2017/02/28のデータ分析基盤Night #1で発表したスライドです。
# 今日のagenda
1. Rettyの分析基盤の歴史
1. 現在の分析基盤
1. まとめ
# Retty の分析基盤の歴史
rettyの分析基盤は現在、 次のフェーズへ移ろうとしています。
なぜ、そのような形になったのかを歴史を含め説明させていただきます。
## Retty の分析基盤の流れ
Rettyの分析基盤はこのような形になっております。
1. trasuerdata
1. trasuerdata+BigQuery
1. 現在
## trasuer data
以前はRettyの分析基盤としてtrasuer dataが使用されていました。
使用を開始した当初は、レコード量が多いわけでもなく、クエリを投げる人も多くなく、まだ分析で多く使われるわけではなかったため問題が発生しませんでしたが、最近では集計jobだけではなく、アドホック分析に使われることが多くなってきました。
使う人や頻度が増え、jobが詰まるようになり、集計クエリにも影響が出るようになりtrasuer dataを使い続けて分析するのが困難になりました。
その結果、trasuer dataを以前のように自由に使うことができなくなりました。
## BigQuery
trasuer dataでは、解析に時間がかかったり集計クエリに影響が出ないように調整するようになったためBig Queryを使用する人が出てきました。
集計の速度自体は改善されましたが、それぞれの担当者が別々にクエリを投げているため、出す人によって使用するデーターのとり方が違っているため同じ意図として取得したデータでも、出す人によってデータが違うということが発生しました。
また、金額をハンドルする人がいなかったため、大きなデータに対して豪快なクエリを投げて。。。等も発生しておりました。
# データ分析基盤の構築
## 要件
- 分析者がストレスなく分析することが可能な環境を構築する。
- 各チームで共通のデータを使用することができている状態を作る。
- サービスDBの必要なデータとログが一つのDBに格納されている。
- 短時間での復元が可能な状態を保持し続ける。
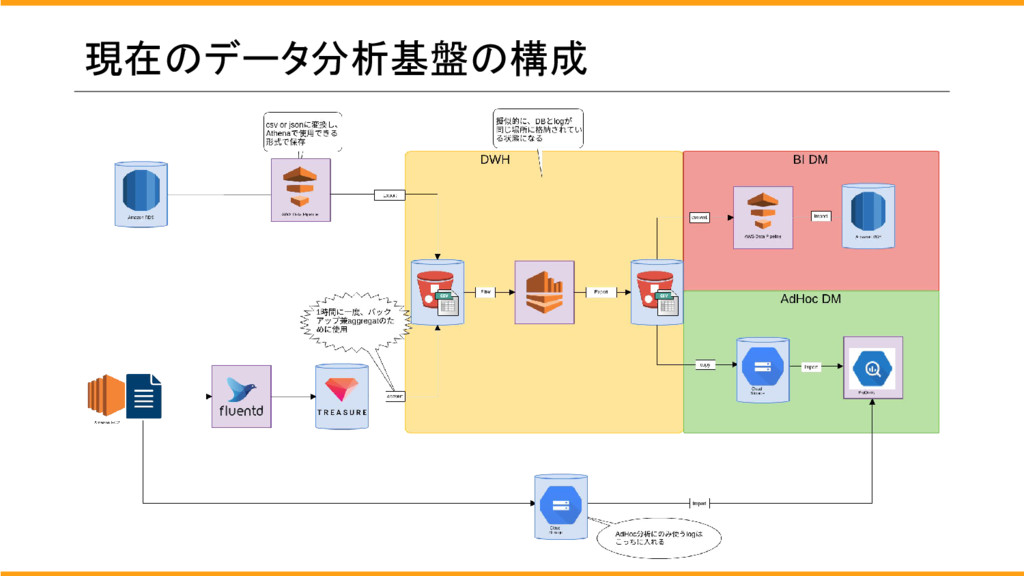
