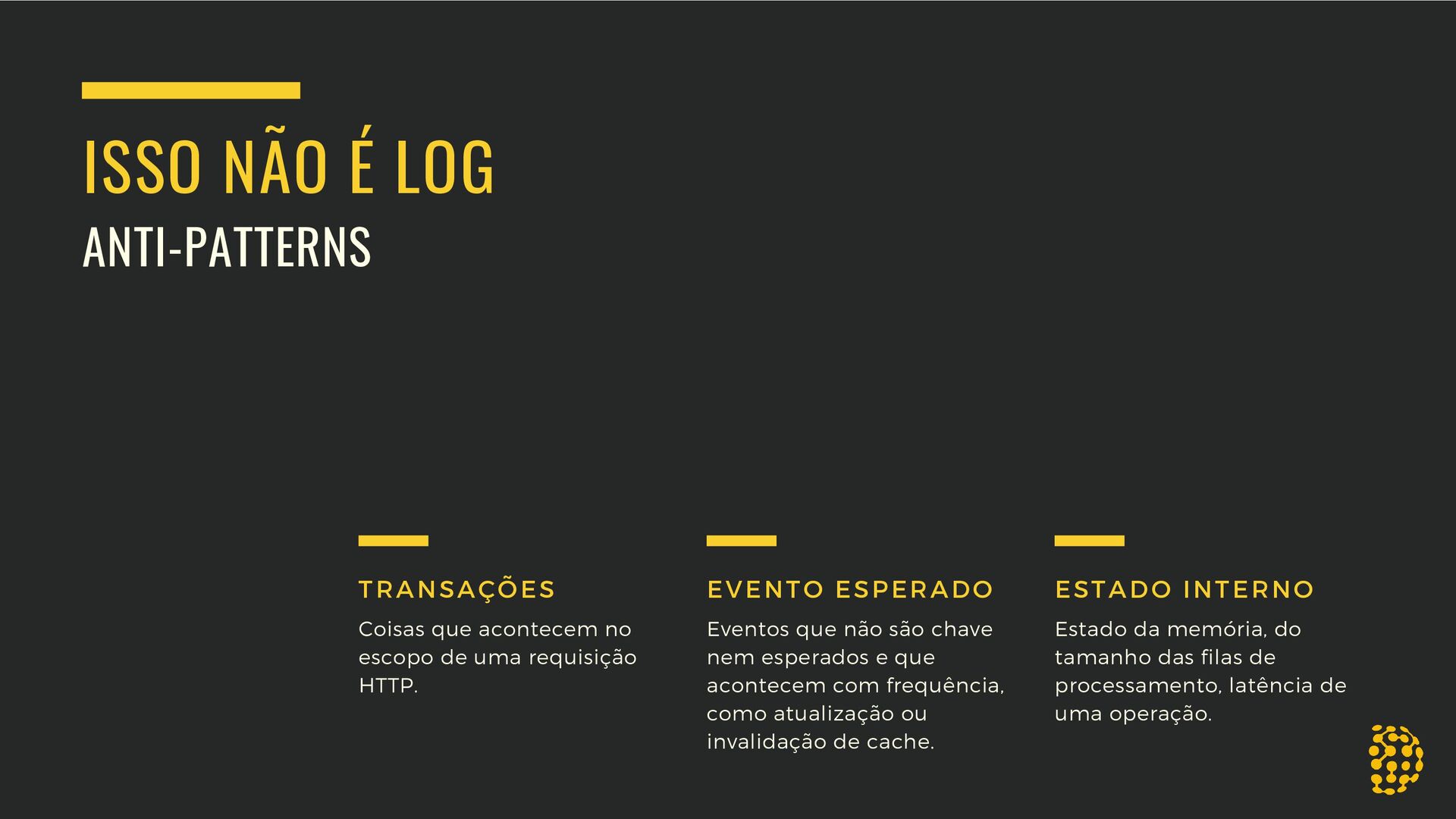
Nessa sessão, Juraci Paixão Kröhling fala sobre porquê precisamos de observabilidade, qual a diferença entre observabilidade e monitoramento, onde entra a telemetria nessa história toda, assim como os principais tipos de telemetria, quando usá-los e quando NÃO usá-los.
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}