Medindo a confiabilidade da sua aplicação: como o Nubank define níveis de serviço para tomar riscos calculados
In this presentation, Julio Turolla talks about how we measure and define reliability objectives for Nubank's services, and what was the journey to reach this level of operational maturity.
rights reserved. SUMMIT Medindo a confiabilidade da sua aplicação: como o Nubank define níveis de serviço para tomar riscos calculados Julio Turolla SWE, Tech Manager @ Observability Platform Nubank #STP05
rights reserved. SUMMIT Agenda 1. We want our customers to love us fanatically. 2. Como garantir que nossos sistemas estão operando dentro de padrões aceitáveis? 3. Monitoramento reativo é bom, mas tem seu custo. 4. Definindo o quanto arriscar.
rights reserved. SUMMIT Rápida atualização sobre o Nubank O maior banco digital fora da ásia, com 8,5MM clientes. Nossa equipe de atendimento continua robusta e premiada. Mais de 30MM de pessoas já se aplicaram para o cartão. 4.8MM de NuContas abertas. Aumentando a velocidade de crescimento.
rights reserved. SUMMIT Rápida atualização sobre o Nubank - Tech Mais de 2700 tabelas de DynamoDB Globalmente um dos maiores clientes do banco de dados da AWS. Mais de 2500 instâncias de computação EC2 no ambiente de produção. 3000 containers de serviço totalizando cerca de 10.000 vCPUs e 50Tb de Memória. 1 Bilhão de Requisições HTTP por dia. 90k Mensagens kafka por segundo. Expansão internacional para México. Aumentando a velocidade de crescimento.
rights reserved. SUMMIT Queremos que nossos clientes nos amem fanaticamente... … com um atendimento premiado. … sem asteriscos, taxas e cobranças escondidas. … com um aplicativo funcional e de qualidade. … respondendo suas requisições com sucesso em 300ms.
rights reserved. SUMMIT Em escala, as 3 funcionalidades mais importantes de um produto são: 1. O produto funciona. 2. O produto funciona. 3. O produto funciona.
rights reserved. SUMMIT O funcionamento do produto garante... • Alta confiança dos clientes na robustez do Nubank Fundamental para um banco digital. • Redução de tickets de atendimento, escalabilidade da operação e menos gargalos Incidentes geram sobredemanda, impactando filas de atendimento e reduzindo a experiência WOW dos clientes, sendo necessários mais analistas de atendimento. • Redução de burnout e mais tempo para melhorar o produto Menos incidentes significam mais horas para a engenharia entregar novidades que geram valor, impactando diretamente no emocional e qualidade de vida da engenharia, bem como o resultado financeiro da empresa.
rights reserved. SUMMIT Os pilares que permitem uma operação saudável a longo prazo: • Robustez Arquitetural • Desde o princípio o time de engenharia criou fundamentos robustos de comunicação entre sistemas distribuídos. Idempotência, mensageria, circuit breakers, balanceamento, etc. • Sharding • Clientes são divididos em grupos lógicos para escalabilidade. • Divisão lógica também reduz o raio de impacto de incidentes de tecnologia. • Observabilidade por padrão • Todos os novos serviços vêm instrumentados e suas métricas, logs e traces são coletadas automaticamente. • Cultura DevOps • Quem desenvolve o serviço é responsável por sua operação, resultando em maior contexto. • Times horizontais fornecem o ferramental para abstrair operações na AWS.
rights reserved. SUMMIT Arquitetura de Observabilidade Funcionamento Comentários Logs Todos os eventos que ocorrem no Nubank. Debugging, auditoria. Não funciona para métricas em tempo real, alertas, devido à imensa quantidade de dados. Métricas em Tempo Real Valores numéricos que representam características do sistema. Permite criação de alertas com baixa latência e baixo custo: levamos um minuto para acionar uma pessoa durante incidentes. Tracing Distribuído Acompanhar o percurso de um fluxo inteiro por vários microsserviços Melhoria na visualização de fluxos que podem ser altamente complexos.