## 現在のデータ分析基盤の構成
[f:id:rettydev:20170223162436p:plain]
Rettyの分析基盤はAthenaとBigQueryを中心に構築しています。
データの流れとしては、各サーバーから吐かれたログをfluentdを通してtrasuerdataに送ります。
trasuerdataをaggregatorとして使用し、trasuerdataからs3にログを送ります。
サービスで使用しているデータもAWSのDataPipelineを通して、ファイル形式に変換してS3に送ります。
このデータをAthenaにより、BIツールやAdhoc分析で必要なデータに正規化してS3にファイル形式で送ります。
BIツール用のDMやAdHoc分析用のDMでは正規化されたデータを元に分析を行うようにします。
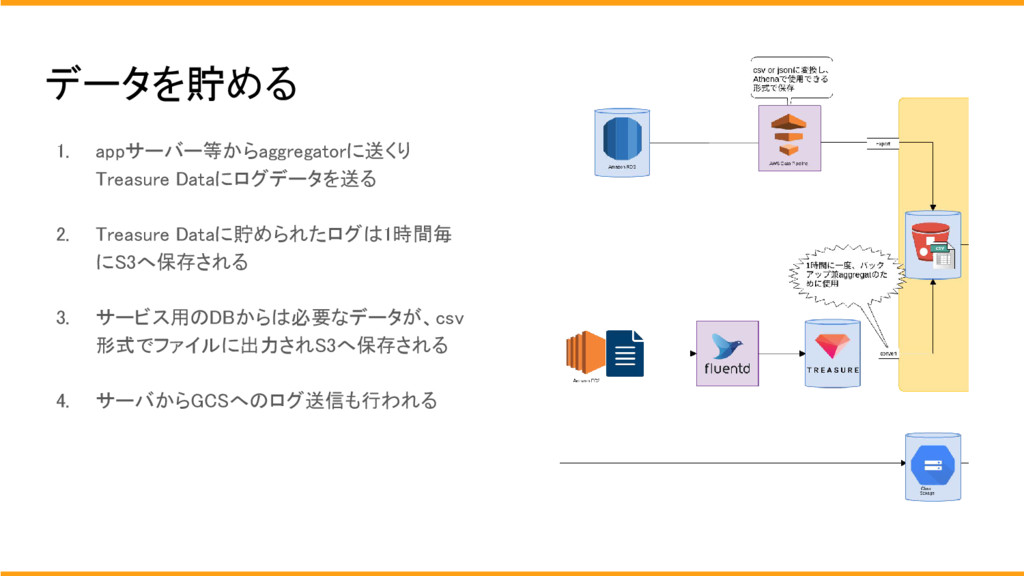
## データを貯める
データを蓄積するための仕組みとしては、現在このようなルートで行っております。
1. appサーバー等からfluentdを使用してaggregatorに送くりtrasuerdataにログデータを送ります。
