recebe e responde requisições web, mensagens ou outros tipos de IO; se comunica com bancos de dados, caches, e third parties. Um bom toolset de observabilidade permite o acesso fácil a detalhes do funcionamento de cada um dos componentes do seu sistema, em diferentes níveis de granularidade e latência e tipos de dados.
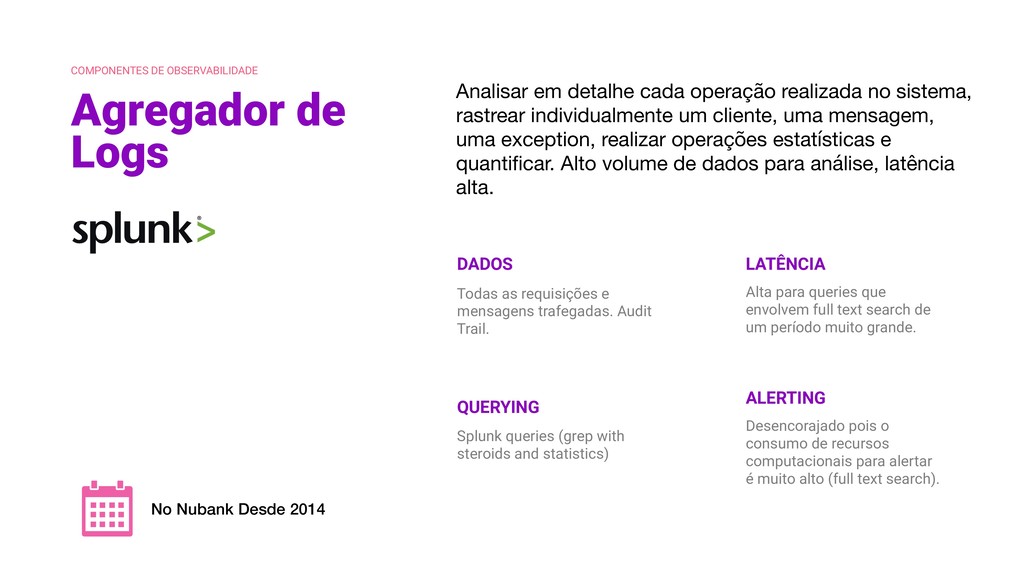
mensagens trafegadas. Audit Trail. DADOS Alta para queries que envolvem full text search de um período muito grande. LATÊNCIA ALERTING Desencorajado pois o consumo de recursos computacionais para alertar é muito alto (full text search). Splunk queries (grep with steroids and statistics) QUERYING No Nubank Desde 2014 Analisar em detalhe cada operação realizada no sistema, rastrear individualmente um cliente, uma mensagem, uma exception, realizar operações estatísticas e quantificar. Alto volume de dados para análise, latência alta.
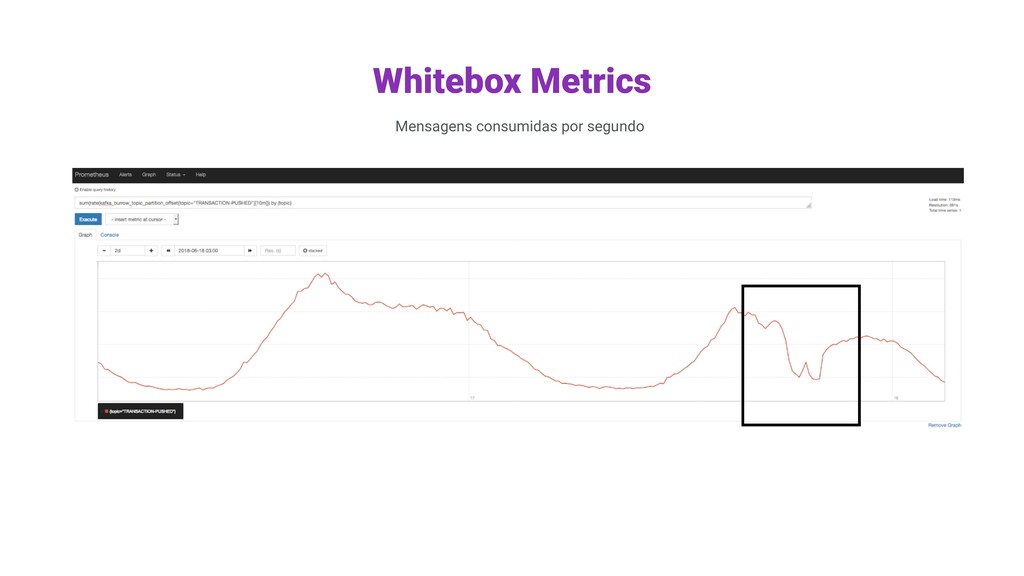
dimensões. DADOS Muito baixa, informação obtida a cada 30s; Queries rápidas para retenção longa. LATÊNCIA Suitable, fácil de definir thresholds e regras. ALERTING PromQL QUERYING v1 (Riemann) Desde 2013 v2 Desde 2018 Permitem criar visualizações, dashboards, e alertas, definir thresholds, tempos de resposta aceitáveis, taxa de erros aceitáveis. Dados dimensionais numéricos, latência baixa.