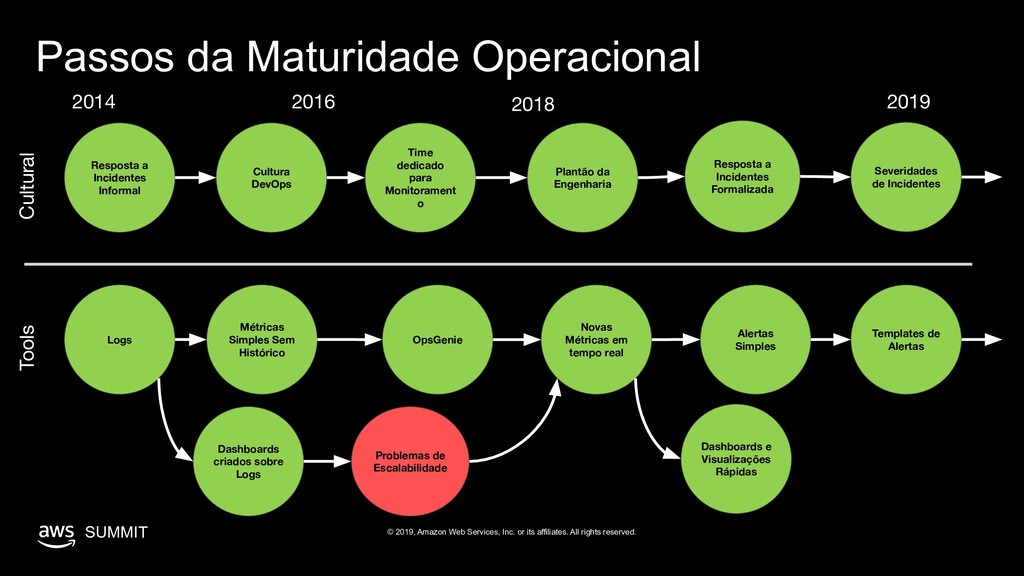
All rights reserved. Passos da Maturidade Operacional Novas Métricas em tempo real Severidades de Incidentes Alertas Simples Resposta a Incidentes Formalizada Cultural Tools 2014 Logs Templates de Alertas Resposta a Incidentes Informal Cultura DevOps 2016 2018 Métricas Simples Sem Histórico Time dedicado para Monitorament o Plantão da Engenharia OpsGenie 2019 Dashboards criados sobre Logs Problemas de Escalabilidade Dashboards e Visualizações Rápidas
rights reserved. SUMMIT Começamos cobrindo o básico (e um pouco mais) Métricas em tempo real acionam alertas quando níveis de erro são atingidos. Usando métricas com baixa latência, podemos avaliar centenas de milhares de valores por segundo contra limites pré estabelecidos para indicar a saúde de um sistema. Dashboards facilitam identificação de problemas e depuração em escala. Qualquer pessoa pode criar métricas e visualizações de seus serviços. Logs permitem um detalhamento de problemas, exceções e falhas. Todas as operações podem ser acompanhadas nos logs. Visualizações robustas inspiradas em projetos do Uber e Netflix auxiliam na identificação visual de problemas. A capacidade humana de identificar padrões é extremamente importante para correlacionar informações e descobrir causas-raíz.
rights reserved. SUMMIT Com monitoramento reativo atingimos um nível muito robusto de operação Com 100% dos times aderindo à cultura de resposta a incidentes e ao monitoramento de tempo real com alertas, conseguimos resolver problemas de forma muito mais eficiente. Nosso tempo médio de acionamento da engenharia em caso de incidentes se mantêm constantemente abaixo de 5 minutos. Ainda não avaliavamos quanto tempo total de falha ocorreu em um trimestre, tampoco definiamos o valor máximo aceitável de falha por trimestre, ou quais serviços são mais críticos que outros. Carece uma visão de longo prazo na estabilidade dos sistemas, e uma separação entre a importância dos mais de 250 microsserviços para que cada um tenha o nível de disponibilidade que necessita.
rights reserved. SUMMIT Voltamos para o whiteboard para projetar a confiabilidade pró-ativa. Precisamos repensar a forma que visualizamos informações, para permitir a criação de relatórios de confiabilidade. Definimos classificações de importância de serviços: críticos, importantes, úteis e experimentais. Integramos métricas em tempo real com nossa plataforma analítica (ETL).
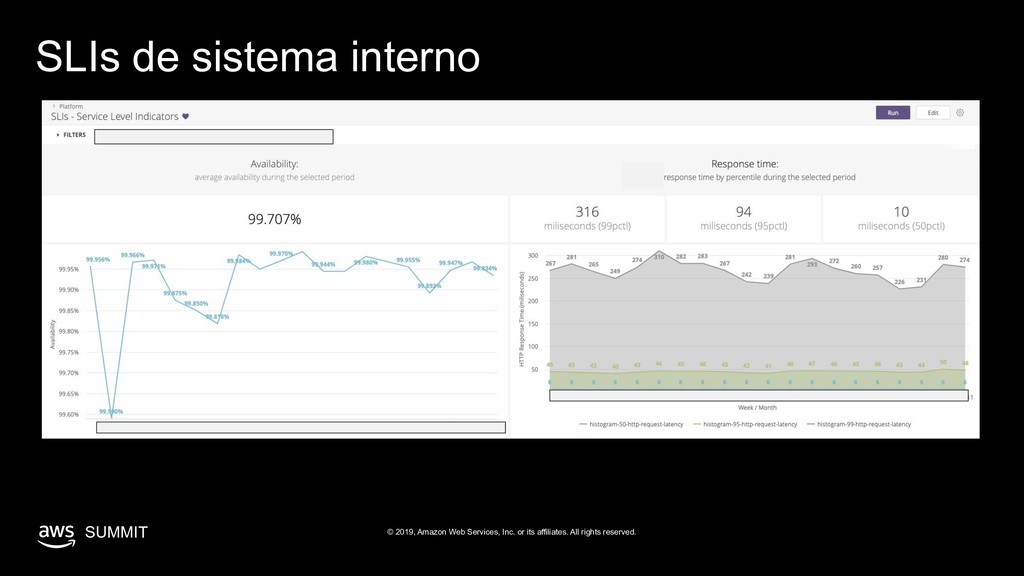
rights reserved. SUMMIT Adotamos o framework de SLOs 1. Serviços são categorizados em níveis de criticidade. 2. Dada uma criticidade, níveis aceitáveis de disponibilidade, erros e latência são passados como referência. Serviços críticos devem responder 99.9% das requisições com sucesso no trimestre. 3. Criamos o ferramental para visualizar estes níveis de serviço na plataforma de ETL. Para que gerentes de produto, analistas, e engenheiros entendam o impacto de incidentes no resultado final e cruzem estes dados com outros indicadores de performance do Nubank. 4. Dentro das referências, cada equipe define o quanto de erro aceita para cada fluxo ou serviço.