1. trasuerdataに貯められたログは1時間毎にS3へ保存されます。
1. サービス用のDBからは必要なデータが、csv形式でファイルに出力されS3へ保存されます。
1. また、appサーバからGCSへのログの送信も行われます。
trasuerdataへ送信する理由は、trasuerdataでは現在収益に関わる集計クエリが動いており、クエリの移植が終わっていないため、まだ現在はtrasuerdataにログを送っている状態です。
appサーバーからGCSへログを送る理由としては、開発の人たちは自由にログを設定したいが、全てのログをDWHに送ったところで、共通的なログではないため、DWHが汚れてしまいます。
そのため、一旦GCSに吐き出すように設定し、施策の指標としてチームでBIツール等を通して追っていきたいとなった場合はDWHに追加する運用にしております。
この際にログをappサーバー等から直接送信しない理由としては、サーバーがオートスケールした際にファイルの粒度を統一しておくため
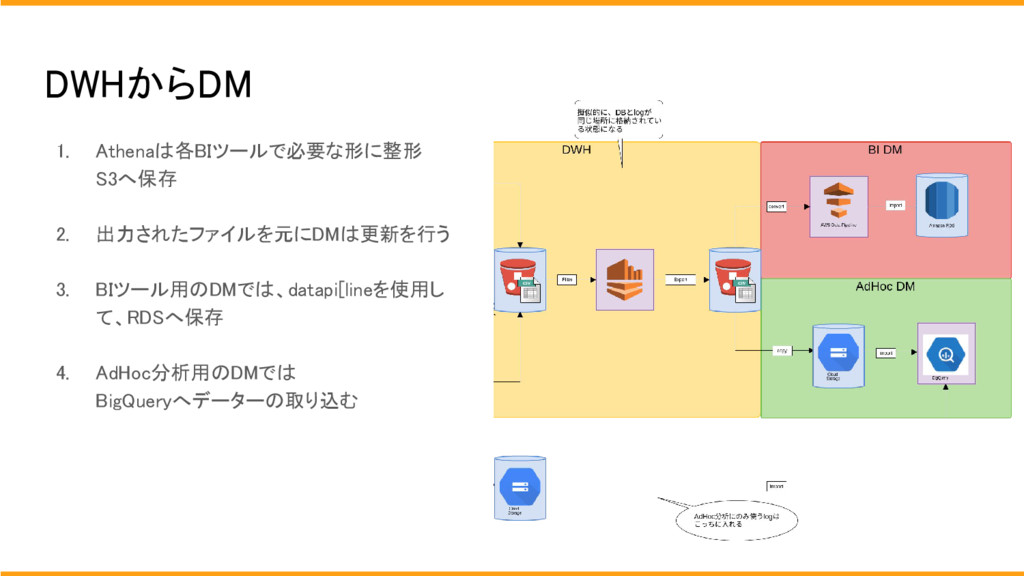
## DWHからDMへ
1. Athenaで各BIツールで必要な形に整形をおこない、S3へファイル形式で保存します。
1. 出力されたファイルを元にDMは更新を行います。
1. BIツール用のDMでは、datapi[lineを使用して、RDSへ保存します。
1. AdHoc分析用のDMではGCSにファイルをsyncさせた後に、BigQueryへデーターの取り込みを行っております。
今回、athenaを使用した理由は、オンプレにある機械学習基盤にも同様にDWHのような物を作成したかったため、ファイル形式で保存することが望ましかった、
また、ファイルで保持し続けるほうが将来的に変更する場合でも移行する場合でも、S3へクエリを投げて出力するathenaが望ましかった。
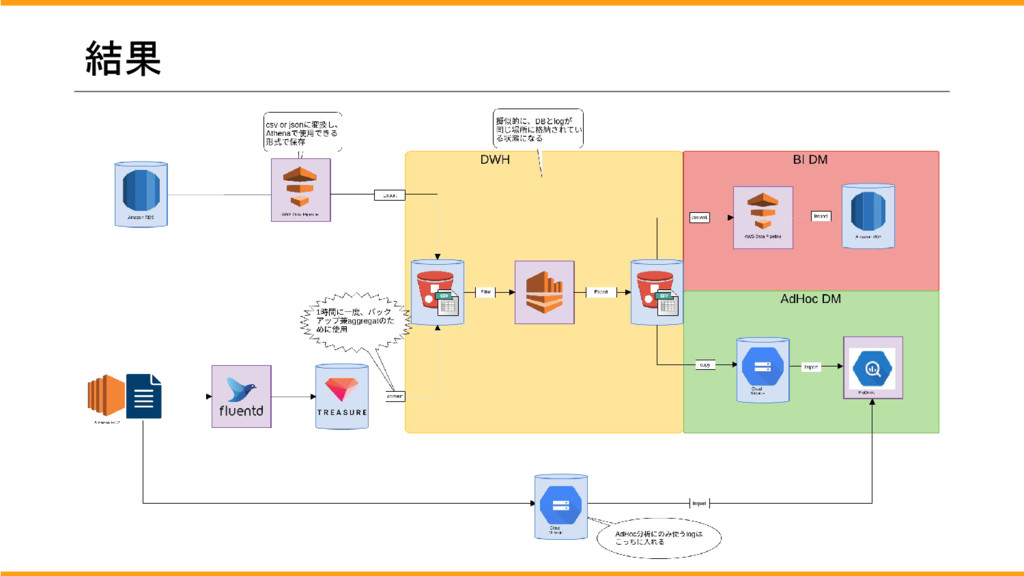
## 結果
これらのことを考慮してこのような構成になりました。
DWH自体は明言しておりませんがここの部分に当たります。
# 機会学習基盤について
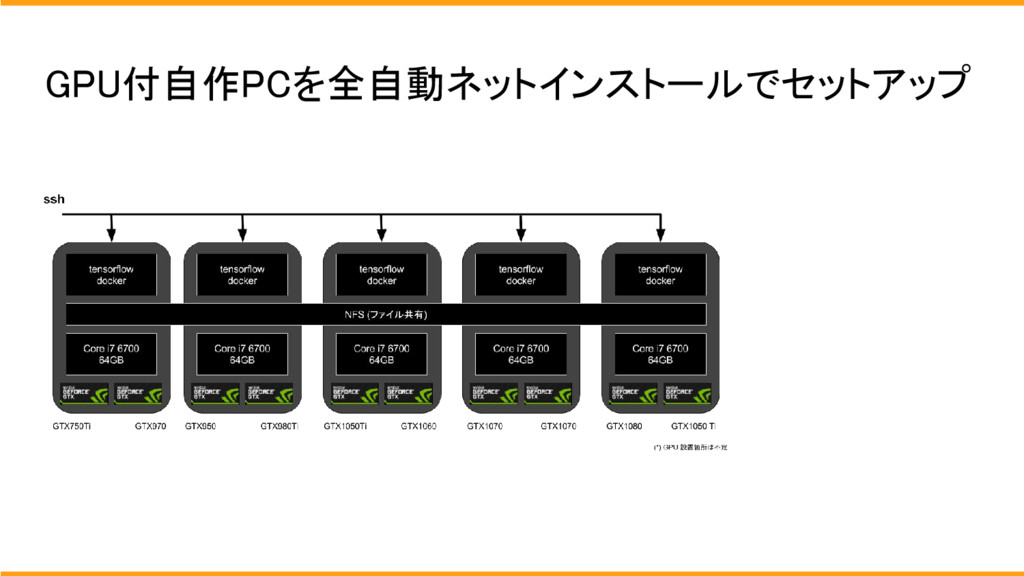