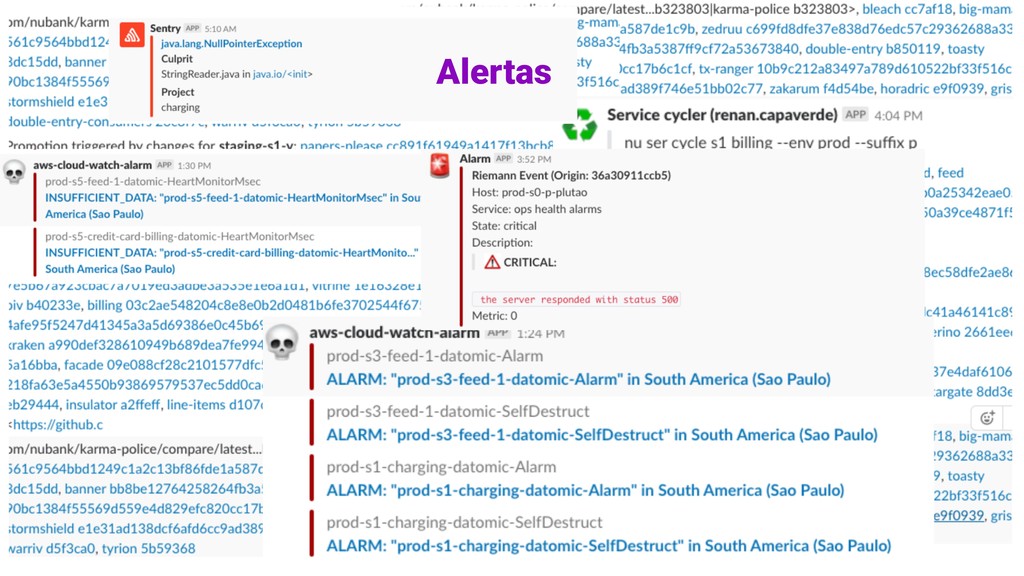
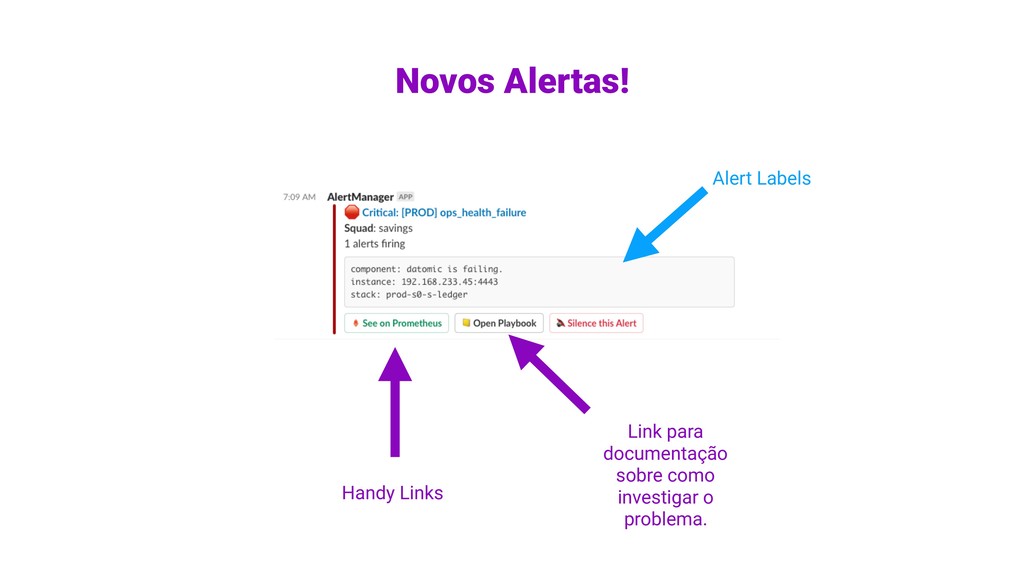
de métricas em tempo real. DADOS < 60s entre o disparo de um alerta e o acionamento de uma engenheira. LATÊNCIA No Nubank desde 2016 Deployado para todo mundo em 2018 Garantir que quando um problema ocorrer, a engenheira responsável será alertada e estará pronta para iniciar um procedimento de resposta a incidentes.
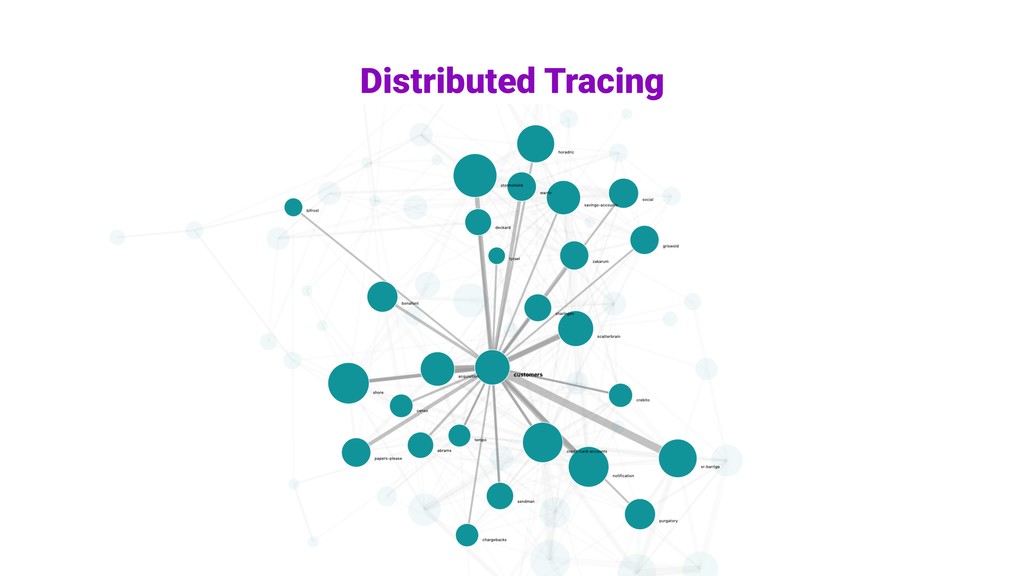
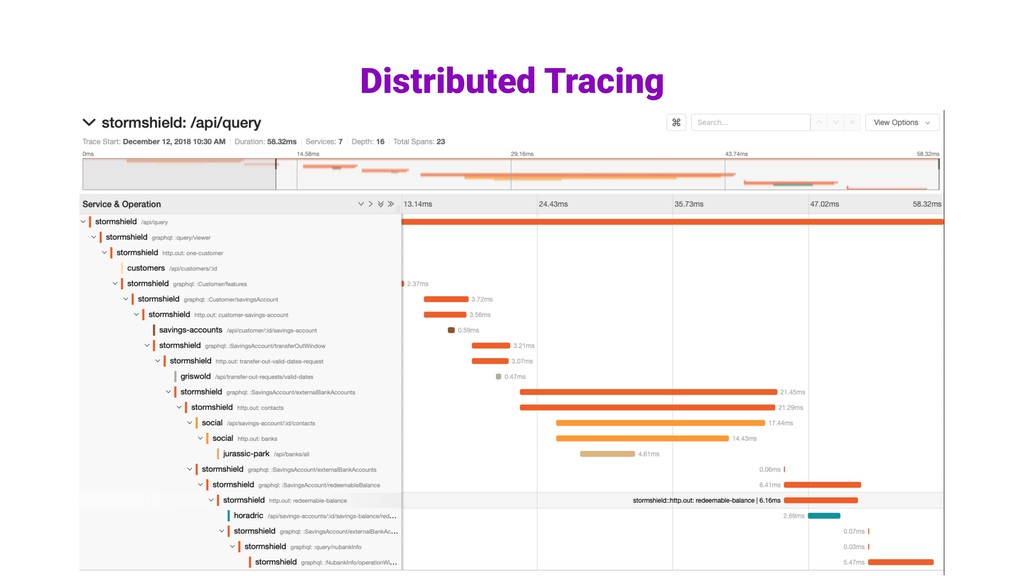
day. 12 Instances Elasticsearch. SIZE Sample de requisições e mensagens. DADOS No Nubank desde Setembro, experimental. Analisar o percurso de uma requisição ou mensagem, desde o momento que ela sai do app, até o momento que todas as operações resultantes dessa sejam concluídas. Dados de amostragem.
