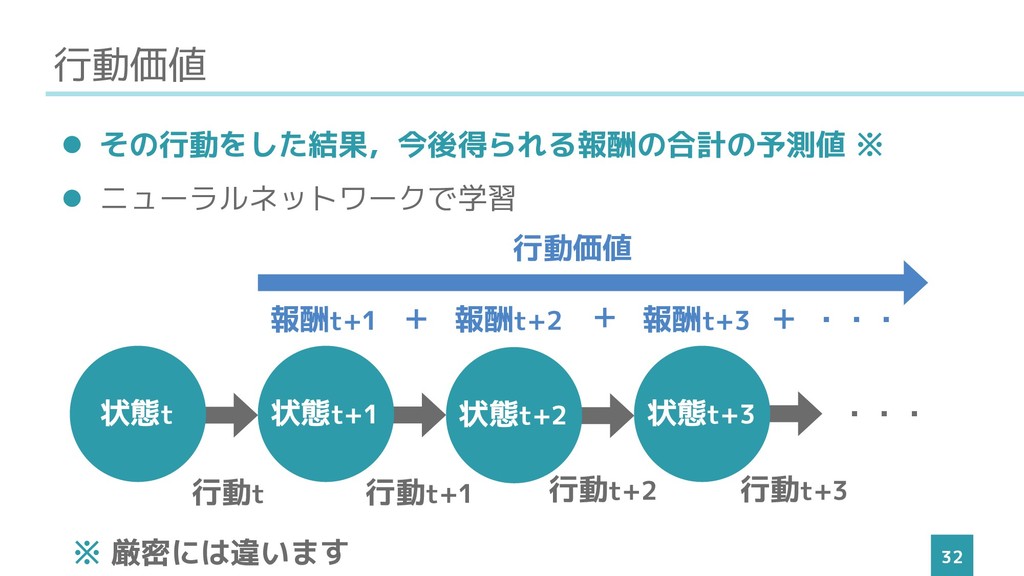
行動価値 32 ⚫ その行動をした結果,今後得られる報酬の合計の予測値 ※ ⚫ ニューラルネットワークで学習 状態t 状態t+1 状態t+2
状態t+3 報酬t+1 報酬t+2 報酬t+3 ・・・ + + + ・・・ 行動t 行動t+1 行動t+2 行動t+3 行動価値 ※ 厳密には違います
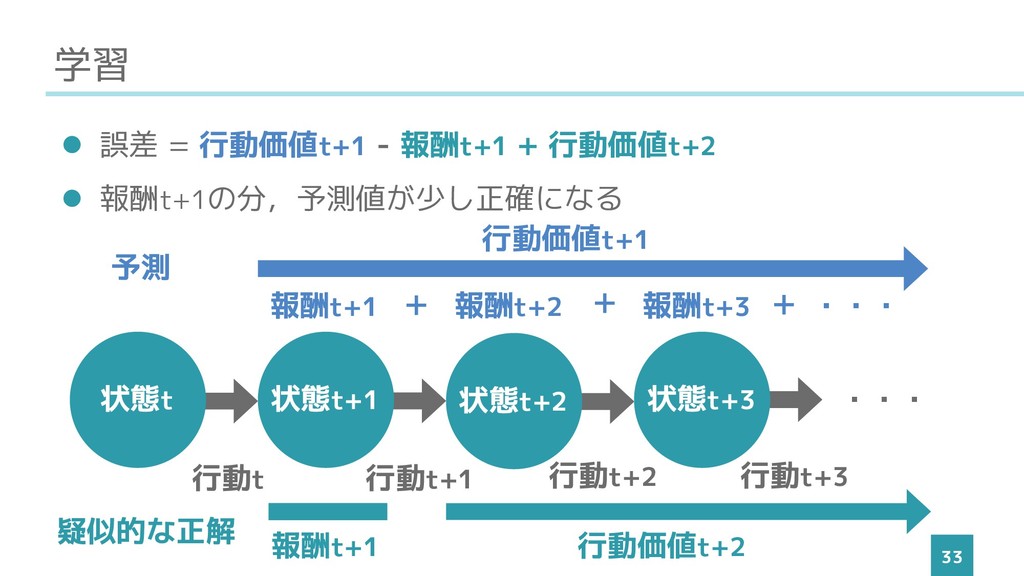
学習 33 ⚫ 誤差 = 行動価値t+1 -(報酬t+1 + 行動価値t+2) ⚫
報酬t+1の分,予測値が少し正確になる 状態t 状態t+1 状態t+2 状態t+3 報酬t+1 報酬t+2 報酬t+3 ・・・ + + + ・・・ 行動t 行動t+1 行動t+2 行動t+3 報酬t+1 行動価値t+2 行動価値t+1 予測 疑似的な正解
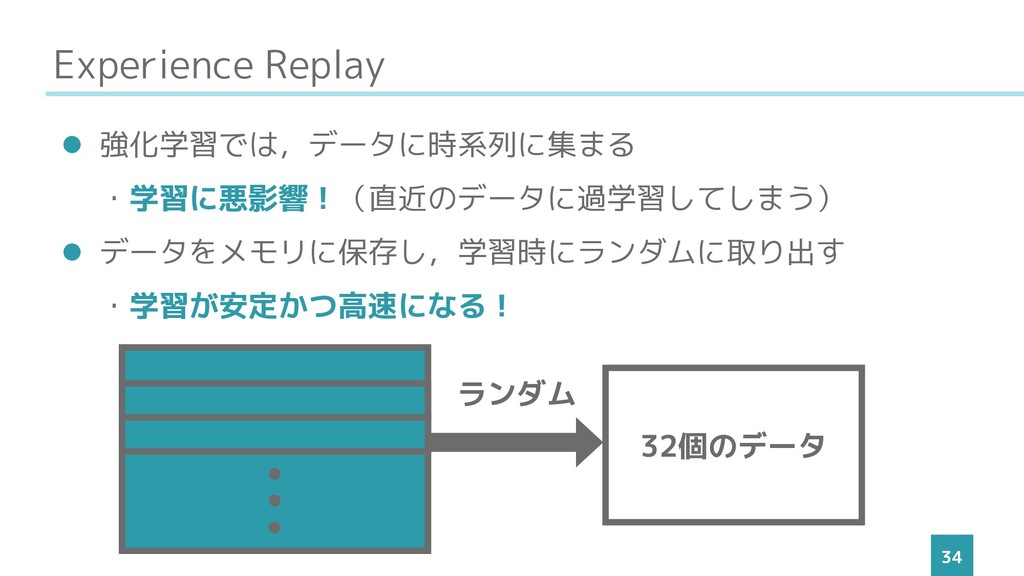