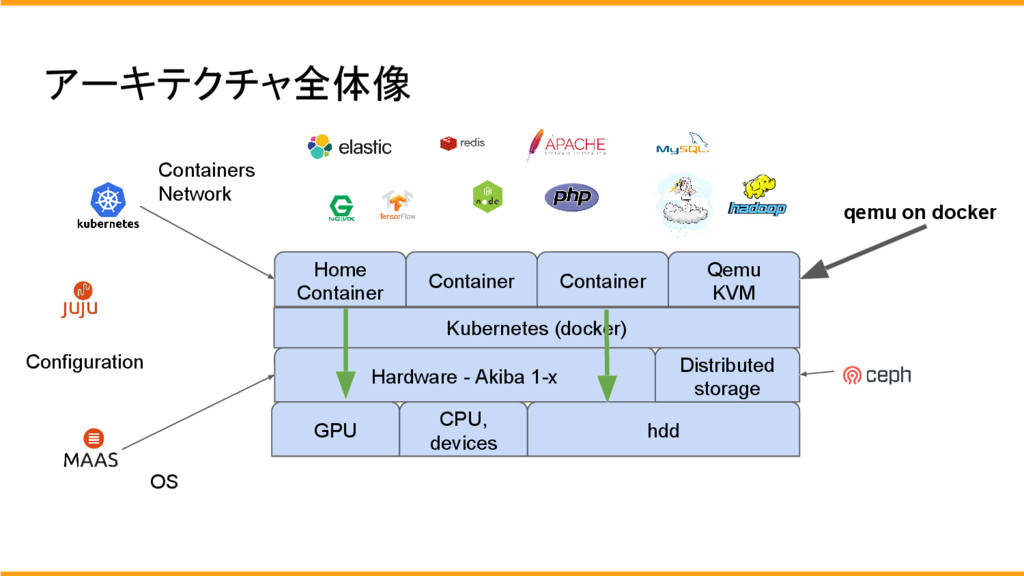
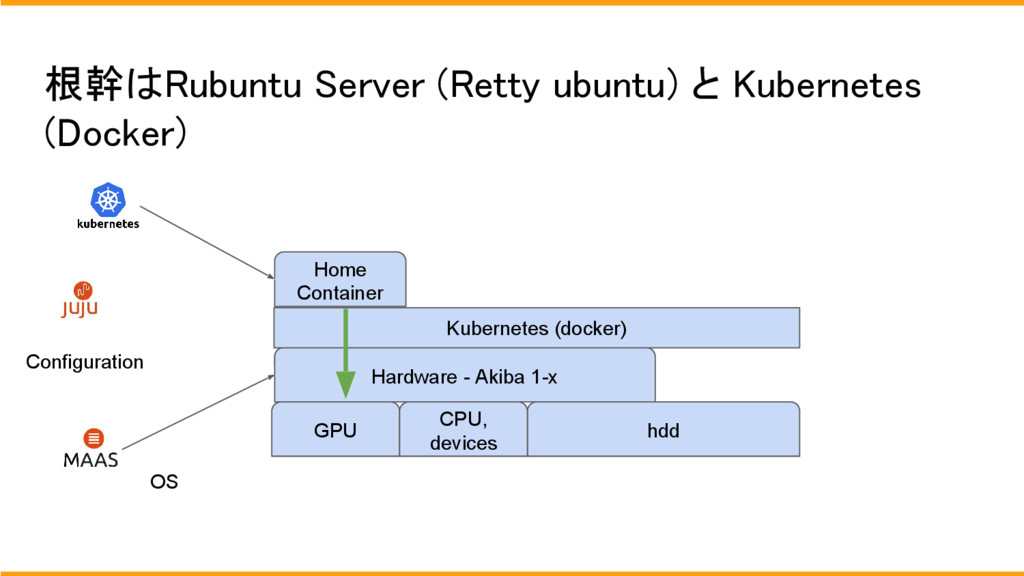
機械学習基盤は、基本的に全環境が同じものになっており、GPUのみ違う環境で構築されています。
OSのインストールはMaasとjujuを使用してネットワークインストールで行います。
また、ストレージは基本的には、chefにより共有ストレージを構築しております。
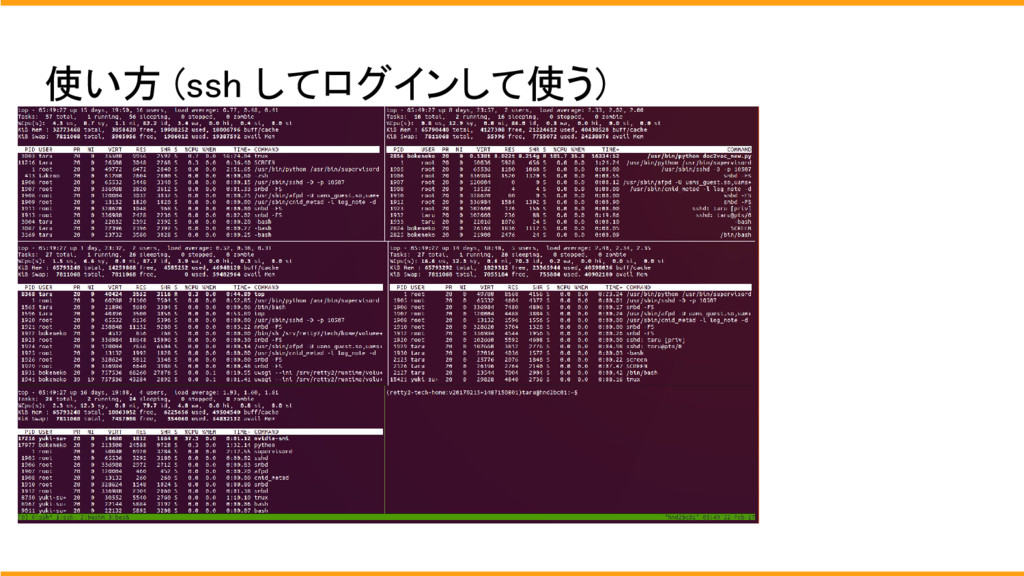
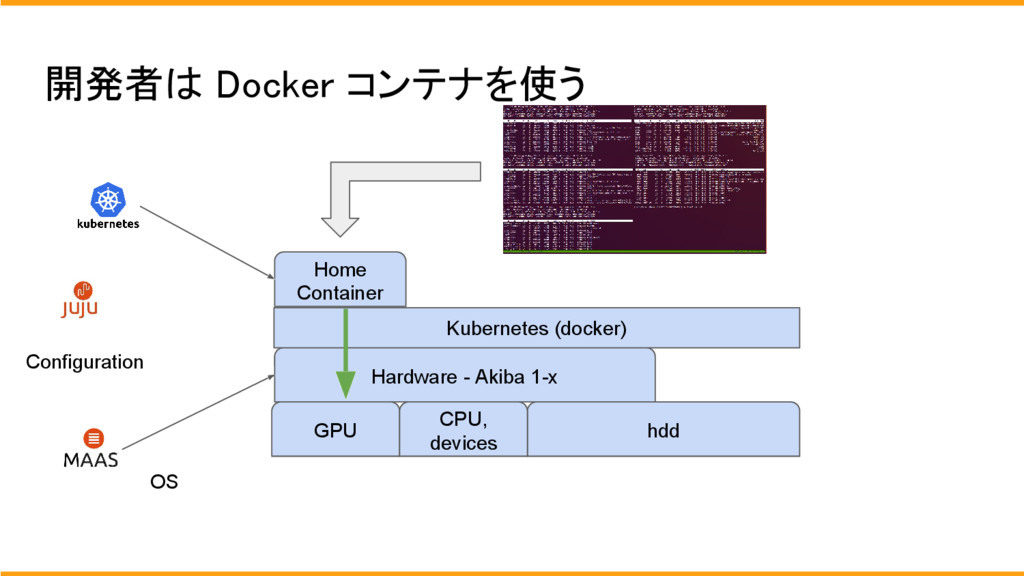
使用方法はsshで各個人のdocker にログインをして使用します。
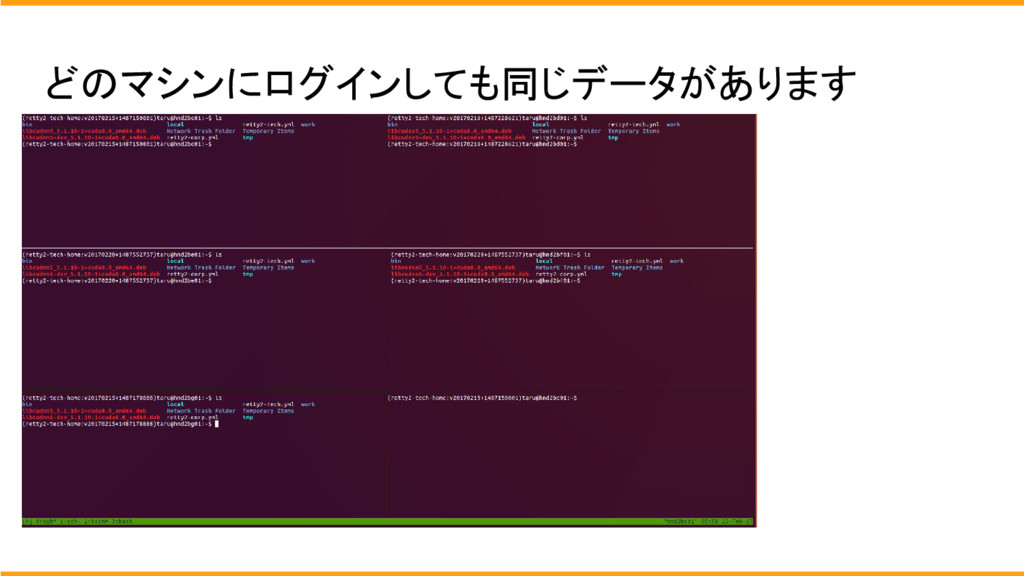
chefで共有ストレージとなっているため、どのサーバーにログインをしても、同じデーターがあります。
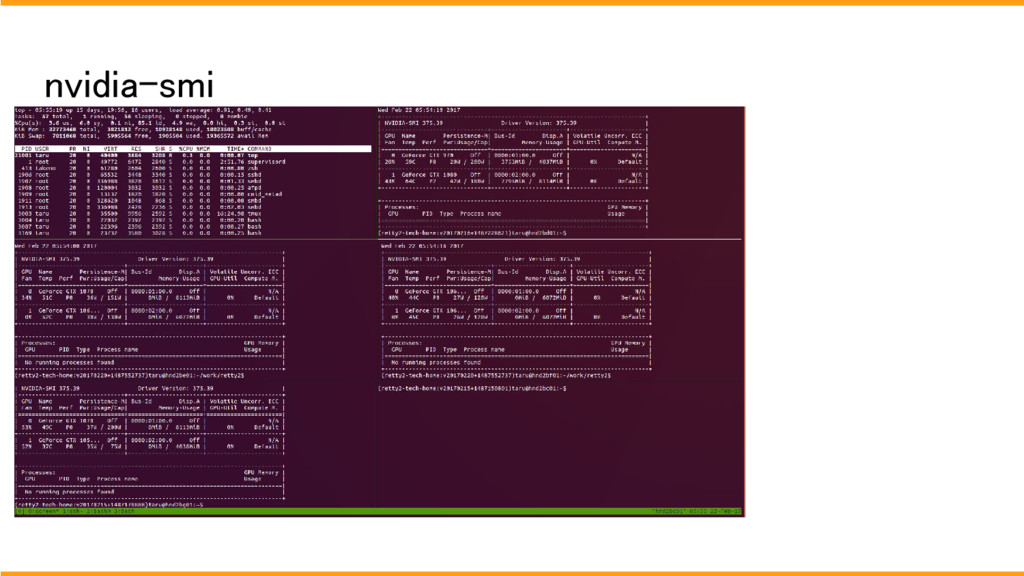
サーバー内はデーターは一緒ですが、搭載しているGPUはちがうため、開発者は用途や状況に合わせてサーバを選択してGPUを使用します。
## Quadro GP100 とは
FP32用CUDA Core数:3584基
FP64用CUDA Core数:1792基
グラフィックスメモリ容量:16GB(※HBM2 4モジュール)
マルチGPU対応:NVLink(※最大2-way)
世界初のNVLink対応のPCIe拡張カードです
詳しくは、まだベンチが取れていないのでご説明できませんが、かなり期待できるのではないかと思っています。
# まとめ
今回のデータ分析基盤のリプレイスにより、今まで課題となっていた問題を解決できたのではないかと思っています。
また、先のことを考慮して、移行のし易い環境を構築できていたのではないかと思います。
今後の課題としては、appサーバーからのログの送信やデータの鮮度を上げていくというようなことを考慮してアップデートをしていかなければいけないと考えております。
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}