crítico :) LATÊNCIA Snapshot de performance da aplicação. DADOS nu k8s dump flamegraph s0 billing --env prod COMO USAR Entender a fundo o funcionamento de um processo, quais métodos estão tomando mais tempo, com lock ou baixa eficiência, usando muita cpu. Dados ad-hoc, solicitados pela engenheira durante debugging.
na correção do incidente se reúnem no canal #crash, ou pessoalmente para coordenar a resposta. DURANTE O INCIDENTE Uma reunião de Postmortem é agendada para discutir mitigações para que o incidente não volte a ocorrer. APÓS O INCIDENTE Ao identificar um problema, os responsáveis pelo sistema devem estar prontos para implementar uma mitigação e correção do problema, e realizar uma reunião posterior para evitar que o problema se repita e compartilhar informação.
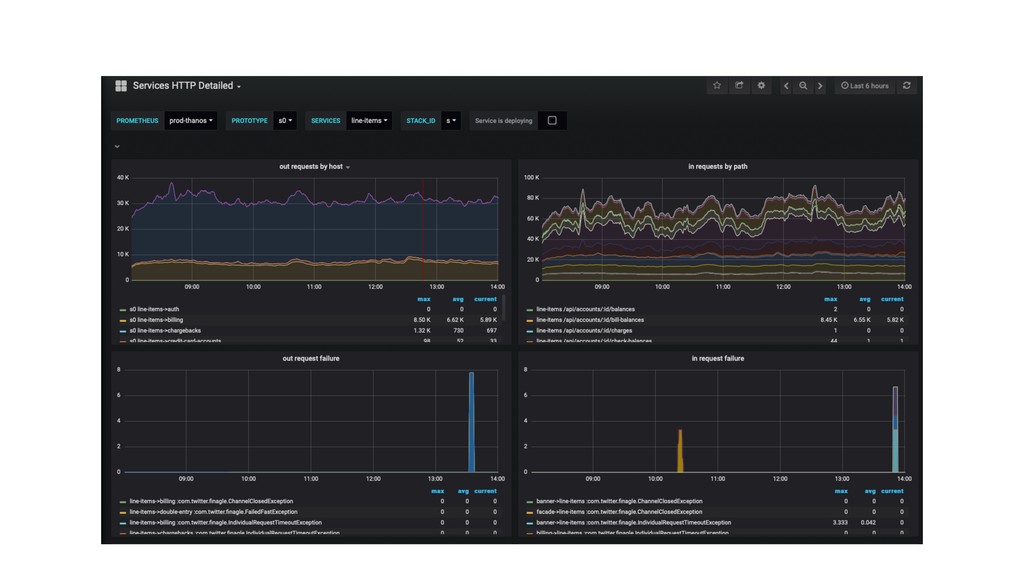
demanda sem comprometer as métricas anteriores. Saturação As operações devem finalizar em tempo aceitável, evitando uma experiência frustrante do ponto de vista do cliente ou do backoffice. Latência Quantas requisições por segundo estamos recebendo? Houve uma degradação por um pico de acesso? Tráfego Cada operação realizada deve ter sucesso na grande maioria dos casos. Taxa de erro acima de um limite pode indicar um problema e deve acionar os engenheiros. Taxa de Erros 1 Ou... Funcionar com (bem) poucos defeitos 2 3 4 Todas métricas de tempo real, logo, vamos implementá-las!