Experience Replay 34 ⚫ 強化学習では,データに時系列に集まる ・学習に悪影響!(直近のデータに過学習してしまう) ⚫ データをメモリに保存し,学習時にランダムに取り出す ・学習が安定かつ高速になる! •
• • 32個のデータ ランダム
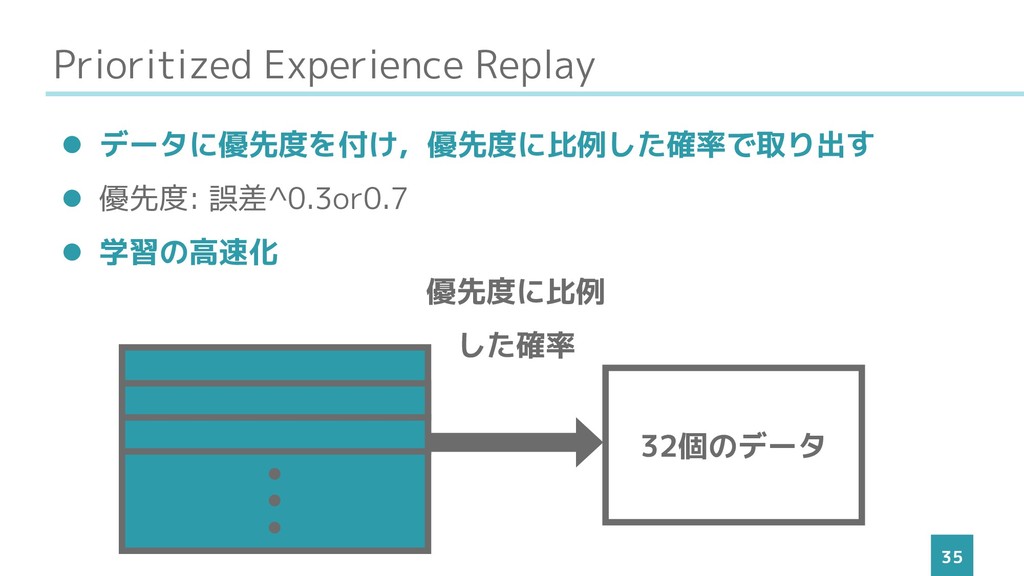
Prioritized Experience Replay 35 ⚫ データに優先度を付け,優先度に比例した確率で取り出す ⚫ 優先度: 誤差^0.3or0.7 ⚫
学習の高速化 • • • 32個のデータ 優先度に比例 した確率
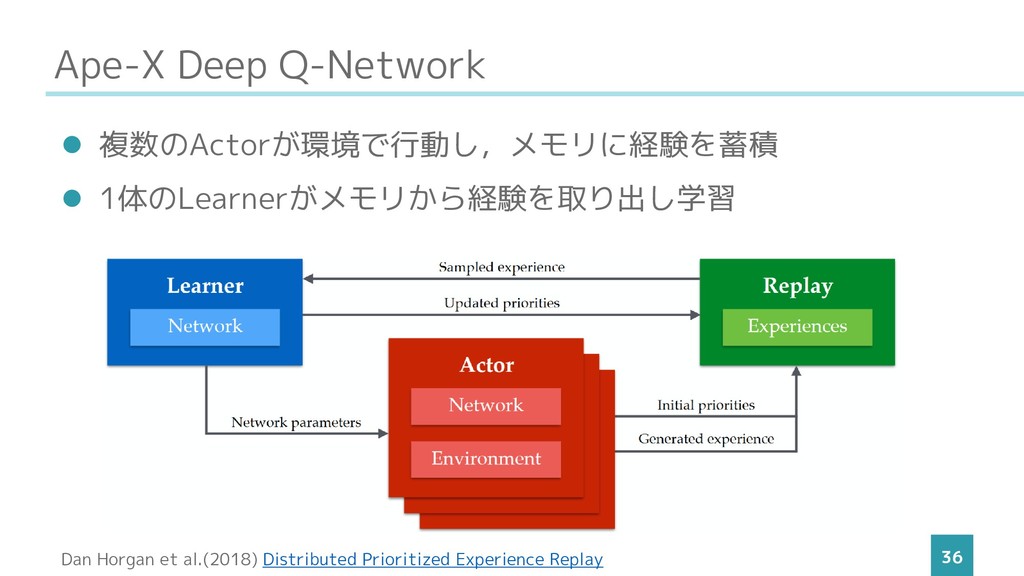
Ape-X Deep Q-Network 36 ⚫ 複数のActorが環境で行動し,メモリに経験を蓄積 ⚫ 1体のLearnerがメモリから経験を取り出し学習 Dan Horgan
et al.(2018) Distributed Prioritized Experience Replay
Ape-X Deep Q-Network 37 ⚫ 他にも様々な工夫が… ・clipping ・target Q-Network ・Double
Deep Q-Network ・Dueling Network ・multistep bootstrap target ・ε-greedyのεの分担 ⚫ もし気になる方がいれば最後の質問で聞いてください
SEGA Sonic the hedgehog 38 ⚫ シリーズ合計58ステージ 出展:OpenAI Blog「Retro Contest」
学習の設計 39 ⚫ 状態:4フレーム分の白黒画像 ⚫ 行動:コントローラーの7種類の操作 {→,←,→↓,←↓,↓,↓B,B} ⚫ 報酬:x座標を更新するたびに +0.01
None
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}