rights reserved. SUMMIT Por exemplo... Um Objetivo de Nível de Serviço de Disponibilidade define quanto tempo uma aplicação deve estar disponível para o cliente final. 99.9% availability = 1m 26s downtime / dia 43m 50s downtime / mês 8h 45m downtime / ano 1 de 1000 clientes não conseguirão completar suas solicitações.
rights reserved. SUMMIT Aplicando a serviços do Nubank Objetivo de Nível de Serviço (fictício) Efetivo (fictício) Auth 99.9% Disponibilidade 99.43% => Demanda melhoria operacional Credit Card Accounts 99.5% Disponibilidade 99.998% => Acima do Nível, arriscamos pouco? Mortician 95% Disponibilidade 96% => Dentro do aceitável
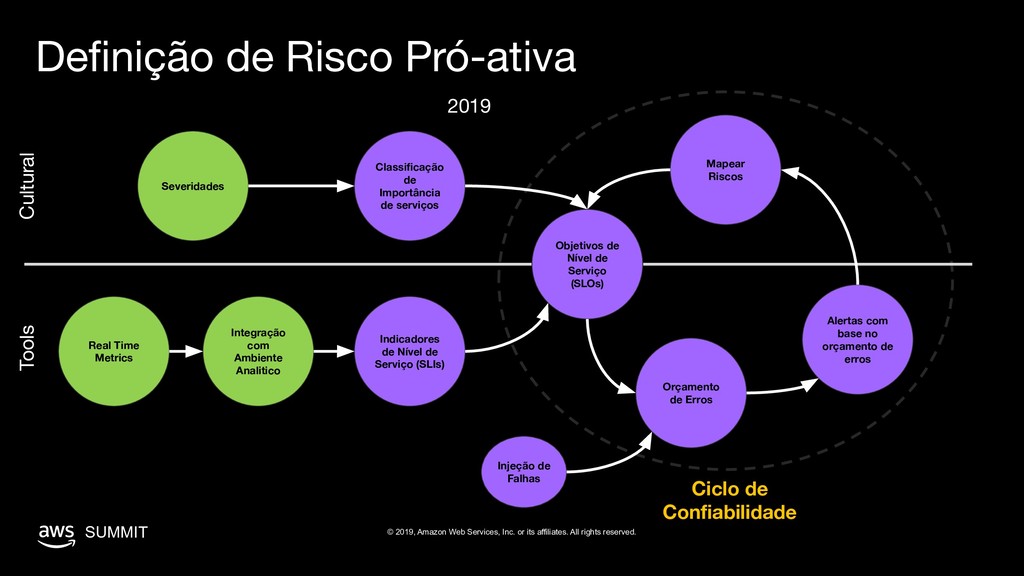
All rights reserved. Definição de Risco Pró-ativa Real Time Metrics Severidades Classificação de Importância de serviços Integração com Ambiente Analitico Indicadores de Nível de Serviço (SLIs) Orçamento de Erros Alertas com base no orçamento de erros Cultural Tools Mapear Riscos Objetivos de Nível de Serviço (SLOs) Ciclo de Confiabilidade To map the desired level for each service Injeção de Falhas 2019
rights reserved. SUMMIT Recapitulando... 1. Para que nossos clientes nos amem fanaticamente, e para a escalabilidade de nossa operação, precisamos de um sistema que funcione. 2. Níveis aceitaveis de disponibilidade, erros e latência são definidos por suas equipes para cada sistema ou fluxo. 3. Nos beneficiamos de nossa plataforma de métricas em tempo real para calcular a confiabilidade dos sistemas a longo prazo. 4. Times são responsáveis por acompanhar seus Objetivos de Níveis de Serviço, seus Orçamentos de Erros, e mitigar riscos.
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}