shard="s0"} 100.0 services_http_requests_total{service="billing", shard="s1"} 13370.0 Identificador (nome da métrica) Dimensões (labels) Valor O serviço expõe o que está acontecendo internamente.
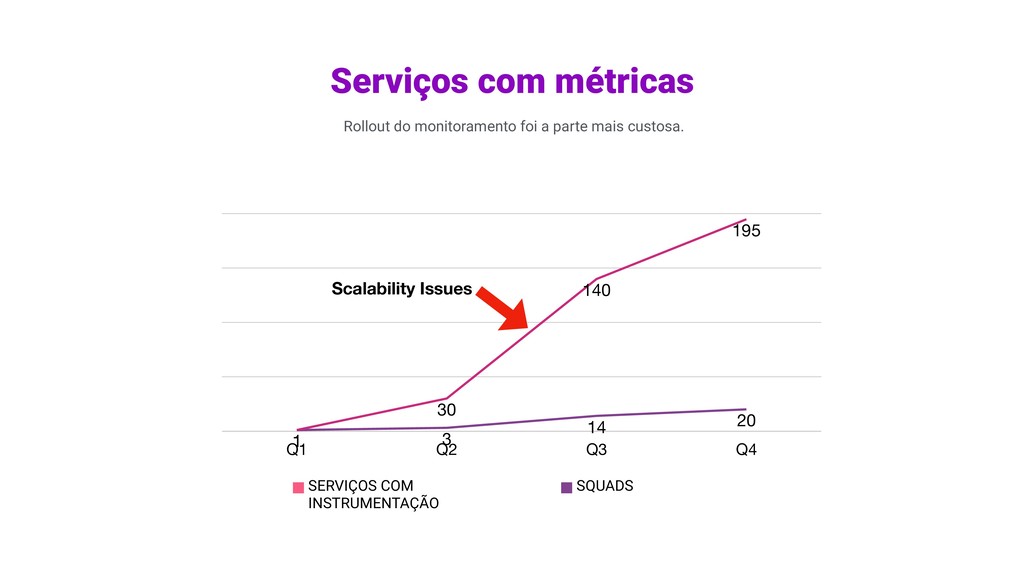
você não vai conseguir fazer isso sozinha! Incentive um loop de feedback Nossas aplicações precisa exibir as métricas que estamos buscando, como requisições HTTP com sucesso, com erro, e mensagens consumidas. Instrumentar uma métrica Uma aplicação de monitoramento precisa coletar estas métricas, armazená-las e permitir querying. Infraestrutura de Coleta e Query Com os dados ingeridos, criamos o primeiro alerta de taxa de erros acima do limite. Criar o primeiro alerta 1 Baby Steps... Um serviço por vez, e mudanças culturais. 2 3 4 Rollout do monitoramento foi a parte mais custosa.
suas aplicações, melhores serão suas métricas e mais dados estarão disponíveis para negociar com stakeholders aquele refactor que já foi postergado por tempo demais. Monitorando desde o dia zero, a curva de rollout para métricas e alertas vai ser orgânica e demandar muito menos esforço. Comece a monitorar cedo!
ele crescerá organicamente. Desenvolva a plataforma, playbooks e garanta que ela esteja funcionando, mas não é escalável realizar todas as instrumentações você mesmo — ensine as pessoas que monitorar é parte de desenvolver um software. Você não consegue fazer o trabalho sozinho!
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}